精度更高、速度更快!从RT-DETR到RF-DETR全面突破实时检测瓶颈
原创
精度更高、速度更快!从RT-DETR到RF-DETR全面突破实时检测瓶颈
原创
导读
YOLO虽快,但其依赖的非最大抑制(NMS)后处理拖累速度与精度。DETR架构首次实现无需NMS的“一对一”预测,却受限于计算成本。如今,RT-DETR 通过混合编码器、不确定性查询选择等创新突破实时瓶颈;RF-DETR 更进一步,成为首个在COCO上突破60 AP的实时模型,兼顾高精度与边缘部署效率。>>更多资讯可加入CV技术群获取了解哦~
传统上,YOLO(You Only Look Once)凭借其轻量级和直接的设计,一直是实时物体检测的首选模型。尽管 YOLO 因其在速度和准确率之间的平衡而广受欢迎,但它也面临着挑战,尤其是在非最大抑制 (NMS) 方面。
一、NMS 如何影响 YOLO?
现有的实时检测器(例如 YOLO)通常采用基于 CNN 的架构。尽管 YOLO 在速度和准确率之间进行了合理的权衡,但它需要 NMS 进行后处理,非最大抑制 (NMS) 是一种计算机视觉方法,用于从多个重叠实体(通常是物体检测中的边界框)中选择一个实体。该方法会丢弃低于特定概率阈值的实体,并重复选择概率最高的实体。任何与先前选定的边界框的并集 (IoU) ≥ 0.5 的剩余边界框都将被丢弃。此过程会降低推理速度并引入超参数,从而影响 YOLO 的速度和准确性。
二、DETR:告别 NMS 的全新尝试
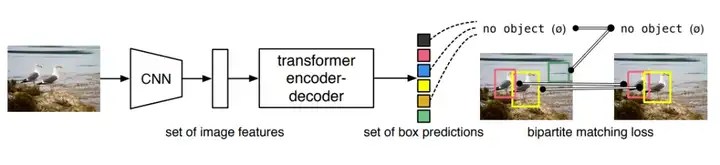
因此DETR(Detection Transformer)便出现了,通过Transformer的全局注意力机制彻底摒弃NMS,实现检测框的“一对一”预测。随着开发人员的创新,如今DETR的变体模型也是越来越优秀,从最初RT-DETR到前不久刚刚发布发布的RF-DETR。
在 Coovally 平台上,无论是经过深度优化、专为实时任务打造的 RT-DETR,还是融合最新改进方案、表现更为强劲的 RF-DETR,都已正式集成上线!用户可以一键调用模型进行训练、测试或部署,也可直接下载模型文件,灵活接入自己的应用流程,无需繁琐配置,真正实现模型即服务,推理即开箱即用。


接下来,我们就来详细看看这两款在实时检测领域大放异彩的 DETR 架构变体——它们是如何一步步突破传统目标检测的瓶颈、又是怎样在 Coovally 平台实现高效落地的。
三、RT-DETR :向实时性能靠拢
DETR模型可以解决YOLO的NMS问题,但其高昂的计算成本使其无法满足实时检测的要求。无NMS架构并未展现出推理速度优势。因此,提出了RT-DETR,RRT-DETR是基于DETR架构的端到端对象检测器,完全消除了对NMS的需求。
然而,RT-DETR面临着许多问题,引入多尺度特征虽然有利于加速训练收敛,但却显著增加了输入编码器的序列长度。多尺度特征相互作用产生的高计算成本使 Transformer 编码器(Transformer编码器是Vaswani等人在论文《Attention is All You Need》中提出的Transformer模型架构的一部分。它利用自注意力机制并行处理输入序列,使其在自然语言处理和计算机视觉等各种任务中高效运行。)成为计算瓶颈,需要重新设计编码器。
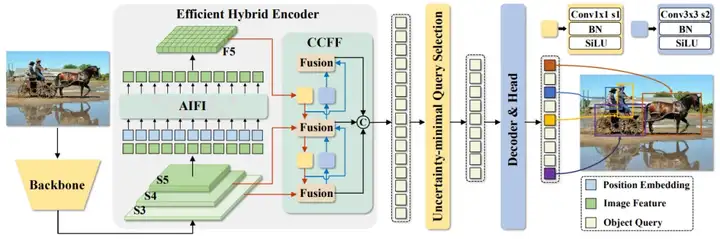
此外,当前直接采用分类分数的查询选择方法忽略了检测器同时建模物体类别和位置的必要性。这可能导致选择定位置信度较低的编码器特征作为初始查询,从而增加不确定性并降低性能。RT-DETR 实现了多种方案来克服这些挑战:
混合编码器
高效混合编码器是标准编码器的重新设计版本,它结合了多种技术来优化性能。它解耦了尺度内交互(处理同一尺度内的特征)和跨尺度融合(融合不同尺度的特征),从而降低了计算成本并提高了处理速度。
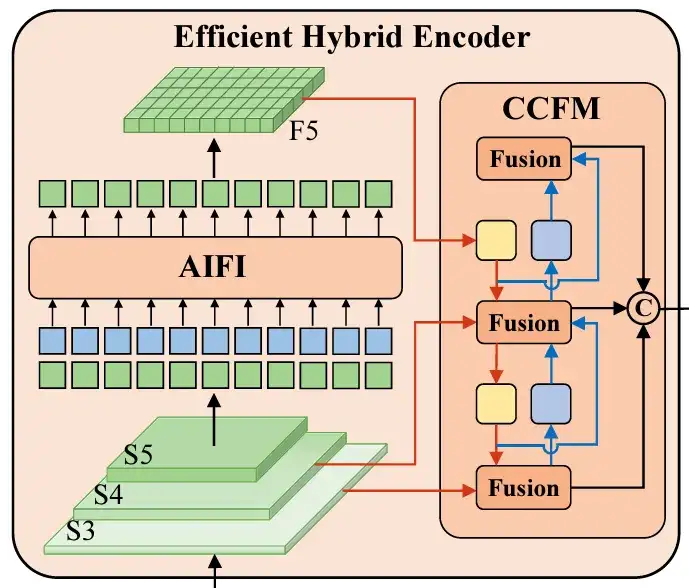
