【论文复现】揭秘AI如何揪出图片中的“李鬼“


文字篡改图像的“照妖镜”:揭秘AI如何揪出图片中的“李鬼”
在当下的数字洪流中,各类图像信息如潮水般涌向我们,其中不乏暗藏玄机的被篡改文字或图像,它们悄无声息地影响着我们的判断,有时甚至会引发严重的后果。但幸运的是,随着人工智能(AI)的飞跃进步,我们手中已握有一把利剑,能够揭露这些图像中的“伪装者”。
我们的AI系统如同一位敏锐的侦探,能够接收用户提交的疑似遭篡改的文字图像,并运用深度学习与图像分析技术,精准锁定并标记出图像中可能存在的篡改痕迹。这对于新闻界人士、调查专家乃至广大网民而言,都是一项极具价值的技能。
然而,我们也需坦诚相告,尽管我们的系统在检测文字图像篡改方面表现出色,但并非无所不能。AI的效能受限于其训练数据和算法框架。面对如物体移除或人脸篡改等更为复杂的图像操作,我们的系统可能难以提供同等精准的反馈。这主要是因为这些篡改手段涉及更高深的图像处理与合成技巧,需要更为先进的算法和庞大的数据集作为支撑。
此外,我们还需提醒用户,系统的表现与训练数据集息息相关。不同的数据集会引导系统学习到不同的特征模式。因此,使用不同数据集训练的模型,在检测同一张图片时,可能会产生迥异的结果。这也是我们在提供服务时,会明确告知用户所用数据集及训练流程的原因。
对于追求更高检测精度的用户,我们鼓励他们利用自己的数据集来定制模型。通过搜集更多样、更贴近实际应用需求的图像素材,用户可以打造出更为精确、更符合自身需求的AI模型。当然,这要求一定的技术功底和实践经验,但这也是AI技术的独特魅力所在——它赋予了我们根据个人需求定制和优化解决方案的能力。
前言
- 在如今这个“P图大神”遍地走的时代,图片的真实性越来越难以保证。尤其是在文档图像领域,篡改文字、伪造证书等行为可能带来严重的风险。想象一下,你正准备签一份重要合同,却发现附件中的资质证书似乎有点不对劲。是的,你没猜错,这正是图像篡改的“作案现场”。

文字图像篡改,听起来是不是很像电影里的高级犯罪?但这可不仅仅是电影情节,它真实地发生在我们的数字生活中。文档图像篡改指的是对文档图像进行的未经授权的修改,包括文字、图表、印章等内容的删除、修改、添加或替换。 当你怀疑一张图片被篡改时,你会怎么做?是不是会像侦探一样,拿着放大镜仔细观察,寻找蛛丝马迹?AI侦探也是如此,它会运用一种叫做注意力机制的技术,就像人眼一样,不断放大缩小图像,对比观察不同区域的特征,从而精准定位篡改区域。这种技术的运用,不仅提高了检测的准确性,也极大提升了效率,让AI在图像取证领域展现出了惊人的潜力。 但AI侦探的“火眼金睛”是如何炼成的呢?这就不得不提到一项最新的研究成果——一种结合了伪造痕迹增强和多尺度注意力机制的网络框架。这个框架通过深度学习算法,能够从多个维度分析图像,识别出那些肉眼难以察觉的篡改痕迹。 研究人员们通过构建一个大规模的文本图像篡改数据集,训练AI侦探识别各种篡改手段。在实验中,AI侦探展现出了极高的准确率,即使是面对经过精心伪装的篡改图像,也难逃它的“法眼”。 这项技术的出现,无疑为我们的数字生活增添了一份安全保障。它不仅能够帮助我们识别出那些潜在的风险,更能够提升我们对数字内容的信任度。在未来,随着技术的不断进步,AI侦探将更加智能,成为我们守护信息安全的重要伙伴。
AI侦探的“放大镜”和“显微镜”:揭秘注意力机制如何工作
