二十行代码!我用Spark实现了电影推荐算法
原创
前言
很久之前,就有人问我如何做一个基于大数据技术的xx推荐系统。当时对于这个问题,着实难倒我了,因为当时只是知道一个协同过滤,其他的也没有过于深度研究。
最近,又有人私信问了我这个问题。于是,趁着这次机会,记录一下我一个小白从零做一个推荐系统的全过程。
推荐算法
从网上搜索了一些资料,发现推荐算法有很多,例如协同过滤(Collaborative Filtering)、内容过滤(Content-Based Filtering)、基于模型的推荐(Model-Based Recommendations)、混合推荐系统(Hybrid Recommendation Systems)以及基于强化学习的推荐。
最后我选择了协同过滤算法,原因就是题目要求基于大数据技术,而Spark中恰好集成了协同过滤,同时Spark能与其他的大数据技术更好地联动,所以最后就是就基于Spark的协同过滤来实现一个推荐系统。
协同过滤
我们先了解什么是协同过滤算法。协同过滤算法的原理基于用户之间的行为和偏好,通过分析用户与物品之间的交互数据(如评分、购买记录等)来进行推荐。其核心思想是“相似的用户喜欢相似的物品”。
协同过滤主要有两种类型:用户协同过滤和物品协同过滤。
用户协同过滤
