AAAI 2024| 知识图谱论文总结



最近,收集一下AAAI 2024关于知识图谱的论文,主要是以Knowledge graph为关键词进行总结,关于知识图谱中涉及到的实体识别、关系抽取等文章就不在本次的总结之列(如有遗漏,欢迎大家补充)。
本次总结发表的在AAAI2024的论文总共22篇,涉及的研究内容有静态知识图谱推理、时序知识图谱推理、多模态知识图谱推理以及知识图谱的应用等。特别是最近比较火热的研究话题KG+LLM总共有五篇。
- Knowledge Graph Prompting for Multi-Document Question Answering
- Editing Language Model-based Knowledge Graph Embeddings
- CK12: A Rounded K12 Knowledge Graph Based Benchmark for Chinese Holistic Cognition Evaluation
- KG-TREAT: Pre-training for Treatment Effect Estimation by Synergizing Patient Data with Knowledge Graphs
- Mitigating Large Language Model Hallucinations via Autonomous Knowledge Graph-Based Retrofitting
(如果对您有用,还请您点赞。感谢您的支持!)
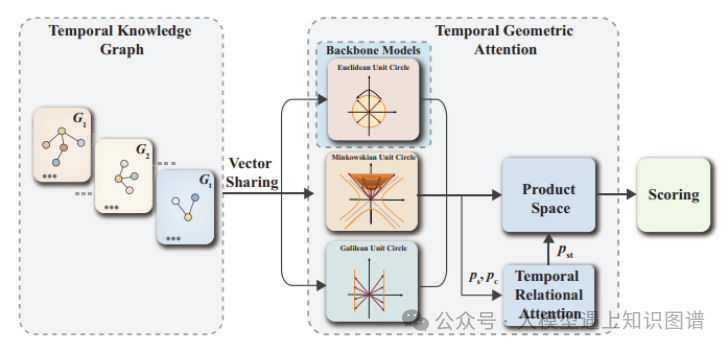
1.HGE: Embedding Temporal Knowledge Graphs in a Product Space of Heterogeneous Geometric Subspaces
作者:Jiaxin Pan, Mojtaba Nayyeri Yinan Li Steffen Staab
摘要:时序知识图谱表示与主体𝑠和客体𝑜通过关系标签p在时间τ上相关的时序事实 (𝑠,𝑝,𝑜,𝜏),其中 𝜏 可以是一个时间点或时间间隔。时序知识图谱可能在不同的时间点展示静态时序模式,并在不同的时间戳之间展示动态时序模式。为了学习丰富的静态和动态时序模式并将其应用于推理,文献中提出了几种嵌入方法。然而,由于大多数方法都采用单一的底层嵌入空间,它们模拟所有种类的时序模式的能力受到了严重的限制,因为它们必须遵守其一个嵌入空间的几何性质。我们通过一种嵌入方法来解除这一限制,该方法将时序事实映射到由几个异构几何子空间组成的乘积空间,具有不同的几何属性,即复数、双重和分裂复数空间。此外,我们提出了一种时序几何注意机制,根据捕获的关系和时序信息方便地整合来自不同几何子空间的信息。在标准时序基准数据集上的实验结果有利地评估了我们的方法相对于最先进的模型。
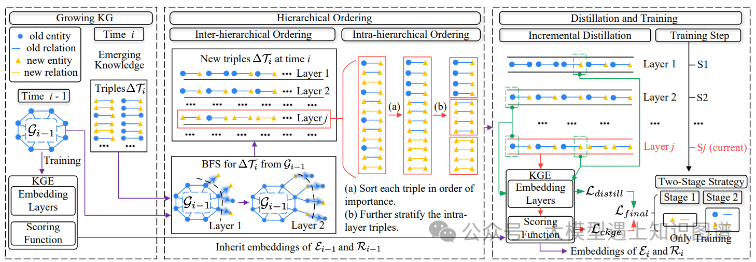
2.Towards Continual Knowledge Graph Embedding via Incremental Distillation
作者:Jiajun Liu, Wenjun Ke, Peng Wang, Ziyu Shang, Jinhua Gao, Guozheng Li , Ke Ji, Yanhe Liu1
摘要:传统的知识图谱嵌入(KGE)方法通常需要保存整个知识图谱(KG),当新知识出现时,训练成本很大。为了解决这个问题,连续知识图谱嵌入(CKGE)任务被提出,通过有效地学习新出现的知识同时保留良好的旧知识来训练KGE模型。然而,现有的CKGE方法严重忽视了KG中的显式图结构,这对上述目标至关重要。一方面,现有方法通常随机学习新的三元组,破坏了新KG的内部结构。另一方面,旧的三元组被同等地保留,未能有效地减轻灾难性遗忘。在本文中,我们提出了一种基于增量蒸馏(IncDE)的CKGE竞争方法,该方法充分考虑了KG中的显式图结构的使用。首先,为了优化学习顺序,我们引入了一种分层策略,逐层对新的三元组进行排序学习。通过同时采用层间和层内的顺序,根据图结构特征,新的三元组被分组成层。其次,为了有效地保留旧知识,我们设计了一种新颖的增量蒸馏机制,该机制促进了实体表示从前一层到下一层的无缝转移,推动了旧知识的保留。最后,我们采用两阶段训练范式,避免了由于训练不足的新知识对旧知识的过度破坏。实验结果显示,IncDE优于最先进的基线模型。值得注意的是,增量蒸馏机制在平均倒数排名(MRR)得分上提高了0.2%-6.5%。更多的探索性实验验证了IncDE在所有时间步骤中有效地学习新知识同时保留旧知识的有效性。