想象一下,当你怀疑一张图片被篡改时,你会怎么做?是不是会像侦探一样,拿着放大镜仔细观察,寻找蛛丝马迹?AI侦探也是如此,它会运用一种叫做注意力机制的技术,就像人眼一样,不断放大缩小图像,对比观察不同区域的特征,从而精准定位篡改区域。
那么,这个神秘的注意力机制是如何工作的呢?首先,AI模型会像一位细心的侦探一样,对图像进行彻底的特征提取,分析并记录下各种特征,比如颜色、纹理、形状等。这些特征就像是图像的指纹,为后续的分析提供了重要的线索。接着,模型会根据这些特征的重要性,为图像的不同区域分配不同的权重。这就好比侦探在案件中,会根据嫌疑人的可疑程度给予不同的关注。在图像篡改的案件中,那些与周围环境不一致的区域,往往就是篡改的痕迹,因此会被赋予更高的权重。最后,模型会根据权重分布,将注意力集中在最有可能被篡改的聚焦区域,进行更深入的分析。这就好比侦探在案件的关键环节,会集中精力,深入挖掘线索,力求揭开真相。注意力机制的优势显而易见。它不仅能够精准定位篡改痕迹,减少误判率,还能够高效处理图像数据,通过合理分配计算资源,只关注重要的区域。此外,它的权重分布还具有很好的可解释性,能够直观地展示模型的关注点,让整个过程更加透明。
- 实战演练:复现论文代码 当然,光说不练假把式。在接下来的文章中,我们将以一篇论文为例,论文题目是《Robust Text Image Tampering Localization via Forgery Traces Enhancement and Multiscale Attention》,于24年2月发表在SCI二区期刊**IEEE Transactions on Consumer Electronics上,**详细讲解文字篡改图像的检测定位技术,并带你一起复现论文中的代码。通过亲自动手实践,你将更深入地理解这项技术的原理和实现过程,也能更好地掌握AI侦探的“火眼金睛”。
论文背景
在数字化时代,图像已成为信息传播的主要载体之一。无论是社交媒体分享,还是正式文件电子版,图像都扮演着关键角色。然而,随着图像编辑技术的飞速发展,尤其是深度学习和人工智能的介入,图像篡改变得前所未有的容易。一些不法分子利用这些技术,对图像内容进行非法篡改,以达到误导、欺诈甚至更严重的犯罪目的。
其中,文字图像篡改尤其值得关注。如资质证书、官方文件、合同协议等,文字篡改可能导致极其严重的后果。一份被篡改的合同文本,可能会造成巨大的经济损失;一张伪造的身份证,可能被用于洗钱或其他犯罪活动。因此,研究和开发有效的文字图像篡改检测技术,对于维护社会秩序、保护公民权益、促进信息安全具有重大意义。相较于自然图像,文本图像中轻微的篡改(如单个字符)可能会大幅改变其语义,因此确保文本图像真实性至关重要。与自然图像相比,文本图像篡改检测面临独特挑战,包括均匀的纹理、简单的封闭边界,以及对象之间的规则间隙。篡改区域可能微小(如单个字符),与背景对比度也很微妙,这使得文本图像篡改检测更具挑战性。
文字图像篡改检测面临着独特的挑战:
文字图像具有均匀的纹理、简单的边界和规则的间隙,使得篡改区域难以识别。 篡改区域可能非常小(例如单个字符),并且与背景的对比度微妙,增加了检测难度。 现实场景中的伪造图像可能经过压缩、重拍或图像融合等后处理,进一步掩盖了篡改痕迹,降低了检测算法的有效性。 尽管已有一些相关方法,但大多数现有算法是在受控实验室环境中开发和验证的,缺乏对真实场景的鲁棒性和普遍性考虑。在实际情况中,伪造图像不可避免地会遭受后处理,如有损压缩、重新捕捉或复杂融合,这些操作可能掩盖篡改痕迹,严重降低了篡改定位性能。
