Google OCS光路解耦揭秘:寒武纪大爆发,从供应链双轨到CPO百万卡全光计算织物

Google OCS光路解耦揭秘:寒武纪大爆发,从供应链双轨到CPO百万卡全光计算织物

AGI小咖
发布于 2025-12-30 20:27:01
发布于 2025-12-30 20:27:01
AGI小咖
本文基于 Google 十年来的 OCS 研发与部署经验,从 TPUv4 的 48 台 OCS 原型验证,到 TPUv7 Ironwood 的 14 万卡级 Jupiter 网络大规模商用,深度复盘了 OCS 如何从边缘辅助设备演变为承载 ICI(Inter-Chip Interconnect)协议 的“内存语义织物(Memory Semantic Fabric)”。文章进一步跳出 Google 视角,横向剖析了2025年技术产业界爆发的 MEMS、Piezo、Robotic、SiPh硅光四大技术流派,并结合 Lumentum R300 商用化进程以及 CPO(共封装光学)的演进路径,预判了未来CPO和OCS融合的百万卡全光计算织物演进。
1、Google OCS光路解耦演进
世界上唯一大规模商业化应用OCS的估计只有Google,从早期的Apollo 项目探索到Ironwood 架构落地,从 TPUv4 的 3D Torus 拓扑到 Jupiter DCN网络中 Spine 层的全面光化,从48台OCS组建3D Torus的4096颗TPUv4 Pod到1024台OCS支撑起147,456 颗 TPU v7 Pod的超大规模互联网络,OCS成为了Google打破数据中心物理限制、实现算力线性扩展的奇点,OCS的角色也从单纯的流量工程工具演变为计算架构的内生组件,从微观计算单元到宏观数据中心架构的物理层解耦与重构。
1.1 ICI 网络革命:从 48 台 OCS 构建 TPUv4 Pod 到 3D Torus 范式
在 ICI 专用网络层面,OCS 的引入彻底改变了超算集群的拓扑构建方式 , Google在NSDI 2023年发表的《TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings》中首次披露了仅适用48台Palomar OCS构建了一个标准的 3D Torus Pod拓扑支撑起了4096颗TPUv4芯片的工程化落地实践 。
其核心黑科技之一是 Google自研的Palomar OCS 基于 3D MEMS 镜面阵列技术,Google 采用了136x136的端口配置 ,内部通过精密的 MEMS 微镜阵列在不经过任何光电转换的情况下,直接在物理层实现了芯片间的高速互联。 OCS 的成本不到系统总成本的 5%,功耗不到 3% ,却支撑起了比 Infiniband 更大规模的无阻塞网络 。
