斯坦福祭出 CU-Mamba | 不仅具有通道感知,更是将双状态空间模型(SSM)框架融入到U-Net

斯坦福祭出 CU-Mamba | 不仅具有通道感知,更是将双状态空间模型(SSM)框架融入到U-Net

公众号-arXiv每日学术速递
发布于 2024-04-25 19:06:24
发布于 2024-04-25 19:06:24

重建退化图像是图像处理中的关键任务。尽管基于卷积神经网络(CNN)和Transformer的模型在该领域中非常普遍,但它们存在固有的局限性,比如对长距离依赖的建模不足以及高计算成本。 为了克服这些问题,作者引入了通道感知U型Mamba(CU-Mamba)模型,它将双状态空间模型(SSM)框架融入到U-Net架构中。 CU-Mamba使用空间SSM模块进行全局上下文编码,并采用通道SSM组件来保持通道相关性特征,两者相对于特征图大小都具有线性计算复杂性。 广泛的实验结果验证了CU-Mamba相对于现有最先进方法的优越性,强调了在图像恢复中同时融合空间和通道上下文的重要性。
I Introduction
图像恢复是数字图像处理中的基本任务,旨在从各种退化(如噪声、模糊和雨迹)损害的图像中重建高质量图像。最近的进展凸显了卷积神经网络(CNNs)[1, 2, 3]和基于Transformer的模型[4, 5, 6, 7]在此领域的有效性。CNN利用层次结构,擅长捕捉图像内的空间层次。Transformer模型最初是为自然语言处理设计的,但已经显示出对视觉理解的积极成果,例如Vision Transformer[8]。Transformer模型采用自注意力机制,特别擅长建模长距离依赖。这两种方法在许多图像恢复任务中均取得了最先进的结果[9, 10, 11]。
然而,卷积神经网络(CNNs)和基于Transformer的模型都有其局限性。尽管CNN在局部特征提取方面很有效,但由于其有限的感受野,它们通常难以捕捉图像中的长距离依赖关系。相比之下,尽管Transformers通过全局注意力模块缓解了这个问题,但它们相对于特征图大小的计算成本是二次的。此外,Transformers可能会忽略对于有效图像恢复至关重要的细粒度局部细节。
为了解决这些限制,近期的进展引入了结构化状态空间模型(SSMs),特别是Mamba模型[12, 13],作为图像识别网络的有效构建模块[14, 15]。通过高效地通过输入依赖的选择性SSMs[13]压缩全局上下文,Mamba保持了全局感受野的好处,同时与输入标记的线性复杂度进行操作。这种方法已经在各种语言和视觉任务中展示了卓越的性能,超过了基于CNN和Transformer的模型[13]。然而,大多数视觉Mamba模型将SSM块独立应用于每个特征通道,这可能导致通道间信息流的丢失[16],这对于在图像恢复中压缩和重建图像细节尤其关键。