基于用户的协同过滤算法(user-based collaboratIve filtering):给用户推荐和他兴趣相似的其他用户喜欢的产品,根据用户u对所有相似用户购买物品的预测分进行排序,取TopN的候选物品推荐给用户u即可。
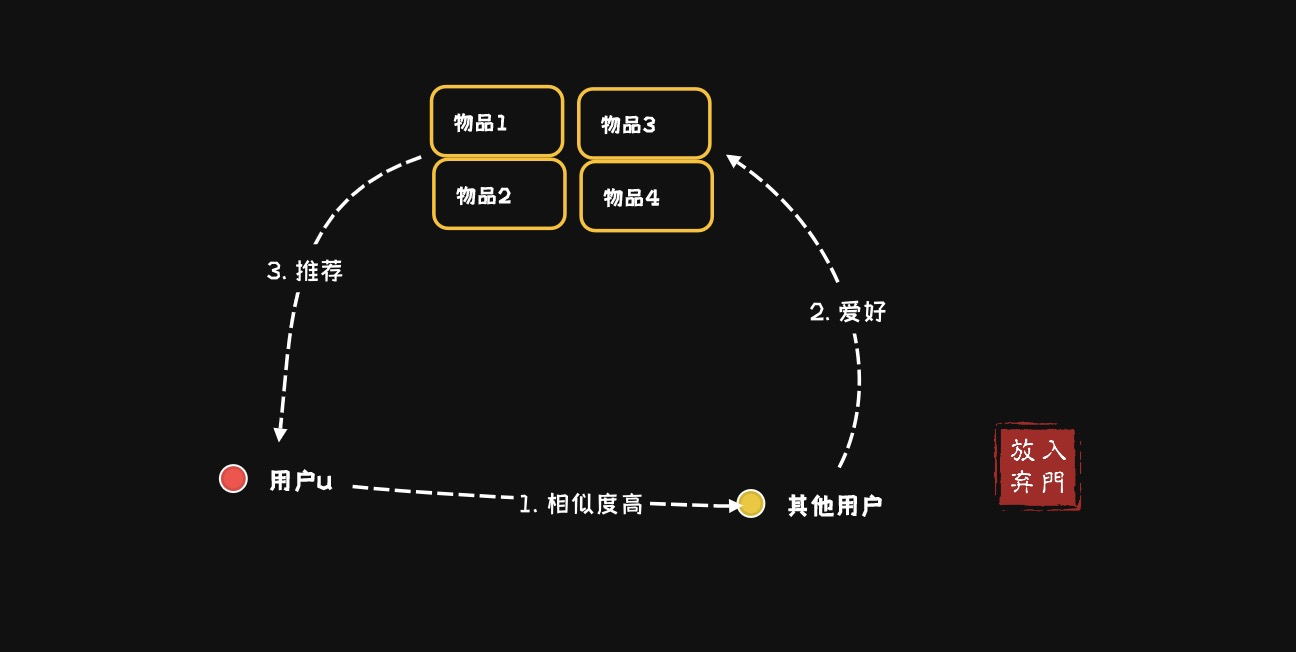
该方法通过寻找与目标用户具有相似兴趣的其他用户,以推荐这些相似用户喜欢的物品。
- 计算用户之间的相似度(如使用皮尔逊相关系数、余弦相似度等)
- 找到与目标用户最相似的K个用户
- 根据这些相似用户的评分,推荐他们喜欢但目标用户尚未接触过的物品
物品协同过滤
基于物品的协同过滤算法(item-based collaborative filtering):用户推荐和他之前喜欢的物品相似的物品,在用户u购买的物品集合中,选取与每一个物品TopN相似的物品,利用加权平均预估用户u对每个候选物品的评分。
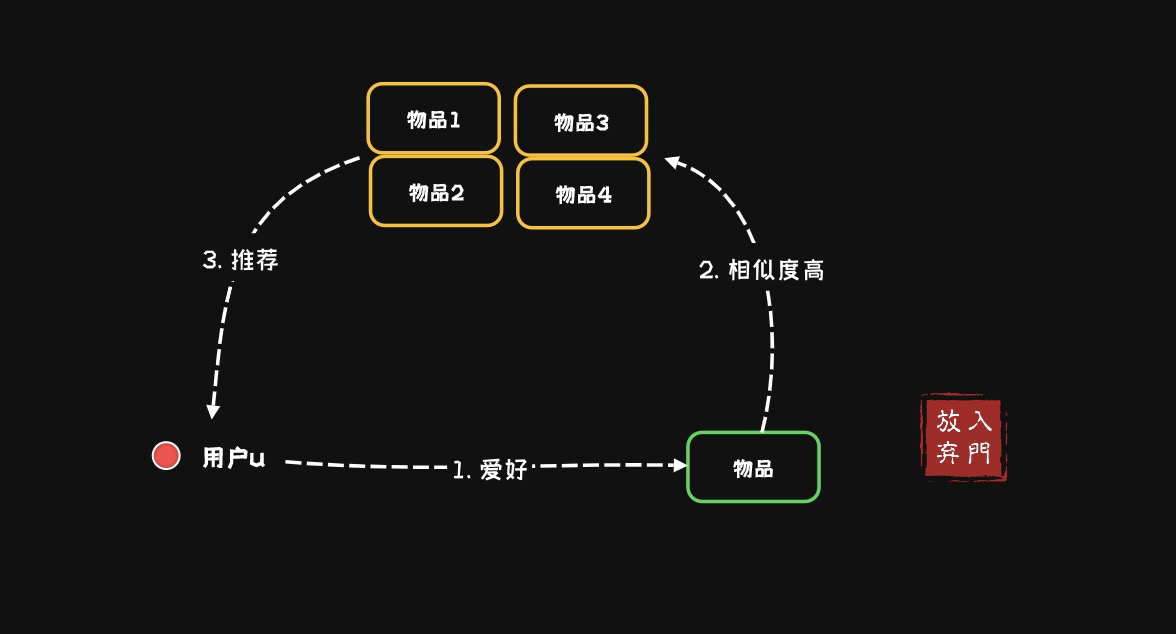
通过找到与目标物品相似的其他物品,推荐与目标物品相似的物品给用户。
- 计算物品之间的相似度(同样可以使用余弦相似度等方法)
- 找到用户曾经评分的物品,并确定这些物品相似的其他物品
- 推荐这些相似物品
综上所述,不论哪种类型,我们都需要知道用户对物品的喜爱程度,需要有个量化值(例如点赞、评分等)去评估。至于协同过滤推荐算法的两种类型涉及的相似度计算、系数等,这里都不做深入探究。了解完上面基本概念之后,如何来实现协同过滤算法?
