019_具身人工智能的跨模态感知与安全融合:从多源数据到协同防御的深度解析

019_具身人工智能的跨模态感知与安全融合:从多源数据到协同防御的深度解析

安全风信子
发布于 2025-11-19 13:40:28
发布于 2025-11-19 13:40:28
引言
在2025年的技术发展背景下,具身人工智能(Embodied AI)系统正朝着更加智能、自主和安全的方向演进。跨模态感知技术作为具身AI的核心能力,使其能够通过视觉、听觉、触觉等多种感官通道感知物理世界,构建全面的环境理解。然而,这种多源数据融合也带来了复杂的安全挑战。本章将深入探讨具身AI的跨模态感知原理、技术实现以及安全融合机制,从多源数据采集到协同防御策略,全面解析这一前沿领域的技术发展与安全保障。
跨模态感知的理论基础
1. 多模态感知的认知基础
人类认知系统的多模态融合机制为具身AI提供了重要启示:
- 并行处理特性:人类大脑能够同时处理来自不同感官的信息
- 互补增强效应:多模态信息相互补充,提高认知准确性
- 冗余验证机制:通过多通道验证降低感知误差
- 上下文理解能力:基于多模态信息构建完整的场景理解
- 自适应整合策略:根据任务需求动态调整各模态权重
2. 具身AI中的模态类型
现代具身AI系统集成的主要感知模态:
感知模态 | 传感器类型 | 数据特征 | 主要挑战 | 安全考量 |
|---|---|---|---|---|
视觉 | 摄像头、深度相机、红外相机 | 图像、视频、深度图 | 光照变化、遮挡、欺骗 | 图像对抗样本、视频篡改 |
听觉 | 麦克风阵列、声纳 | 声音波形、频谱 | 噪声干扰、远场识别 | 声信号注入、音频欺骗 |
触觉 | 力传感器、压力传感器 | 力学信号、压力分布 | 精度限制、漂移 | 传感器篡改、信号伪造 |
proprioception | 惯性测量单元、编码器 | 位置、姿态、加速度 | 累积误差、校准 | 信号干扰、数据篡改 |
环境感知 | 温度、湿度、气体传感器 | 环境参数 | 响应延迟、精度 | 传感器攻击、异常检测 |
通信感知 | Wi-Fi、蓝牙、雷达 | 信号强度、距离 | 干扰、多径效应 | 信号劫持、伪装攻击 |
3. 跨模态融合的信息理论
从信息理论角度理解跨模态融合:
- 互信息最大化:最大化不同模态间的信息互补
- 不确定性最小化:通过多源信息降低系统不确定性
- 信噪比优化:提高系统整体的信噪比
- 信息熵平衡:平衡各模态信息在决策中的贡献
- 冗余信息管理:有效处理和利用冗余信息
跨模态感知架构设计
1. 系统架构概览
具身AI的跨模态感知架构通常包含以下核心组件:
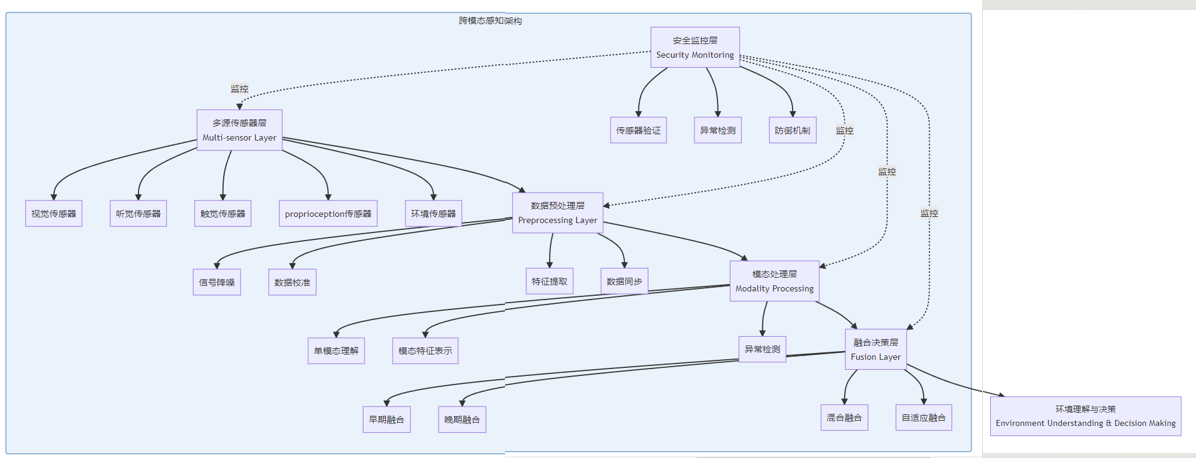
2. 传感器网络拓扑
现代具身AI系统的传感器网络设计考虑:
- 分布式布局:传感器在物理载体上的最优分布
- 冗余配置:关键模态的冗余设计提高可靠性
- 异构集成:不同类型传感器的协同工作机制
- 能源效率:传感器网络的能源管理策略
- 可扩展性:系统架构的可扩展设计
3. 实时处理要求
跨模态感知的实时性保障机制:
- 计算资源优化:专用硬件加速器的应用
- 并行处理架构:多核心并行计算策略
- 处理优先级:任务驱动的处理优先级调度
- 数据压缩技术:高效的数据压缩算法
- 边缘计算模式:在传感器端进行初步处理
跨模态融合算法
1. 早期融合方法
早期融合在特征层面进行信息整合:
- 特征拼接:直接拼接不同模态的特征向量
- 特征对齐:基于时间或空间对齐多模态特征
- 联合表示学习:学习统一的多模态特征空间
- 典型相关分析(CCA):最大化不同模态间的相关关系
- 多视图学习:将不同模态视为数据的不同视图
2. 晚期融合方法
晚期融合在决策层面进行结果整合:
- 投票机制:基于多模态决策结果的投票策略
- 加权平均:动态调整各模态的权重
- 贝叶斯融合:基于贝叶斯理论的概率融合
- Dempster-Shafer证据理论:处理不确定性的融合框架
- 集成学习:利用集成方法融合多模态决策
3. 混合融合策略
混合融合结合早期和晚期融合的优势:
- 层次化融合:多层次的融合架构设计
- 模态交互模型:建模模态间的交互关系
- 注意力机制:动态关注不同模态的重要信息
- 图神经网络融合:利用图结构建模模态关系
- 胶囊网络:通过胶囊网络进行层次化特征融合
4. 自适应融合算法
根据场景动态调整融合策略:
# 具身AI自适应跨模态融合框架示例
import numpy as np
from scipy.stats import entropy