为了解决上述挑战,作者提出了一个通道感知型U形Mamba(CU-Mamba)模型用于图像修复。在图像修复的传统U-Net结构[17]之上,CU-Mamba通过Mamba模块实现了全局感受野,同时保持了通道特定的特征。作者在架构中使用了一个空间状态空间模型模块,以线性计算复杂度有效地捕获图像中的长距离依赖关系,确保了对全局上下文的全面理解。此外,作者还实现了一个通道状态空间模型组件,在U-Net的特征图压缩和后续上采样过程中增强通道间的特征混合。这种双重方法使得CU-Mamba模型能够在捕捉广泛的空间细节和保持复杂的通道间相关性之间达到微妙的平衡,从而显著提高了修复图像的质量和准确性。
总的来说,这项工作主要贡献如下:
- 作者引入了通道感知U形玛巴(Channel-Aware U-Shaped Mamba,简称CU-Mamba)模型,通过结合双状态空间模型(State Space Model,简称SSM)来为图像恢复任务丰富U-Net的全球上下文和通道特定特征。
- 作者通过详细的消融研究验证了空间和通道SSM模块的有效性。
作者的实验表明,CU-Mamba模型在多种图像恢复数据集上取得了有希望的性能,超越了当前的SOTA方法,同时保持了较低的计算成本。
II Related Work
基于CNN的方法: 近几年,基于CNN的模型[3, 11]一直是图像恢复的基本架构。这些模型相比于传统的技术[18](后者严重依赖手工制作特征和先验知识)实现了实质性的改进。在基于CNN的模型中,具有跳跃连接的U形编码器-解码器网络[19]因其分层多尺度架构和残差特征表示,在各种图像恢复任务中展现出了强大的竞争力。
基于Transformer的方法: CNN中的固有局部感受野限制了捕捉长距离依赖的能力。这一挑战促使采用Transformer模型[8, 20],它们利用全局自注意力机制来封装图像中的长距离交互。现在,Transformer模型广泛应用于低级视觉任务中,如超分辨率[7]、图像去噪[21]、去模糊[22]和去雨[23]。为了减少注意力机制中的二次计算复杂度,自注意力在局部窗口[24]或通道维度[25]上执行。尽管进行了架构设计,但由于自注意力模块的内在机制,计算开销依然很高。
视觉结构化状态空间模型: 最近的创新包括将状态空间模型(SSMs)[12, 13]集成到图像识别流程中,正如Vision Mamba [15]所示。SSMs提供了一种新颖的方法,以线性计算复杂度捕获长距离依赖关系,从而解决了Transformer固有的计算低效问题,同时保留了其全局上下文建模能力。U-Mamba [26]和VM-UNet [27]将Mamba模块引入到U-net结构中,以解决生物医药图像分割问题。为了促进通道间的信息流动,MambaMixer [16]引入了通道混合的Mamba模块到图像识别和时间序列预测中。然而,现有的U形Mamba架构并没有集成通道SSM模块,这对于在丰富的通道维度上下文中压缩和重建特征至关重要。在这项工作中,作者提出了一种高效且有效的双向Mamba U-Net,它在图像恢复过程中同时考虑了全局上下文和通道相关性。
III Method
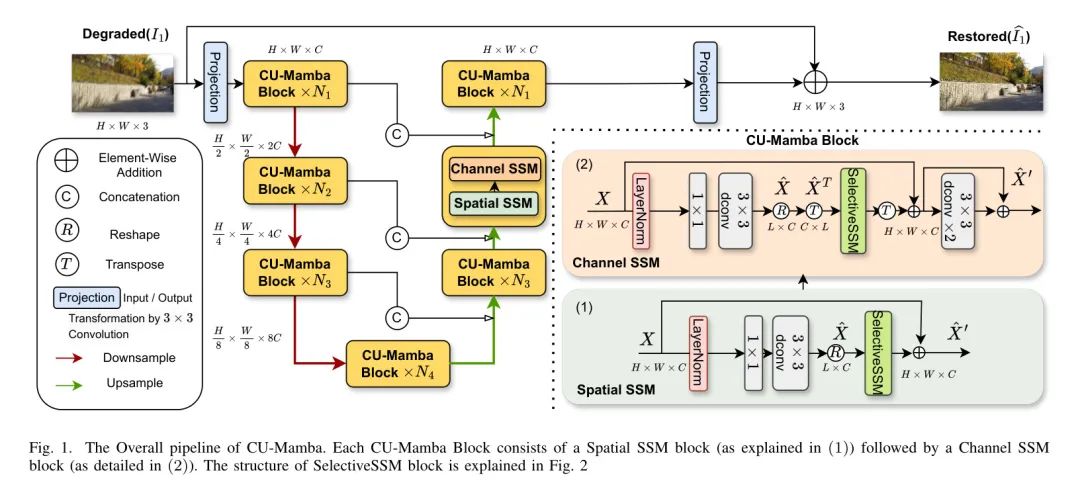