论文思路
在文字图像篡改检测这一领域,该论文提出了一种创新的网络框架,旨在提升检测的准确性和鲁棒性。论文的核心思路是通过增强篡改痕迹和应用多尺度注意力机制,来精确地定位和检测图像中的篡改区域。这一思路的提出,基于对现有技术的深刻理解和对现实挑战的准确把握。
该篇论文的主要贡献点为:
- 篡改痕迹增强网络:论文中提出的伪造痕迹增强网络是一个创新点。该网络能够从多个领域增强伪造痕迹,减少背景干扰,这对于提高篡改区域的检测精度至关重要。这一模块的设计,使得模型能够更好地聚焦于潜在的篡改区域,而不是被图像的非篡改部分所分散注意力。
- 多尺度注意力机制:通过设计一个多尺度注意力模块,论文进一步创新了特征融合策略。这种机制类似于人类视觉系统的工作方式,能够同时关注图像的宏观结构和微观细节,从而更全面地捕捉篡改特征。
- 编码器-解码器网络:论文中提出的编码器-解码器网络结构,通过融合高级语义和低级视觉细节,进一步提升了篡改特征的提取能力。这种结构的设计,使得模型在处理复杂的图像篡改时,能够保持高效的特征传递和信息恢复。
- 大规模数据集构建:为了验证所提方法的有效性,研究者构建了一个大规模的文本图像篡改数据集。该数据集包含了多种篡改方法和失真情况,为研究者提供了一个全面评估模型性能的平台。
- 在文字图像篡改检测领域,该论文的提出的方法与现有技术相比,具有显著的优势。传统的篡改检测方法往往依赖于单一的特征提取或简单的机器学习模型,这在面对复杂的篡改手段时,容易受到干扰和欺骗。而该论文提出的方法,通过深度学习技术的应用,能够从更深层次理解图像内容,从而提高检测的准确性。此外,论文中的方法在设计时,充分考虑了现实世界中的复杂情况。例如,现实世界中的篡改图像往往会经历多次压缩、传输和编辑,这些操作会在图像中留下难以察觉的痕迹。通过增强这些痕迹并应用多尺度分析,论文中的方法能够有效地抵抗这些干扰,提高检测的鲁棒性。论文中的模型在多种真实世界的失真场景下进行了测试,包括JPEG压缩、图像重摄和屏幕截图等。这些测试结果证明了模型不仅在理论上是可行的,而且在实际应用中也具有很高的鲁棒性。
模型结构
该论文针对这一问题,提出了一种创新的解决方案,如图所示,该方法主要包括三个关键阶段:训练数据集的构建,篡改痕迹增强和文本图像篡改定位。
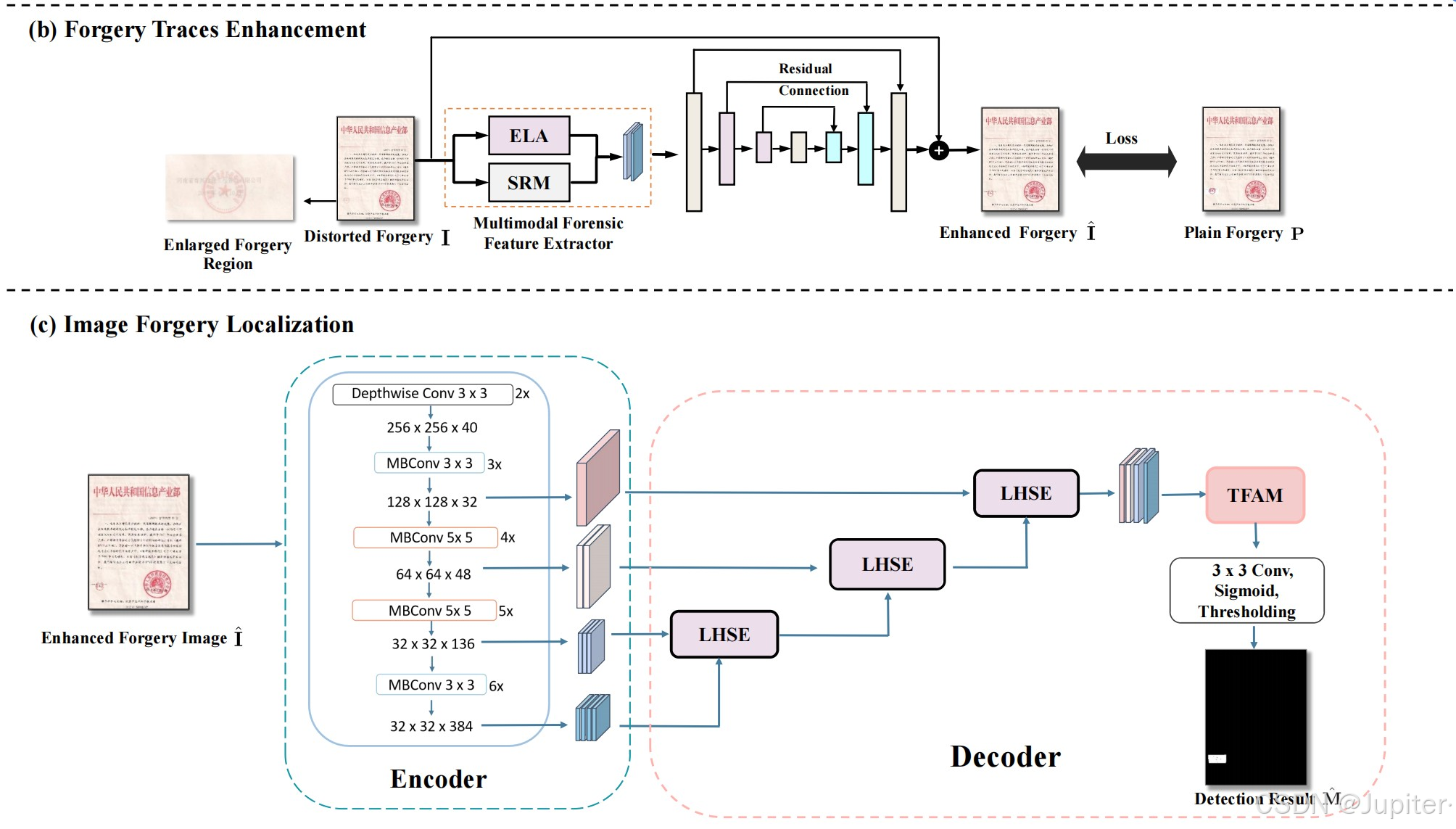
篡改痕迹增强网络
经过篡改的文本图像常常会经历如JPEG压缩等后处理操作,这些操作往往会损害或掩盖篡改的痕迹。针对这一问题,该论文提出了一种篡改痕迹增强网络模块,其核心目的是提升图像定位在面临有损后处理时的鲁棒性。
该网络模块由两个主要部分构成:多模态特征提取器和篡改痕迹增强网络。多模态特征提取器采用两种不同的特征算子,分别从空间域和错误级域中提取篡改的线索。恢复网络则采用融合的特征,并应用类似UNet的网络结构,其主要目标是通过残差学习来恢复细微的篡改痕迹。此外,该恢复网络还能抑制非篡改相关的图像伪影,并尝试恢复纯篡改图像,以便于进一步的定位。
该网络结合了误差级别分析(Error Level Analysis,ELA)和空间丰富模型(Spatial Rich Model,SRM)来提取粗略的篡改伪影。SRM模块在空间域中操作,提供了图像的空间统计信息和文本结构的重要线索。ELA模块则在误差级别域中工作,揭示出篡改过程中引入的差异和伪影。这两种模态的融合为后续模块提供了区分真实区域和被篡改区域的有力特征。因此,多模态特征提取器包括ELA和SRM两个算子,其可表示为:

文本图像篡改定位网络
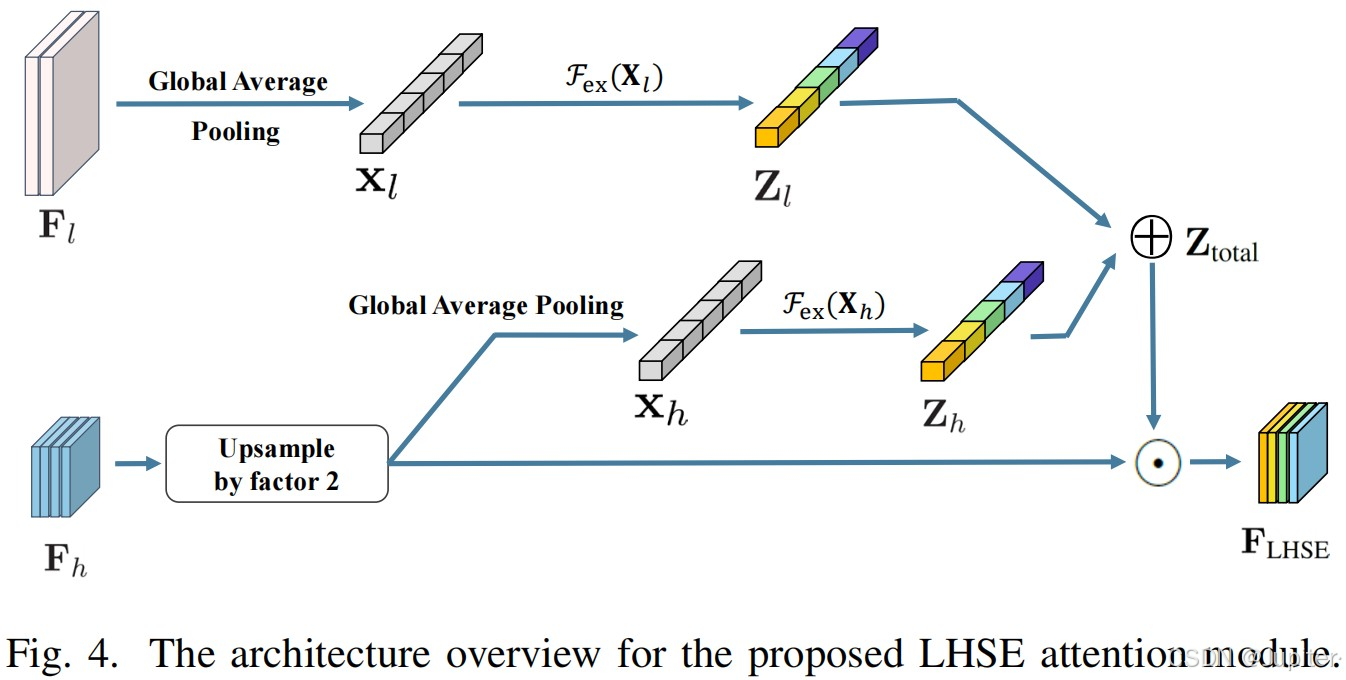
在文字图像篡改检测领域,该论文引入了一个关键创新点——LHSE(Local and Hierarchical Semantic Enhancement)模块。该模块旨在通过局部和层次化的语义增强,进一步提升篡改检测的性能。具体来说,LHSE模块首先利用局部卷积操作精细捕捉图像中的局部特征,这些特征能够精确反映图像各区域的细节信息,特别是潜在的篡改区域。通过精心设计的卷积核大小和步长,模块能够提取出多尺度的局部特征,为后续的语义增强提供了丰富的信息基础。
接下来,LHSE模块利用层次化的语义融合策略整合这些局部特征。它采用多尺度金字塔结构,将不同层次的特征进行融合,从而全面捕获从微观到宏观的全方位信息。这种层次化的处理方式不仅有助于模型更好地理解图像的结构和上下文信息,还显著提高了篡改检测的准确性。
为了进一步增强篡改痕迹的表达能力,LHSE模块还引入了一种语义增强机制。通过对特征图进行非线性变换和重新加权,模块能够突出显示潜在的篡改区域,并有效抑制背景干扰。这种增强操作使模型能够更加专注于篡改痕迹,从而提高了检测的灵敏度。
在实际应用中,LHSE模块不仅显著增强了图像中篡改痕迹的表达能力,使模型能够更准确地定位和识别篡改区域,还提高了检测的精度和可靠性。同时,该模块的设计充分考虑了现实世界中的多种失真场景,如JPEG压缩、图像重摄等,通过提取多尺度的局部特征和进行层次化的语义融合,模块能够在这些复杂场景下保持稳定的性能,从而增强了模型的鲁棒性。
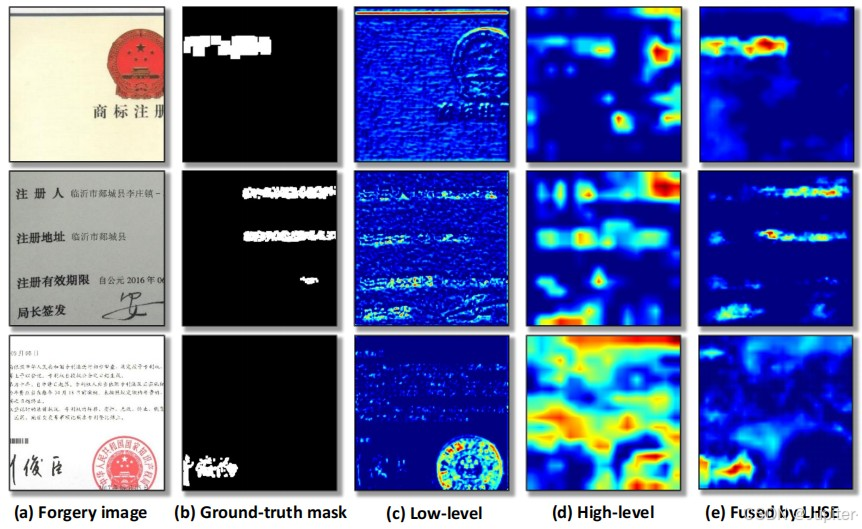
下图是对LHSE模块前后的特征映射的可视化。从左到右两列分别为输入的篡改图像、真实掩模、LHSE模块前后的特征结果。由最后一列的结构可以看出,LHSE模块生成的融合特征图有效地捕获了被篡改的区域。
损失函数
该论文提出了一种损失函数,旨在提高文本图像篡改检测的准确性。该损失函数将权重二进制交叉熵(WeightBCE)和权重骰子损失(WeightDice)进行组合,以平衡正负样本和困难样本的权重。
具体而言,权重二进制交叉熵损失函数通过引入额外的权重参数q,控制负样本与正样本的比例,从而有效解决训练过程中正负样本的不平衡问题。权重骰子损失函数则计算预测掩膜和对应真值掩膜之间的交集和并集,以量化预测和真值之间的重叠程度。同时,通过引入权重参数p,该损失函数可以调整困难样本的权重,以提高检测的准确性。
综合而言,该损失函数能够有效地利用权重二进制交叉熵损失函数的优势,惩罚模型在错误区域过度自信的倾向,同时利用权重骰子损失函数的优势,量化预测和真值之间的重叠程度。通过合理地平衡正负样本和困难样本的权重,该损失函数在文本图像篡改检测任务中取得了较好的性能。

复现过程
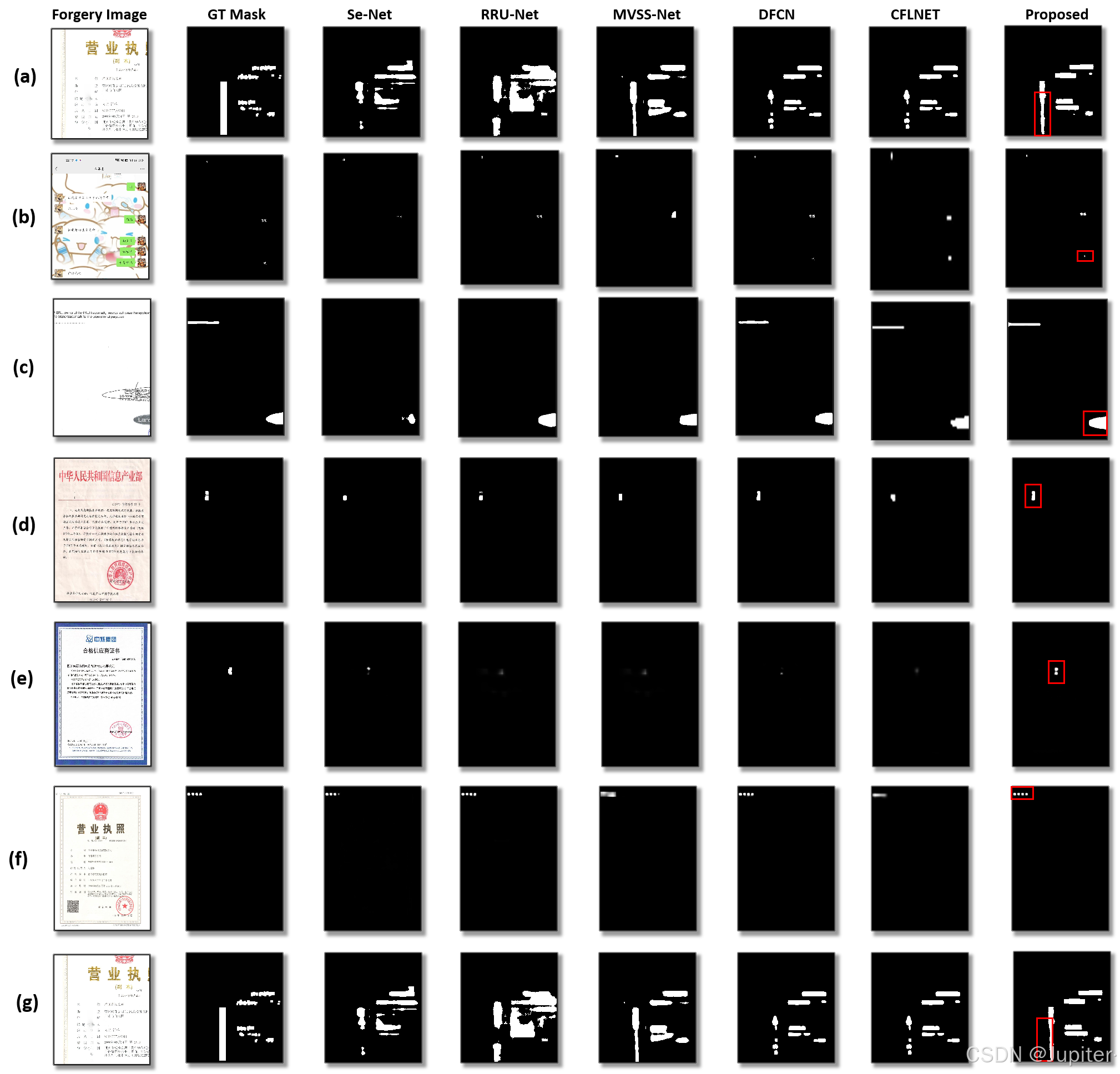
