【深度学习】Pytorch 教程(十五):PyTorch数据结构:7、模块(Module)详解(自定义神经网络模型并训练、评估)

【深度学习】Pytorch 教程(十五):PyTorch数据结构:7、模块(Module)详解(自定义神经网络模型并训练、评估)

一、前言
PyTorch的Module模块是定义神经网络模型的基类,提供了方便的方式来定义模型的结构和行为。通过继承Module类,可以轻松地定义自定义的神经网络模型,并在其中实现初始化方法、前向传播方法等。Module类还提供了模型保存和加载、自动求导等功能,使得模型的训练和使用变得更加便利。
二、实验环境
本系列实验使用如下环境
conda create -n DL python==3.11conda activate DLconda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia三、PyTorch数据结构
1、Tensor(张量)
Tensor(张量)是PyTorch中用于表示多维数据的主要数据结构,类似于多维数组,可以存储和操作数字数据。
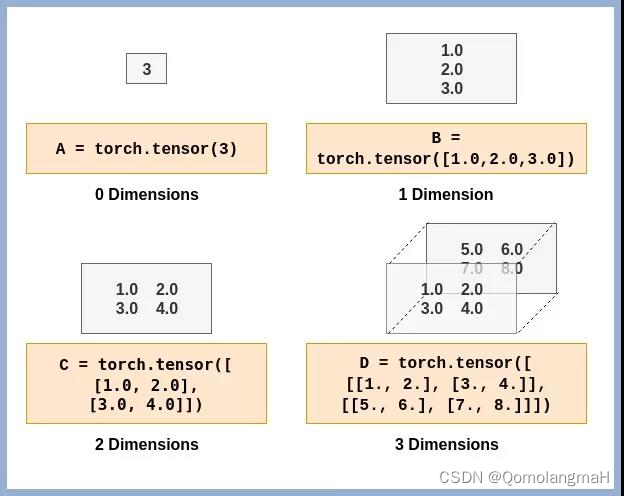
1. 维度(Dimensions)
Tensor(张量)的维度(Dimensions)是指张量的轴数或阶数。在PyTorch中,可以使用size()方法获取张量的维度信息,使用dim()方法获取张量的轴数。
2. 数据类型(Data Types)
PyTorch中的张量可以具有不同的数据类型:
- torch.float32或torch.float:32位浮点数张量。
- torch.float64或torch.double:64位浮点数张量。
- torch.float16或torch.half:16位浮点数张量。
- torch.int8:8位整数张量。
- torch.int16或torch.short:16位整数张量。
- torch.int32或torch.int:32位整数张量。
- torch.int64或torch.long:64位整数张量。
- torch.bool:布尔张量,存储True或False。
【深度学习】Pytorch 系列教程(一):PyTorch数据结构:1、Tensor(张量)及其维度(Dimensions)、数据类型(Data Types)
3. GPU加速(GPU Acceleration)
【深度学习】Pytorch 系列教程(二):PyTorch数据结构:1、Tensor(张量): GPU加速(GPU Acceleration)
2、张量的数学运算
PyTorch提供了丰富的操作函数,用于对Tensor进行各种操作,如数学运算、统计计算、张量变形、索引和切片等。这些操作函数能够高效地利用GPU进行并行计算,加速模型训练过程。
1. 向量运算
【深度学习】Pytorch 系列教程(三):PyTorch数据结构:2、张量的数学运算(1):向量运算(加减乘除、数乘、内积、外积、范数、广播机制)
2. 矩阵运算
【深度学习】Pytorch 系列教程(四):PyTorch数据结构:2、张量的数学运算(2):矩阵运算及其数学原理(基础运算、转置、行列式、迹、伴随矩阵、逆、特征值和特征向量)
3. 向量范数、矩阵范数、与谱半径详解
【深度学习】Pytorch 系列教程(五):PyTorch数据结构:2、张量的数学运算(3):向量范数(0、1、2、p、无穷)、矩阵范数(弗罗贝尼乌斯、列和、行和、谱范数、核范数)与谱半径详解
4. 一维卷积运算
【深度学习】Pytorch 系列教程(六):PyTorch数据结构:2、张量的数学运算(4):一维卷积及其数学原理(步长stride、零填充pad;宽卷积、窄卷积、等宽卷积;卷积运算与互相关运算)
5. 二维卷积运算
【深度学习】Pytorch 系列教程(七):PyTorch数据结构:2、张量的数学运算(5):二维卷积及其数学原理
6. 高维张量
【深度学习】pytorch教程(八):PyTorch数据结构:2、张量的数学运算(6):高维张量:乘法、卷积(conv2d~ 四维张量;conv3d~五维张量)
3、张量的统计计算
【深度学习】Pytorch教程(九):PyTorch数据结构:3、张量的统计计算详解
4、张量操作
1. 张量变形
【深度学习】Pytorch教程(十):PyTorch数据结构:4、张量操作(1):张量变形操作
2. 索引
3. 切片
【深度学习】Pytorch 教程(十一):PyTorch数据结构:4、张量操作(2):索引和切片操作
4. 张量修改
【深度学习】Pytorch 教程(十二):PyTorch数据结构:4、张量操作(3):张量修改操作(拆分、拓展、修改)