Spark的协同过滤
在Spark的Mlib机器学习库中,就提供了协同过滤的实现。
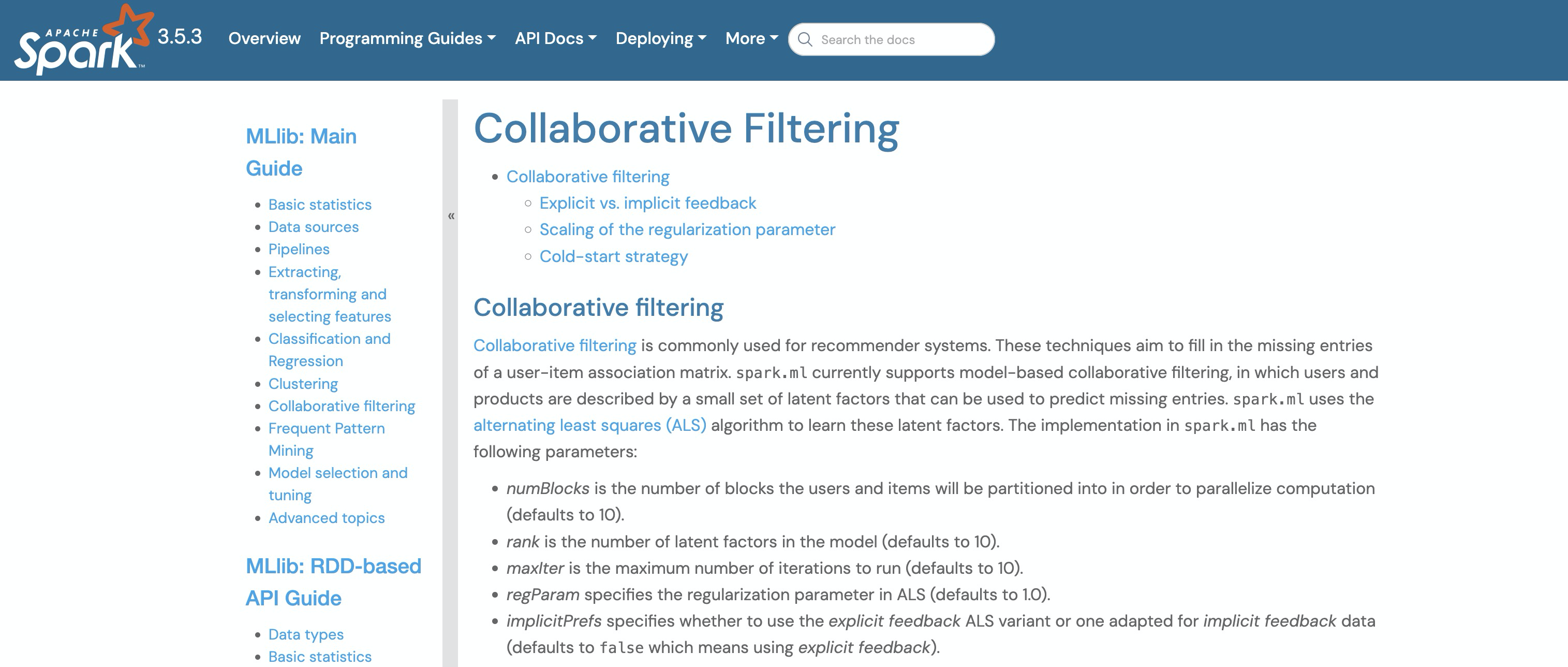
Spark关于协同过滤的实现是这样描述的:spark.ml目前支持基于模型的协同过滤,其中用户和产品由一组可用于预测缺失条目的潜在因素来描述。spark.ml使用交替最小二乘(ALS)算法来学习这些潜在因素。
ALS(最小交替二乘法)
到了Spark这里,协同过滤又和机器学习关联上了。ALS(Alternating Least Squares)是协同过滤的一种具体实现方式,主要用于优化用户-物品评分矩阵的分解。
用户-物品矩阵的稀疏性是推荐系统中的一个常见问题,主要指的是在这个矩阵中,大多数用户和物品之间没有交互(如评分、购买等),导致矩阵中大多数元素为空或缺失,从而缺乏足够的数据来捕捉用户的偏好。
而ALS是一种广泛使用的矩阵分解技术,常用于处理大规模稀疏矩阵,通过训练模型来学习用户和物品的潜在特征,以生成个性化的推荐。总结成一句话就是:Spark使用ALS实现了更精准的推荐算法。
电影喜好推荐
那么,如何使用Spark的ALS实现推荐算法呢?Spark官网文档中给出了一个电影推荐的代码,我们借着这个样例,就可以反向学习。
代码有python、java、scala、R版本,这里以scala为例,看看Spark Mlib如何基于ALS实现协同过滤的推荐算法。
1. 数据准备
首先我们先看数据准备部分。
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
}
val ratings = spark.read.textFile("data/mllib/als/sample_movielens_ratings.txt")
.map(parseRating)
.toDF()代码很简单,先加载sample_movielens_ratings.txt,这个文件就是用来做推荐的数据。
0::2::3::1424380312
0::3::1::1424380312
0::5::2::1424380312
1::94::2::1424380312
1::96::1::1424380312
1::97::1::1424380312
2::4::3::1424380312
2::6::1::1424380312自定义parseRating函数将每行数据分割,然后映射成Rating对象,生成DataFrame进行计算。其中包含用户ID、电影编号、评分和时间戳四个字段。数据中的评分字段,是用户对电影爱好程度的量化。
2. ALS
