打破算力瓶颈:LLM推理中Prefill/Decode分离架构深度解析
原创
打破算力瓶颈:LLM推理中Prefill/Decode分离架构深度解析
原创
聚客AI
发布于 2025-09-09 14:49:35
发布于 2025-09-09 14:49:35
本文较长,建议点赞收藏,以免遗失。
在LLM推理计算中Prefill和Decode两个阶段的计算/显存/带宽需求不一样,通常Prefill是算力密集,Decode是访存密集。一些场景中P和D两者分开计算可提升性能。vLLM是一种主流的推理框架,今天我将主要围绕其PD分离场景做讨论,欢迎交流指正!👍
1. Prefill与Decode分离的背景与必要性
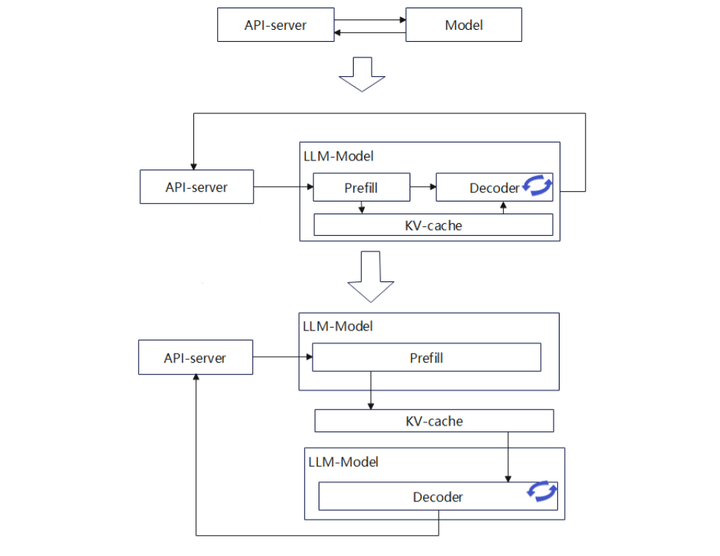
在LLM推理中,Transformer架构的自回归特性导致计算过程分为两个阶段:
- Prefill阶段:处理输入提示(prompt),一次性生成所有Token的Key-Value(KV)缓存。该阶段计算密集,消耗大量算力。
- Decode阶段:基于KV缓存进行自回归迭代生成输出Token,访存密集,对显存带宽要求高。
传统部署方案将P和D整合在单一实例中,但存在显著缺陷:
- P阶段显存利用率低(算力需求高但显存闲置)。
- D阶段算力利用率低(显存需求高但算力闲置)。
- 固定硬件资源下,无法灵活适应动态负载,尤其当输入长度变化或batch size增大时效率下降。
为提升资源效率,业界提出KV缓存(KV Cache)机制,避免重复计算,并衍生出P与D分离部署方案:
- P实例专注高算力任务,生成KV缓存。
- D实例专注高带宽任务,消费KV缓存生成输出。
2. vLLM框架中的PD分离实现现状
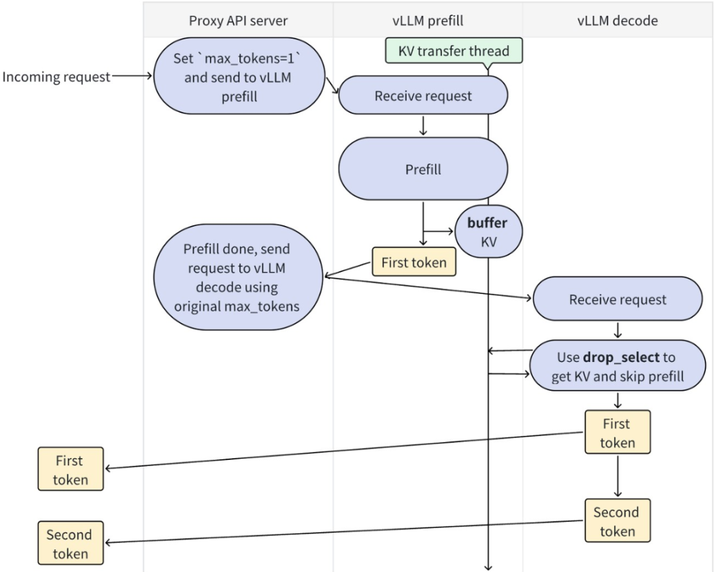