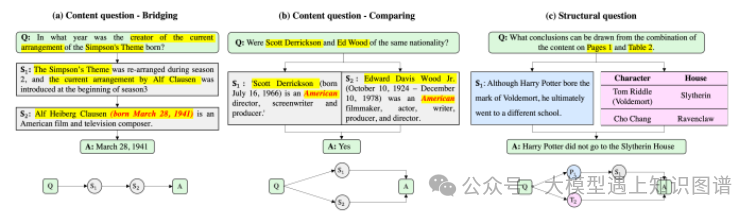
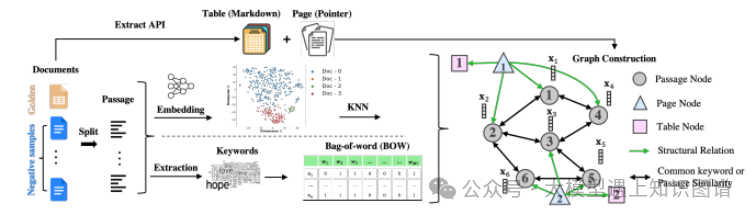
3.Knowledge Graph Prompting for Multi-Document Question Answering
作者:Yu Wang, Nedim Lipka, Ryan A. Rossi, Alexa Siu, Ruiyi Zhang, Tyler Derr
摘要:大型语言模型(LLMs)的“预训练、提示、预测”范式在开放域问答(OD-QA)中取得了显著的成功。然而,很少有研究探索这种范式在多文档问答(MD-QA)中的应用,这是一个需要深入理解文档内容和结构之间逻辑关联的任务。为了填补这一关键差距,我们提出了一种知识图谱提示(KGP)方法,用于为MD-QA提示LLMs的正确上下文,该方法包括图构建模块和图遍历模块。对于图构建,我们在多个文档上创建一个知识图谱(KG),其中节点代表段落或文档结构(例如,页面/表),边表示段落或文档结构关系之间的语义/词汇相似性。对于图遍历,我们设计了一个基于LLM的图遍历代理,该代理在节点之间导航并收集支持的段落,帮助LLMs在MD-QA中。构建的图作为全局规则器,调节段落之间的过渡空间并减少检索延迟。同时,图遍历代理作为局部导航器,收集相关上下文逐步接近问题并确保检索质量。大量实验强调了KGP在MD-QA中的有效性,表明利用图来增强LLMs的提示设计和检索增强生成的潜力。
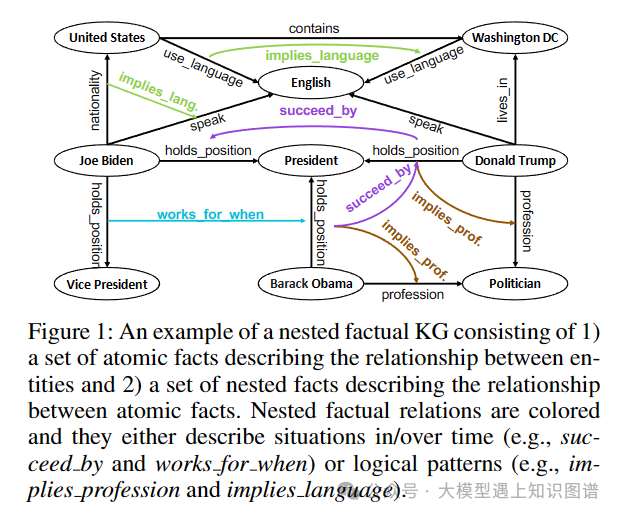
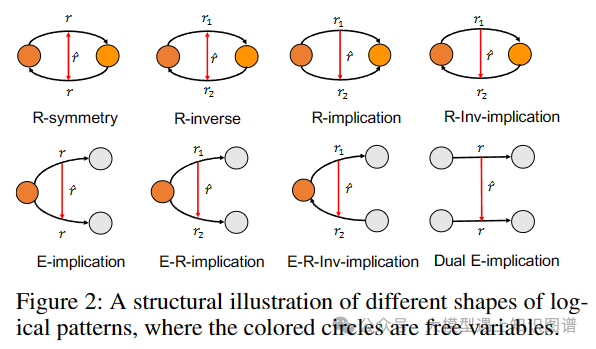
4.NestE: Modeling Nested Relational Structures for Knowledge Graph Reasoning
作者:Bo Xiong, Mojtaba Nayyeri, Linhao Luo, Zihao Wang, Shirui Pan, Steffen Staab
摘要:知识图推理主要集中在三元组上。最近的进展已被探讨,以提高这些事实的语义,通过将更有效的陈述如超关系的事实。然而,这些方法仅限于描述单个信息的原子事实。本文扩展到原子事实之外,深入研究嵌套事实,由引用的三元组表示,其中主语和宾语本身是三元组(例如,(巴拉克·奥巴马,holdposition,President),succeed_by,(唐纳德·特朗普,现任总统))。这些嵌套的事实使得复杂语义的表达成为可能,比如随时间变化的情况,以及实体和关系上的逻辑模式。作为回应,我们引入NestE,一个新的KG嵌入方法,捕捉原子和嵌套的事实知识的语义。NestE将每个原子事实表示为一个1X3矩阵,每个嵌套关系被建模为一个3X3矩阵,该矩阵通过矩阵乘法旋转1X3原子事实矩阵。矩阵的每个元素在广义4D超复数空间中表示为一个复数,包括(球形)四元数、双曲四元数和分裂四元数。通过深入的分析,我们证明了嵌入的功效,捕捉不同的逻辑模式嵌套的事实,超越了一阶逻辑类表达式的限制。我们的实验结果展示了在三元组预测和条件链接预测中,雀巢在当前基线上的显著性能提升。代码和预先训练的模型可在https://github.com/xiongbool0/NestE
5.TEILP: Time prediction over knowledge graphs via logical reasoning
