突破 LSTM 核心精髓 !!

突破 LSTM 核心精髓 !!

Python编程爱好者
发布于 2024-07-22 20:23:29
发布于 2024-07-22 20:23:29
Hi,我是Johngo~
今儿和大家聊聊 LSTM !~
先用大白话,和大家进行了一个简短的交流~
想象一下,你正在听一个故事。为了理解这个故事,你需要记住之前发生的事情。比如,如果故事一开始提到了一个名叫小红的女孩,那么当她再次出现时,你需要记住她是谁,做过什么事。
LSTM 就像是你的大脑在听故事时的记忆功能。它能记住重要的信息,并且可以忘记不重要的细节。LSTM 是一种特别的神经网络,用来处理和预测时间序列数据(例如文本、音频或股票价格),因为它能有效地记住之前的信息。
我们可以把LSTM想象成有三个开关的小盒子:
- 记住开关:这个开关决定了当前的信息是否要记住。
- 忘记开关:这个开关决定了之前的信息是否要忘记。
- 输出开关:这个开关决定了要输出多少记住的信息。
举个例子,如果我们在教一个机器人记住天气预报:
- 今天下雨,明天下雪,大后天晴天。
- 机器人需要记住“下雨”和“下雪”,因为这些信息会影响它是否带伞出门。
- 但是,关于前天的天气,它可以选择忘记,因为这对现在的决定没有影响。
LSTM 就是通过这三个开关来管理它的记忆的,确保它记住了重要的信息,忘记了不重要的细节,并在需要的时候输出正确的信息。
在这些解释之后,下面,给出详细的核心逻辑以及一个完整的案例。
核心组成
LSTM(长短期记忆网络)的核心逻辑是通过设计的门控结构来控制信息的流动和记忆的更新。
这种门控机制使得LSTM能够有效地处理和记忆长期依赖关系,是一种特殊的循环神经网络(RNN)架构。
LSTM的核心组成部分
- 输入门(Input Gate): 控制新输入数据进入记忆单元的量。
- 遗忘门(Forget Gate): 控制之前的记忆状态中哪些信息应该被遗忘。
- 输出门(Output Gate): 决定从当前记忆状态中输出多少信息。
- 记忆单元(Cell State): 存储和传递记忆信息的长期状态。
LSTM 公式说明
输入门(Input Gate)
输入门决定更新记忆单元的程度。它由一个 sigmoid 函数控制,输出值范围在 0 到 1 之间,用来确定更新量。
- 输入门的计算公式:
其中:
- 是当前时刻的输入向量,
- 是前一时刻的隐藏状态(或记忆状态),
- 和 是输入门的权重矩阵和偏置向量,
- 是 sigmoid 函数。
遗忘门(Forget Gate)
遗忘门决定在当前时刻应该从记忆状态中忘记多少信息。同样由 sigmoid 函数控制。
- 遗忘门的计算公式:
其中:
- 和 是遗忘门的权重矩阵和偏置向量。
更新记忆单元(Cell State)
通过结合输入门和记忆单元的更新来计算新的记忆状态。
- 记忆单元更新公式:
其中:
- 是前一时刻的记忆单元状态,
- 是当前时刻的候选记忆单元状态,通过 tanh 函数进行处理:
其中 和 是用来计算候选记忆单元的权重矩阵和偏置向量。
输出门(Output Gate)
输出门决定从当前记忆单元状态中输出多少信息到下一时刻的隐藏状态。
- 输出门的计算公式:
其中:
- 和 是输出门的权重矩阵和偏置向量。
隐藏状态(Hidden State)
隐藏状态是当前时刻的输出,它经过输出门的调节后输出到下一时刻。
- 隐藏状态的计算公式:
LSTM通过这些门控结构(输入门、遗忘门、输出门)和记忆单元(Cell State)来处理和记忆时间序列数据中的长期依赖关系。每个门控结构都通过学习得到自己的权重和偏置,从而决定了信息的流动和记忆的更新,使得LSTM在处理复杂序列数据时表现出色。
案例
这里,给大家实现一个简单的 LSTM 模型案例,使用 PyTorch 来实现 LSTM 模型,并结合一个实际的数据集来展示其应用。
首先,我们需要导入必要的库,并准备数据。假设我们使用的是某个时间序列数据集,可以是股票价格、天气数据等。这里简单起见,我们随机生成一些数据作为示例。
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 生成随机时间序列数据
