开发者视角看GLM-4-9B!Datawhale成员万字测评(二)

开发者视角看GLM-4-9B!Datawhale成员万字测评(二)

Datawhale
发布于 2024-06-08 08:16:42
发布于 2024-06-08 08:16:42
Datawhale干货 作者:邹雨衡,Datawhale成员
智谱于 2024年6月5日发布了其新一代开源模型——GLM-4-9B,以 9B 的体量,同时支持了 128K 长上下文推理、26种语言多语言支持,且在多个经典评测任务上都实现了超过以往同等开源模型的效果。在 GLM-4-9B 发布之初,我们抢先体验了其效果,并在多种开发者常见任务上进行评测,帮助开发者进一步了解该模型的使用和性能。
接口使用
智谱此次新推出的新模型 GLM-4-9B 的 API 和之前模型接口保持了一致的调用方式,只需将调用的模型切换为新版名称即可。我们可以基于文档给出的接口示例,定义一个简单的函数来获取模型输出:
import time
from zhipuai import ZhipuAI
def get_completion(prompt:str, history=None):
client = ZhipuAI(api_key="your api key") # 请填写您自己的APIKey
if history is None:
history = []
history.append({"role":"user", "content":prompt})
response = client.chat.asyncCompletions.create(
model="glm-4-9b", # 填写最新的模型
messages=history,
)
task_id = response.id
task_status = ''
get_cnt = 0
while task_status != 'SUCCESS' and task_status != 'FAILED' and get_cnt <= 40:
result_response = client.chat.asyncCompletions.retrieve_completion_result(id=task_id)
task_status = result_response.task_status
time.sleep(2)
get_cnt += 1
return result_response.choices[0].message.content整体使用上来说,API 响应速度较快,明显优于其他厂商的同类模型;接口调用方式也并不复杂,但是和主流的 request 访问方式有一些区别,初级开发者需要在示例代码基础上做一些小改动来适配自己的应用。
在之后的测评中,我们都会使用该函数来调用智谱的新模型;我们分别选取了国内外两个顶尖性能的模型接口 GPT-4 和 讯飞星火大模型v3.5 来进行横向对比,以分析该模型更适合在哪个场景下使用。调用 GPT-4 与讯飞星火大模型的代码此处就不一一展示了,在下文中我们会通过 get_compeletion 函数调用我们此次测评的主角——GLM-4-9B 模型,通过 get_completion_gpt 函数调用 GPT-4,并通过 get_completion_spark 调用讯飞星火大模型。
通用能力测评
接下来我们将分别从多个日常高频使用场景的方面来对此次的新模型进行评测。
首先是最基本的自我认知——你是谁:

可以看到,三个模型都有正确的自我认知;其中,由于其以英文为主场,GPT-4 的回复较简短且和其功能不匹配;星火的自我认知设计非常全面;GLM-4-9B 的回答强调了其来源,并简单说明其任务是针对用户的问题和要求提供适当的答复和支持。
场景一:专业论文翻译
对 LLM 来说,通用文本的翻译目前已不是太大的问题。但我们对翻译的需求更多在于一些专业领域、通用翻译不能触及的文本上,例如具有大量专业术语的论文和研究报告。考虑要适合读者判断多个模型的翻译结果好坏,且要是新发布的文本以保证文本没有在模型预训练中出现过,我们此处选用了 Meta 于 2024年5月发布的 LLaMA-3 技术报告中关于预训练规模的一段文本,分别要求三个模型给出翻译。原文为:
To effectively leverage our pretraining data in Llama 3 models, we put substantial effort into scaling up pretraining. Specifically, we have developed a series of detailed scaling laws for downstream benchmark evaluations. These scaling laws enable us to select an optimal data mix and to make informed decisions on how to best use our training compute. Importantly, scaling laws allow us to predict the performance of our largest models on key tasks (for example, code generation as evaluated on the HumanEval benchmark—see above) before we actually train the models. This helps us ensure strong performance of our final models across a variety of use cases and capabilities.
We made several new observations on scaling behavior during the development of Llama 3. For example, while the Chinchilla-optimal amount of training compute for an 8B parameter model corresponds to ~200B tokens, we found that model performance continues to improve even after the model is trained on two orders of magnitude more data. Both our 8B and 70B parameter models continued to improve log-linearly after we trained them on up to 15T tokens. Larger models can match the performance of these smaller models with less training compute, but smaller models are generally preferred because they are much more efficient during inference.
To train our largest Llama 3 models, we combined three types of parallelization: data parallelization, model parallelization, and pipeline parallelization. Our most efficient implementation achieves a compute utilization of over 400 TFLOPS per GPU when trained on 16K GPUs simultaneously. We performed training runs on two custom-built 24K GPU clusters. To maximize GPU uptime, we developed an advanced new training stack that automates error detection, handling, and maintenance. We also greatly improved our hardware reliability and detection mechanisms for silent data corruption, and we developed new scalable storage systems that reduce overheads of checkpointing and rollback. Those improvements resulted in an overall effective training time of more than 95%. Combined, these improvements increased the efficiency of Llama 3 training by ~three times compared to Llama 2.
GLM4-9B 给出的翻译为:

我们用红线划出了翻译的不准确或是不符合中文使用习惯的地方,可以看到,模型对深度学习领域的专业术语翻译都基本准确,略有几处翻译不符合中文使用习惯,但用于辅助论文阅读绰绰有余。 GPT-4 给出的翻译为:

可以看到,GPT-4 对一些专业术语的翻译出现了较大的偏差,如流水线并行化、扩展定律等;同时,GPT-4 给出的翻译结果不符合中文使用习惯的现象明显更严重,且出现了一些病句(如缺少主语、情感倾向不当等)。 星火大模型给出的翻译为:

星火和 GPT-4 的翻译结果类似。
因此,就辅助专业论文阅读而言,GLM-4-9B 在中文语境下使用起来更丝滑、顺畅。
场景二:创新文案编辑
我们经常会让 LLM 来帮我们思考一些创新性的文案,以满足人际交往、营销、运营等各类型的要求。在这里,我们假设自己是一个马上要支教完成的支教老师,需要给每一个学生留下一段祝福语,要求模型给出十条互不相同、富有创意、符合身份的祝福语。
GLM-4-9B 给出的结果为:

这十条祝福语从内容和文风来说,都比较符合我们的要求,且用词优美、意蕴生动,可用性比较高。但美中不足的是,同时看十条祝福语,就发现彼此之间会出现较高的相似程度,都是比喻的修辞手法,多样性有些不足。
GPT-4 给出的结果为:

GPT 的结果明显更俗套一些,文采相较 GLM 逊色不少;虽然十条之间的相似程度要更低一些,但是出现某几条之间高度相似(如第5、7、10条),多样性同样不足。
再看看星火给出的回答:

星火的回复同样文风卓彩,比 GPT 的结果更优美动人,且星火的祝福语更长,也更具多样性。但其结果也存在一个问题——引申开每一条对应了一个科目,整体看上去很好,但如果考虑到我们是给每一个学生写一条祝福语,会有失偏颇。
因此,在生成创新文案这个场景下,三者各有所长,但都有一些短期内难以弥补的缺陷,想要在这个场景下直接高质量满足更多人群的需求,可能还需要期待模型能力的进一步提升。
场景三:代码生成
作为程序员、开发者,对辅助代码生成的任务一定充满期待。在这个场景下,同样为避免“作弊”现象,我们选用了力扣网站上的周赛题目,以最大程度保证模型在预训练过程中没有见过该题的答案。由于 LLM 在代码生成的场景下能力还比较有限,我们选择了一道不算特别困难的题目:
给你一个整数数组 nums。
返回两个(不一定不同的)质数在 nums 中 下标 的 最大距离。
示例 1:
输入:nums = [4,2,9,5,3]
输出:3
解释:nums[1]、nums[3] 和 nums[4] 是质数。因此答案是 |4 - 1| = 3。
示例 2:
输入:nums = [4,8,2,8]
输出:0
解释:nums[2] 是质数。因为只有一个质数,所以答案是 |2 - 2| = 0。
提示:
1 <= nums.length <= 3 * 105 1 <= nums[i] <= 100 输入保证 nums 中至少有一个质数。
你需要完成的代码:
class Solution: def maximumPrimeDifference(self, nums: List[int]) -> int:
以上是我们给到模型的 Prompt 全文,接下来我们会分别用三个模型生成的代码“交卷”,来对比模型的代码生成能力。
GLM-4-9B 生成的 Python 代码如下:
class Solution:
def maximumPrimeDifference(self, nums: List[int]) ->int:
ans = 0
lastp = -1
for x in nums:
if self.isprime(x):
if lastp != -1:
ans = max(ans, x - lastp)
lastp = x
return ans
def isprime(self, x: int) ->bool:
if x < 2:
return False
for i in range(2, int(x ** 0.5) + 1):
if x % i == 0:
return False
return True在评测中,通过了 171/904 个测试用例,算是部分完成。
GPT-4 生成的 Python 代码如下:
class Solution:
def maximumPrimeDifference(self, nums: List[int]) -> int:
def is_prime(n):
if n < 2:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
min_prime_index = float('inf')
max_prime_index = float('-inf')
for i, num in enumerate(nums):
if is_prime(num):
min_prime_index = min(min_prime_index, i)
max_prime_index = max(max_prime_index, i)
return max_prime_index - min_prime_index可以看出,GPT-4 生成的代码更加优美、符合编程惯例,且评测通过了全部测试用例,证明 GPT-4 在代码生成领域确实具备最突出的能力。
讯飞星火生成的 Python 代码如下:
class Solution:
def maximumPrimeDifference(self, nums: List[int]) ->int:
ans = 0
lastp = -1
for x in nums:
if self.isprime(x):
if lastp != -1:
ans = max(ans, x - lastp)
lastp = x
return ans
def isprime(self, x: int) ->bool:
if x < 2:
return False
for i in range(2, int(x ** 0.5) + 1):
if x % i == 0:
return False
return True与 GLM-4-9B 的结果几乎完全一致,也同样通过了 171/904 个测试用例。
从上述结果来看,在代码生成领域,GPT-4 还是要更胜一筹,而 GLM-4-9B 与星火大模型v3.5 持平。
场景四:代码解释
对辅助编程而言,模型仅会写代码还不够,还需要能够读代码,对专业的代码进行解释。我们选取了用于开源 LLM 本地微调的一段 Python 代码,分别要求三个模型“尽可能详细”地解释代码,原片段如下:
def process_func(example):
MAX_LENGTH = 384
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(f"<|im_start|>system\n现在你要扮演皇帝身边的女人--甄嬛<|im_end|>\n<|im_start|>user\n{example['instruction'] + example['input']}<|im_end|>\n<|im_start|>assistant\n", add_special_tokens=False)
response = tokenizer(f"{example['output']}", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}GLM-4-9B 给出的解释如下:

模型给出的解释基本没有错误,说明对代码是有一定理解的——但每一步解释的都比较粗浅,没有深入地解释背后的逻辑及原因,读者很容易看完仍然难以理解,还有所不足。
GPT-4 同样在代码解释任务上展现出了更好的表现:

相较 GLM-4-9B 略显死板的解释,GPT-4 的解释明显更深入,适合读者学习。
而星火大模型的表现如下:

与 GLM-4-9B 的结果类似,都和 GPT-4 的结果还有一定距离。
综上来看,在辅助编程领域,GPT-4 还有着最大的性能优势。
场景五:逻辑推理
逻辑推理能力往往是衡量模型性能的重要标准,其决定了模型在求解数学题、完成复杂任务等方面上的能力。在这里,我们选择了一道逻辑推理题来让模型进行推理,从而对比三个模型的逻辑推理能力。原题如下:
有一个很古老的村子,这个村子的人分两种,红眼睛和蓝眼睛,这两种人并没有什么不同,小孩在没生出来之前,没人知道他是什么颜色的眼睛,这个村子中间有一个广场,是村民们聚集的地方,现在这个村子只有三个人,分住三处。在这个村子,有一个规定,就是如果一个人能知道自己眼睛的颜色并且在晚上自杀的话,他就会升入天堂,这三个人不能够用语言告诉对方眼睛的颜色,也不能用任何方式提示对方的眼睛是什么颜色,而且也不能用镜子、水等一切有反光的物质来看到自己眼睛的颜色,当然,他们不是瞎子,他们能看到对方的眼睛,但就是不能告诉他!他们只能用思想来思考,于是他们每天就一大早来到广场上,面对面的傻坐着,想自己眼睛的颜色,一天天过去了,一点进展也没有。直到有一天,来了一个外地人,他到广场上说了一句话,改变了他们的命运,他说,你们之中至少有一个人的眼睛是红色的。说完就走了。这三个人听了之后,又面对面的坐到晚上才回去睡觉,第二天,他们又来到广场,又坐了一天。当天晚上,就有两个人成功的自杀了!第三天,当最后一个人来到广场,看到那两个人没来,知道他们成功的自杀了,于是他也回去,当天晚上,也成功的自杀了!根据以上,请说出三个人的眼睛的颜色,并能够说出推理过程!GLM4-9B 给出的推理如下:

可以看出,GLM-4-9B 的推理过程是完全正确的!
GPT-4 给出的推理如下:

GPT-4 的整个推理逻辑都是混乱的,看似有模有样,实则一窍不通,基本每一步推理之间都无法成立。
因此,GLM-4-9B 的逻辑推理能力同样是其的主要优势之一。
长文本能力测评
GLM-4-9B 的一大特点是对长文本的理解能力,最大能支持 128K 的上下文输出。在此,我们通过一些实际示例来测评其长文本能力。我们首先下载了《红楼梦》的前二十四回内容,以纯文本的形式给到模型,要求模型根据小说回答相关问题。根据统计,我们输入的文本字符数达到 159K。
我们提出的第一个问题是,蕙香(贾宝玉的丫头之一)的原名是什么?相关原文在小说第二十一回《贤袭人娇嗔箴宝玉 俏平儿软语救贾琏》中:
正闹着,贾母遣人来叫他吃饭,方往前边来。胡乱吃了半碗,仍回自己房中。只见袭人睡在外头炕上,麝月在旁边抹骨牌。宝玉素知麝月与袭人亲厚,一并连麝月也不理,揭起软帘自往里间来。麝月只得跟进来。宝玉便推她出去,说:“不敢惊动你们。”麝月只得笑着出来,唤两个小丫头进来。宝玉拿一本书,歪着看了半天,因要茶,抬头只见两个小丫头在地下站着,一个大些的生得十分水秀。宝玉便问:“你叫什么名字?”那丫头便说:“叫蕙香。”宝玉便问:“是谁起的?”蕙香道:“我原叫芸香的,是花大姐姐改了蕙香。
而即使在如此上的上下文中的一句话,GLM4-9B 也做到了很好的捕捉:
更进一步,我们提出需要概括性回答的问题:秦可卿总共在哪几回出现过?分别做了些什么?模型回答为:

可以看到,模型成功地判断出了每节的主要内容且秦可卿是否出现过。但是,从十六回往后,秦可卿都没有出现过,但模型都列出了每回的内容并强调了“秦可卿的名字并未出现”,说明在长上下文的情况下,模型对用户的指令还是会出现一定的困惑和理解失能。
我们再来测试一下《西游记》。这次我们直接读取全本《西游记》,取前 128K 的字符文本输入给模型,然后要求它给出“文中孙悟空第一次见到唐僧的原文”。模型给出的结果为:

可以看出,确实是《西游记》大圣与唐僧初相逢的原文,说明模型理解指令并摘抄的能力在 128K 的上下文上仍然强悍。
我们还可以测试一下自制探针,我们在文中中间部分(128K 的中间)随机插入一句“今天是 2024年6月3日”,然后询问模型今天的日期,它能够正确地捕捉到这一个信息:
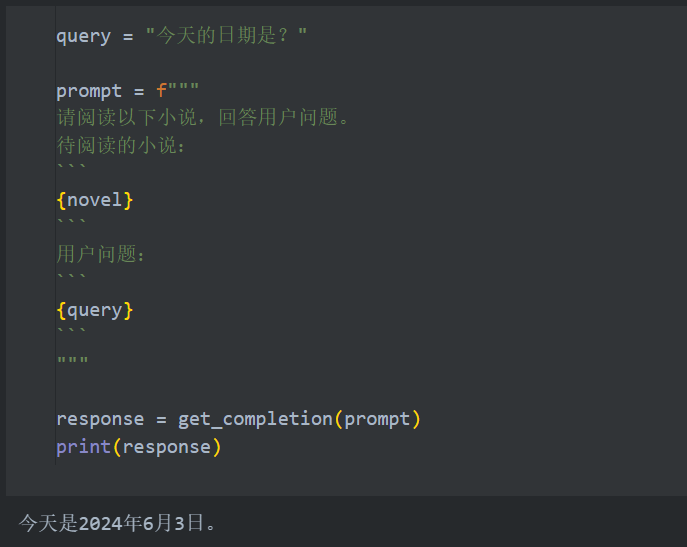
这都说明模型在长文本的提取、理解、阅读上具有极强的能力。
考虑到《红楼梦》、《西游记》作为经典名著,模型可能在预训练阶段见过的问题,我们选择了一本经典网络小说《诡秘之主》来进一步测试。同样的,我们取书中的前 128K 字符的内容。我们首先要求其列举出现过的超凡序列及能力(小说中设定的特殊能力):