在图像篡改检测的研究领域,首先关注实验结果的可视化图像,其中“Images”列展示了被篡改的原始图像,而“Mask”列则呈现了对应的篡改区域。该研究的主要目标是实现图像篡改区域的精确定位。从图像分类的角度来看,这个问题可以被视为一个逐像素级别的二分类任务。具体来说,针对被篡改的图像A中的每个像素点(x,y),模型需要对其是否被篡改进行判断。如果模型判断一个像素点被篡改,则输出1;否则,输出0。通过这种方式,所有像素点的0和1输出组合成了一张与原始图像A分辨率相同的二值掩膜图像。在这张掩膜图像中,白色区域代表了图像中被篡改的位置,而黑色区域则表示未被篡改的部分。通过生成精确的篡改区域图,篡改检测模型能够辅助用户识别和定位图像中的不真实内容。在本文的可视化结果中,所提出的方法表现出对小规模篡改区域的精确定位能力,例如单个数字或字符的篡改。这种能力得益于所采用的多尺度特征融合机制,它能够有效整合高层语义特征和低层视觉细节。此外,从可视化结果中可以观察到,所提出的方法不仅能够突出微小篡改区域,而且能够有效抑制背景噪声,尤其在复杂文本图像背景下,仍能准确识别篡改区域,不受背景噪声的干扰。
复现过程可以分解成以下几个模块分别实现(以下只给出代码的关键部分):
- 使用python代码实现给出的损失函数公式;
- 使用pytorch代码搭建模型网络结构搭建;
- 整体训练框架搭建;
- 设置参数,训练和测试模型;
步骤一:
- 使用python代码实现给出的损失函数公式,由上可得,总损失函数由两个损失函数组成,分别是
import torch.nn.functional as F
import torch.nn as nn
######## Weighted BCE Loss ###########
class WeightedBCE(nn.Module):
def __init__(self, weights=[0.2, 0.8]):
super(WeightedBCE, self).__init__()
self.weights = weights
def forward(self, logit_pixel, truth_pixel):
logit = logit_pixel.reshape(-1)
truth = truth_pixel.reshape(-1)
assert(logit.shape==truth.shape)
loss = F.binary_cross_entropy(logit, truth, reduction='mean')
pos = (truth>=0.35).float()
neg = (truth<0.35).float()
pos_weight = pos.sum().item() + 1e-12
neg_weight = neg.sum().item() + 1e-12
loss = (self.weights[0]*pos*loss/pos_weight + self.weights[1]*neg*loss/neg_weight).sum()
return loss
######## Weighted Dice Loss ###########
class WeightedDiceLoss(nn.Module):
def __init__(self, weights=[0.5, 0.5]): # W_pos=0.8, W_neg=0.2
super(WeightedDiceLoss, self).__init__()
self.weights = weights
def forward(self, logit, truth, smooth=1e-5):