class AdaptiveMultimodalFusion:
def __init__(self, modalities_config):
"""
初始化自适应跨模态融合系统
参数:
modalities_config: 包含各模态配置的字典
"""
self.modalities = list(modalities_config.keys())
self.modalities_config = modalities_config
self.weights_history = []
self.confidence_scores = {}
self.uncertainty_measures = {}
self.context_state = None
self.adaptation_history = []
def process_single_modality(self, modality_name, raw_data):
"""
处理单个模态的数据
参数:
modality_name: 模态名称
raw_data: 原始传感器数据
返回:
处理后的特征和置信度
"""
if modality_name not in self.modalities:
raise ValueError(f"未知的模态名称: {modality_name}")
config = self.modalities_config[modality_name]
# 数据预处理
processed_data = self._preprocess_data(raw_data, config["preprocessing"])
# 特征提取
features = self._extract_features(processed_data, config["feature_extraction"])
# 置信度估计
confidence = self._estimate_confidence(features, processed_data, modality_name)
# 不确定性估计
uncertainty = self._estimate_uncertainty(features, processed_data, modality_name)
# 更新状态
self.confidence_scores[modality_name] = confidence
self.uncertainty_measures[modality_name] = uncertainty
return features, confidence, uncertainty
def _preprocess_data(self, raw_data, preprocessing_config):
"""数据预处理"""
# 实际实现中包含降噪、归一化等操作
return raw_data # 简化实现
def _extract_features(self, processed_data, feature_config):
"""特征提取"""
# 实际实现中包含各种特征提取算法
return processed_data # 简化实现
def _estimate_confidence(self, features, processed_data, modality_name):
"""估计置信度分数"""
# 简化实现,实际应基于多种因素计算置信度
return np.random.uniform(0.5, 1.0)
def _estimate_uncertainty(self, features, processed_data, modality_name):
"""估计不确定性度量"""
# 简化实现,实际应基于熵、方差等计算不确定性
return np.random.uniform(0.0, 0.5)
def update_context(self, context_info):
"""
更新上下文信息
参数:
context_info: 包含当前环境状态的信息
"""
self.context_state = context_info
def calculate_adaptive_weights(self):
"""
根据当前状态计算自适应权重
返回:
各模态的权重字典
"""
weights = {}
total_confidence = 0.0
# 基础权重基于置信度
for modality in self.modalities:
conf = self.confidence_scores.get(modality, 0.5)
