【机器学习实战】 手把手教学,kaggle贷款批准预测 (使用xgboost解决正负样本不平衡问题)

【机器学习实战】 手把手教学,kaggle贷款批准预测 (使用xgboost解决正负样本不平衡问题)

机器学习司猫白
发布于 2025-01-21 17:45:15
发布于 2025-01-21 17:45:15
Hello 大家好,今天和大家分享一个kaggle贷款批准预测的竞赛,使用xgboost方法进行预测。
数据描述
train.csv - 训练数据集;loan_status是二进制目标 test.csv - 测试数据集;
id — ID(记录编号) person_age — 年龄 person_income — 收入 person_home_ownership — 房屋拥有情况 person_emp_length — 工作年限 loan_intent — 贷款意图 loan_grade — 贷款等级 loan_amnt — 贷款金额 loan_int_rate — 贷款利率 loan_percent_income — 贷款收入比 cb_person_default_on_file — 个人信用记录中是否有违约记录 cb_person_cred_hist_length — 信用历史长度 loan_status — 贷款状态
源码分析
话不多说,让我们进入分析。
import numpy as np
import pandas as pd
train_data = pd.read_csv(train.csv')
test_data = pd.read_csv('test.csv')
train_data.imnfo()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 58645 entries, 0 to 58644
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 58645 non-null int64
1 person_age 58645 non-null int64
2 person_income 58645 non-null int64
3 person_home_ownership 58645 non-null object
4 person_emp_length 58645 non-null float64
5 loan_intent 58645 non-null object
6 loan_grade 58645 non-null object
7 loan_amnt 58645 non-null int64
8 loan_int_rate 58645 non-null float64
9 loan_percent_income 58645 non-null float64
10 cb_person_default_on_file 58645 non-null object
11 cb_person_cred_hist_length 58645 non-null int64
12 loan_status 58645 non-null int64
dtypes: float64(3), int64(6), object(4)
memory usage: 5.8+ MB通过观察数据基本信息可以发现,数据已经是进行过初步处理的,不存在缺失值,且字段基本都是数值类型。
## 查看目标变量分布
train_data['loan_status'].value_counts()loan_status
0 50295
1 8350
Name: count, dtype: int64预测的目标变量是一定要进行分析的,根据输出可以看到正负样本是极度不平衡的,如果直接进行建模,模型会偏向于多数类的样本。
from sklearn.preprocessing import OneHotEncoder
# 选择所有 object 类型的列
object_columns = train_data.select_dtypes(include=['object']).columns
# 初始化 OneHotEncoder,设置 sparse=False 以返回一个 DataFrame
encoder = OneHotEncoder(sparse_output=False)
# 对所有 object 类型的列进行编码
train_encoded_data = encoder.fit_transform(train_data[object_columns])
test_encoded_data = encoder.transform(test_data[object_columns])
# 创建编码后的 DataFrame(列名是原来的列名加上对应的类别)
train_encoded_df = pd.DataFrame(train_encoded_data, columns=encoder.get_feature_names_out(object_columns))
test_encoded_df = pd.DataFrame(test_encoded_data, columns=encoder.get_feature_names_out(object_columns))
# 将编码后的 DataFrame 和原 DataFrame 中的其他列合并
train_data_encoded = pd.concat([train_data.drop(columns=object_columns), train_encoded_df], axis=1)
test_data_encoded = pd.concat([test_data.drop(columns=object_columns), test_encoded_df], axis=1)
# 查看编码后的数据
train_data_encoded.shape, test_data_encoded.shape这里先将数据中的分类变量进行编码,以便后续的建模。
# 删除多个列
train_data2 = train_data_encoded.drop(['id','loan_status'], axis=1)
test_data2 = test_data_encoded.drop(['id'], axis=1)
train_data2.drop_duplicates(inplace = True)
label = train_data_encoded['loan_status']选好特征和标签,并删除重复值。
正负样本不平衡解决方法一
import optuna