batch_size = len(logit)
logit = logit.reshape(batch_size,-1)
truth = truth.reshape(batch_size,-1)
assert(logit.shape==truth.shape)
p = logit.view(batch_size,-1)
t = truth.view(batch_size,-1)
w = truth.detach()
w = w*(self.weights[1]-self.weights[0])+self.weights[0]
p = w*(p)
t = w*(t)
intersection = (p * t).sum(-1)
union = (p * p).sum(-1) + (t * t).sum(-1)
dice = 1 - (2*intersection + smooth) / (union +smooth)
loss = dice.mean()
return loss
######## Total Loss = WeightedDice Loss + WeightedBCE###########
class WeightedDiceBCE(nn.Module):
def __init__(self,dice_weight=1,BCE_weight=1):
super(WeightedDiceBCE, self).__init__()
self.BCE_loss = WeightedBCE(weights=[0.8, 0.2])
self.dice_loss = WeightedDiceLoss(weights=[0.5, 0.5])
self.BCE_weight = BCE_weight
self.lovasz_weight = 0
self.dice_weight = dice_weight
def forward(self, inputs, targets):
dice = self.dice_loss(inputs, targets)
BCE = self.BCE_loss(inputs, targets)
dice_BCE_loss = self.dice_weight * dice + self.BCE_weight * BCE
return dice_BCE_loss步骤二:
使用pytorch代码搭建模型网络结构搭建,这一步的关键是根据对网络的描述实现对上述LHSE模块和TFAM模块的结构搭建:
## 如下代码是使用torch对LHSE模块的搭建
import torch
import torch.nn as nn
import torch.nn.functional as F
class LHSE(nn.Module):
def __init__(self):
super(LHSE, self).__init__()
self.conv1h = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn1h = nn.BatchNorm2d(64)
self.conv2h = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn2h = nn.BatchNorm2d(64)