weights[modality] = conf
total_confidence += conf
# 归一化权重
if total_confidence > 0:
for modality in weights:
weights[modality] = weights[modality] / total_confidence
# 如果有上下文信息,根据场景调整权重
if self.context_state:
weights = self._adjust_weights_for_context(weights)
# 考虑历史表现调整权重
weights = self._adjust_weights_for_history(weights)
# 记录权重历史
self.weights_history.append({
"timestamp": np.datetime64('now'),
"weights": weights.copy(),
"context": self.context_state
})
return weights
def _adjust_weights_for_context(self, base_weights):
"""根据上下文调整权重"""
# 实际实现中根据不同场景类型动态调整权重
adjusted_weights = base_weights.copy()
if self.context_state.get("lighting_condition") == "low":
# 低光照条件下降低视觉权重,增加其他模态权重
if "visual" in adjusted_weights:
visual_weight = adjusted_weights["visual"]
adjusted_weights["visual"] *= 0.5
# 重新分配权重
weight_increase = visual_weight * 0.5
other_modalities = [m for m in adjusted_weights.keys() if m != "visual"]
if other_modalities:
increase_per_modality = weight_increase / len(other_modalities)
for modality in other_modalities:
adjusted_weights[modality] += increase_per_modality
# 归一化调整后的权重
total = sum(adjusted_weights.values())
if total > 0:
for m in adjusted_weights:
adjusted_weights[m] = adjusted_weights[m] / total
return adjusted_weights
def _adjust_weights_for_history(self, base_weights):
"""根据历史表现调整权重"""
# 简化实现,实际应基于历史准确性动态调整
return base_weights
def fuse_features(self, modality_features, weights):
"""
融合多模态特征
参数:
modality_features: 字典,键为模态名称,值为特征向量
weights: 各模态的权重
返回:
融合后的特征向量
"""
# 确保所有模态特征维度相同
feature_dim = None
for modality, features in modality_features.items():
if feature_dim is None:
feature_dim = len(features)
elif len(features) != feature_dim:
raise ValueError(f"特征维度不匹配: {modality} 有 {len(features)} 维,但期望 {feature_dim} 维")
# 加权融合特征
fused_features = np.zeros(feature_dim)
for modality, features in modality_features.items():
weight = weights.get(modality, 1.0/len(modality_features))
fused_features += weight * np.array(features)