import xgboost as xgb
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score, roc_curve, auc
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
x = train_data2
y = label
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # 对训练集进行标准化
X_test_scaled = scaler.transform(X_test) # 对测试集使用相同的缩放器进行标准化
# 应用SMOTE进行过采样
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train_scaled, y_train)
# 定义优化目标函数
def objective(trial):
# Optuna 超参数搜索空间
param = {
'objective': 'binary:logistic', # XGBoost 的二分类任务
'eval_metric': 'auc', # 使用 AUC 作为评估指标
'random_state': 42,
'scale_pos_weight': 1, # 由于已经过采样,正负样本比例平衡,设置为1
'max_depth': trial.suggest_int('max_depth', 3, 15), # 最大深度
'learning_rate': trial.suggest_float('learning_rate', 1e-5, 1e-1), # 学习率
'n_estimators': trial.suggest_int('n_estimators', 50, 200), # 树的数量
'subsample': trial.suggest_float('subsample', 0.5, 1.0), # 子样本比率
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.5, 1.0), # 树的列抽样比率
'gamma': trial.suggest_float('gamma', 0, 1), # 最小化的损失函数值
'min_child_weight': trial.suggest_int('min_child_weight', 1, 10), # 子节点权重
'lambda': trial.suggest_float('lambda', 1e-5, 1e3), # L2 正则化项
'alpha': trial.suggest_float('alpha', 1e-5, 1e3), # L1 正则化项
}
# 初始化 XGBoost 模型
model = xgb.XGBClassifier(**param)
# 训练模型
model.fit(X_resampled, y_resampled)
# 进行预测
y_pred_train = model.predict(X_train_scaled) # 在训练集上预测
y_pred_test = model.predict(X_test_scaled) # 在测试集上预测
# 计算 F1 分数(测试集)
f1_test = f1_score(y_test, y_pred_test)
# 评估训练集上的 F1 分数
f1_train = f1_score(y_train, y_pred_train)
# 输出训练集评估结果
print(f"Training F1: {f1_train:.2f}, Test F1: {f1_test:.2f}")
# 返回 F1 分数作为优化目标(使用测试集的 F1)
return f1_test
# 运行 Optuna 进行超参数优化
study = optuna.create_study(direction='maximize') # 我们的目标是最大化 F1 分数
study.optimize(objective, n_trials=50) # 运行 50 次试验
# 输出最优超参数
print("Best hyperparameters: ", study.best_params)
# 使用最优的超参数训练模型
best_params = study.best_params
model_best = xgb.XGBClassifier(**best_params)
# 训练最优模型
model_best.fit(X_resampled, y_resampled)
# 进行预测
y_pred_train = model_best.predict(X_train_scaled) # 在训练集上预测
y_pred_test = model_best.predict(X_test_scaled) # 在测试集上预测
y_proba_test = model_best.predict_proba(X_test_scaled)[:, 1] # 获取测试集的预测概率
# 计算 F1 和 AUC 分数
f1_train = f1_score(y_train, y_pred_train)
f1_test = f1_score(y_test, y_pred_test)
auc_train = roc_auc_score(y_train, model_best.predict_proba(X_train_scaled)[:, 1]) # 训练集AUC
auc_test = roc_auc_score(y_test, y_proba_test) # 测试集AUC
# 输出评估结果
print("训练集评估结果:")
print("F1分数: {:.2f}".format(f1_train))
print("AUC分数: {:.2f}".format(auc_train))
print("\n测试集评估结果:")
print("F1分数: {:.2f}".format(f1_test))
print("AUC分数: {:.2f}".format(auc_test))
# 绘制ROC曲线
fpr, tpr, thresholds = roc_curve(y_test, y_proba_test)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--') # 随机预测的对角线