作者:Siheng Xiong , Yuan Yang , Ali Payani , James C Kerce , Faramarz Fekri
摘要:传统的基于嵌入的模型将时间事件预测在时序知识图谱(TKGs)中视为一个排名问题。然而,它们常常在捕捉如顺序和距离等基本时序关系方面表现不足。在本文中,我们提出了TEILP,这是一个逻辑推理框架,自然地将这些时序元素整合到知识图谱预测中。我们首先将TKGs转换为一个时间事件知识图谱(TEKG),它在图的节点方面具有更明确的时间表示。TEKG使我们能够开发一种可微分的随机游走方法来进行时间预测。最后,我们引入了条件概率密度函数,与涉及查询间隔的逻辑规则相关联,使用它们我们得出时间预测。我们在五个基准数据集上将TEILP与最先进的方法进行了比较。我们展示了我们的模型在提供可解释性解释的同时,相对于基线实现了显著的改进。特别是,我们考虑了训练样本有限、事件类型不平衡以及仅基于过去事件预测未来事件的时间等多种场景。在所有这些情况下,TEILP在鲁棒性方面均超过了最先进的方法。
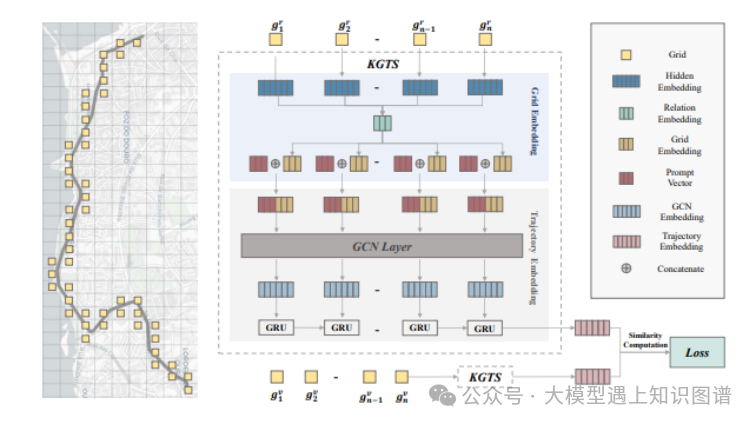
6.KGTS: Contrastive Trajectory Similarity Learning over Prompt Knowledge Graph Embedding
作者:Zhen Chen , Dalin Zhang , Shanshan Feng, Kaixuan Chen, Lisi Chen, Peng Han, Shuo Shang
摘要:轨迹相似性计算是各种空间信息应用的基本功能。尽管现有的深度学习相似性计算方法比非学习解决方案提供了更好的效率和准确性,但它们在轨迹嵌入方面仍然不成熟,且在训练时需要大量的预处理工作,具有很差的通用性。针对这些限制,我们提出了一个基于知识图谱网格嵌入、提示轨迹嵌入和无监督对比学习的新框架,名为KGTS,以改进轨迹相似性计算。具体而言,我们首先使用GRot嵌入方法嵌入地图网格,以强烈把握网格的邻近关系。然后,一个提示轨迹嵌入网络整合了结果的网格嵌入,并提取轨迹结构和点顺序信息。它通过无监督对比学习进行训练,这不仅减轻了繁重的预处理负担,还通过创造性设计的策略为正样本生成提供了出色的通用性。提示轨迹嵌入采用定制的提示范 paradigm,以缓解网格嵌入和轨迹嵌入之间的差距。在两个实际轨迹数据集上的大量实验表明,KGTS相对于最先进的方法具有卓越的性能。
7.Editing Language Model-based Knowledge Graph Embeddings
****Siyuan Cheng, Ningyu Zhang, Bozhong Tian, Xi Chen, Qingbin Liu, Huajun Chen
摘要:近几十年来,通过语言模型构建知识图谱(KG)嵌入已经得到了实证成功。然而,基于语言模型的KG嵌入通常被部署为静态的工件,这使得在部署后要进行重新训练以修改它们变得困难。为了解决这个问题,我们在本文中提出了一个新任务,即编辑基于语言模型的KG嵌入。这个任务旨在在不影响其他方面性能的情况下,便捷、高效地更新KG嵌入。我们构建了四个新的数据集:E-FB15k237、A-FB15k237、E-WN18RR 和 A-WN18RR,并评估了几个知识编辑基线,展示了之前的模型处理提出的具有挑战性任务的能力有限。我们进一步提出了一个名为KGEditor的简单但强大的基线,该基线利用超网络的额外参数层来编辑/添加事实。我们的全面实验结果显示,即使在面对有限的训练资源时,KGEditor在更新特定事实方面都表现出色,而不影响整体性能。
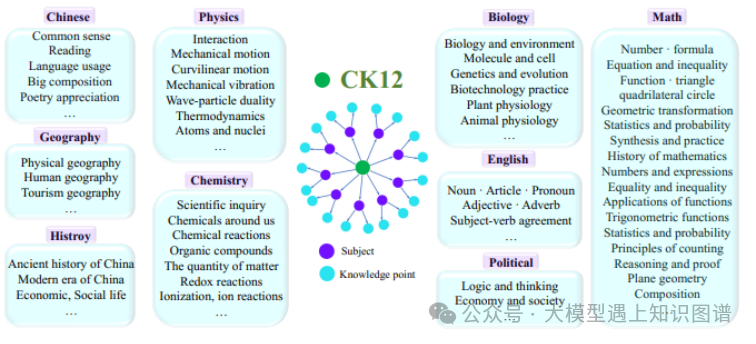
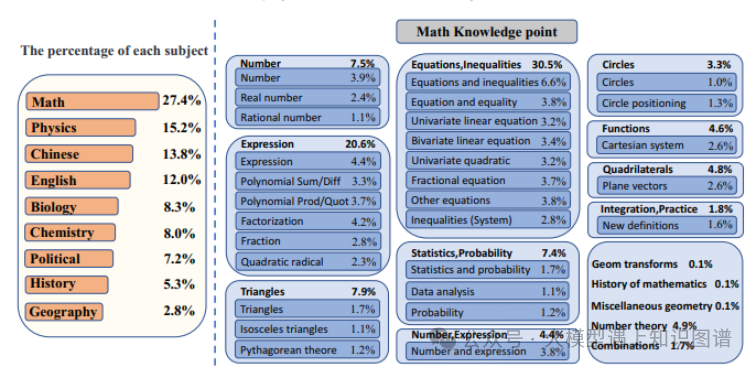
8.CK12: A Rounded K12 Knowledge Graph Based Benchmark for Chinese Holistic Cognition Evaluation