return fused_features
def fuse_decisions(self, modality_decisions, weights):
"""
融合多模态决策结果
参数:
modality_decisions: 字典,键为模态名称,值为决策结果
weights: 各模态的权重
返回:
融合后的决策结果
"""
# 假设决策结果是类别概率分布
num_classes = None
for modality, decision in modality_decisions.items():
if num_classes is None:
num_classes = len(decision)
elif len(decision) != num_classes:
raise ValueError(f"类别数量不匹配: {modality} 有 {len(decision)} 个类别,但期望 {num_classes} 个")
# 加权融合决策
fused_decision = np.zeros(num_classes)
for modality, decision in modality_decisions.items():
weight = weights.get(modality, 1.0/len(modality_decisions))
fused_decision += weight * np.array(decision)
# 归一化
if np.sum(fused_decision) > 0:
fused_decision = fused_decision / np.sum(fused_decision)
return fused_decision
def detect_modality_anomalies(self):
"""
检测各模态数据中的异常
返回:
异常检测结果字典
"""
anomalies = {}
for modality in self.modalities:
# 基于置信度和不确定性检测异常
confidence = self.confidence_scores.get(modality, 0.0)
uncertainty = self.uncertainty_measures.get(modality, 1.0)
# 简单的异常检测逻辑
if confidence < 0.3 or uncertainty > 0.7:
anomalies[modality] = {
"is_anomalous": True,
"confidence": confidence,
"uncertainty": uncertainty,
"suggestion": "降低该模态权重或重新校准传感器"
}
else:
anomalies[modality] = {
"is_anomalous": False,
"confidence": confidence,
"uncertainty": uncertainty
}
# 检测模态间不一致性
inter_modality_anomalies = self._detect_inter_modality_inconsistencies()
return {
"intra_modality_anomalies": anomalies,
"inter_modality_anomalies": inter_modality_anomalies
}
def _detect_inter_modality_inconsistencies(self):
"""检测模态间的不一致性"""
# 简化实现,实际应比较不同模态的输出一致性
return {"detected": False, "details": "各模态数据一致"}
def adapt_to_anomalies(self, anomaly_results):
"""
根据异常检测结果调整系统
参数:
anomaly_results: 异常检测结果
返回:
适应措施
"""
adaptations = []
# 处理单模态异常
for modality, result in anomaly_results["intra_modality_anomalies"].items():
if result["is_anomalous"]:
adaptations.append({
"type": "weight_adjustment",
"modality": modality,
"action": "decrease_weight",