接下来就是将处理好的电影评分数据,使用ALS中进行训练,构建一个推荐模型。
// 80%数据为训练数据,20%为测试数据
val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2))
// Build the recommendation model using ALS on the training data
val als = new ALS()
.setMaxIter(5)
.setRegParam(0.01)
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating")
val model = als.fit(training)setMaxIter设置最大迭代次数,在ALS算法中,迭代主要是指用户特征矩阵和物品特征矩阵的更新过程。其中用户特征矩阵用于描述用户的偏好,物品特征矩阵用于描述物品的特征。
在迭代过程中,交替重复以下过程,直到达到最大迭代次数或满足某个收敛条件。
- 固定物品矩阵,更新用户矩阵:使用当前的物品特征来计算用户特征
- 固定用户矩阵,更新物品矩阵:使用当前的用户特征来计算物品特征
代码中设置了ALS的参数:
- setRegParam(0.01):设置正则化参数为 0.01,以防止过拟合
- setUserCol("userId"):指定用户 ID 列的名称,表示用户数据的唯一标识。
- setItemCol("movieId"):指定物品 ID 列的名称,表示物品(如电影)的唯一标识。
- setRatingCol("rating"):指定评分列的名称,表示用户对物品的评分
这里出现了个名词:迭代和过拟合。
迭代
setMaxIter(5)控制ALS算法在寻找最佳推荐模型时的迭代次数,迭代次数决定了算法达到收敛(即误差不再显著下降)所需的步骤数。
通常情况下,增加迭代次数可以提高模型的精度,但同时也会增加计算成本和时间。过多的迭代可能导致模型过度拟合训练数据,从而在新数据上表现不佳。
5次迭代通常被认为是一个合理的起点,能够在保证一定计算效率的同时,提供较好的模型性能。但最佳值可能因具体数据集和应用场景的不同而有所变化。建议根据以下因素进行调整:
- 数据规模:大数据集可能需要更多的迭代才能收敛
- 评估指标:通过交叉验证或其他评估手段来确定达到最佳性能所需的迭代次数
- 计算资源:考虑可用的计算资源和时间预算来决定合适的迭代次数
过拟合
过拟合(Overfitting)是指在机器学习和深度学习中,模型在训练数据上表现过于优秀,过度学习了训练数据中的细节,包括数据中的噪声和异常数据,但在测试数据或新数据上表现较差的现象。