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show()Best hyperparameters: {'max_depth': 12, 'learning_rate': 0.04486815194849625, 'n_estimators': 88, 'subsample': 0.7261203476334473, 'colsample_bytree': 0.8781987643477961, 'gamma': 0.26824985423900694, 'min_child_weight': 2, 'lambda': 4.516299629494085, 'alpha': 9.734410788455286}
训练集评估结果:
F1分数: 0.82
AUC分数: 0.96
测试集评估结果:
F1分数: 0.79
AUC分数: 0.95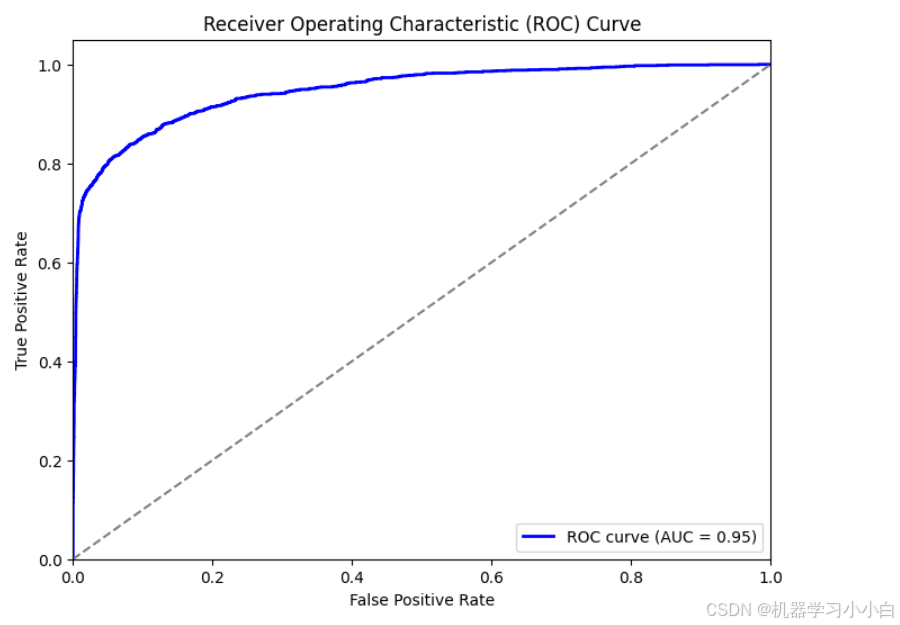
这是我最常用的一种方法,就是使用过采样或者欠采样来平衡正负样本。
过采样与欠采样在处理类别不平衡问题中的应用
在机器学习中,类别不平衡问题会导致模型偏向多数类,影响预测准确性。通过过采样和欠采样,可以平衡数据集,从而提高模型性能。
过采样(Oversampling)
过采样是通过增加少数类样本的数量来平衡数据集。常见方法包括:
- 随机过采样(Random Over-Sampling) 描述:通过复制少数类样本,直到少数类样本数量与多数类相同。 优点:实现简单,易于理解。 使数据集更加平衡,改善模型的预测能力。 缺点:容易导致过拟合,因重复样本可能导致模型过度记忆少数类样本。 无法引入新信息,仅仅是样本的复制。
- SMOTE(Synthetic Minority Over-sampling Technique) 描述:通过在少数类样本的邻居之间插值生成合成样本,而非简单复制。 优点:通过生成新样本而非复制样本,避免过拟合。 增加数据多样性,有助于模型学习少数类特征。 缺点:可能导致合成样本不符合真实分布,从而增加噪声。 生成的样本可能会影响模型的准确性。
- ADASYN(Adaptive Synthetic Sampling) 描述:在SMOTE的基础上,ADASYN重点生成那些难以分类的少数类样本,依难度决定生成样本的数量。 优点:重点补充难分类的少数类样本,优化决策边界。 缺点:与SMOTE类似,可能生成不真实的噪声样本,影响模型稳定性。
欠采样(Undersampling)
欠采样通过减少多数类样本的数量来平衡数据集。常见方法包括:
- 随机欠采样(Random Under-Sampling) 描述:随机删除多数类样本,直到少数类和多数类样本数量平衡。 优点:简单且有效,减少计算复杂度。减少多数类样本过多的影响。 缺点:可能丢失重要信息,因为删除了多数类样本。数据量减少,可能导致训练不足。
- Tomek Links 描述:通过删除少数类和多数类样本之间边界区域的样本,减少噪声。 优点:去除决策边界附近的噪声样本,简化模型,提高泛化能力。 缺点:可能丢失一些有用的多数类样本,降低数据集代表性。
- NearMiss 描述:通过保留与少数类样本最近的多数类样本来保持数据平衡。NearMiss有三种策略: NearMiss-1:选择与少数类样本最近的多数类样本。 NearMiss-2:选择与少数类样本距离较远的多数类样本。 NearMiss-3:选择少数类样本与最近k个多数类样本的平均距离最小的样本。 优点:比随机欠采样更智能,保留有代表性的多数类样本。 缺点:可能仍然丢失重要信息,尤其是当多数类样本较为复杂时。
方法 | 类型 | 优点 | 缺点 |
|---|---|---|---|
随机过采样 | 过采样 | 简单实现,提升模型性能 | 容易过拟合,样本重复 |
SMOTE | 过采样 | 增加样本多样性,避免过拟合 | 可能产生噪声,样本不真实 |
ADASYN | 过采样 | 专注难分类样本,优化决策边界 | 生成噪声,影响模型稳定性 |
随机欠采样 | 欠采样 | 简单有效,减少计算负担 | 丢失重要样本,数据集较小 |
Tomek Links | 欠采样 | 去除噪声样本,简化模型 | 可能丢失有代表性的样本 |
NearMiss | 欠采样 | 智能选择样本,减少信息丢失 | 丢失部分有用样本 |
正负样本不平衡解决方法二
import optuna
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score, roc_curve, auc
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
x = train_data2
y = label
# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # 对训练集进行标准化
X_test_scaled = scaler.transform(X_test) # 对测试集使用相同的缩放器进行标准化
# 计算正负样本的比例,设置 scale_pos_weight
negative_class = np.sum(y_train == 0) # 负样本的数量
positive_class = np.sum(y_train == 1) # 正样本的数量
scale_pos_weight = negative_class / positive_class # 正负样本比例
# 定义优化目标函数
def objective(trial):
# Optuna 超参数搜索空间
param = {
'objective': 'binary:logistic', # XGBoost 的二分类任务
'eval_metric': 'auc', # 使用 AUC 作为评估指标
'random_state': 42,
'scale_pos_weight': scale_pos_weight, # 设置平衡正负样本的比例
'max_depth': trial.suggest_int('max_depth', 3, 15), # 最大深度
'learning_rate': trial.suggest_float('learning_rate', 1e-5, 1e-1), # 学习率
'n_estimators': trial.suggest_int('n_estimators', 50, 200), # 树的数量
'subsample': trial.suggest_float('subsample', 0.5, 1.0), # 子样本比率
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.5, 1.0), # 树的列抽样比率