"reason": f"置信度过低({result['confidence']:.2f})或不确定性过高({result['uncertainty']:.2f})"
})
# 处理模态间不一致
if anomaly_results["inter_modality_anomalies"]["detected"]:
adaptations.append({
"type": "fusion_strategy_change",
"action": "switch_to_robust_fusion",
"reason": "检测到模态间数据不一致"
})
# 记录适应历史
self.adaptation_history.append({
"timestamp": np.datetime64('now'),
"adaptations": adaptations,
"anomaly_results": anomaly_results
})
return adaptations
def generate_fusion_report(self):
"""
生成融合系统报告
返回:
系统状态和性能报告
"""
report = {
"timestamp": np.datetime64('now'),
"active_modalities": self.modalities,
"current_confidence_scores": self.confidence_scores,
"current_uncertainty": self.uncertainty_measures,
"latest_weights": self.weights_history[-1]["weights"] if self.weights_history else {},
"context_state": self.context_state,
"adaptation_count": len(self.adaptation_history),
"anomaly_status": self.detect_modality_anomalies()
}
return report
# 使用示例
def example_adaptive_fusion():
# 定义模态配置
modalities_config = {
"visual": {
"preprocessing": {"denoise": True, "normalize": True},
"feature_extraction": {"type": "cnn_features"}
},
"audio": {
"preprocessing": {"denoise": True, "resample": 16000},
"feature_extraction": {"type": "mfcc_features"}
},
"proprioception": {
"preprocessing": {"calibrate": True, "filter": True},
"feature_extraction": {"type": "kinematic_features"}
}
}
# 创建融合系统
fusion_system = AdaptiveMultimodalFusion(modalities_config)
# 模拟处理各模态数据
visual_data = "模拟视觉数据"
audio_data = "模拟音频数据"
proprio_data = "模拟本体感受数据"
visual_features, _, _ = fusion_system.process_single_modality("visual", visual_data)
audio_features, _, _ = fusion_system.process_single_modality("audio", audio_data)
proprio_features, _, _ = fusion_system.process_single_modality("proprioception", proprio_data)
# 更新上下文
context = {
"lighting_condition": "normal",
"noise_level": "low",
"task_type": "navigation"
}
fusion_system.update_context(context)
# 计算自适应权重
weights = fusion_system.calculate_adaptive_weights()