作者:Weihao You, Pengcheng Wang, Changlong Li, Zhilong Ji, Jinfeng Bai
摘要:随着大型语言模型(LLMs)的快速发展,我们迫切需要新的自然语言处理(NLP)基准测试来与之对齐。我们提出了一个精心设计的评估基准测试,利用知识图谱。这个评估包括584个一级知识点和1,989个二级知识点,从而涵盖了K12教育领域知识的全面范围。主要目标是全面评估在中国背景下运行的LLMs的高级理解能力和推理能力。我们的评估包括五种不同类型的问题,共计39,452个问题。我们通过三种不同的模式测试当前主流的LLMs。首先,使用四种提示评估模式来评估基本能力。此外,对于选择题,通过数据增强设计了一种以结果为导向的评估方法,以评估模型在高级知识和推理方面的熟练程度。此外,派生出一个带有推理过程的子集,并使用过程导向的测试方法来测试模型的可解释性和高阶推理能力。我们进一步展示了模型在我们的知识点上的能力,并期望这个评估能够帮助评估LLMs在知识点上的优点和不足,从而促进它们在中国背景下的发展。
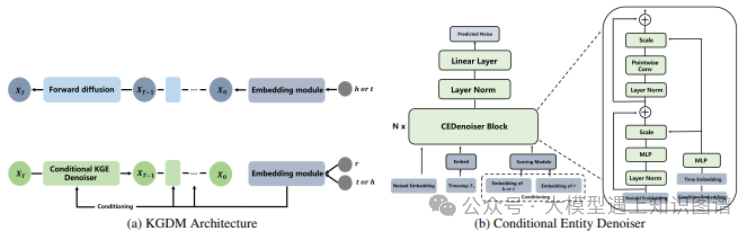
9.KGDM: A Diffusion Model to Capture Multiple Relation Semantics for Knowledge Graph Embedding
作者:Xiao Long, Liansheng Zhuang, Aodi Li, Jiuchang Wei, Houqiang Li, Shafei Wang
摘要:知识图谱嵌入(KGE)是一种高效且可扩展的知识图谱补全方法。然而,大多数现有的KGE方法都面临着多重关系语义的挑战,这通常会降低它们的性能。这是因为大多数KGE方法学习实体(关系)的固定连续向量,并做出确定性的实体预测以完成知识图谱,这几乎不捕捉到多重关系语义。为了解决这个问题,以前的工作尝试学习复杂的概率嵌入,而不是固定的嵌入,但是受到了重计算复杂性的困扰。相反,本文提出了一个简单而高效的框架,即知识图谱扩散模型(KGDM),以捕捉预测中的多重关系语义。其关键思想是将实体预测问题转化为条件实体生成。具体而言,KGDM通过去噪扩散概率模型(DDPM)估计预测中目标实体的概率分布。为了弥合连续扩散模型和离散知识图谱之间的差距,定义了两个可学习的嵌入函数,将实体和关系映射到连续向量。为了考虑知识图谱的连接模式,引入了一个条件实体去噪模型,以生成基于给定实体和关系的目标实体。大量实验表明,KGDM在三个基准数据集上显著优于现有的最先进方法。
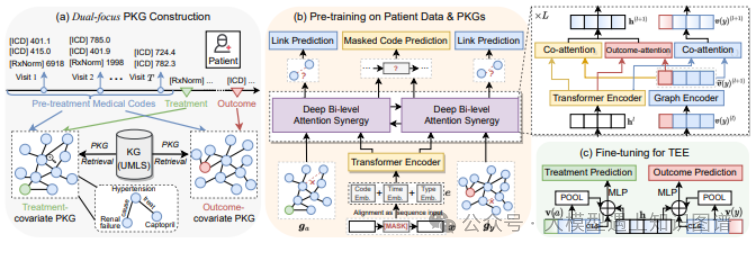
10.KG-TREAT: Pre-training for Treatment Effect Estimation by Synergizing Patient Data with Knowledge Graphs
作者:Ruoqi Liu , Lingfei Wu , Ping Zhang
摘要:治疗效果估计(TEE)是确定各种治疗对患者结果影响的任务。当前的TEE方法由于依赖有限的标注数据和稀疏、高维的观察性患者数据带来的挑战而表现不佳。为了解决这些挑战,我们介绍了一个新颖的预训练和微调框架,名为KG-TREAT,该框架将大规模的观察性患者数据与生物医学知识图谱(KGs)相结合,以增强TEE。与以往的方法不同,KG-TREAT构建了双重焦点的知识图谱,并整合了深层的双级注意力协同方法进行深入信息融合,实现了治疗-协变量和结果-协变量关系的明确编码。KG-TREAT还融合了两个预训练任务,以确保对患者数据和知识图谱的深入理解和上下文化。对四个下游TEE任务的评估显示,KG-TREAT相对于现有方法具有明显优势,ROC曲线下面积(AUC)平均提高了7%,而基于影响函数的估计异质效应精度(IF-PEHE)提高了9%。我们估计的治疗效果的有效性通过与已建立的随机临床试验发现的一致性进一步得到确认。
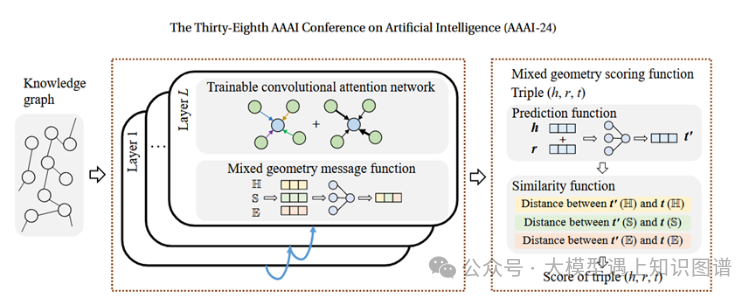
