LayerMerge: 一种新颖的深度压缩方法,移除激活层和卷积层,实现推理加速的同时最小化性能损失!
LayerMerge: 一种新颖的深度压缩方法,移除激活层和卷积层,实现推理加速的同时最小化性能损失!


最近的工作表明,减少卷积神经网络中的层数可以在保持网络性能的同时提高效率。现有的深度压缩方法移除了冗余的非线性激活函数,并将连续的卷积层合并为单一层。 然而,这些方法存在一个关键缺陷;合并层的核尺寸变大,显著削弱了由于减少网络深度而获得的延迟降低。作者展示,通过联合剪枝卷积层和激活函数可以解决这个问题。 为此,作者提出了 LayerMerge,一种新颖的深度压缩方法,它选择移除哪些激活层和卷积层,以实现期望的推理加速同时最小化性能损失。 由于相应的选择问题涉及指数级的搜索空间,作者构建了一个新颖的代理优化问题,并通过动态规划高效地解决它。 经验结果表明,作者的方法在多种网络架构上,无论是图像分类任务还是生成任务,都一致优于现有的深度压缩和层剪枝方法。 作者在https://github.com/snu-mllab/LayerMerge发布了代码。
1 Introduction
卷积神经网络(CNNs)在各种基于视觉的任务中表现出色,如分类、分割和目标检测(Krizhevsky等人,2012年;Chen等人,2018年;Girshick,2015年)。近来,采用基于U-Net架构的扩散概率模型在各种高质量图像生成任务中显示出极大的性能。然而,随着这些模型规模的扩大,它们在复杂视觉任务上的出色能力是以越来越高的计算资源和推理延迟为代价的(Nichol和Dhariwal,2021年;Liu等人,2022年)。
解决这一问题的有效方法是结构化剪枝,这包括移除模型中冗余的规则权重区域,如通道、滤波器和整个层,以使模型在不要求专用硬件的情况下更高效,同时保持其性能。特别是,通道剪枝方法移除CNN中的冗余通道。尽管这些方法在加速模型和降低复杂性方面取得了显著改进,但与减少网络层数的方法相比,它们在通道数量较少的架构上效果不佳。减少层数的一种方法是层剪枝,它移除网络中的整个层。尽管这些方法实现了更大的加速因子,但由于它们在移除参数时过于激进,往往会导致性能严重下降。
为此,一项名为深度压缩或深度缩减的研究提出,通过移除冗余的非线性激活函数,并将结果连续的卷积层合并为一个层,以实现更高的推理加速。
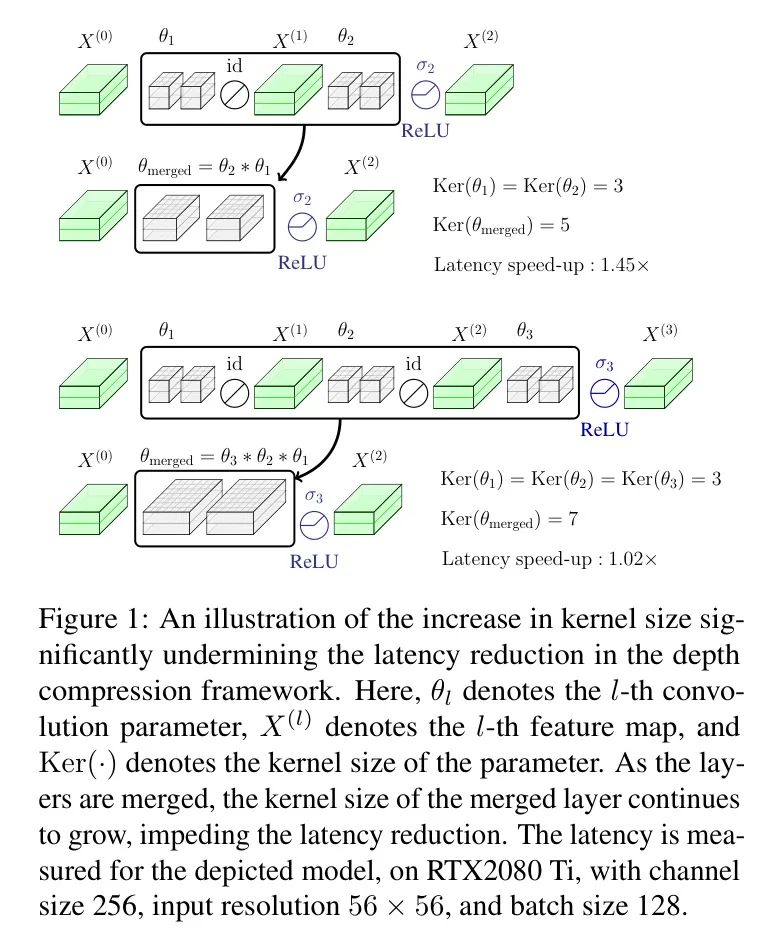
然而,这些方法有一个根本的局限性;合并连续的卷积层会导致合并层 Kernel 大小的增加,这大大阻碍了通过减少网络深度获得的延迟降低(图1)。
在这项工作中,作者认为现有深度压缩方法的这一关键缺点可以通过扩展搜索空间并联合优化非线性激活层和卷积层的移除选择来解决(图2)。由于相应的优化问题涉及指数数量的潜在解决方案,作者提出了一种新颖的替代优化问题,可以通过高效的动态规划(DP)算法精确求解。

具体来说,作者做出了以下贡献:
- 作者提出了一种新颖的深度压缩方法,引入了一种新的剪枝模式;除了激活层外,还移除卷积层。这种表述包括了现有深度压缩方法的搜索空间,并使作者能够绕过合并卷积层 Kernel 大小的增加(图2)。
- 作者提出了一种替代优化问题,可以通过DP算法精确求解。作者进一步开发了一种高效的方法来构建DP查找表,利用问题的内在结构。
- 作者进行了广泛的实验,并在不同的网络(包括ResNet、MobileNetV2和DDPM)的图像分类和生成任务上证明了作者方法的有效性(He等人,2016年;Sandler等人,2018年;Ho等人,2020年)。
2 Preliminaries
令 和 分别表示第 个卷积层和第 个激活层。这里, 表示卷积层 的参数。一个 层的CNN可以表示为 ,其中 表示迭代函数组合,最后一个激活函数 设置为恒等函数。
深度压缩方法消除了不那么重要的非线性激活层,然后通过对其参数应用卷积操作,将连续的卷积层合并为一个单独的层(Dror等人,2022;Fu等人,2022;Kim等人,2023)。这种方法利用了连续卷积层 可以表示为单个等效卷积层 的这一事实,其中 表示卷积操作。
然而,这种方法有一个基本的局限性;随着合并的层数增多,合并层的卷积核大小也会增加。这大大削弱了通过减少层数实现的延迟加速(图1)。为了说明这一点,让作者将合并层的卷积参数表示为 ,并假设所有卷积层都具有步长为 。那么,这个合并层的卷积核大小由以下公式给出:
其中 表示给定卷积参数的卷积核大小。为了解决这个问题,作者 Proposal 联合移除不重要的卷积层和非线性激活层(图2)。
3 LayerMerge
在本节中,作者提出了作者设计的深度压缩方法_LayerMerge_,旨在解决由于深度压缩导致的核大小增加问题,并寻找更高效的网络。作者首先制定了作者旨在解决的NP难子集选择问题。然后,作者提出了一个替代优化问题,该问题可以用一个高效的动态规划算法精确求解。之后,作者考察了作者的方法的理论最优性、复杂性和实际成本。
Selection problem
作者观察到,如果作者选择性地将某些卷积层替换为恒等函数(id),可以有效缓解由于合并层导致的核尺寸增大的问题。实际上,一个恒等层可以用一个的深度卷积层来表示,其中参数值设置为。作者将相应的卷积参数表示为,其中表示输入通道的数量。然后,从方程(1)中可以明显看出并不贡献核尺寸的扩展。
为此,作者提出优化两组层索引:用于激活层,用于卷积层,其中表示原始网络的深度。中的索引表示作者保留原始激活层的位置,而中的索引对应于保留原始卷积层的位置。对于任何不在中的层,作者将它的激活函数替换为id函数。类似地,如果一个层不在中,作者用恒等层替换其卷积层。
值得注意的是,当输入和输出特征图的形状不同时,去除一个卷积层并非易事。为了解决这个问题,作者定义了一组不可约卷积层索引,其中输入形状和输出形状不同。具体来说,作者将定义为,其中表示张量的形状,表示第层的特征图。然后,作者将的选择限制为的超集,即。
给定一个期望的延迟目标,作者的目标是选择和,以最大化在微调后所得模型的性能,同时满足合并后的延迟目标。作者以下列方式制定这个问题:
在以下内容中,我会将提供的英文论文文本翻译为简体中文:
最大化 {L-1]中的子集A和{L]中的子集C,关于\theta的最大值:\max_{A\subseteq[L-1],C\subseteq[L]}\max_{\theta}\ \mathrm{Perf} \left(\sum_{l=1}^{L}\left(\sigma_{A,l}\circ f_{C,\theta_{l},l}\right)\right) \tag{2}
受限于以下条件:
(不可约卷积) (替换激活) (替换卷积) (合并参数) T\left(\mathop{\cap}_{i=1}^{|A|}\left(\sigma_{a_{i}}\circ f_{ \hat{\theta}_{i}}\right)\right)<t_{0},
其中 表示迭代卷积操作,,,以及 表示集合 中按升序排列的元素。这里, 和 分别表示网络的性能和延迟。网络的性能定义为与任务相关的度量:对于分类任务为准确度,对于生成任务为负扩散损失(Ho等人,2020年)。指示函数 等于 (如果 ),否则等于 。作者用 表示根据集合 替换的第 个激活层,用 表示根据集合 替换的第 个卷积层。参数 是合并网络中的第 个卷积层。
注意,作者在合并目标之前使用了剪枝网络,而延迟约束应用于合并后的网络。这两个网络表示相同的函数并产生相同的输出,因此具有相同的表现目标。然而,在实践中,作者观察到,在微调完成后,仅在推理时合并连续的卷积层效果更好。作者选择在合并目标之前使用网络,以强调这一点。
Surrogate optimization problem
解决一般问题(2)是NP难的。作者建议为每个合并层分配一个重要性值,并将重要性值的总和作为替代目标进行优化。这是文献中常用的近似方法(Shen等人,2022年;Frantz和Alistarh,2022年;Kim等人,2023年)。作者还用层状延迟的总和近似合并网络的总体延迟(Cai等人,2019年;Shen等人,2022年)。作者所面临的主要挑战是,由于在上的联合优化而产生的潜在合并层的组合数量呈指数级增长。为此,作者开发了一种有效的方法来衡量延迟和重要性值,利用问题的内在组合结构。随后,作者使用动态规划算法在多项式时间内计算替代问题的最优解。
延迟成本作者在所有可能的合并层上构建一个延迟查找表。一种直接的方法是构建一个包含所有,i<jt[i,j,c]的表,其中每个条目表示通过合并从(i+1)层到第j层并在根据c替换卷积层后得到的层的延迟。然而,这种方法不可行,因为它需要对指数级的可能集合c\cap(i,j]的延迟进行测量。< p=""></j的条目t[i,j,c]的表,其中每个条目表示通过合并从(i+1)层到第j层并在根据c替换卷积层后得到的层的延迟。然而,这种方法不可行,因为它需要对指数级的可能集合c\cap(i,j]
为了解决这个问题,作者注意到的选择仅通过合并层 Kernel 的大小影响合并层的延迟,因为输入和输出通道的数量是固定的。为此,作者建议构建带有条目的延迟表,其中最后一个索引表示合并层的 Kernel 大小,由给出。