作者旨在开发一种有效的U-Net,该网络专注于图像修复中的长距离空间和通道相关性。作者提出了CU-Mamba模型,该模型应用空间和通道SSM块来学习全局上下文和通道特征,仅具有线性复杂性。在本节中,作者首先介绍U-Net设计的整体流程,然后通过解释以下内容深入探讨其组成部分:选择性的SSM框架、作者的空间SSM块以及作者的通道SSM块。最后,作者分析作者模型的计算成本以证明其效率。
Overall Pipeline
图1展示了CU-Mamba的整体框架。给定一个退化的图像
,首先通过一个
卷积来获取低级特征
。
然后被送入一个4级的对称编码器-解码器U-Net结构中,以形成细粒度、高质量的特征。在每一级
,编码器包含
个CU-Mamba块和一个下采样层。具体来说,每个CU-Mamba块包含一个空间SSM块,后面跟着一个通道SSM块,如图1中的(1)和(2)所示。下采样操作逐级减少空间尺寸并增加通道数量,形成特征图
。
在公式中,
表示真实图像,
是到频域的傅里叶变换。在实验中,作者设置
和
。
Selective SSM Framework
作者提供了一个简单的概述,关于作者框架中所采用的的选择性SSM(Mamba)机制[13]。
结构化状态空间序列模型(SSMs)通过一个隐含的潜在状态
将一维序列输入
映射到
。一个SSM由四个参数
定义,具有以下操作:
在公式中,
是通过固定变换从
得到的离散版本,即
和
。在SSM块中可以采用各种离散化规则,而离散化使得通过全局卷积的高效并行化训练成为可能。
尽管离散化带来了效率,但在SSMs中的参数
是数据独立的且时间不变的,这限制了隐藏状态在压缩已观察上下文时的表现力。选择性SSM(或Mamba)引入了数据相关参数
,这些参数能有效选择
中的相关信息:
。
通过硬件感知优化,选择性的SSM(选择性状态空间模型)在与序列长度相关的计算和内存复杂性方面保持线性消耗,同时有效地压缩全局输入序列中的相关上下文。优化后的选择性SSM(Mamba)架构[13]如图2所示。
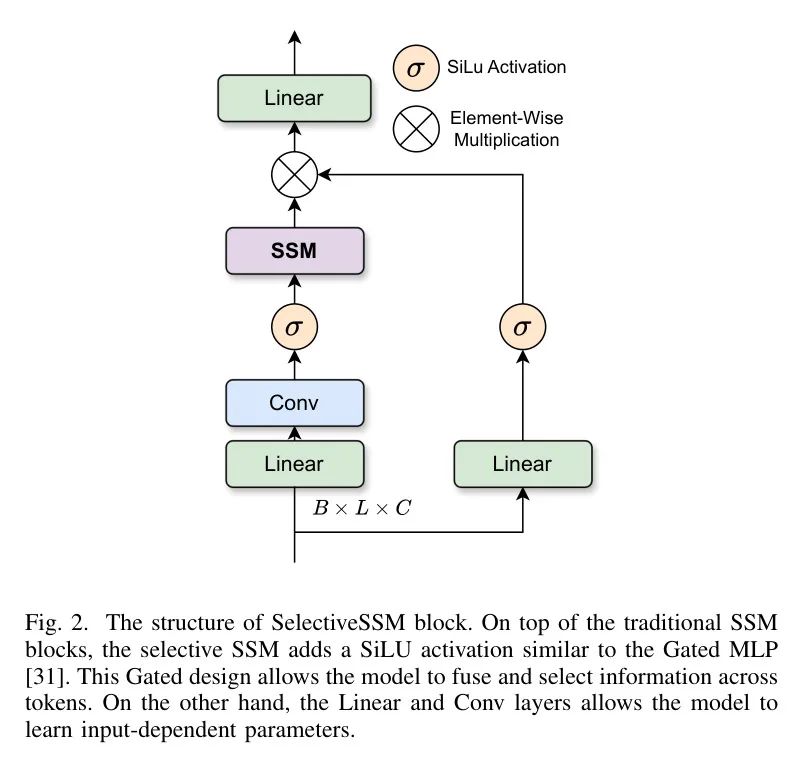
Global Learning Block: Spatial SSM
Transformer 架构的成功表明,通过U-Net的分层结构整合全局上下文对于高质量图像恢复至关重要。然而,这种全局感受野的代价是二次计算复杂度[20]。因此,作者设计了一个全局学习块,它有效地使用选择性的SSM框架压缩长距离上下文,这个框架只需要线性的计算复杂度。
给定一个层归一化的输入张量
,作者首先应用
卷积在像素 Level 上汇聚不同通道的上下文,然后使用
深度卷积通过通道捕获空间上下文。接着,作者将特征图展平为
,其中
,以构建特征块的序列。作者通过以下方式编码
的全局上下文:
在图2中展示了选择性SSM块并对其进行了说明。作者可以将这一操作解释为从左上角到右下角线性扫描张量
的特征图,其中图中的每个像素都从所有先前看到的环境中学到其隐藏表示。最终的表示
被 Reshape 为
,并在其
维度内编码长距离依赖关系。
Channel Learning Block: Channel SSM