np.random.seed(42)
data = np.sin(np.linspace(0, 100, num=1000)) + np.random.normal(0, 0.1, size=1000)
data = data[:, np.newaxis] # 转换成 (1000, 1) 的形状
# 划分训练集和测试集
train_size = 800
train_data = data[:train_size]
test_data = data[train_size:]
# 将数据转换成 PyTorch 的 Tensor
train_data = torch.FloatTensor(train_data).view(-1)
# 定义 LSTM 模型
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, input):
lstm_out, _ = self.lstm(input.view(len(input), 1, -1))
output = self.linear(lstm_out.view(len(input), -1))
return output[-1]
# 定义模型和优化器
input_size = 1
hidden_size = 64
output_size = 1
model = LSTM(input_size, hidden_size, output_size)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
epochs = 100
for epoch in range(epochs):
for i in range(len(train_data) - 1):
optimizer.zero_grad()
input_seq = train_data[i:i+1]
target = train_data[i+1:i+2]
output = model(input_seq)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 测试模型
model.eval()
test_input = torch.FloatTensor(test_data).view(-1)
predicted = []
with torch.no_grad():
for i in range(len(test_input)):
input_seq = test_input[i:i+1]
output = model(input_seq)
predicted.append(output.item())
# 可视化结果
plt.figure(figsize=(12, 6))
plt.plot(data, label='True Data')
plt.plot(range(train_size, len(data)), predicted, label='Predictions')
plt.title('LSTM Predictions on Time Series Data')
plt.xlabel('Time Steps')
plt.ylabel('Value')
plt.legend()
plt.show()
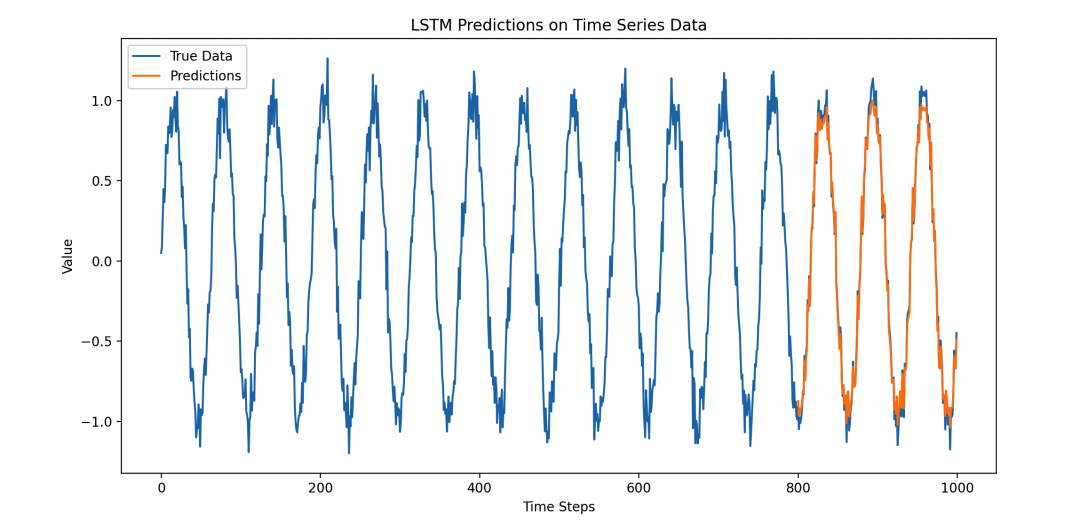
这段代码做了以下几件事情:
- 数据生成和准备:生成一个带有随机噪声的正弦波数据,并划分为训练集和测试集。
- LSTM 模型定义:定义了一个简单的单层 LSTM 模型,输入维度为 1,隐藏层大小为 64,输出维度为 1。
- 模型训练:使用 Adam 优化器训练模型,使其学会预测时间序列数据的下一个时间步。
- 模型测试和预测:在测试集上评估模型性能,并生成预测结果。
- 结果可视化:用 matplotlib 将原始数据和模型预测的结果进行对比展示。
这样的图表展示了 LSTM 模型在时间序列数据上的预测能力,可以很好地展示出模型学习到的模式和对未来数据的预测能力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