设为从层到第层合并后可能出现的合并 Kernel 大小的集合。注意,。因此,构建带有条目的延迟表需要的延迟测量,其中表示原始网络中 Kernel 大小的总和。这远低于构建带有条目的延迟表所需的测量。
重要性价值与延迟成本的情况类似,作者构建带有条目的重要性查找表。每个条目表示从层到第层合并得到的层的重要性,合并层具有 Kernel 大小。
作者将每个合并层的重要性值定义为在用合并层替换原始网络的相应部分后性能的变化。然而,多个的选择可能导致合并层中相同的 Kernel 大小,但在性能上会有所不同。
计算 的成本可以忽略不计。作者现在可以如下定义重要性 :
-\ \max_{\theta}\operatorname{Perf}\!\left(\underset{\underset{l =1}{\underbrace{\bigodot_{l=1}^{L}\big{(}\sigma_{l}\circ f_{\theta_{l}}\big{)} }}{\underbrace{\bigodot_{l=1}^{L}\big{(}\sigma_{l}\circ f_{\theta_{l}}\big{)} }}}\right). \tag{4}
作者使用 来归一化重要性值。这个选择是基于作者的经验观察,即使用正的重要性值会导致更好的性能,因为它倾向于具有更多激活层的解决方案。在实践中,为了估计第一个项,作者在微调网络几步后测量网络的性能。对于第二个项,作者使用预训练原始网络的性能。构建重要性表需要 次重要性值评估,这与所需的延迟测量次数相同。
优化问题在作者预先计算延迟和重要性查找表 和 之后,作者在延迟成本总和的约束下最大化合并层的重要性值之和。这可以表述如下:
算法 1 对于问题 (5) 的动态规划算法
(5) 受限于 \sum_{i=1}^{|A|+1}T[a_{i-1},a_{i},k_{i}]<t_{0},k_{i}\in="" k_{a_{i-1}a_{i}},
其中 , 与之前一样。给定问题(5)的一个解 ,作者保留的卷积层集合由 给出。
Dynamic programming algorithm
一旦作者构建了查找表和,作者就可以使用动态规划(DP)针对离散化的延迟值获得问题(5)的精确解。特别是,作者将查找表中的延迟值向下取整到最接近的值集,其中是一个表示离散化 Level 的大的自然数。
然后,作者考虑问题(5)的一个子问题,即在前层中,在延迟预算内最大化,如下所示:
(6) 受限于 \sum_{i=1}^{|A|+1}T[a_{i-1},a_{i},k_{i}]<t,k_{i}\in="" k_{a_{i-1}a_{i}},
其中且。作者定义为子问题(6)中可实现的对应最大目标值。然后给出了问题(5)中可实现的最高目标值。作者初始化对于,以及对于。然后,对于,DP算法的递归可以写为如下形式:
M[l,t]=\max_{0\leq l^{\prime}<l,\,k\in k_{l^{\prime}l}}\left(="" \underbrace{m[l^{\prime},t-t[l^{\prime},l,k]]}_{\text{直到层的最优重要性总和}}\right.="" \left.+\underbrace{i[l^{\prime},l,k]}_{\text{最后一压缩层的重要性值}}\right).="" \tag{7}
作者在算法1中提出了问题(5)的DP算法。一旦作者计算出了最优集合和,作者就会在相应地替换层之后对网络进行微调。然后,在推理时,作者将所有在和之间的卷积层进行合并,对于所有。作者在算法2中概述了LayerMerge的整体流程。


Theoretical analysis
作者证明了所提出的动态规划(DP)算法能够最优地解决代理优化问题(5)。证明在附录B中给出。
定理3.1:算法1给出的解和是问题(5)的一个最优解。
动态规划算法的时间复杂度为。在实际应用中,动态规划算法效率极高,通常在CPU上几秒钟内即可完成。此外,作者的方法有效地计算了动态规划查找表,利用了问题的结构。值得注意的是,这可以以非常并行的方式完成。作者在附录C中报告了构建动态规划查找表的墙钟时间。
4 Experiments
在本节中,作者提供了实验结果,证明了作者的方法在不同网络结构和任务上的有效性。作者将方法应用于ResNet-34和MobileNetV2模型(He等人,2016;Sandler等人,2018)进行图像分类任务,以及DDPM模型(Ho等人,2020)进行图像生成任务。作者将在附录A中提供关于如何处理归一化层、步进卷积、填充、跳跃连接以及作者方法的网络特定实现细节的额外信息。
Baseline 方法作者比较了作者的方法与一种深度压缩方法和一种层剪枝方法,因为这两种方法都依赖于减少网络层数以加速网络,就像作者的方法一样。在附录E中,作者还包括了与知识蒸馏方法的比较。对于深度压缩 Baseline ,作者使用了Kim等人(2023年)的现有最佳工作,作者将其表示为_Depth_。
现有的层剪枝方法在剪枝过程中并未直接考虑延迟(Jordao等人,2020;Chen和Zhao,2018;Elkerdawy等人,2020)。为了弥补这一空白,作者提出了一个专门针对层剪枝的作者方法的变体,作者将其作为层剪枝的 Baseline 。
具体来说,作者为每个卷积层分配一个重要性值和一个延迟成本。卷积层的重要性值定义为在原始网络中将该层替换为恒等层,然后对其进行少量步骤的微调所导致的性能变化。与_LayerMerge_一样,作者通过层级的延迟和重要性值的总和来近似整个网络的延迟和重要性。作者解决以下替代问题:
\text{subject to}~{}\sum_{l\in C}T[l]<t_{0}.\qquad\text{(延迟约束)}
问题(8)是一个0-1背包问题,可以通过动态规划算法在时间内准确解决离散化的延迟值,其中表示离散化水平。作者将这种方法称为_LayerOnly_。