1.2 ICI 演进:TPUv7 Ironwood 与 Twisted 3D Torus 的软硬协同
随着大模型参数规模突破万亿级别、训练数据集跨越万亿Tokens 量级, Google 2025年Hot Chips峰会上 展示其最新的 TPUv7 Ironwood架构 , 为了支撑 TPUv7 支持单 Pod 扩展至 9,216 个芯片 , Google 引入了更为复杂的 Twisted 3D Torus 拓扑 : 通过增加长距离跳线连接来提高对剖带宽和降低网络直径。Ironwood 搭载了新一代 ICI(Inter-Chip Interconnect),总带宽达到 9.6 Tb/s,配合 OCS 实现了超大规模的内存统一寻址( 1.77 PB的全局 HBM 内存池 ) ,打破了单芯片显存容量的物理限制,为万亿参数模型的全量加载提供了物理基础。
这一物理层架构的成功离不开上层技术栈 ( Orion SDN 控制器 与 XLA 编译器 ) 的深度支撑 , 更多关于TPUv4 4096 Pod标准3D Torus环面与 TPUv7 9216 Pod的Twisted 3D Torus环面组网拓扑背后的原理和数学实现以及 上下游供应链生态与CPO技术趋势分析等更 多细节请查看前序文章《Google TPU架构揭秘:OCS光交换,从4x4x4 Cube到9216卡Ironwood的进化引擎》。
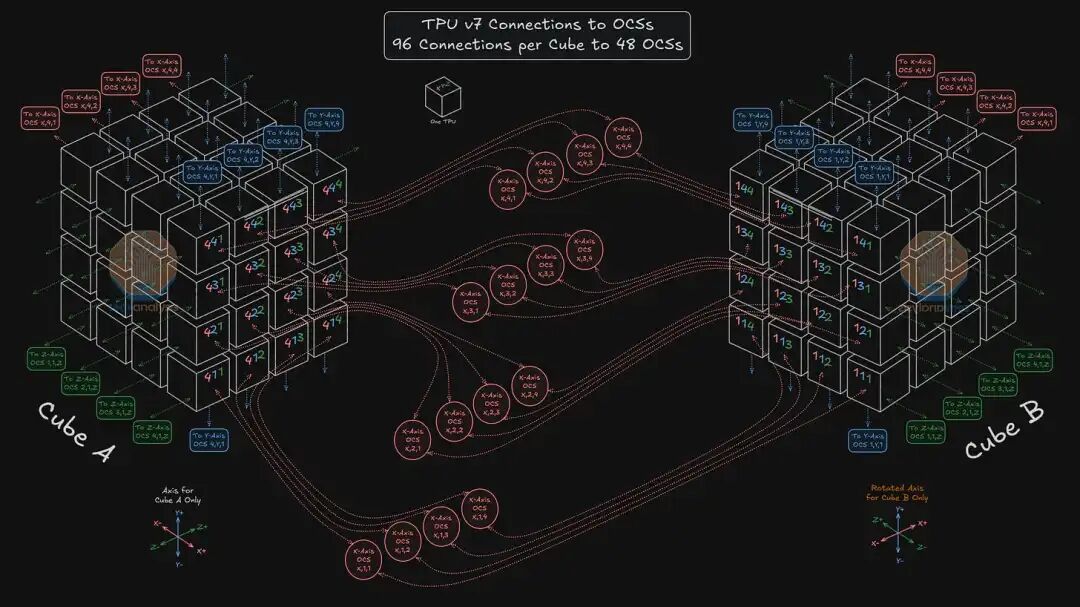
1.3 Jupiter DCN 范式转移:OCS 重构骨干网迈向 14 万卡集群
如果说 ICI 网络是 OCS 在专用超算领域的胜利,那么 Jupiter DCN 的演进则标志着 OCS 在通用数据中心骨干网层面的全面突围。自 2022 年起,Google 开始在生产环境的 Jupiter DCN 网络中大规模部署 OCS,并在 SIGCOMM 发表了里程碑式的论文 《Jupiter Evolving: Transforming Google’s Datacenter Network via Optical Circuit Switches and Software-Defined Networking》 。
在Jupiter Evolving架构中,OCS 替代了传统的电聚合交换机(Aggregation Blocks)。这一替换不仅节省了数以万计的光电转换模块,消除了昂贵的 retimer 组件,更重要的是实现了流量工程 在 物理层卸载。通过集中式SDN 控制平面(Orion), Jupiter Evolving 网络可以根据实时业务负载动态调整光纤链路的物理指向 进而 实现流级而非包级的调度。据内部测算及SemiAnalysis 数据显示 基于OCS的Jupiter Evolving架构 为Google 节省了超过 30 亿美元的资本支出(CAPEX), 更为关键的是 Apollo OCS 波长与端口速率无关的黑科技创新,即使Spine层交换机 从 400G 升级到 800G 乃至 1.6T, 无需更换核心 OCS 设备 , 这也一定程度上 奠定了Google OCS 占据全球光交换市场约 70% 份额的基础 。