11.Mixed Geometry Message and Trainable Convolutional Attention Network for Knowledge Graph Completion
作者:Bin Shang, Yinliang Zhao1, Jun Liu, Di Wang
摘要:知识图补全(KGC)旨在研究嵌入表示以解决知识图(KG)的不完备性。最近,图卷积网络(GCN)和图注意网络(GAT)通过捕获实体的邻居信息被广泛用于 KGC 任务。然而,基于 GCN 和GAT的 KGC 模型都有其局限性,最好的方法是分析每个实体的邻居(预验证),而这个过程的成本却非常高。此外,嵌入的表示质量可以影响邻居信息的聚合(消息传递)。为了解决上述限制,我们提出了一种新颖的知识图补全模型,具有混合几何消息和可训练的卷积注意网络,名为 MGTCA。具体地,混合几何消息函数通过联合集成双曲空间、超球面空间和欧几里德空间中的空间信息来生成丰富的邻居消息。为了完成图神经网络(GNN)的自主切换并消除预先验证知识图谱局部结构的必要性,提出了一种可训练的卷积注意网络,在一个可训练的公式中包含三种类型的 GNN。此外,提出了一种混合几何评分函数,它通过基于不同几何空间的新颖预测函数和相似度函数来计算三元组的分数。对三个标准数据集的广泛实验证实了我们创新的有效性,并且与最先进的方法相比,MGTCA 的性能得到了显着提高。
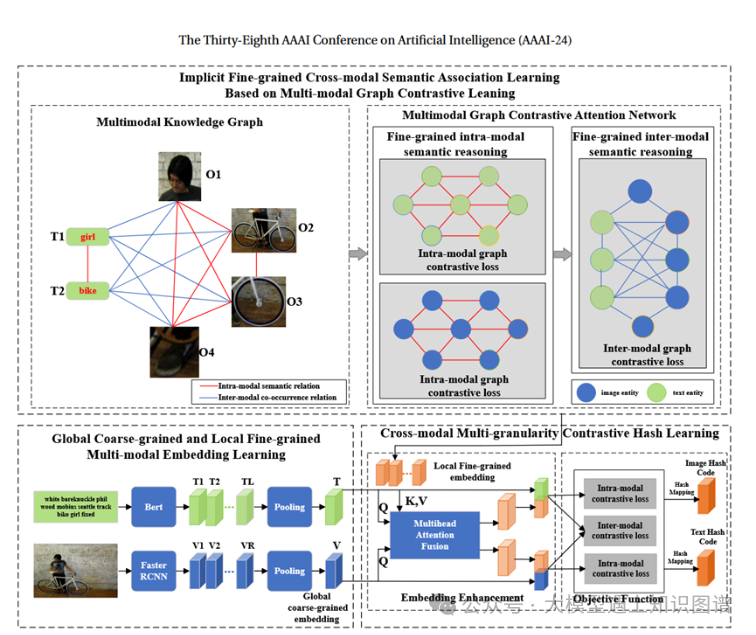
12. Self-supervised Multi-modal Knowledge Graph Contrastive Hashing for Cross-Modal Search
作者:Meiyu Liang, Junping Du*, Zhengyang Liang, Yongwang Xing, Wei Huang, Zhe Xue
摘要:深度跨模态哈希技术为跨模态搜索提供了有效、高效的跨模态统一表示学习解决方案。然而,现有的方法忽略了不同模态之间隐含的细粒度多模态知识关系,例如当图像包含文本中未直接描述的信息时。为了解决这个问题,我们提出了一种新颖的用于跨模态搜索的自监督多粒度多模态知识图对比哈希方法(CMGCH)。首先,为了捕获隐式细粒度跨模态语义关联,构建了多模态知识图,将图像和文本之间的隐式多模态知识关系表示为模态间和模态内语义关联。其次,提出了跨模态图对比注意网络对多模态知识图进行推理,以充分学习隐式细粒度模态间和模态内知识关系。第三,提出了一种跨模态多粒度对比嵌入学习机制,通过多头注意力机制融合全局粗粒度和局部细粒度嵌入,进行模态间和模内对比学习,从而增强跨模态的学习能力。具有更强区分性和语义一致性保持能力的统一表示。通过模内和模间对比的联合训练,可以在最终的跨模态统一哈希空间中保持不同模态的不变性和模态特定信息。对多个跨模式基准数据集的广泛实验表明,所提出的 CMGCH 优于最先进的方法。
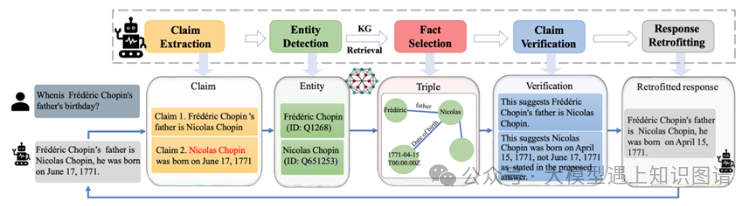
12、Mitigating Large Language Model Hallucinations via Autonomous Knowledge Graph-Based Retrofitting
作者:Xinyan Guan, Yanjiang Liu, Hongyu Lin, Yaojie Lu1, Ben He, Xianpei Han, Le Sun
摘要:将事实知识纳入知识图中被认为是减轻大语言模型(LLM)幻觉的一种有前途的方法。现有方法通常仅使用用户的输入来查询知识图谱,无法解决LLM在推理过程中产生的事实幻觉。为了解决这个问题,本文提出了基于知识图的改造(KGR),这是一种将法学硕士与知识图谱相结合的新框架,通过根据知识图谱中存储的事实知识对法学硕士的初始草案响应进行改造,以减轻推理过程中的事实幻觉。具体来说,KGR 利用 LLM 在模型生成的响应中提取、选择、验证和改进事实陈述,从而实现自主知识验证和提炼过程,无需任何额外的手动操作。实验表明,KGR 可以显着提高 LLM 在事实 QA 基准上的表现,尤其是在涉及复杂推理过程时,这证明了 KGR 在减轻幻觉和增强 LLM 可靠性方面的必要性和有效性。