此外,作者还与每种网络的通道剪枝 Baseline 进行了比较。请注意,通道剪枝与深度压缩是正交的方法。尽管如此,作者包括通道剪枝结果以研究与在不同类型的网络中减少宽度相比,减少层数的有效性。作者在ResNet-34上与HALP (Shen等人,2022)进行比较,在MobileNetV2上与AMC和MetaPruning (He等人,2018; Liu等人,2019)进行比较,在DDPM上与Diff-Pruning (Fang等人,2023)进行比较。
对于ResNet-34,作者使用他们公开可用的代码应用深度压缩和通道剪枝 Baseline 。对于所有压缩方法,作者也使用Wightman等人(2021)原始网络的预训练权重。对于MobileNetV2,作者报告了原始论文(Kim等人,2023)中的深度压缩 Baseline 结果。对于通道剪枝 Baseline ,作者使用与他们的优化模型相同的通道比例来剪枝每个层的通道,这些通道来自他们开源的代码。作者使用来自Kim等人(2023)公共代码的原始网络的预训练权重,以确保公平比较。对于DDPM,作者使用他们开源的代码(Kim等人,2023; Fang等人,2023)应用深度压缩和通道剪枝 Baseline 。对于DDPM中的所有压缩方法,作者使用来自Song等人(2021)原始网络的预训练权重。在所有网络中,作者使用相同的微调计划在每张表中比较压缩结果,以保证公平性。
最后,作者提供了关于在激活层和卷积层联合优化重要性方面的消融研究,作者将作者的方法与依次应用深度然后是LayerOnly进行了比较。在这一节中,作者将通过Depth、LayerOnly和LayerMerge获得的每个压缩模型分别称为Depth-_p%_、LayerOnly-_p%_和LayerMerge-_p%_。在这里,_p%_的计算公式为,其中是选定的延迟预算,是原始模型的延迟。
实验设置作者在RTX2080 Ti GPU上构建了每种方法的延迟查找表,并报告了在同一设备上测量到的压缩网络的墙钟延迟加速比。作者将在附录C中提供关于测量过程的详细信息。值得注意的是,作者以两种不同的格式测量网络的延迟,分别是PyTorch格式和TensorRT编译格式。在测量延迟加速比时,对于ImageNet数据集作者使用128的批处理大小,对于CIFAR10数据集使用64,遵循Kim et al. (2023); Shen et al. (2022); Fang et al. (2023)的相同测量协议。对于ResNet-34,作者按照HALP(Shen et al., 2022)的微调方法对每个剪枝网络进行90轮的微调。对于MobileNetV2,作者按照Kim et al. (2023)的微调方法进行180轮的微调。对于DDPM,作者遵循Diff-Pruning(Fang et al., 2023)的微调和采样方法,但将学习率设置为,因为这样可以获得更好的性能。作者在表1到6中展示了一组具有代表性的结果。对于额外的结果,请参见附录E。
Classification task results