print("自适应权重:", weights)
# 准备特征字典
features = {
"visual": np.random.random(128), # 模拟特征向量
"audio": np.random.random(128),
"proprioception": np.random.random(128)
}
# 融合特征
fused_features = fusion_system.fuse_features(features, weights)
print(f"融合特征维度: {len(fused_features)}")
# 模拟决策结果
decisions = {
"visual": np.array([0.8, 0.1, 0.1]), # 类别概率分布
"audio": np.array([0.1, 0.7, 0.2]),
"proprioception": np.array([0.2, 0.3, 0.5])
}
# 融合决策
fused_decision = fusion_system.fuse_decisions(decisions, weights)
print("融合决策结果:", fused_decision)
# 检测异常
anomalies = fusion_system.detect_modality_anomalies()
print("异常检测结果:", anomalies)
# 适应异常
adaptations = fusion_system.adapt_to_anomalies(anomalies)
print("适应措施:", adaptations)
# 生成报告
report = fusion_system.generate_fusion_report()
print(f"报告生成时间: {report['timestamp']}")
return report跨模态感知的安全挑战
1. 传感器攻击面分析
具身AI系统的传感器攻击面主要包括:
- 物理攻击:直接干扰或损坏传感器硬件
- 信号注入:向传感器注入伪造信号
- 欺骗攻击:生成对抗样本欺骗传感器处理算法
- 重放攻击:重放预先录制的传感器数据
- 拒绝服务:干扰传感器正常工作
- 隐私侵犯:利用传感器收集敏感信息
2. 多模态欺骗攻击
针对跨模态感知的高级欺骗攻击:
- 模态不一致攻击:注入不一致的多模态信息
- 协同欺骗:同时攻击多个模态使其产生一致的错误感知
- 时序欺骗:在特定时间点攻击破坏时序一致性
- 上下文操纵:通过操纵上下文环境影响多模态融合
- 适应性攻击:根据系统响应动态调整攻击策略
3. 融合系统的脆弱性
跨模态融合系统的特有脆弱性:
- 模态依赖风险:过度依赖特定模态
- 融合规则攻击:针对融合算法的定向攻击
- 置信度操纵:操纵系统对各模态的置信度估计
- 自适应机制滥用:利用系统的自适应机制进行攻击
- 信息不对称利用:利用系统对环境信息的不完全了解
跨模态安全融合机制
1. 多层次防御架构
具身AI跨模态安全融合的多层次防御架构:
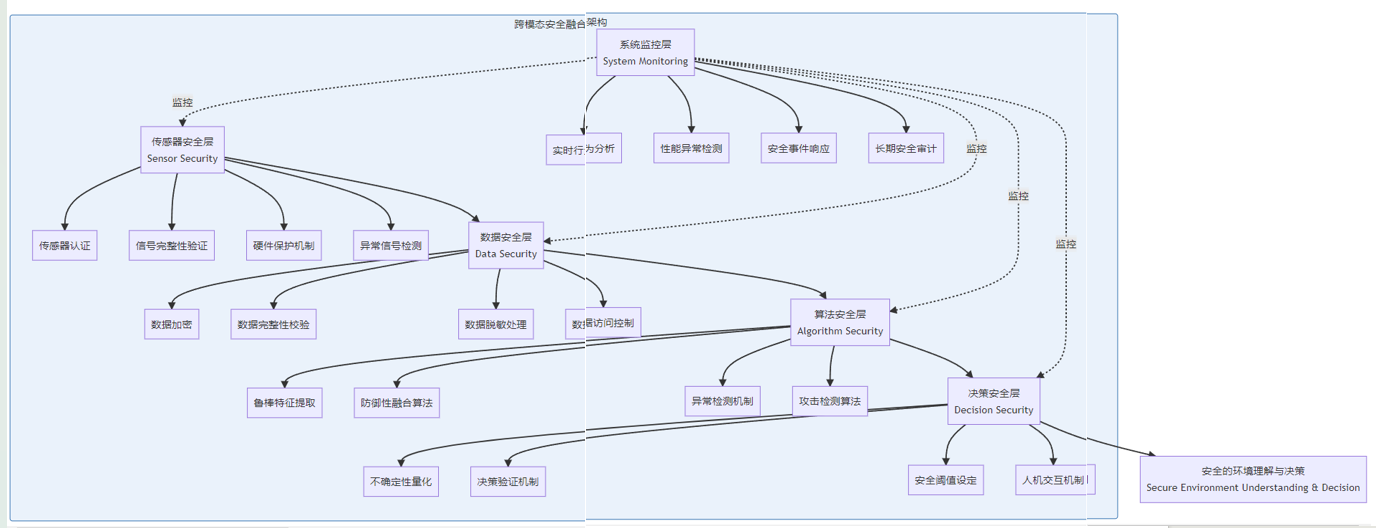
2. 传感器可信验证
传感器数据可信性验证方法:
- 硬件级验证:基于硬件安全模块的传感器身份验证
- 数据一致性校验:跨传感器数据一致性检查
- 物理约束验证:利用物理世界约束验证数据合理性
- 统计异常检测:基于统计模型的异常检测
- 时空一致性验证:验证数据在时空维度的一致性
3. 鲁棒融合算法
增强融合算法安全性的方法:
- 对抗训练:通过对抗样本训练提高鲁棒性
- 模态隔离:隔离不同模态处理防止级联失效
- 鲁棒性度量:实时评估融合系统的鲁棒性
- 安全融合规则:考虑安全因素的融合规则设计
- 降级机制:在攻击情况下的安全降级策略
4. 自适应安全防御
动态调整的安全防御机制:
- 威胁感知:实时感知潜在威胁
- 防御策略切换:根据威胁等级调整防御策略
- 资源动态分配:根据安全需求动态分配计算资源
- 学习型防御:通过机器学习优化防御策略
- 协同防御:多系统间的协同防御机制
跨模态安全融合的实现技术
1. 模态冗余与互补
利用模态冗余增强安全性的技术:
- N-1冗余设计:确保单一模态失效不影响系统安全
- 异构冗余:使用原理不同的传感器提供冗余
- 主动感知:通过主动操作验证被动感知结果
- 模态互补策略:设计互补的模态组合提高鲁棒性
- 冗余信息管理:有效管理和利用冗余信息
2. 异常检测与响应
跨模态异常检测与响应技术:
- 多模态异常检测:利用多模态信息检测异常