在U-Net架构中,下采样和上采样路径中的通道特征对于压缩和重建图像的上下文和结构至关重要。现有基于Mamba的U-Net的一个问题是,在扫描图像特征图以捕捉全局上下文时,通常忽略了通道信息。为了学习跨通道特征之间的依赖关系,作者在通道维度上引入了选择性的SSM机制。
类似于空间SSM模块,给定一个层归一化的输入张量
,作者使用
卷积后接
深度卷积来预处理局部语境。然后,作者将
转置为
并展平为
。这可以被视为使用展平的特征像素作为通道表示。然后,作者通过以下方式应用选择性的SSM:
这个操作通过从上至下扫描通道图,有效地混合并记忆通道特征。最终的特征
被重新调整形状并转置回
。然后它被传递给带有LeakyReLU激活函数的2个
深度卷积块,以平滑局部表示。
Computational Complexity of CU-Mamba
作者遵循和的复杂性分析。将批量大小表示为
,输入序列长度表示为
(这里,
),通道维度表示为
,扩展因子表示为
(在作者的实现中
)。采用高效的并行扫描算法,空间SSM块的计算复杂度为
,而通道SSM块的复杂度为
。因此,总复杂度为
,这在与序列长度和通道维度成线性关系。
IV Experiments
作者首先解释实验设置的细节。然后,通过在图像去噪和图像去模糊的广泛实验中,作者展示了CU-Mamba的强大性能。最后,作者进行消融研究以验证CU-Mamba模型中每个模块的有效性。
Experimental Settings
参数设置:遵循之前的训练设置[5],作者通过随机水平翻转图像以及将图像旋转
,
或
来预处理训练样本。在训练过程中,作者使用AdamW优化器[48],动量参数
和
。为了稳定训练过程,作者将初始学习率设置为
,并采用余弦退火策略[49]逐渐降低到
。传递到初始SSM块的通道宽度
设置为32。
评估指标: 为了评估恢复质量,作者采用了PSNR(峰值信噪比)和SSIM(结构相似性指数)[50]指标,这与之前的研究保持一致。PSNR通过计算最大可能信号功率与破坏性噪声功率之间的比率来衡量重建图像的质量,而SSIM则比较重建图像与原始图像之间的结构相似性。作者是在RGB色彩空间下计算这些指标的。
Image Denoising Results
作者评估了作者的方法在真实世界噪声去除方面的性能,使用了SIDD [32] 和DND [33] 数据集。对于DND数据集的评估,作者遵循了之前工作[5]的常见策略:使用SIDD数据集训练作者的模型,并在DND的在线服务器上测试作者的模型。表1呈现了作者的 Proposal 方法与在SIDD和DND数据集上的最先进方法的比较分析。值得注意的是,作者的方法优于现有的基于CNN的方法(RIDNet [35], MPRNet [38], HINet [39])和基于Transformer的方法(Uformer [5], Restormer [4]),显示了其在处理真实世界噪声方面的有效性。图3展示了与SIDD数据集上的真实图像相比,作者方法的定性结果。作者可以观察到,作者的方法能够以更精确的细节重建噪声图像,类似于真实图像。