vLLM作为主流推理框架,其0.8.x版本通过KV Transfer机制支持PD分离(1P1D场景)。核心设计如下:
工作流程:
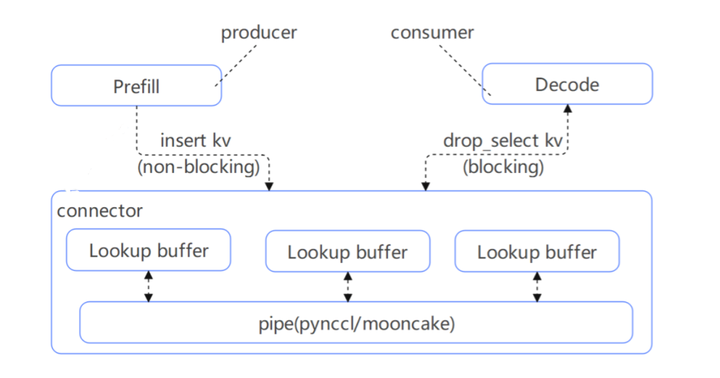
- P实例以非阻塞方式将生成的KV缓存插入缓冲区(LookupBuffer)。
- D实例以阻塞方式从缓冲区获取KV缓存。
- 数据传递通过管道(pipe)实现,支持PyNCCL或Mooncake Store等通信后端。
代码实现简化:
- 通过KVTransferConfig配置角色(producer/consumer)和通信参数。
- 示例代码展示P和D实例的初始化与协同:
# Prefill节点配置
ktc = KVTransferConfig.from_cli('{"kv_connector":"PyNcclConnector", "kv_role":"kv_producer", "kv_rank":0, "kv_parallel_size":2}')
llm = LLM(model="meta-llama/Meta-Llama-3.1-8B-Instruct", kv_transfer_config=ktc)
llm.generate(prompts, sampling_params)
# Decode节点配置
ktc = KVTransferConfig.from_cli('{"kv_connector":"PyNcclConnector", "kv_role":"kv_consumer", "kv_rank":1, "kv_parallel_size":2}')
llm = LLM(model="meta-llama/Meta-Llama-3.1-8B-Instruct", kv_transfer_config=ktc)