13、Knowledge Graph Error Detection with Contrastive Confidence Adaption
作者:Xiangyu Liu, Yang Liu, Wei Hu
摘要:知识图(KG)经常包含各种错误。以前检测知识图谱错误的工作主要依赖于图结构的三元组嵌入。我们进行了实证研究,发现这些作品很难区分语义相似的正确三元组中的噪音。在本文中,我们提出了一种 KG 错误检测模型 CCA,用于集成三元组重建中的文本和图形结构信息,以更好地区分语义。我们设计交互式对比学习来捕捉文本和结构模式之间的差异。此外,我们构建了具有语义相似噪声和对抗性噪声的真实数据集。实验结果表明,CCA 的性能优于最先进的基线,特别是在检测语义相似的噪声和对抗性噪声方面。
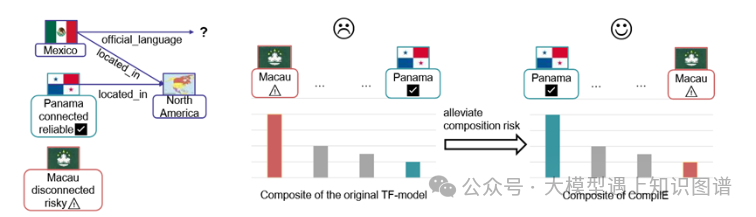
14、Modeling Knowledge Graphs with Composite Reasoning
作者:Wanyun Cui, Linqiu Zhang
摘要:结合多个现有知识来推断新知识的能力既至关重要又具有挑战性。在本文中,我们探讨了如何在知识图补全(KGC)的背景下组合各种实体的事实。我们使用复合推理来统一不同 KGC 模型的观点,包括平移模型、基于张量分解(TF)的模型、基于实例的学习模型和 KGC 正则化器。
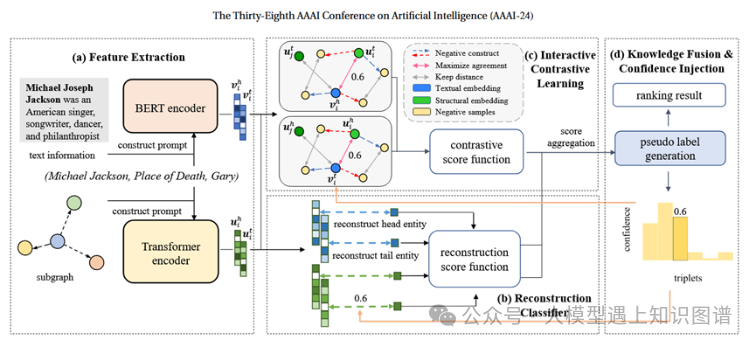
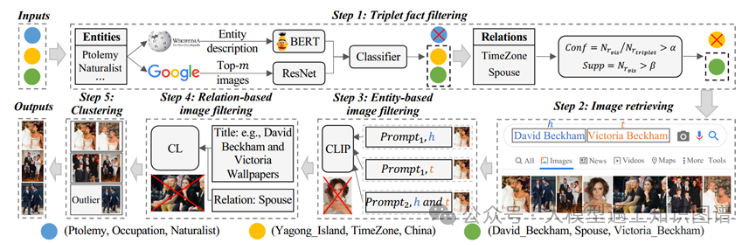
15:Beyond Entities: A Large-Scale Multi-Modal Knowledge Graph with Triplet Fact Grounding
作者:Jingping Liu, Mingchuan Zhang, Weichen Li, Chao Wang, Shuang Li, Haiyun Jiang, Sihang Jiang, Yanghua Xiao, Yunwen Chen
摘要:人们致力于通过在图像上可视化实体来构建多模态知识图,但忽略了实体之间关系的多模态信息。因此,在本文中,我们的目标是构建一个新的大规模多模态知识图,其基于基于图像的三元组事实,不仅反映实体,而且反映它们的关系。为了实现这一目的,我们提出了一种新颖的管道方法,包括三元组事实过滤、图像检索、基于实体的图像过滤、基于关系的图像过滤和图像聚类。这样就构建了一个名为ImgFact的多模态知识图谱,其中包含247,732个三元组事实和3,730,805张图像。在实验中,手动和自动评估证明了我们的ImgFact的可靠质量。我们进一步使用获得的图像来增强模型在两项任务上的性能。特别是,与现有多模态知识图和关系分类 F1 上的 VisualChatGPT 增强的解决方案相比,通过我们的 ImgFact 优化的模型实现了令人印象深刻的 8.38% 和 9.87% 的改进。我们在 https://github.com/kleinercubs/ImgFact 发布了ImgFact及其说明。
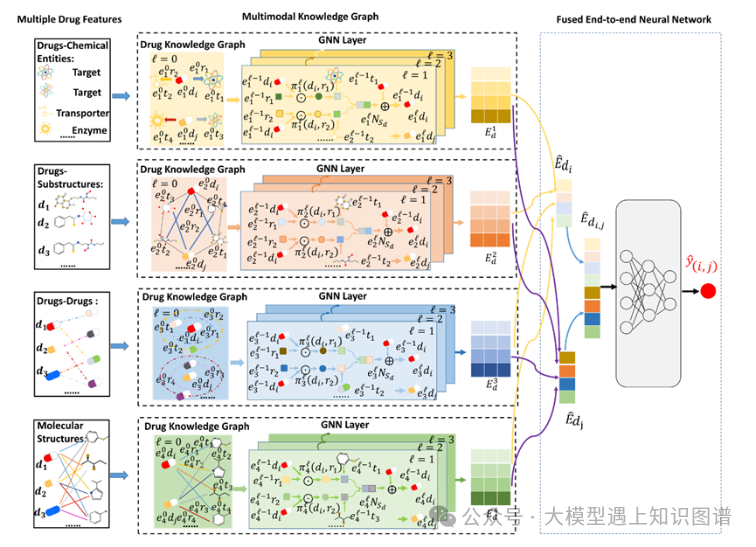
16:MKG-FENN: A Multimodal Knowledge Graph Fused End-to-End Neural Network for Accurate Drug–Drug Interaction Prediction
作者:Di Wu, Wu Sun, Yi He, Zhong Chen, Xin Luo
