从零开始构建百度智能体与知识库:完整指南与实践


从零开始构建百度智能体与知识库:完整指南与实践
引言:AI时代的企业智能助手
在数字化转型浪潮中,企业智能助手已成为提升服务效率、优化用户体验的关键工具。百度智能云提供的智能体(Agent)服务,结合强大的文心大模型,让企业能够快速构建专属的AI助手。本文将详细介绍如何从零开始创建百度智能体,并构建高效的知识库系统,包含实际代码示例和最佳实践。
第一部分:百度智能体创建全流程
1.1 准备工作与环境搭建
在开始创建智能体前,需要完成以下准备工作:
# 安装百度智能云Python SDK
pip install baidu-aip
# 导入必要模块
from aip import AipNlp
# 配置认证信息
APP_ID = '你的AppID'
API_KEY = '你的ApiKey'
SECRET_KEY = '你的SecretKey'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)1.2 创建智能体的五个关键步骤
1.2.1 注册与登录
访问百度智能云官网(https://cloud.baidu.com/),完成企业实名认证后,进入"人工智能"服务板块。
1.2.2 基础配置
在控制台中创建新智能体时,需要填写以下核心参数:
{
"agent_name": "电商客服助手",
"description": "处理商品咨询、订单查询的智能客服",
"industry": "电子商务",
"default_response": "抱歉,我暂时无法理解您的问题,请换种方式提问。"
}1.2.3 能力配置
选择适合的底层模型是关键决策:
模型类型 | 适用场景 | 特点 |
|---|---|---|
文心大模型-Pro | 复杂对话场景 | 理解能力强,支持长文本 |
文心大模型-Lite | 简单问答场景 | 响应快,成本低 |
行业定制模型 | 专业领域 | 需额外训练 |
1.2.4 对话流程设计
使用可视化工具设计对话树:
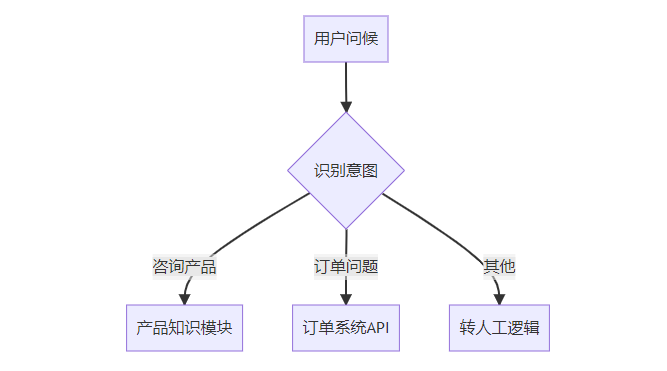
1.2.5 测试与发布
建议采用A/B测试策略:
def test_agent_response(query):
response_v1 = legacy_agent(query)
response_v2 = new_agent(query)
return compare_responses(response_v1, response_v2)第二部分:知识库构建深度解析
2.1 知识工程方法论
构建高质量知识库需要遵循"CRISP"原则:
- Complete(完整性)
- Relevant(相关性)
- Integrated(整合性)
- Structured(结构性)
- Precise(精确性)
2.2 知识库构建实战
2.2.1 数据采集与清洗
import pandas as pd
# 从多个来源收集原始数据
faq_data = pd.read_csv('faq.csv')
product_docs = parse_pdf('product_manual.pdf')
chat_logs = clean_chat_data('chat_history.log')
# 数据合并与去重
knowledge_base = pd.concat([faq_data, product_docs, chat_logs]).drop_duplicates()2.2.2 知识结构化处理
构建三元组知识表示:
class KnowledgeNode:
def __init__(self, entity, relation, value):
self.entity = entity
self.relation = relation
self.value = value
# 示例知识节点
node1 = KnowledgeNode("iPhone15", "支持网络", "5G")
node2 = KnowledgeNode("退货政策", "时间限制", "7天无理由")2.2.3 百度知识库API集成
def upload_to_baidu_knowledge(knowledge_items):
for item in knowledge_items:
response = client.knowledgeAdd(
item['question'],
item['answer'],
tags=item.get('tags', []),
status=1 # 1表示立即生效
)
log_upload_result(response)2.3 知识图谱进阶应用
对于复杂领域,建议构建知识图谱:
from py2neo import Graph
# 连接Neo4j图数据库
graph = Graph("bolt://localhost:7687", auth=("username", "password"))
# 创建知识图谱节点和关系
def create_knowledge_graph(nodes, relationships):
tx = graph.begin()
for node in nodes:
tx.create(node)
for rel in relationships:
tx.create(rel)
tx.commit()第三部分:高级功能与优化策略
3.1 多轮对话实现
class DialogManager:
def __init__(self):
self.context = {}
def handle_message(self, user_id, message):
# 获取对话历史
history = self.get_dialog_history(user_id)
# 结合上下文理解意图
intent = self.understand_intent(message, history)
# 维护对话状态
self.update_dialog_state(user_id, intent)
# 生成响应
response = self.generate_response(intent)
return response3.2 性能监控与优化
建议监控以下关键指标:
# 监控指标示例
monitor_metrics = {
'response_time': {'threshold': 1.5, 'unit': 's'},
'accuracy': {'threshold': 0.85, 'unit': '%'},
'fallback_rate': {'threshold': 0.1, 'unit': '%'}
}
def check_metrics(metrics):
alerts = []
for name, config in monitor_metrics.items():
if metrics[name] > config['threshold']:
alerts.append(f"{name}超出阈值:{metrics[name]}{config['unit']}")
return alerts3.3 持续学习机制
实现反馈闭环系统:
def feedback_loop(user_query, agent_response, user_feedback):
# 记录交互数据
log_interaction(user_query, agent_response, user_feedback)
# 识别知识缺口
if user_feedback['score'] < 3: # 低分反馈
identify_knowledge_gap(user_query)
# 定期更新模型
if need_retraining():
retrain_model()第四部分:行业应用案例
4.1 电商客服智能体
典型知识库结构:
电商知识库/
├── 产品信息
│ ├── 手机类
│ └── 家电类
├── 促销活动
├── 支付方式
└── 售后服务4.2 金融咨询智能体
特殊处理要求:
def handle_sensitive_query(query):
if detect_sensitive_content(query):
return {
'response': '该问题涉及敏感信息,请咨询人工客服',
'action': 'transfer_to_human',
'log_level': 'warning'
}
else:
return process_normal_query(query)第五部分:常见问题解决方案
5.1 知识库冷启动问题
解决方案:
- 使用现有文档生成种子问题集
- 采用主动学习策略:
def active_learning():
uncertain_samples = get_uncertain_predictions()
for sample in uncertain_samples:
human_label = get_human_review(sample)
update_training_data(human_label)5.2 意图识别不准
优化方法:
def enhance_intent_detection(query):
# 增加同义词扩展
expanded_query = synonym_expansion(query)
# 结合上下文分析
contextual_query = add_context(context, expanded_query)
# 多模型投票
results = ensemble_models.predict(contextual_query)
return majority_vote(results)结语:构建持续进化的智能体
百度智能体与知识库的建设不是一次性的项目,而是需要持续优化的过程。建议企业:
- 建立专门的知识运营团队
- 制定每周知识更新机制
- 定期评估智能体性能指标
- 保持与业务发展的同步迭代
通过本文介绍的方法论和实战技巧,您已经掌握了构建企业级智能助手的关键技能。随着技术的不断进步,智能体将在企业数字化转型中发挥越来越重要的作用。
附录:
- 百度智能云官方文档链接
- 示例代码GitHub仓库
- 推荐学习资源列表
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-11-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号