为了避免选择定位置信度较低的编码器特征作为对象查询,RT-DETR 引入了不确定性最小查询选择。该方法明确地优化了不确定性,为解码器提供了高质量的初始查询,从而提高了准确率。
AIFI(自适应交互融合集成):它融合了来自不同级别的主干(S3、S4、S5)的特征,以创建更丰富的表示。python实现代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class AIFI(nn.Module):
def __init__(self, in_channels_s3, in_channels_s4, in_channels_s5, out_channels):
super(AIFI, self).__init__()
# 假设S3, S4, S5的通道数分别为in_channels_s3, in_channels_s4, in_channels_s5
# 使用1x1卷积来调整通道数
self.conv_s3 = nn.Conv2d(in_channels_s3, out_channels, kernel_size=1)
self.conv_s4 = nn.Conv2d(in_channels_s4, out_channels, kernel_size=1)
self.conv_s5 = nn.Conv2d(in_channels_s5, out_channels, kernel_size=1)
# 自适应加权模块,利用全连接层进行权重计算
self.fc = nn.Linear(out_channels * 3, 1)
def forward(self, s3, s4, s5):
# 对不同层次特征进行处理
s3_out = self.conv_s3(s3)
s4_out = self.conv_s4(s4)
s5_out = self.conv_s5(s5)
# 融合特征(可以通过拼接或者加权)
fused_features = torch.cat((s3_out, s4_out, s5_out), dim=1) # 拼接通道
# 计算加权系数
attention_weights = self.fc(fused_features.view(fused_features.size(0), -1)) # 平展后输入全连接层
attention_weights = F.sigmoid(attention_weights) # 使用Sigmoid激活函数确保权重在0-1之间
# 加权融合后的特征
weighted_fusion = fused_features * attention_weights.unsqueeze(-1).unsqueeze(-1)
return weighted_fusion.sum(dim=1) # 对通道维度进行求和,得到最终融合特征CCFF(跨尺度通道融合):该模块进行多层次的融合,结合来自不同尺度的特征,以保持高级语义信息和低级细节特征之间的平衡。
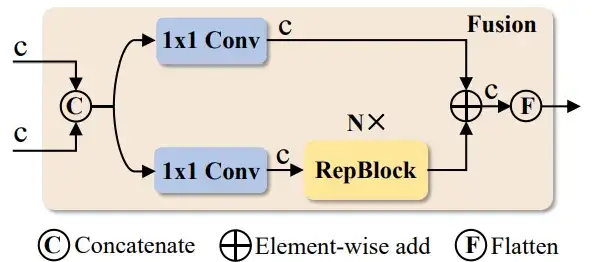
CCFF模块通常采用跨通道注意力机制或简单的加权平均来完成这一任务:
class CCFF(nn.Module):
def __init__(self, in_channels_list, out_channels):
super(CCFF, self).__init__()
self.convs = nn.ModuleList([nn.Conv2d(in_channels, out_channels, kernel_size=1) for in_channels in in_channels_list])
self.attn_fc = nn.Linear(out_channels * len(in_channels_list), 1)
def forward(self, features):