如果有读过这本小说的读者可以发现,列举的内容基本和小说原文一字不差,且成功地展示了小说前 128K 字符出现过的几乎所有超凡序列。但是,如果我们进一步要求其总结文中的超凡力量设定:
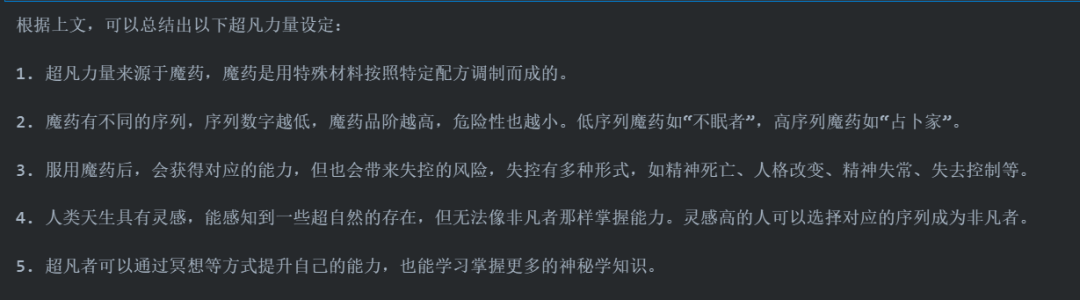
会发现,模型的总结大致贴合文中内容,但细致、深入程度明显不足,且容易出现一些和原文内容冲突的内容。说明在需要对大跨度的上下文进行概括性总结的任务上,模型还无法支持到 128K 的长度。
我们还可以测试一下更难的文本内容。我们选择了由 Datawhale 出品的大模型开源教程《Self LLM——开源大模型食用指南》,从中挑了一个章节,将其中所有文本线性输入到模型中,然后尝试询问其一些文本中提到的技术问题。根据计算,我们输入的所有文本长度在 45K 字符左右。我们询问的问题是,如何把 ChatGLM 接入 LangChain(输入一共十多个文件中,有一个文件是讲解这个技术的),然而,模型出现了困惑,其输出的结果全部成了感叹号:
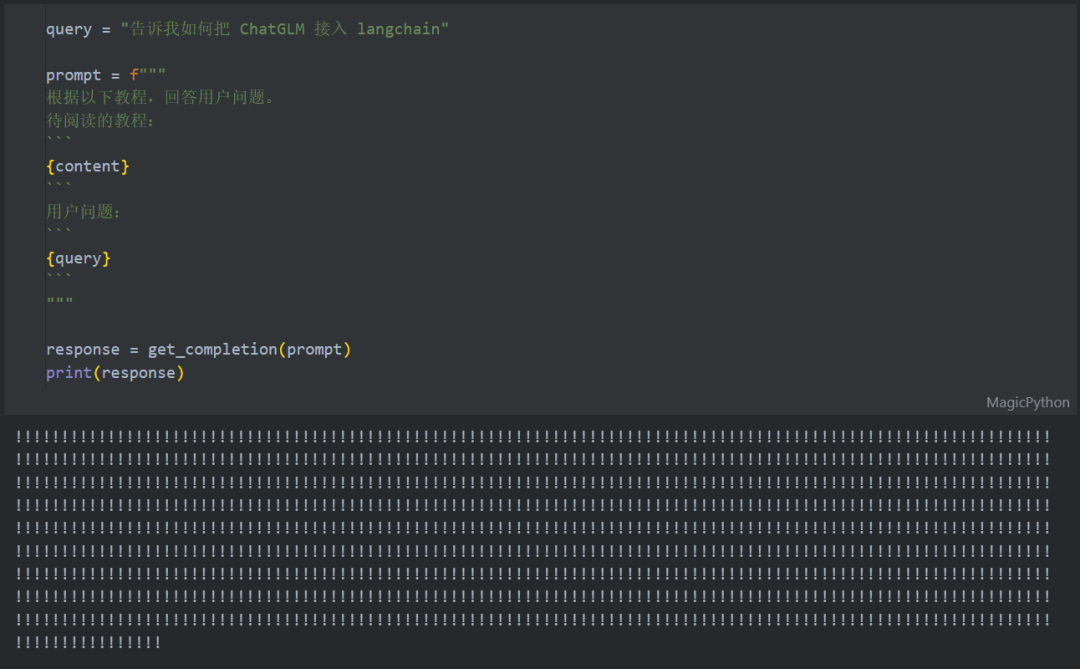
综上可见,GLM-4-9B 在长文本的提取、特定知识点抓取等任务上表现非常好,覆盖几十万汉字文本没有问题;但在长文本的概括、或是一些比较专业的长文本上的表现还有待加强,可用性不足。
应用展望
根据上述评测,可以看出 GLM-4-9B 虽然模型体量较小,但却有着不逊色于其他通用大模型的能力,尤其是在中文文本生成、逻辑推理等方面,更优于 GPT-4。小模型的优点在于较小的部署、推理成本与更快的推理速度,更适用在一些强速度要求的应用上。同时,GLM-4-9B 强悍的长文本能力更是对 RAG、Multi_Agent 等框架有着重要的作用。结合 GLM-4-9B 的特点,考虑到目前大模型应用开发的主要趋势,以下几个方向的应用开发者可以更多地将 GLM-4-9B 纳入考虑:
- 辅助论文阅读。从评测中我们可以看出,GLM-4-9B 具有比 GPT-4 更为强悍的翻译能力,且对专业术语的翻译较为准确。论文阅读往往需要输入大量 token 作为翻译或是归纳的原文,因此调用成本也较高,而 GLM-4-9B 较小的体量使其能够帮助开发者节省大量的成本;
- 企业知识库助手。GLM-4-9B 在长文本知识点提取方面能够达到 128K 甚至更大的上下文长度,这在企业知识库构建中具有极大的优势。企业往往有海量的内部文档,员工需要从中找到自己所急需的1~2条相关知识,时间成本非常高。而 GLM-4-9B 的长文本能力非常适合应用在这一场景下,因此基于 GLM-4-9B 打造企业知识库助手具有较大的拓展空间;
- 任务规划智能体。在 Multi-Agent 框架下,往往需要多种类型的智能体协助完成任务。在完成一个任务的过程中,往往需要对智能体进行多次调用。其中,任务规划智能体由于需要进行任务的拆解、工具调用,是一个类似大脑的角色,往往会有更高的调用次数。而 GLM-4-9B 较强的逻辑推理能力、较小模型体量带来的快速推理和较低成本,都使其非常适合该任务;
- 特定业务的微调基座。GLM-4-9B 之后也会开放微调功能,具有长上下文能力、体量合适,其非常适合作为特定业务(例如搜索优化、文本生成等)等基座模型,在 GLM-4-9B 基座上进行微调,更容易达到性能与效率的平衡点。 一起“点赞”三连↓
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号