5、张量的梯度计算
【深度学习】Pytorch教程(十三):PyTorch数据结构:5、张量的梯度计算:变量(Variable)、自动微分、计算图及其可视化
6、数据集(Dataset)与数据加载器(DataLoader)
【深度学习】Pytorch 教程(十四):PyTorch数据结构:6、数据集(Dataset)与数据加载器(DataLoader):自定义鸢尾花数据类
import torch
from sklearn.datasets import load_iris
from torch.utils.data import Dataset, DataLoader
# 此函数用于加载鸢尾花数据集
def load_data(shuffle=True):
x = torch.tensor(load_iris().data)
y = torch.tensor(load_iris().target)
# 数据归一化
x_min = torch.min(x, dim=0).values
x_max = torch.max(x, dim=0).values
x = (x - x_min) / (x_max - x_min)
if shuffle:
idx = torch.randperm(x.shape[0])
x = x[idx]
y = y[idx]
return x, y
# 自定义鸢尾花数据类
class IrisDataset(Dataset):
def __init__(self, mode='train', num_train=120, num_dev=15):
super(IrisDataset, self).__init__()
x, y = load_data(shuffle=True)
if mode == 'train':
self.x, self.y = x[:num_train], y[:num_train]
elif mode == 'dev':
self.x, self.y = x[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
else:
self.x, self.y = x[num_train + num_dev:], y[num_train + num_dev:]
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
def __len__(self):
return len(self.x)
batch_size = 16
# 分别构建训练集、验证集和测试集
train_dataset = IrisDataset(mode='train')
dev_dataset = IrisDataset(mode='dev')
test_dataset = IrisDataset(mode='test')
train_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=True)7、模块(Module)
PyTorch的Module模块是构建神经网络模型的基本组件之一。Module模块提供了一种方便的方式来定义神经网络模型的结构,并且可以方便地进行参数的管理和训练。
1. 自定义神经网络模型
Module模块是所有神经网络模型的基类,它包含了一些方法和属性,用来定义神经网络的结构和行为。通过继承Module类,可以轻松地自定义一个神经网络模型,其中至少要包含下面两个方法:
__init__()方法:用于初始化网络模型的结构,可以在这个方法中定义网络的层和参数。- 这个方法通常会调用父类的
__init__()方法来初始化模型的参数。
- 这个方法通常会调用父类的
forward()方法:定义了模型的前向传播过程,即给定输入数据,通过网络模型计算出输出。- 这是Module模块中必须要实现的方法,它定义了整个神经网络模型的计算过程。
class IrisModel(nn.Module):
def __init__(self):
super(IrisModel, self).__init__()
self.fc = nn.Linear(4, 3)
def forward(self, x):
return self.fc(x)2. Module类功能简介
- 自动求导:Module类内部的操作默认支持自动求导。在前向传播过程中,PyTorch会自动构建计算图,并记录每个操作的梯度计算方式。这样,在反向传播过程中,可以自动计算和更新模型的参数梯度。
parameters()方法:返回模型中定义的所有可学习的参数,可以用于在训练过程中更新参数。modules()方法:返回模型中定义的所有子模块,可以用于递归地遍历和访问模型的所有组件。- Module类自动跟踪和管理模型中的可学习参数。