# features是一个包含多个尺度特征的列表
processed_features = [conv(f) for conv, f in zip(self.convs, features)] # 每个尺度的特征通过1x1卷积处理
# 融合多个尺度的特征
fused_features = torch.cat(processed_features, dim=1) # 拼接各尺度特征
# 计算注意力权重
attention_weights = self.attn_fc(fused_features.view(fused_features.size(0), -1)) # 使用全连接层计算加权系数
attention_weights = F.sigmoid(attention_weights) # 使用sigmoid激活函数
# 对融合特征进行加权
weighted_fusion = fused_features * attention_weights.unsqueeze(-1).unsqueeze(-1) # 加权融合
return weighted_fusion.sum(dim=1) # 对通道维度进行求和,返回融合后的特征查询选择器
不确定性最小查询选择是一种通过最小化不确定性来为解码器选择最佳初始查询的技术。这确保了所选特征具有较高的定位置信度,从而提高了目标检测过程的准确性和可靠性。
改进的解码器结构
RT-DETR的解码器结构经过优化,使其能够更高效地生成物体的位置和类别,无需重新训练即可适应各种实时场景。在传统的DETR中,解码器通常需要大量的计算来匹配物体和查询,但RT-DETR在此基础上进行了改进,通过更高效的解码机制加速了计算过程。

四、RF-DETR:推理加速的新突破
前不久刚刚发布的RF-DETR,是第一个在Microsoft COCO基准测试中超过 60 AP 的实时模型,同时在基础尺寸下具有竞争力。它还在 RF100-VL 目标检测基准测试中实现了最先进的性能,该基准测试衡量模型对现实世界问题的领域适应性。RF-DETR 的速度与当前实时目标检测模型相当。 它专为需要高速、高精度且计算资源有限(例如边缘计算或低延迟)的模型的项目而开发。
RF-DETR 有两种型号:RFDETRBase 和 RFDETRLarge,同样它足够小巧,可以在边缘设备上运行,能同时兼顾精度和实时性,使其成为需要强大准确性和实时性能的部署的理想模型。
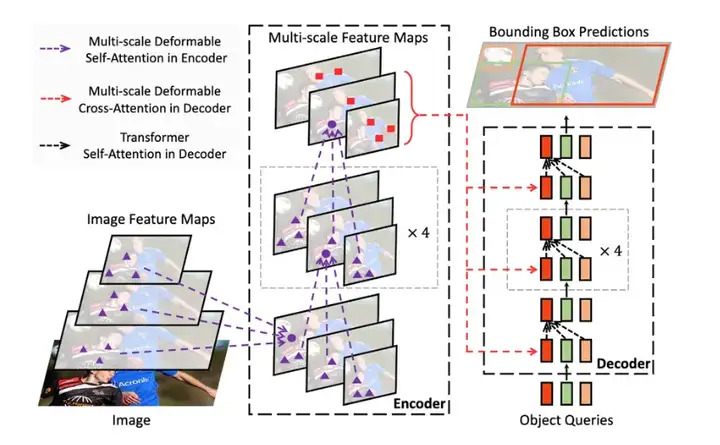
RF-DETR 采用基于可变形 DETR 论文中阐述的基础架构。可变形 DETR 采用多尺度自注意力机制,而 RF-DETR 则从单尺度主干网络中提取图像特征图。并通过将 LW-DETR 与预训练的 DINOv2 主干相结合,创建了 RF-DETR。
五、重新定义实时检测的边界:Coovally 平台全面集成
对于模型基础有所了解后,大家是否都想进行使用训练呢?借助Coovally提供的无代码训练环境和灵活的模型部署能力,用户可以一键调用这两款模型进行训练、验证与部署,适用于工业检测、智能安防、农业识别等多种场景。
平台不仅免去了繁琐的算法配置流程,还支持多种格式转换与数据增强方式,让模型应用变得前所未有地简单高效。无论你是算法研究者,还是产业应用者,都可以在Coovally上轻松上手、快速试验并落地你的目标检测任务。
!!点击下方链接,立即体验Coovally!!
如果你希望在不牺牲精度的前提下提升检测速度,又想体验无 NMS 架构的未来潜力,不妨现在就来试试 RT-DETR 和 RF-DETR —— Coovally 平台已经为你准备好一切。
结论
从YOLO的NMS枷锁,到RT-DETR的实时化突破,再到RF-DETR的精度-效率平衡,实时检测技术正加速向端到端、轻量化演进。“无需NMS”不仅是一场技术革命,更是工业落地的必然选择。通过Coovally平台,企业可快速调用RT-DETR与RF-DETR的顶尖能力,让AI真正成为产线“鹰眼”。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