outputs = llm.generate(prompts, sampling_params)当前局限:
- 仅支持1P1D,缺乏多实例(如xPyD)和分布式(TP/PP)扩展。
- 未集成负载均衡、自动扩缩容等高级调度功能。
- Chunk Prefill等优化未适配,需V1版本进一步迭代。
3. PD分离设计的关键问题
实现高效PD分离需解决以下核心问题:
关键点 | 内容 | 说明 |
|---|---|---|
a) PD配比与数量 | a1) 分离与融合的选择 | 短序列/低频请求场景下,融合部署可能更优。 |
a2) P/D实例初始配比 | 需根据负载动态调整P和D比例。 | |
a3) 实例扩缩容支持 | 集群管理需支持弹性伸缩以提升资源利用率。 | |
a4) 角色互换可行性 | 闲置P实例可转为D实例(反之亦然),实现资源复用。 | |
b) 请求调度 | b1) 调度亲和性 | 减少P与D间通信延迟,例如就近部署实例。 |
b2) 负载均衡 | 多P多D时需均衡实例负载。 | |
b3) 网络均衡 | 避免KV传输导致网络阻塞,需平衡计算与带宽。 | |
b4) Batch分配策略 | P阶段适合小batch,D阶段适合大batch。 | |
c) KV存储设计 | c1) 存储介质 | 显存(HBM)、内存、SSD或远端存储(如S3),需权衡速度与容量。 |
c2) 传输方式 | RDMA(NCCL/HCCL)、TCP/RPC等,影响传输效率。 | |
d) Cache复用 | d1) 存储位置 | 显存速度快但容量小,内存/SSD容量大但延迟高。 |
d2) 保存/加载策略 | P阶段生成KV后保存,D阶段直接加载,减少重复计算。 | |
d3) 共享范围 | 是否支持跨节点全局共享Cache。 | |
d4) 淘汰机制 | LRU等策略处理Cache溢出。 | |