Image Deblurring Results
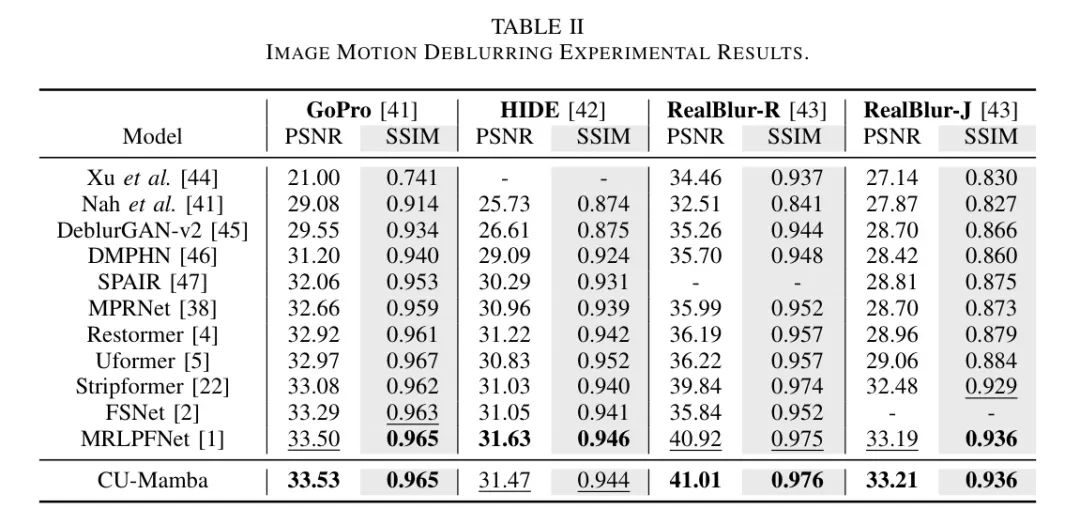
作者测试了CU-Mamba在四个数据集上的运动模糊去除性能。按照之前的方法[38],作者使用GoPro数据集[41]的训练集来训练作者的模型,然后作者在两个合成数据集(GoPro的测试集[41]和HIDE[42])和两个真实世界数据集(RealBlur-R和RealBlur-J[43])上测试作者的模型。
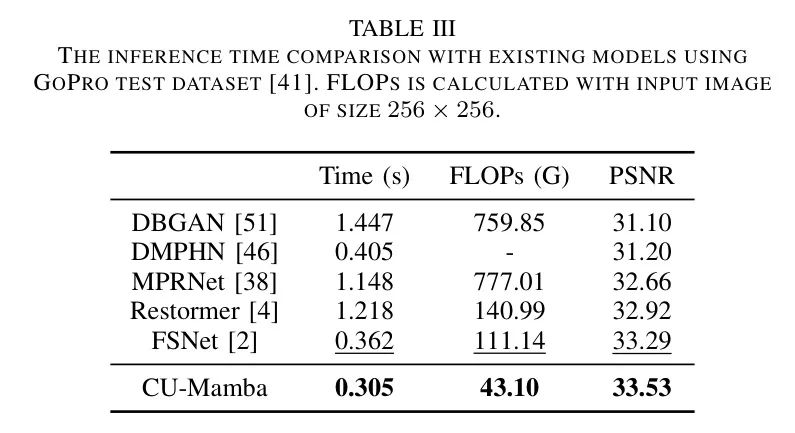
正如表2所示,作者的方法优于当前最先进的技术MRLPFNet[1],在RealBlur-R数据集上实现真实世界图像去模糊时,获得了0.09 dB的改进。作者还测试并与之前的工作在表3中比较了模型的推理时间。与基于变换的模型Restormer[4]相比,作者的模型表现出快4倍的推理速度,此外在PSNR上还实现了0.87 dB的性能提升。
这证明了作者选择性SSM块中线性复杂度相对于自注意力模块的二次成本的有效性。此外,通过与其他现有方法在图4中的定性比较,作者突显了CU-Mamba在生成与 GT 标签更接近的更真实去模糊图像方面的有效性。

Ablation Studies
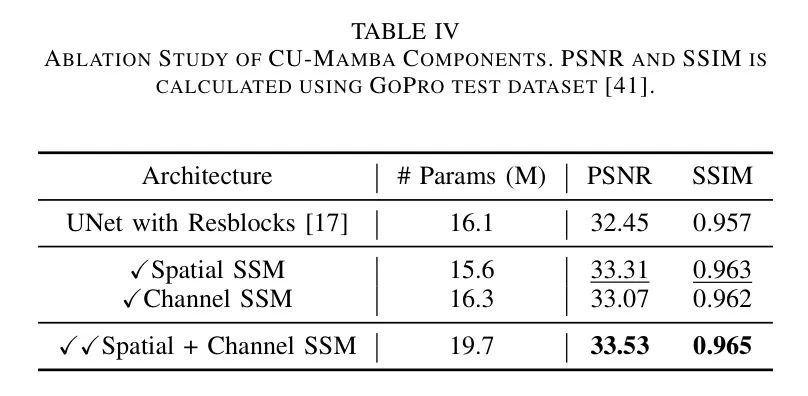
作者对CU-Mamba的空间和通道SSM模块进行了消融研究,以分析它们的影响。表4展示了在GoPro测试数据集[41]中,每种消融设置下的模型参数数量、SSIM和PSNR。独立应用时,空间SSM模块在提高模型性能方面比单独的通道SSM模块更有效。这表明长距离依赖在图像恢复中起着关键作用,而单独的通道SSM无法编码全局信息。另一方面,通道SSM促进了通道方向上的信息混合,因此它也在PSNR上比UNet Baseline 提高了0.62 dB。然而,当作者同时应用空间和通道模块时,CU-Mamba在PSNR上展示了最佳性能,达到33.53 dB。这突显了整合这两种选择性SSM模块以充分利用模型学习复杂、分层的图像表示能力的高效性。
V Conclusion
总之,作者提出了通道感知的U形Mamba(CU-Mamba)模型,该模型通过将U-Net框架与双向选择性状态空间模型相结合,来更好地理解和重建图像,从而提高了图像恢复的性能。广泛的实验表明,与现有方法相比,CU-Mamba表现出色,验证了作者所采用方法的效率和有效性。这项工作为图像恢复中的U-Net架构提供了新的视角,突显了在特征重建中空间和通道上下文的重要性,并为未来的研究和实际应用开辟了有前景的方向。
参考
[1].CU-Mamba: Selective State Space Models with Channel Learning for Image Restoration.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-04-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号