self.conv3h = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn3h = nn.BatchNorm2d(64)
self.conv4h = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn4h = nn.BatchNorm2d(64)
self.conv1v = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn1v = nn.BatchNorm2d(64)
self.conv2v = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn2v = nn.BatchNorm2d(64)
self.conv3v = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn3v = nn.BatchNorm2d(64)
self.conv4v = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn4v = nn.BatchNorm2d(64)
def forward(self, left, down):
if down.size()[2:] != left.size()[2:]:
down = F.interpolate(down, size=left.size()[2:], mode='bilinear')
out1h = F.relu(self.bn1h(self.conv1h(left )), inplace=True)
out2h = F.relu(self.bn2h(self.conv2h(out1h)), inplace=True)
out1v = F.relu(self.bn1v(self.conv1v(down )), inplace=True)
out2v = F.relu(self.bn2v(self.conv2v(out1v)), inplace=True)
fuse = out2h*out2v
out3h = F.relu(self.bn3h(self.conv3h(fuse )), inplace=True)+out1h
out4h = F.relu(self.bn4h(self.conv4h(out3h)), inplace=True)
out3v = F.relu(self.bn3v(self.conv3v(fuse )), inplace=True)+out1v
out4v = F.relu(self.bn4v(self.conv4v(out3v)), inplace=True)
return out4h, out4v
def initialize(self):
weight_init(self)步骤三:
整体训练框架搭建,该步骤主要包含对数据集的处理和加载、loss的梯度更新等
# 定义训练函数
def train(train_loader, model, criterion1,optimizer, epoch, params,global_step):
metric_monitor = MetricMonitor() # 初始化指标监视器
model.train() # 设置模型为训练模式