摘要:将不相容的多种药物一起服用可能会对身体产生不良相互作用和副作用。准确预测药物相互作用 (DDI) 事件对于避免此问题至关重要。最近,人们提出了各种基于人工智能的方法来预测 DDI 事件。然而,DDI事件与药物、靶标、酶、转运蛋白、分子结构等之间复杂的关系和机制相关。现有方法通过非端到端的学习框架部分或松散地考虑这些关系和机制,导致 用于预测的次优特征提取和融合。与它们不同的是,本文提出了一种多模态知识图融合端到端神经网络(MKGFENN),它由两个主要部分组成:多模态知识图(MKG)和融合端到端神经网络(FENN)。首先,MKG是通过从药物-化学实体、药物子结构、药物-药物和分子结构四个知识图谱中综合利用DDI事件相关关系和机制来构建的。相应地,设计了一个四通道图神经网络来从 MKG 中提取高阶和语义特征。其次,FENN 设计了一个多层感知器,通过端到端学习来融合提取的特征。通过这样的设计,可以保证 DDI 事件的特征提取和融合是全面且最佳的预测。通过对真实药物数据集的大量实验,我们证明 MKG-FENN 在预测 DDI 事件方面表现出很高的准确性,并且显着优于最先进的模型。本文的源代码和补充文件可在:https://github.com/wudi1989/MKG-FENN 获取。
17:Bayesian Inference with Complex Knowledge Graph Evidence
作者:Armin Toroghi, Scott Sanner
摘要:知识图(KG)提供了一种广泛使用的格式来表示实体及其关系,并已在包括问答和推荐在内的各种应用中得到使用。当前关于 KG 推理的大多数研究都集中在使用原子事实(三元组)进行推理,而忽略了进行涉及逻辑运算符(否定、合取、析取)和量词(存在、普遍)的复杂证据观察的可能性。此外,虽然在基于知识图谱的查询回答(KGQA)研究中已经探索了复杂证据的应用,但在许多实际的在线环境中,观察是按顺序进行的。例如,在 KGQA 中,可能会逐步建议其他上下文以缩小答案范围。或者在交互式推荐中,可以按顺序表达用户评论,以缩小首选项目的集合范围。这两种设置都表示信息过滤或跟踪任务,这让人想起贝叶斯推理中的置信跟踪。事实上,在本文中,我们精确地将给定增量复杂知识图谱证据的未知知识图谱实体的信念跟踪问题转化为贝叶斯过滤问题。具体来说,我们利用基于知识的模型构建(KBMC)而不是逻辑知识图谱证据来实例化马尔可夫随机场(MRF)似然表示,以使用复杂的知识图谱证据(BIKG)执行封闭式贝叶斯推理。我们在增量 KGQA 和交互式推荐任务中对 BIKG 进行了实验评估,证明它优于非增量方法,并且与利用模糊 T 范数运算符的 CQD 等现有复杂KGQA方法相比,可以更好地结合联合证据。总的来说,这项工作通过封闭式 BIKG 的视角展示了一种新颖、高效、统一的逻辑、KG 和在线推理视角。
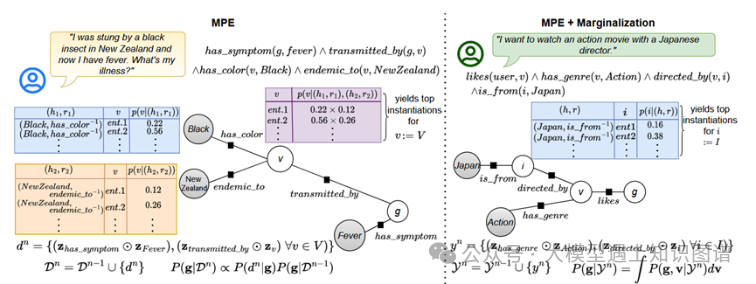
18、Anchoring Path for Inductive Relation Prediction in Knowledge Graphs
作者:Zhixiang Su, Di Wang, Chunyan Miao, Lizhen Cui
摘要:关系预测旨在准确预测现实世界知识图谱(KG)中普遍存在的代表实体之间关系的缺失边,关系预测在增强知识图谱的综合性和实用性方面发挥着至关重要的作用。最近的研究重点是基于路径的方法,因为它们具有归纳性和可解释的特性。然而,当大量推理路径在知识图谱中没有形成闭合路径(CP)时,这些方法面临着巨大的挑战。为了应对这一挑战,我们提出锚定路径句子转换器(APST),通过引入锚定路径(AP)来减轻对 CP 的依赖。具体来说,我们开发了一种基于搜索的描述检索方法来丰富实体描述,并开发了一种评估机制来评估AP的合理性。APST将AP和CP作为统一Sentence Transformer架构的输入,从而实现全面的预测和高质量的解释。我们在三个公共数据集上评估 APST,并在 36 个传导、归纳和少样本实验设置中的 30 个中实现了最先进的 (SOTA) 性能。
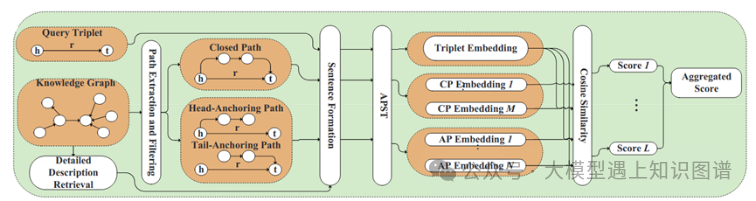
20. LAFA: Multimodal Knowledge Graph Completion with Link Aware Fusion and Aggregation