'gamma': trial.suggest_float('gamma', 0, 1), # 最小化的损失函数值
'min_child_weight': trial.suggest_int('min_child_weight', 1, 10), # 子节点权重
'lambda': trial.suggest_float('lambda', 1e-5, 1e3), # L2 正则化项
'alpha': trial.suggest_float('alpha', 1e-5, 1e3), # L1 正则化项
}
# 初始化 XGBoost 模型
model = xgb.XGBClassifier(**param)
# 训练模型
model.fit(X_train_scaled, y_train)
# 进行预测
y_pred_train = model.predict(X_train_scaled) # 在训练集上预测
y_pred_test = model.predict(X_test_scaled) # 在测试集上预测
y_proba_test = model.predict_proba(X_test_scaled)[:, 1] # 测试集预测概率,用于计算AUC
# 计算 F1 分数
f1_test = f1_score(y_test, y_pred_test) # 测试集F1
f1_train = f1_score(y_train, y_pred_train) # 训练集F1
# 输出训练集评估结果
print(f"Training F1: {f1_train:.2f}, Test F1: {f1_test:.2f}")
# 返回 F1 分数作为优化目标(使用测试集F1)
return f1_test
# 运行 Optuna 进行超参数优化
study = optuna.create_study(direction='maximize') # 我们的目标是最大化 F1 分数
study.optimize(objective, n_trials=50) # 运行 50 次试验
# 输出最优超参数
print("Best hyperparameters: ", study.best_params)
# 使用最优的超参数训练模型
best_params = study.best_params
model_best = xgb.XGBClassifier(**best_params)
# 训练最优模型
model_best.fit(X_train_scaled, y_train)
# 进行预测
y_pred_train = model_best.predict(X_train_scaled) # 在训练集上预测
y_pred_test = model_best.predict(X_test_scaled) # 在测试集上预测
y_proba_test = model_best.predict_proba(X_test_scaled)[:, 1] # 测试集预测概率,用于计算AUC
# 评估模型
f1_train = f1_score(y_train, y_pred_train)
f1_test = f1_score(y_test, y_pred_test)
auc_train = roc_auc_score(y_train, model_best.predict_proba(X_train_scaled)[:, 1]) # 训练集AUC
auc_test = roc_auc_score(y_test, y_proba_test) # 测试集AUC
# 输出评估结果
print("训练集评估结果:")
print("F1分数: {:.2f}".format(f1_train))
print("AUC分数: {:.2f}".format(auc_train))
print("\n测试集评估结果:")
print("F1分数: {:.2f}".format(f1_test))
print("AUC分数: {:.2f}".format(auc_test))
# 绘制ROC曲线
fpr, tpr, thresholds = roc_curve(y_test, y_proba_test)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--') # 随机预测的对角线
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show()Best hyperparameters: {'max_depth': 8, 'learning_rate': 0.006130198259255705, 'n_estimators': 149, 'subsample': 0.9873691639403568, 'colsample_bytree': 0.663845262943208, 'gamma': 0.28141266728918213, 'min_child_weight': 6, 'lambda': 0.4987601752488189, 'alpha': 7.516090015174485}
训练集评估结果:
F1分数: 0.74
AUC分数: 0.93
测试集评估结果:
F1分数: 0.73
AUC分数: 0.94
原理:XGBoost 提供了一个 scale_pos_weight 参数,用来调整正负样本的权重比例。通过增大少数类(正类)的权重,可以帮助模型更加关注少数类样本。 使用方法:计算正负样本的比例,例如
scale_pos_weight = number_of_negative_samples / number_of_positive_samples。
设置 scale_pos_weight 为计算出的比例,或者尝试调整该比例,以优化模型性能。 优点:这种方法简单且高效,通过调整模型对正负样本的关注度,能够缓解不平衡问题。
两种方法都是可用的选择,今天在这里就分享给大家,数据文件已经上传大家可以自行下载尝试。
感谢大家阅读我的博客!非常高兴能够与大家分享一些有价值的知识和经验,希望这些内容对你们有所帮助。如果你觉得我的文章对你有启发,请不要忘记点赞和关注,这对我来说是巨大的支持和鼓励。同时,我也非常欢迎大家在评论区进行交流和讨论,分享你们的观点和经验,让我们一起进步,共同学习!再次感谢大家的关注,期待与大家的互动!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-12-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号