在本节中,作者评估了不同的剪枝方法在ResNet-34、MobileNetV2-1.0和MobileNetV2-1.4模型上的性能,所使用的基准数据集为ImageNet(He等人,2016年;Sandler等人,2018年;Russakovsky等人,2015年)。作者报告了在验证集上评估的经过微调后的压缩模型的最终top-1准确率及其相应的延迟加速。
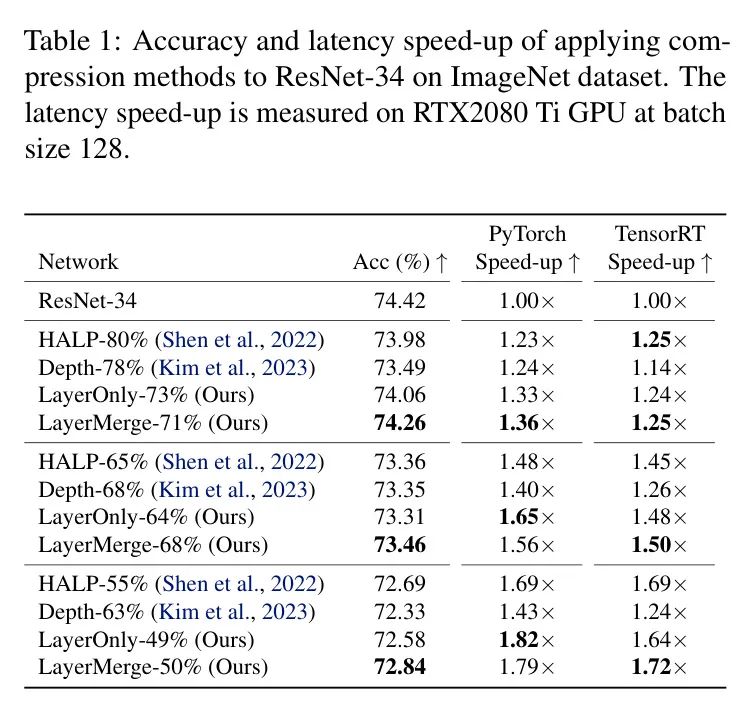
ResNet-34表1总结了ResNet-34上不同的压缩结果。HALP-%指的是通过HALP设置延迟预算为原始模型延迟的%得到的剪枝模型。LayerMerge超过了现有的通道剪枝和深度压缩 Baseline 。具体来说,作者在PyTorch中实现了1.10倍的加速,比深度压缩 Baseline (将LayerMerge-71%与Depth-78%相比较)准确率高出了0.77个百分点。值得注意的是,作者方法的层剪枝变体在ResNet-34上的表现与LayerMerge相当。这主要是因为ResNet-34更适合层剪枝而不是深度压缩。实际上,当应用于ResNet-34时,LayerMerge经常选择剪枝卷积层而不是激活函数。
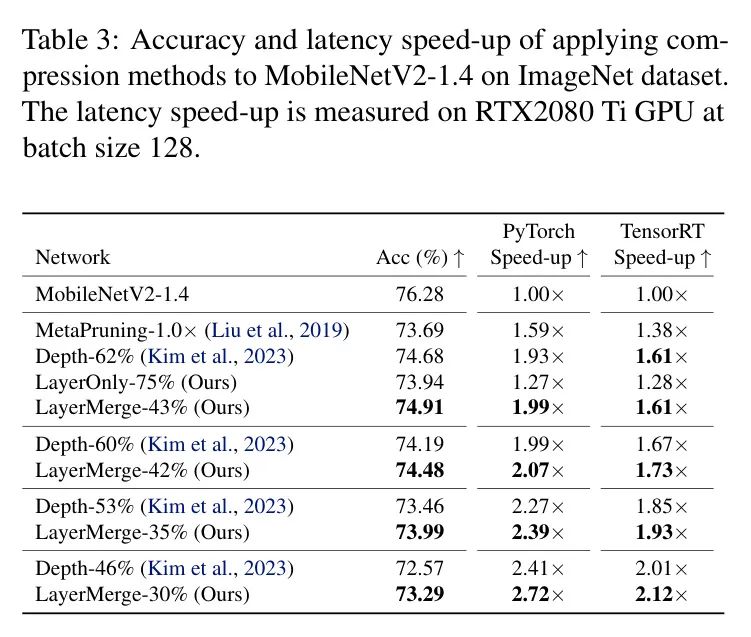
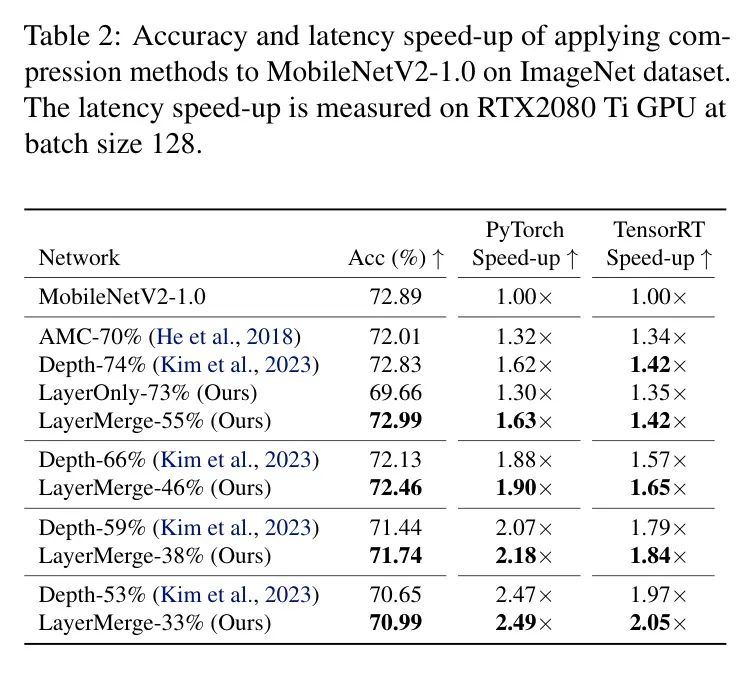
MobileNetV2表2展示了MobileNetV2-1.0上的各种压缩结果。AMC-%表示通过设置FLOPs预算为原始模型的%得到的由AMC剪枝后的模型。LayerMerge超过了现有的通道剪枝和深度压缩 Baseline ,以及作者的层剪枝变体。特别是,作者在PyTorch中实现了1.63倍的加速,且没有从原始网络中损失准确率(LayerMerge-55%)。表3进一步展示了MobileNetV2-1.4上的压缩结果。LayerMerge超过了现有方法,在相对于深度压缩 Baseline 获得更大加速的同时,准确率还提高了0.23个百分点(将LayerMerge-43%与Depth-62%相比较)。效率的提升源于它独特的层剪枝和合并能力,如图2所示。
Generation task results
在本节中,作者评估了不同的剪枝方法在DDPM模型在CIFAR10数据集上的性能。作者使用标准的Frechet Inception Distance(FID)度量(Heusel等人,2017)来衡量性能。作者报告了在验证集上评估的经过微调后的压缩模型的最终FID以及相应的延迟加速。表4报告了DDPM上的不同压缩结果。LayerMerge相比于现有的深度压缩 Baseline 和作者方法的层剪枝变体,显示出更优越的性能。特别是,与深度压缩 Baseline 相比,作者在FID指标较低的情况下实现了1.08的加速。通道剪枝 Baseline Diff-Pruning在此处显示出比LayerMerge更优越的性能(表5)。这可能是由于DDPM比其他模型具有更多的通道冗余。
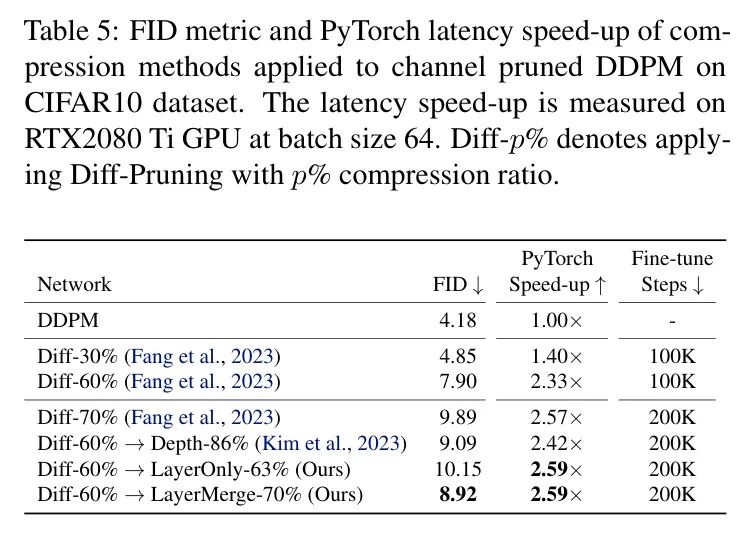