- 模型保存和加载:可以使用
torch.save()方法将整个模型保存到文件中,以便在以后重新加载和使用。加载模型时,可以使用torch.load()方法加载保存的模型参数。 - 将模型移动到指定的设备(如CPU或GPU)
- 通过传入一个torch.device对象或一个字符串来指定目标设备,模型的所有参数和缓冲区都将被移动到目标设备。
- 例如,使用
model.to("cuda")将模型移动到GPU设备上。
- 切换模型的训练和评估模式
train()和eval()方法
3. 训练模型
# 实例化神经网络模型
model = IrisModel()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 20
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
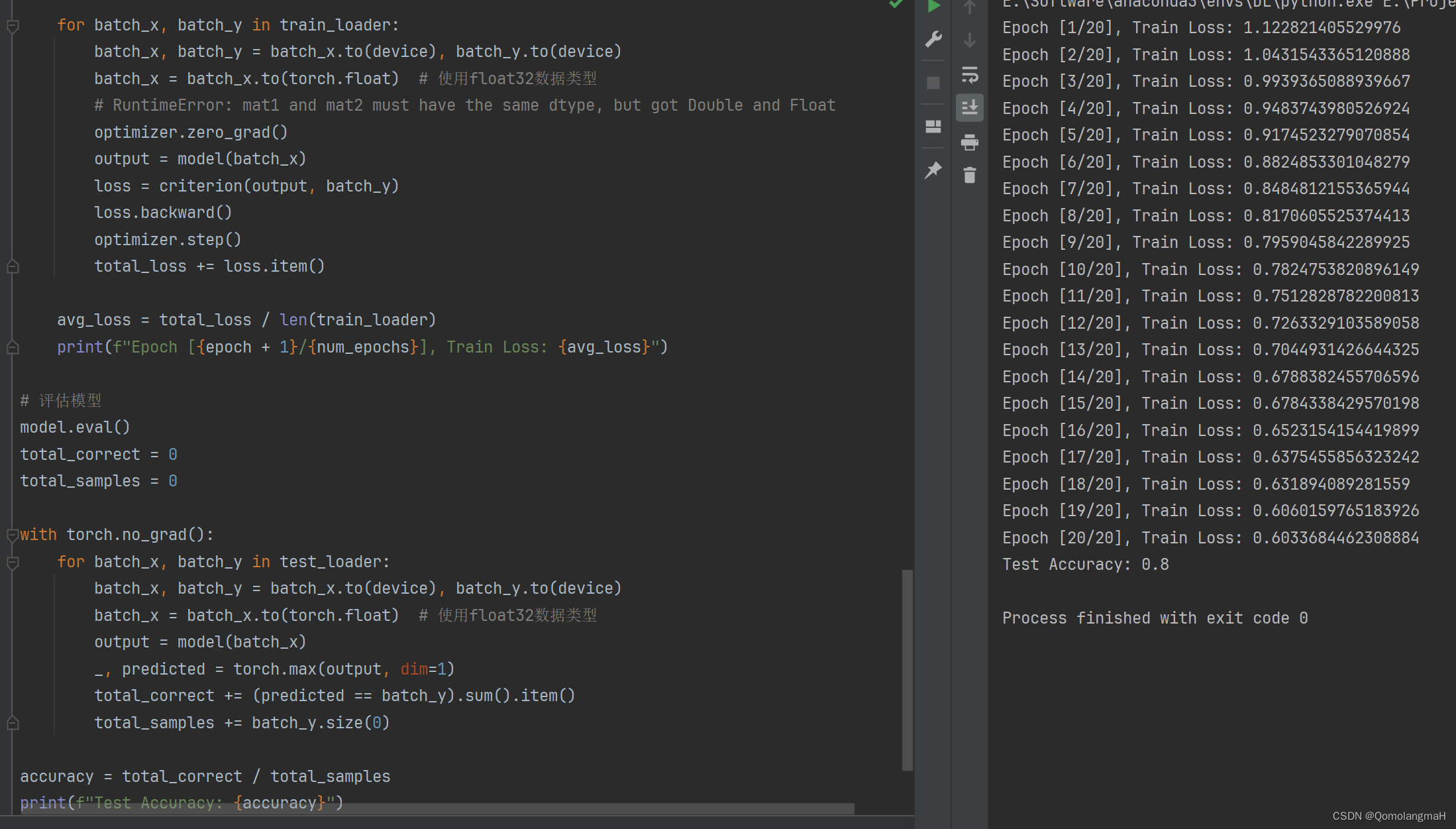
for epoch in range(num_epochs):
model.train()
total_loss = 0
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
batch_x = batch_x.to(torch.float) # 使用float32数据类型
# RuntimeError: mat1 and mat2 must have the same dtype, but got Double and Float
optimizer.zero_grad()
output = model(batch_x)
loss = criterion(output, batch_y)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
print(f"Epoch [{epoch + 1}/{num_epochs}], Train Loss: {avg_loss}")
# 保存模型
torch.save(model.state_dict(), 'iris_model.pth')4. 评估模型
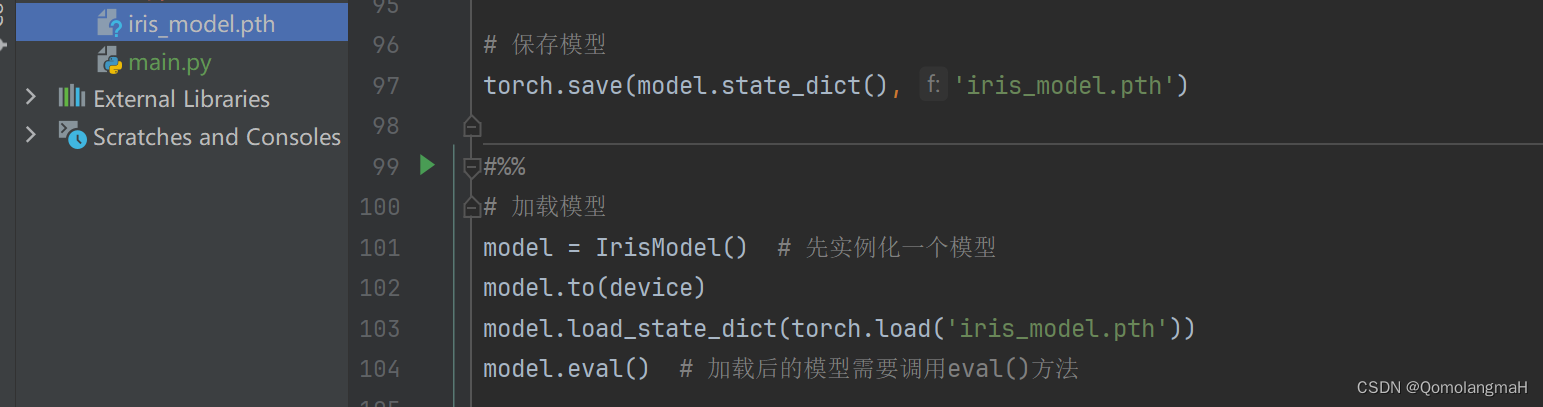
# 加载模型
model = IrisModel() # 先实例化一个模型
model.to(device)
model.load_state_dict(torch.load('iris_model.pth'))
model.eval() # 加载后的模型需要调用eval()方法
# 评估模型
model.eval()
total_correct = 0
total_samples = 0
with torch.no_grad():
for batch_x, batch_y in test_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
batch_x = batch_x.to(torch.float) # 使用float32数据类型
output = model(batch_x)
_, predicted = torch.max(output, dim=1)
total_correct += (predicted == batch_y).sum().item()
total_samples += batch_y.size(0)
accuracy = total_correct / total_samples
print(f"Test Accuracy: {accuracy}")5. 代码整合
import torch
import torch.nn as nn
from sklearn.datasets import load_iris
from torch.utils.data import Dataset, DataLoader
# 此函数用于加载鸢尾花数据集
def load_data(shuffle=True):
x = torch.tensor(load_iris().data)
y = torch.tensor(load_iris().target)
# 数据归一化
x_min = torch.min(x, dim=0).values
x_max = torch.max(x, dim=0).values
x = (x - x_min) / (x_max - x_min)
if shuffle:
idx = torch.randperm(x.shape[0])
x = x[idx]
y = y[idx]
return x, y