stream = tqdm(train_loader,desc='processing',colour='CYAN') # 创建数据加载器的进度条
for i, (images, masks,_) in enumerate(stream, start=1): # 遍历数据加载器
images = images.cuda(non_blocking=params['non_blocking_']) # 将图像数据传输到GPU
masks = masks.cuda(non_blocking=params['non_blocking_']) # 将掩码数据传输到GPU
reg_outs = model(images) # 通过模型前向传播图像数据
reg_outs = torch.sigmoid(reg_outs) # 应用Sigmoid激活函数
loss = criterion1(reg_outs, masks) # 计算损失
optimizer.zero_grad() # 清空优化器的梯度
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
global_step += 1 # 增加全局步数
# 定义训练和验证函数
def train_and_validate(model, optimizer,train_dataset,val_dataset, params,epoch_start = 1,best_acc=0):
train_loader = DataLoader( # 创建训练数据加载器
train_dataset,
batch_size=params["batch_size"], # 指定批量大小
shuffle=True, # 随机打乱数据
num_workers=params["num_workers"], # 指定工作进程数
pin_memory=True, # 是否将数据固定在内存中
drop_last=True, # 是否丢弃最后一个不完整的批量
)
val_loader = DataLoader( # 创建验证数据加载器
val_dataset,
batch_size=params["test_batch_size"], # 指定批量大小
shuffle=False, # 不随机打乱数据
num_workers=params["num_workers"], # 指定工作进程数
pin_memory=True, # 是否将数据固定在内存中
drop_last=False, # 不丢弃最后一个不完整的批量
)
# 定义损失函数
criterion_1 = WeightedDiceBCE(dice_weight=5,BCE_weight=5).cuda()
global_step = 0 # 初始化全局步数为0
for epoch in range(epoch_start, params["epochs"] + 1): # 遍历指定的训练周期
train(train_loader, model,criterion_1,optimizer, epoch, params,global_step) # 调用训练函数编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-11-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号