通道剪枝的DDPM作者注意到通道剪枝和深度压缩方法可以联合应用。因此,作者在表5中包含了将作者的方法应用于通过Diff-Pruning获得的通道剪枝DDPM模型的结果(Fang等人,2023)。Diff-%表示通过在每个层中移除%的通道,使用Diff-Pruning获得的剪枝模型。结果显示,将作者的方法与Diff-Pruning结合使用,比单独依赖Diff-Pruning实现了更大的加速,并且作者的方法在这种设置下也始终优于深度压缩和层剪枝 Baseline 。
Ablation studies
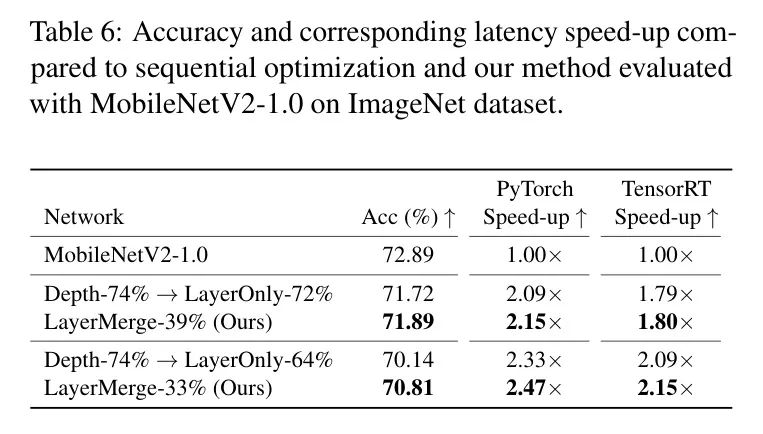
作者的方法联合优化了激活层和卷积层的选取以进行剪枝。另一种方法是逐个独立地优化每种类型层的选取。在表6中,作者将作者的方法与在ImageNet数据集上先应用Depth再应用LayerOnly的顺序优化方法进行了比较。作者的方法优于顺序优化 Baseline ,突显了作者联合优化方法的重要性。作者将在附录D中提供详细信息。
5 Related Work
非结构化剪枝非结构化剪枝方法移除网络中的单个神经元以实现网络稀疏性。在这一研究方向上,与作者的方法最接近的是Frantar和Alistarh(2022年),他们提出了一种动态规划算法,该算法在给定的延迟约束下确定逐层的稀疏性。然而,非结构化剪枝方法需要专用硬件才能实现计算节省。
通道剪枝相比之下,结构化剪枝方法,包括移除多余的规则权重区域,可以在现成的硬件上实现计算节省。这类方法包括通道剪枝方法,它们移除卷积神经网络中的冗余通道。Aflalo等人将此表述为一个背包问题,在给定的FLOPs预算下最大化通道重要性值的总和。同样,Shen等人提出了另一个背包问题,在目标设备上的延迟约束下最大化通道重要性值的总和。
层剪枝层剪枝方法旨在通过完全移除某些卷积层来制作更浅的网络。然而,它们在移除参数时的激进性质导致在高度压缩比下性能大幅下降。
深度压缩相反,深度压缩方法专注于消除不重要的非线性激活层,然后合并连续的卷积层以减少网络的深度。特别是,Dror等人提出训练一个软参数,该参数控制每层的非线性强度,并通过额外的损失对软参数的绝对值进行惩罚。最近,Kim等人提出通过动态规划算法在延迟约束下最大化合并层的重要性值之和。然而,这一研究方向存在一个根本性的缺点,因为合并层会导致合并层的核尺寸增大。Fu等人绕过了这个问题,因为他们只考虑在倒置残差块内合并。然而,这种限制不仅将他们的方法的应用限制在移动优化的CNNs上,而且限制了其性能。实际上,Kim等人已经证明了他们的方法优于。
6 Conclusion
作者提出了_LayerMerge_,一种新颖的高效深度压缩方法,它同时剪枝卷积层和激活函数,以达到期望的目标延迟,同时最小化性能损失。
作者的方法避免了现有深度压缩方法中合并层 Kernel 尺寸增加的问题。
在多种设置中,它一致地优于现有的深度压缩和层剪枝 Baseline 。
参考
[1].LayerMerge: Neural Network Depth Compression.
腾讯云开发者