# 自定义鸢尾花数据类
class IrisDataset(Dataset):
def __init__(self, mode='train', num_train=120, num_dev=15):
super(IrisDataset, self).__init__()
x, y = load_data(shuffle=True) # 将x转换为浮点型数据
y = y.long() # 将y转换为长整型数据
# x, y = load_data(shuffle=True)
if mode == 'train':
self.x, self.y = x[:num_train], y[:num_train]
elif mode == 'dev':
self.x, self.y = x[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
else:
self.x, self.y = x[num_train + num_dev:], y[num_train + num_dev:]
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
def __len__(self):
return len(self.x)
# 创建一个模型类来定义神经网络模型
class IrisModel(nn.Module):
def __init__(self):
super(IrisModel, self).__init__()
self.fc = nn.Linear(4, 3)
def forward(self, x):
return self.fc(x)
# 加载数据
batch_size = 16
train_dataset = IrisDataset(mode='train')
dev_dataset = IrisDataset(mode='dev')
test_dataset = IrisDataset(mode='test')
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=True)
# 实例化神经网络模型
model = IrisModel()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 20
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
batch_x = batch_x.to(torch.float) # 使用float32数据类型
# RuntimeError: mat1 and mat2 must have the same dtype, but got Double and Float
optimizer.zero_grad()
output = model(batch_x)
loss = criterion(output, batch_y)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
print(f"Epoch [{epoch + 1}/{num_epochs}], Train Loss: {avg_loss}")
# 保存模型
torch.save(model.state_dict(), 'iris_model.pth')
#%%
# 加载模型
model = IrisModel() # 先实例化一个模型
model.to(device)
model.load_state_dict(torch.load('iris_model.pth'))
model.eval() # 加载后的模型需要调用eval()方法
# 评估模型
model.eval()
total_correct = 0
total_samples = 0
with torch.no_grad():
for batch_x, batch_y in test_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
batch_x = batch_x.to(torch.float) # 使用float32数据类型
output = model(batch_x)
_, predicted = torch.max(output, dim=1)
total_correct += (predicted == batch_y).sum().item()
total_samples += batch_y.size(0)
accuracy = total_correct / total_samples
print(f"Test Accuracy: {accuracy}")
腾讯云开发者