e) 可靠性 | e1) 实例故障恢复 | P/D实例故障时需保证服务连续性。 |
e2) 网络健壮性 | 增强控制链路容错能力。 |
4. 主流PD分离方案分析
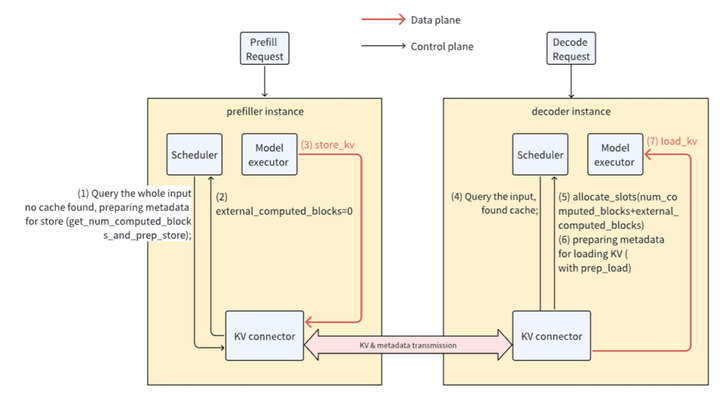
4.1 Connector-Base方案
架构:每个vLLM进程部署两类连接器(Connector):
- Scheduler Connector:与调度器同进程,决定KV缓存传输逻辑。
- Worker Connector:与Worker同进程,执行KV传输操作。
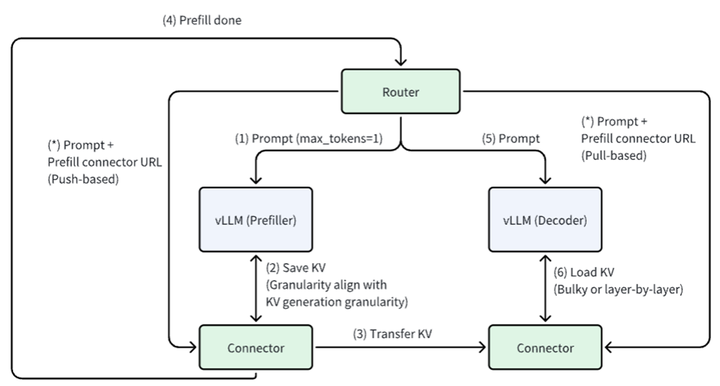
异步传输流程:
- Router发送Prefill请求至Prefiller。
- Prefiller_connector通知目标Decoder。
- Prefiller计算P结果并存入Buffer。
- Prefiller推送KV Cache至Decoder_connector(与Step 3并行)。
- Decoder确认接收后,Router触发Decode请求。
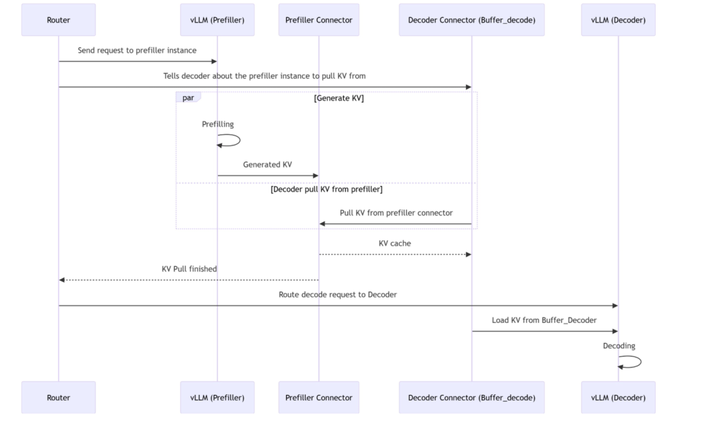
代码修改重点:
- 调度侧:get_computed_blocks集成Connector状态管理。
- Worker侧:模型执行前后异步加载/保存KV。
V1适配方案:分离Prefill与Decode调度器,支持Chunk Prefill优化,但维护复杂度较高。
4.2 英伟达Dynamo方案
架构:分内外两层:
- 外层:全局资源管理(Frontend、Router、Workers)。
- 内层:PD分离实例,通过KV Block交互。
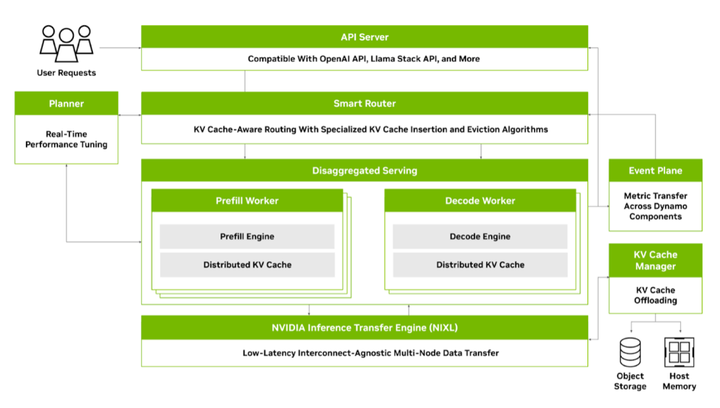
运行逻辑:
- Router分配请求至Worker。