- 异常分类与分级:对异常进行分类和严重性分级
- 快速响应机制:异常检测后的快速响应流程
- 自愈能力:系统从异常状态恢复的能力
- 事件记录与分析:记录安全事件并进行事后分析
3. 隐私保护融合
在融合过程中保护隐私的技术:
- 联邦学习:在保护原始数据的前提下进行模型训练
- 差分隐私:在数据中添加噪声保护个体隐私
- 安全多方计算:在不暴露原始数据的情况下进行协同计算
- 同态加密:在加密数据上直接进行计算
- 隐私感知融合:考虑隐私因素的融合策略
4. 安全验证与认证
具身AI跨模态感知的安全验证方法:
- 形式化验证:通过形式化方法验证系统安全性
- 渗透测试:模拟攻击评估系统安全漏洞
- 安全认证标准:建立跨模态感知系统的安全认证标准
- 运行时验证:实时验证系统行为的安全性
- 第三方审计:独立第三方进行安全审计
应用案例与最佳实践
1. 自动驾驶安全感知
自动驾驶系统中的跨模态安全融合应用:
- 视觉-激光雷达融合:提高环境感知准确性
- 多传感器异常检测:实时检测传感器故障和欺骗
- 安全边界设定:基于多模态信息设定安全操作边界
- 降级运行策略:在传感器受损情况下的安全降级
- 验证与确认:多模态信息相互验证确保安全
2. 工业机器人安全操作
工业机器人中的跨模态安全融合:
- 人机协作安全:通过多模态感知确保人机安全协作
- 环境适应性:适应不同工业环境的感知融合
- 故障诊断与预测:基于多模态信息进行故障诊断
- 操作安全验证:验证操作的安全性和准确性
- 安全培训与模拟:基于多模态数据的安全培训
3. 医疗机器人安全保障
医疗机器人中的跨模态安全融合实践:
- 高精度定位:多模态融合实现高精度定位
- 患者安全监控:实时监控患者状态确保安全
- 手术过程验证:验证手术操作的准确性和安全性
- 异常情况处理:识别并响应异常医疗情况
- 隐私保护措施:保护患者隐私的多模态数据处理
4. 最佳实践指南
跨模态安全融合的实施最佳实践:
- 全面风险评估:在系统设计初期进行全面风险评估
- 分层安全设计:采用分层防御策略
- 持续安全测试:在开发和部署过程中进行持续安全测试
- 安全更新机制:建立安全更新和漏洞修复机制
- 用户安全培训:对系统用户进行安全培训
未来发展趋势与挑战
1. 技术发展方向
跨模态安全融合的未来发展方向:
- 神经形态计算:模仿人脑的高效计算架构
- 量子感知融合:利用量子计算优势处理复杂融合问题
- 自学习安全系统:能够自主学习和适应的安全系统
- 分布式融合架构:去中心化的多智能体融合架构
- 跨平台互操作性:不同平台间的安全互操作
2. 研究挑战
当前面临的主要研究挑战:
- 理论基础:建立跨模态安全融合的统一理论框架
- 计算效率:在保证安全的同时提高计算效率
- 可扩展性:适应不同规模和复杂度的系统
- 可解释性:提高跨模态融合决策的可解释性
- 标准化:建立跨模态安全融合的标准和规范
3. 伦理与社会考量
跨模态感知与安全融合的伦理考量:
- 隐私保护:在增强感知能力的同时保护个人隐私
- 透明度:确保系统行为的透明度和可解释性
- 公平性:避免系统在不同人群和环境中的歧视
- 责任归属:明确系统决策的责任归属
- 社会接受度:提高公众对技术的信任和接受度
4. 标准化与监管
推动跨模态安全融合的标准化与监管:
- 技术标准:制定技术标准规范系统设计和实现
- 安全认证:建立权威的安全认证机制
- 法规框架:完善相关法规和政策框架
- 国际合作:促进国际间的技术交流和标准协调
- 行业自律:推动行业自律和最佳实践共享
结论
具身人工智能的跨模态感知与安全融合是一个复杂而重要的研究领域,对于实现安全、可靠的具身AI系统至关重要。本章从理论基础、架构设计、算法实现、安全挑战、防御机制、应用案例等多个方面全面阐述了这一领域的最新进展和关键技术。
随着传感器技术、机器学习算法和安全机制的不断发展,跨模态感知与安全融合将迎来更多创新和突破。未来的具身AI系统将具备更强的环境感知能力、更智能的融合决策和更可靠的安全保障,为人类社会带来更多价值和便利。
然而,我们也必须清醒地认识到,技术发展总是伴随着新的挑战和风险。跨模态感知系统的复杂性和物理世界的不确定性,使得安全保障工作面临诸多困难。只有通过持续的研究创新、严格的安全验证、完善的监管机制和广泛的国际合作,才能确保具身AI技术的安全、可控、可持续发展,真正造福人类社会。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-11-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号