作者: Cunhang Fan, Yujie Chen, Jun Xue, Yonghui Kong, Jianhua Tao, Zhao Lv
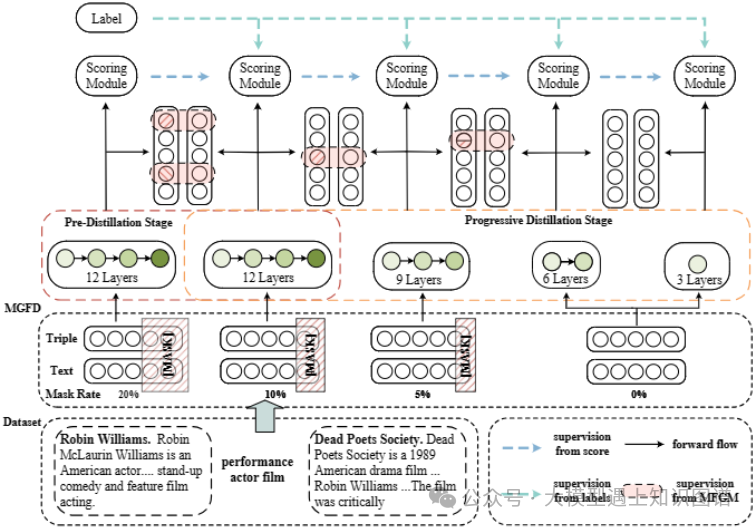
摘要:近年来,基于预训练语言模型(PLM)的知识图完成(KGC)模型取得了良好的效果。然而,PLM模型的大量参数和高计算成本对其在下游任务中的应用提出了挑战。本文针对KGC任务提出了一种基于掩蔽生成特征的渐进蒸馏方法,旨在显著降低预训练模型的复杂度。具体来说,我们在PLM上进行预蒸馏以获得高质量的教师模型,并压缩PLM网络以获得多年级的学生模型。然而,传统的特征提取受到教师模型中信息单一表示的限制。为了解决这个问题,我们提出了师生特征的掩蔽生成,其中包含更丰富的表示信息。同时,教师和学生在表现能力上存在着显著的差距。因此,我们设计了一种渐进式提取方法来提取每个年级的学生模型,从而实现从教师到学生的有效知识转移。实验结果表明,该模型在预蒸馏阶段超过了现有的先进方法。此外,在渐进蒸馏阶段,该模型显著降低了模型参数,同时保持了一定的性能水平。具体而言,与基线相比,低年级学生模型的模型参数减少了56.7%。
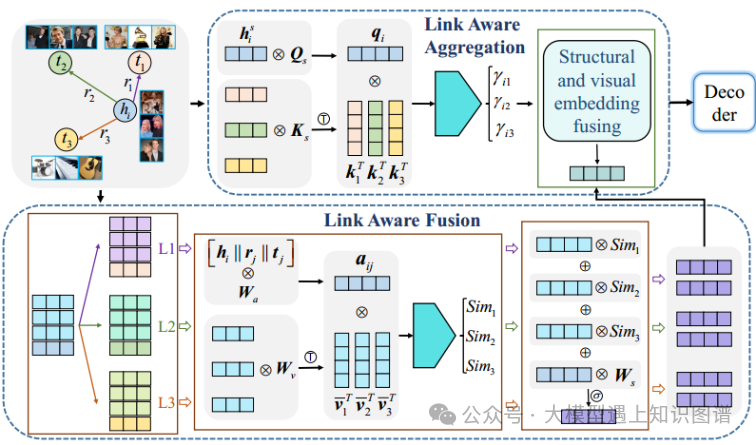
21. Progressive Distillation based on Masked Generation Feature Method for Knowledge Graph Completion
作者:Cunhang Fan, Yujie Chen, Jun Xue, Yonghui Kong, Jianhua Tao, Zhao Lv*
摘要:近年来,基于预训练语言模型(PLM)的知识图完成(KGC)模型取得了良好的效果。然而,PLM模型的大量参数和高计算成本对其在下游任务中的应用提出了挑战。本文针对KGC任务提出了一种基于掩蔽生成特征的渐进蒸馏方法,旨在显著降低预训练模型的复杂度。具体来说,我们在PLM上进行预蒸馏以获得高质量的教师模型,并压缩PLM网络以获得多年级的学生模型。然而,传统的特征提取受到教师模型中信息单一表示的限制。为了解决这个问题,我们提出了师生特征的掩蔽生成,其中包含更丰富的表示信息。同时,教师和学生在表现能力上存在着显著的差距。因此,我们设计了一种渐进式提取方法来提取每个年级的学生模型,从而实现从教师到学生的有效知识转移。实验结果表明,该模型在预蒸馏阶段超过了现有的先进方法。此外,在渐进蒸馏阶段,该模型显著降低了模型参数,同时保持了一定的性能水平。具体而言,与基线相比,低年级学生模型的模型参数减少了56.7%。
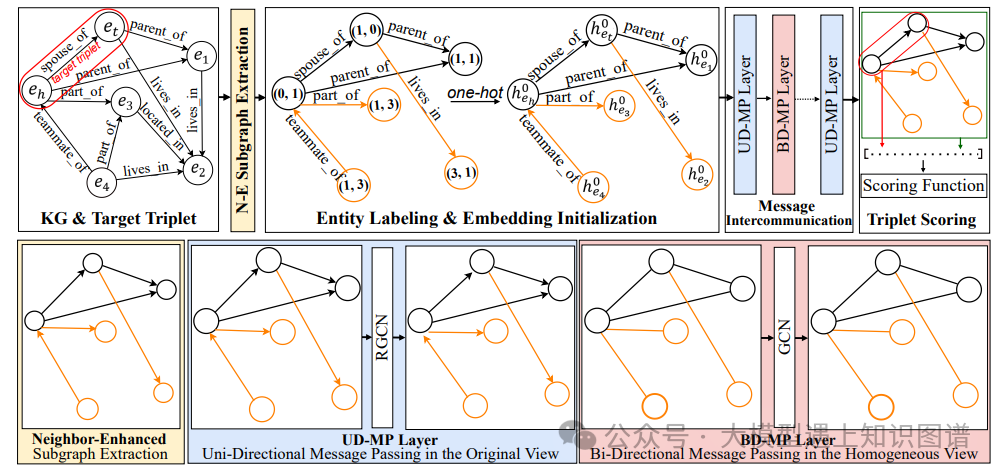
22. MINES: Message Intercommunication for Inductive Relation Reasoning over Neighbor-Enhanced Subgraphs
作者: Ke Liang, Lingyuan Meng, Sihang Zhou, Wenxuan Tu, Siwei Wang, Yue Liu, Meng Liu, Long Zhao, Xiangjun Dong, Xinwang Liu
摘要:GraIL及其变体在知识图的归纳关系推理方面显示出了良好的能力。然而,单向消息传递机制阻碍了这种模型利用有向图中实体之间隐藏的相互关系。此外,大多数基于grail的模型中的封闭子图提取限制了模型提取足够的判别信息进行推理。因此,这些模型的表达能力是有限的。为了解决这些问题,我们提出了一种新的基于grail的框架,称为MINES,通过在邻居增强子图上引入消息交互机制。具体而言,设计了消息交互机制来捕获遗漏的隐藏互信息。通过在无向RGCN层之间插入无向/双向GCN层,引入连接实体之间的双向信息交互。此外,受其他基于图的任务中涉及更多邻居的成功启发,我们将邻居区域扩展到封闭子图之外,以增强归纳关系推理的信息收集。大量的试验从各个方面证明了所提出的MINES的潜力,特别是其优越性、有效性和转移能力。
腾讯云开发者