- Prefill Worker计算KV并写入Block。
- Decode Worker消费Block生成输出。
- 使用NVLINK实现非阻塞KV传输。
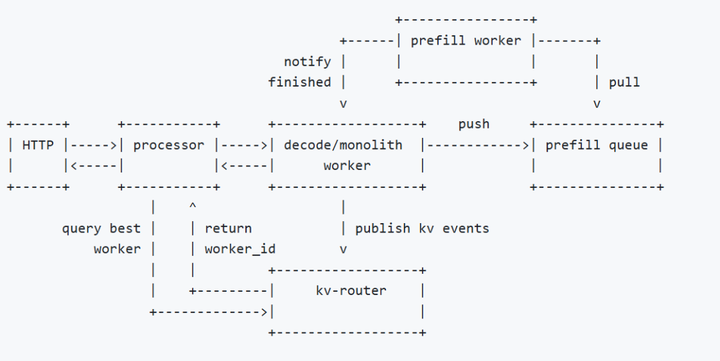
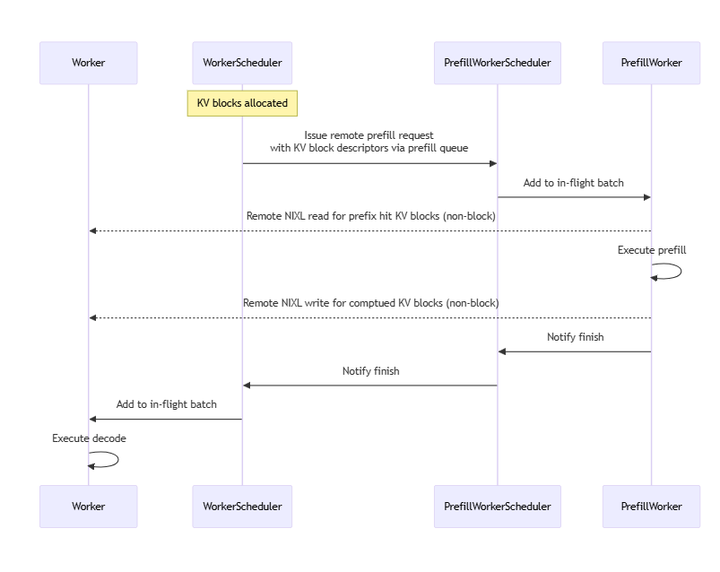
负载均衡优化:通过队列(PrefillQueue)协调远程请求:
- Worker决策本地/远程Prefill,推送请求至队列。
- Prefill Worker拉取请求并回写Block。
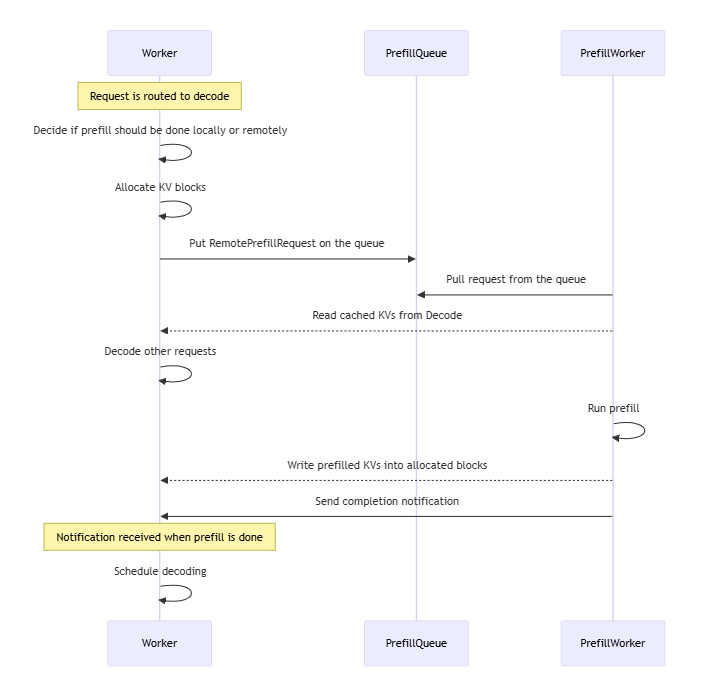
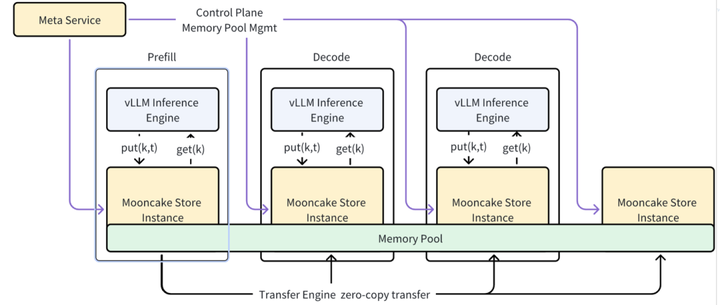
4.3 Mooncake集成方案
核心组件:
- Transfer Engine:统一接口支持TCP/RDMA/NVMe-of协议,实现跨介质数据传输。
- Mooncake Store:分布式KV Cache引擎,提供Put/Get/Remove API。
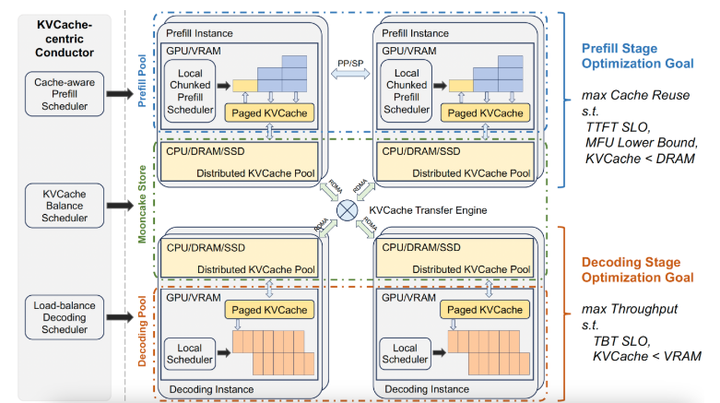
工作流程:
- Put():KV缓存从GPU分页缓存传输至本地DRAM。
- Get():异步拉取KV至DRAM,再传输至GPU分页缓存。
- 调度层分离控制流与数据流,提升健壮性。
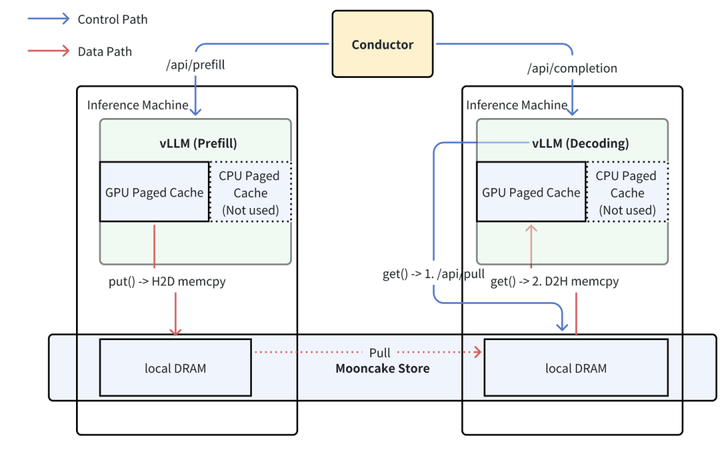
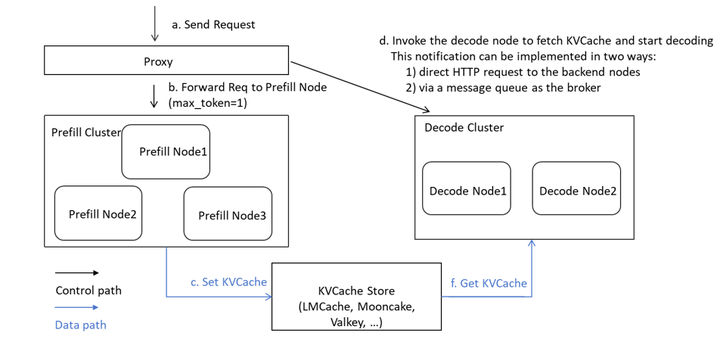
优化方向:
- 零拷贝传输:减少DRAM中间复制(当前方案存在性能瓶颈)。
- 全局Cache复用:跨请求共享Prefix缓存。
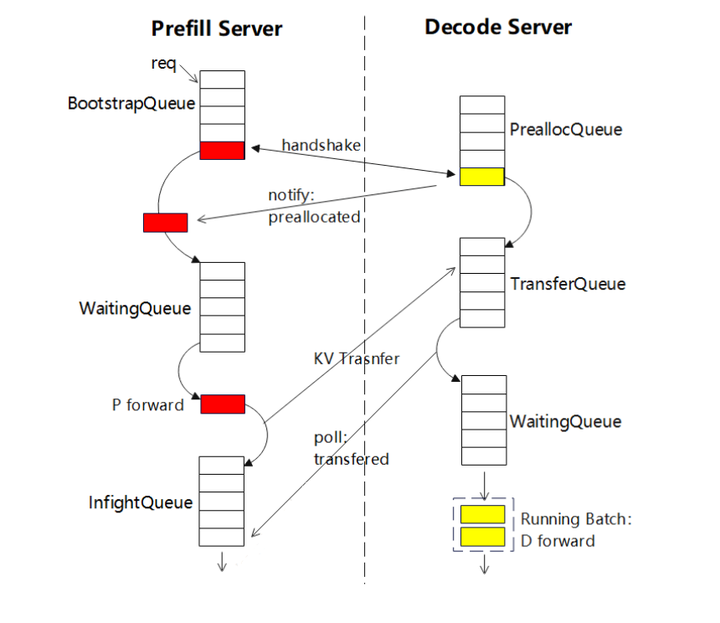
4.4 SGLang方案
事件循环机制:通过队列分阶段处理请求:
Prefill实例:
- BootstrapQueue:创建Sender并与Decoder握手。
- WaitingQueue:等待资源执行P计算。
- InfightQueue:非阻塞查询KV传输状态。
Decode实例:
- PreallocQueue:创建Receiver并分配KV存储。
- TransferQueue:获取Prefill的KV值。
- WaitingQueue:凑批后执行D计算。
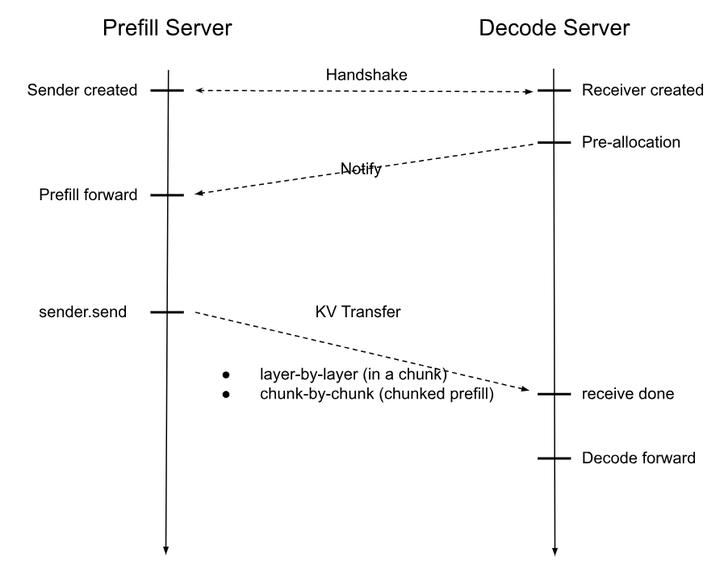
KV传输设计:
- 非阻塞后端进程处理(KVSender/KVReceiver)。
- 支持逐层或Chunk为单位传输。
- 使用方式:通过命令行参数指定角色(prefill/decode)和Bootstrap端口。
- 未来计划:扩展多实例支持与高级调度(路标见下图)。

5.作者总结
PD分离是优化LLM推理资源效率的关键路径,vLLM、Dynamo、Mooncake和SGLang等方案各具优势:
- vLLM:简洁易用,适合快速部署1P1D场景。
- Dynamo:分层架构支持大规模集群。
- Mooncake:专注高性能KV存储与传输。
- SGLang:事件循环机制提升灵活性。
- ps:由于文章篇幅有限,关于LLM推理框架的全面分析和选型,我之前整理了一个详细的技术文档,粉丝朋友自行领取:《大型语言模型(LLM)推理框架的全面分析与选型指南(2025年版)》
未来方向包括:多实例负载均衡、动态扩缩容、全局Cache共享、以及硬件级优化(如零拷贝传输)。建议各位需根据场景需求(序列长度、请求频率)选择融合或分离部署,好了,今天的分享就到这里,点个小红心,我们下期见。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号