比如说数据符合y = x^2的关系,结果训练数据中的一些异常数据符合y=sinx,这些异常数据也影响了xy之间关系,所以最终得出的公式应用在测试集中就不太准确,这就是数据过拟合。
所以为了解决过拟合问题,就引入了损失函数和正则化:
$$
总损失 = 损失函数(L) + λ\ * 正则化项(J)
$$
其中损失函数(Loss Function)用来衡量模型的输出y与真实的y之间的差距,给模型的优化指明方向,J 是正则化项,用于约束模型的复杂度;λ 是正则化系数,用于调控损失函数和正则化项之间的权衡。
在Spark的ALS中,我们只有选择λ的权力,所以这里使用setRegParam来设置λ为0.01。至于为什么是0.01,可能是基于经验、数据特性、模型复杂度以及实验结果的综合决策(源于网络)。
最后调用fit开始训练模型。
3. 模型预测
如何判断我的推荐模型是否过拟合,可以分别计算模型在训练集和验证集上的RMSE。
正常情况下,如果训练集RMSE和验证集RMSE相近,说明模型具有较好的泛化能力。如果训练集RMSE显著低于验证集RMSE,这可能是过拟合的迹象。说明模型在训练集上表现很好,但在新数据(验证集)上表现较差。
model.setColdStartStrategy("drop")
val predictions = model.transform(test)
val evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
val rmse = evaluator.evaluate(predictions)
println(s"Root-mean-square error = $rmse")- setColdStartStrategy设置了冷启动策略为“drop”,即在预测时,如果某个用户或物品没有任何历史数据,则该用户或物品的预测结果将被丢弃。
- transform使用训练好的模型对测试数据集进行预测
- RegressionEvaluator创建一个回归评估器对象,用于评估回归模型的预测性能。
回归评估器
RegressionEvaluator使用 RMSE(均方根误差)衡量回归模型预测性能,它表示模型预测值与实际值之间的偏差大小。
setLabelCol指定标签列的名称为"rating",这是上面数据集中电影评分的列名,setPredictionCol指定预测列的名称为"prediction",这是模型预测值的列名。
最后使用评估器对预测结果DataFrame进行评估,计算模型预测的均方根误差(RMSE)。

最后计算出来的RMSE为1.7,表示输出值和测试数据中的真实值相差1.7。对于大多数内容推荐系统,RMSE在1到3之间可能被认为是可接受的。
4. 模型推荐
然后根据上面训练的模型开始推荐。
val userRecs = model.recommendForAllUsers(10)
// Generate top 10 user recommendations for each movie
val movieRecs = model.recommendForAllItems(10)
// Generate top 10 movie recommendations for a specified set of users
val users = ratings.select(als.getUserCol).distinct().limit(3)
val userSubsetRecs = model.recommendForUserSubset(users, 10)
// Generate top 10 user recommendations for a specified set of movies
val movies = ratings.select(als.getItemCol).distinct().limit(3)
val movieSubSetRecs = model.recommendForItemSubset(movies, 10)recommendForAllUsers为每个用户生成前10部电影的推荐列表,model就是是上面通过ALS算法训练得到的推荐模型。然后生成两个推荐列表:
- 为每部电影生成前10个可能喜欢它的用户的推荐列表
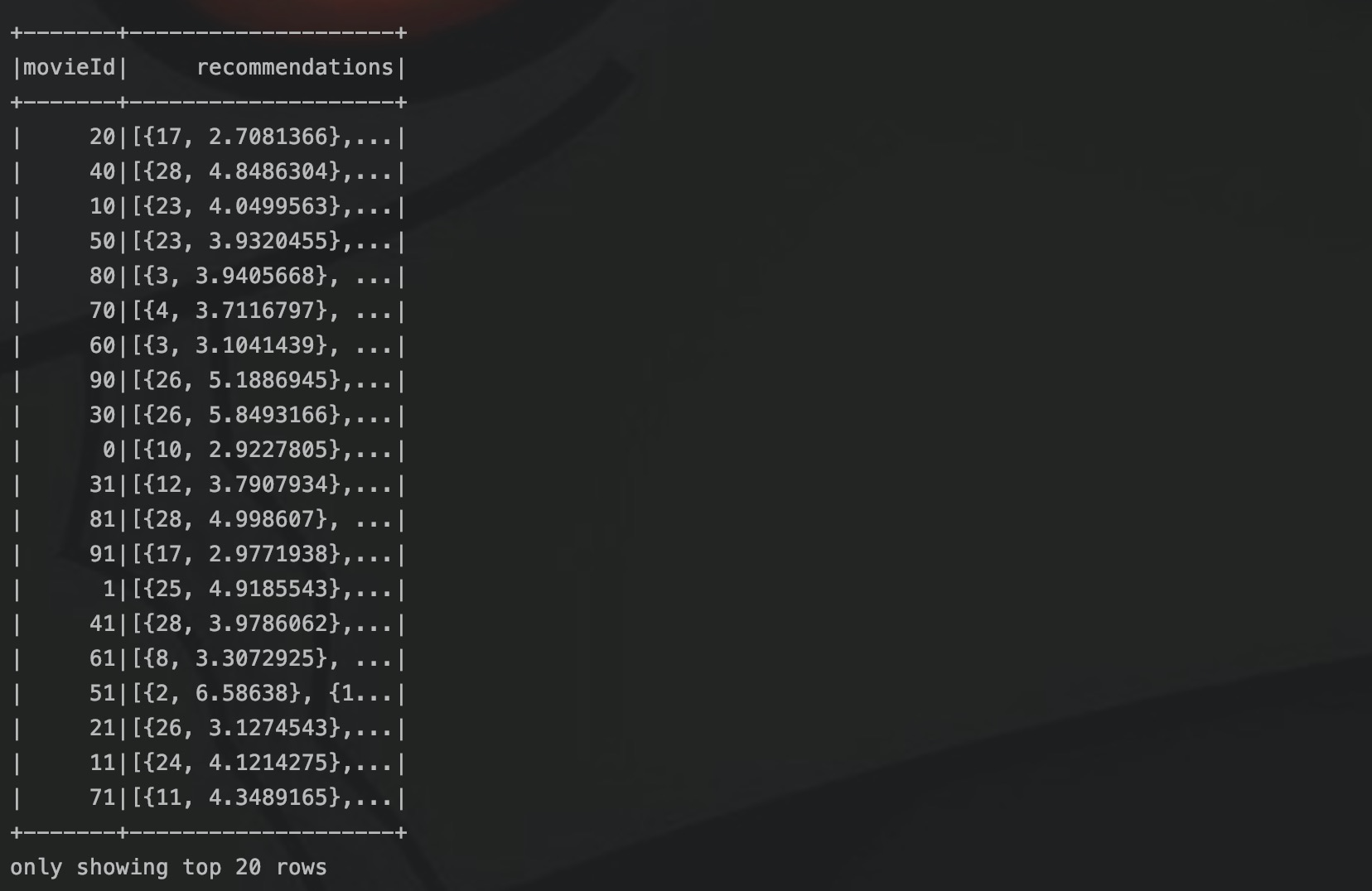
- 为这3个用户生成前10部电影的推荐列表
这样,使用Spark的ALS算法,完成了电影推荐系统的后台推荐数据准备。如果要做一个推荐系统的话,肯定要有前台页面,所以我们要将这部分数据放到后台数据库中。
同样在数据集中用户和电影都是用ID表示,所以在数据库中,也会有用户ID和用户、电影ID和电影名称的关系映射表。
结语
从Spark使用ASL实现协同过滤推荐的整个过程看,代码量少步骤简单。从准备数据到训练模型、验证模型,以及最后生成推荐内容,都提供了标准接口,所以更多的工作是准备数据。
在生成推荐数据放入数据库之后,就可以设计一个前台页面去做推荐,至于如何设计,可以从实用性和展示性两个方面出发。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