在最新的 Ironwood 部署实践中,我们构建了一张包含 73,728 块 400G DCN IPU 网卡、 4,608 台 12.8T ToR 交换机、 2,304 台 25.6T Leaf 交换机以及 2,304 台 25.6T Spine 交换机的庞大物理网络。而在这一切的核心,仅用约 256 台 Apollo OCS 就替代了原本庞大的 Super-Spine 电交换集群,成功支撑起 147,456 颗 TPU v7 的超大规模互联 , 当然 为了驾驭如此复杂的全光网络,Google 构建了从感知到调度的全栈协同体系: 通过 Shim Header 中的 感知层 (CSIG) 遥测数据 + 配合 Titanium IPU 实现 传输层 (Falcon) 协议的硬件级卸载 +全局大脑调度层 (Orion)等一整套软硬结合组合拳,更多14万卡TPU组网细节以及Jupiter DCN架构演进路线请查阅前序文章 《Google Jupiter DCN揭秘:Apollo OCS光交换,重构传统CLOS迈向百万卡集群的范式革命》。
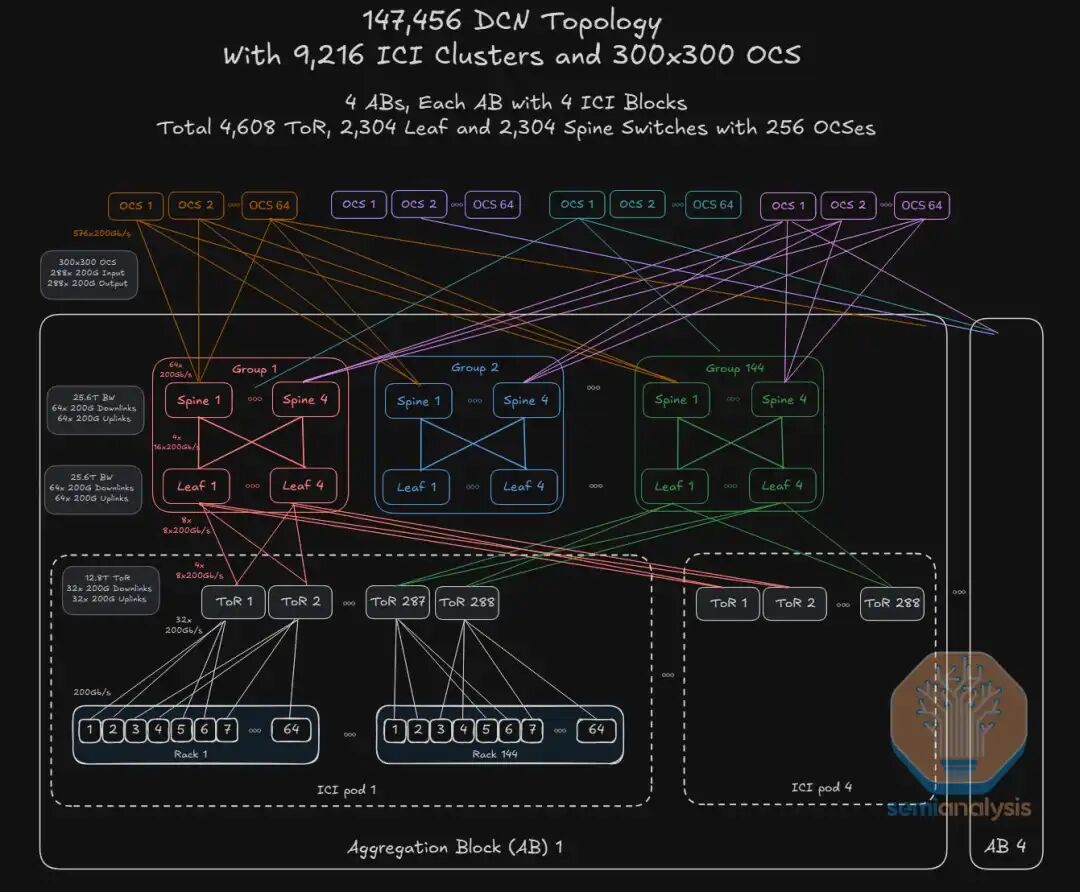
1.4 供应链双轨制:内修与外扩
在上一篇Jupiter DCN网络的分享中我们推演了新增部署14万卡TPUv7单一超大规模集群的时候合计需要256台OCS替换Super-spine电交换集群,加上14万卡TPUv4模块化部署在4个Aggregation Block(AB)中,每个 Aggregation Block(AB)由4个ICI pod组成,而每个ICI pod中部署的9216颗TPUv7 Ironwood需要48台OCS,那么合计部署14万卡TPUv7超大规模集群的合计需要1024台OCS(256+4844),而2027年之前通过 “先租后买” 的 方式合计适用Google TPU芯片100万颗,以14万颗TPUv7为一个最小单元组网拓扑单元推测,为了支撑Meta 100万颗TPU芯片仅OCS的数量就达到了7168台;若按照行业机构普遍共识推测的2026年Google TPU出货量为400万到600万之间,乐观预计OCS的数量达到2.8万到4.3万台之间。为了保障如此突发大规模OCS和TPU芯片交付安全与成本可控, Google 实施了严格的供应链双轨策略:
- 路线一 ( 内部 80%): 核心产能依旧基于 Google 自研的 Apollo 协议及定制化硬件。其中,核心 MEMS 微镜阵列的设计 IP 由 Google 掌握,并由瑞典 Silex Microsystems 进行晶圆代工;最终的 L10 系统集成 、光路自动对准及整机测试由 Celestica (天弘科技) 完成。这一闭环确保了核心技术栈的私密性与大规模制造的成本控制。
- 路线二 ( 外部 20%): 引入 Lumentum (及其 R300 平台)和 Coherent 作为商用供应商。随着光开关技术的标准化,Google 开始采购符合 OCP 规范的商用 OCS 设备 和进一步降本增效,即 通过引入外部竞争倒逼内部成本下降,同时 也用市场需求倒逼OCS技术的行业标准化和上游产业链成熟与升级。
2、OCS 四大技术流派的工程实现与横向对比
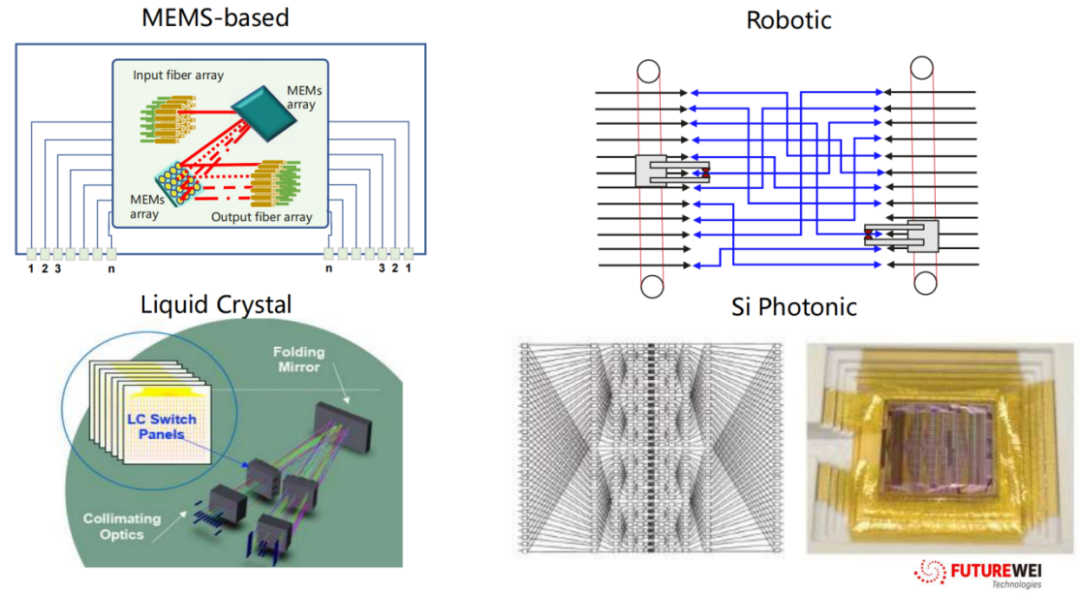
综合 Futurewei Beyond CLOS 报告及OC P峰会等材料分析,2025年OCS技术流派主要有以下4种:
流派一: Google 3D MEMS
目前技术相对最成熟的方案,即文章前半部分提到的Google Apollo OCS,通过 高压静电驱动的2D Mirror Array 在3D空间(即 ±X, ±Y, ±Z 六个方向 ) 内实现光束的精密偏转与交叉连接 ,得益于MEMS OCS 对波长和速率的天然透明性,即使Spine层交换机从 400G 升级到 800G 乃至 1.6T,无需更换核心 OCS 设备,克服了摩尔定律失效带来的硬件迭代压力。 除了Google以外,Lumentum 也发布的 R300 实现了300x300端口规模,且插入损耗(IL)控制在 <1.5dB 。
流派二:Piezo (压电陶瓷)
利用压电材料的逆压电效应驱动光纤准直器进行物理位移或偏转 来 实现光路切换 , 核心优势在于速度与暗光纤特性: 可实现纳秒级(<3ns)的切换速度且具备 Dark Fiber 特性。由于其极低的光学损耗和极高的稳定性在对时延极度敏感的金融高频交易及需要纳秒级同步精度的量子计算网络中占据主导地位,但受限于压电致动器的体积,很难做到500+的超高端口密度。
流派三:Robotic (机械臂/自动跳线)
在标准机架内使用精密的机械臂(Robot)物理地抓取光纤接头并插入目标端口 , 本质上是一个全自动化的配线架。Telescent 提供的这个Robotic解决方案 并非要替代MEMS OCS进行频繁的流量调度,而是 实现数据中心内部 物理布线 的 自动化 ,主要用于解决大规模光纤管理的复杂性, 方案的最大的缺点是故障切换时间是秒级甚至分钟级。
流派四:SiPh硅光
利用马赫-曾德尔干涉仪(MZI)或微环谐振器(MRR)在硅基芯片上实现光路开关 ,Enablence 和剑桥大学的研究代表了SiPh 技术方案的 未来 发展方向,剑桥大学的研究展示了基于SOI 平台的 4x4x4λ 空间波长选择开关(SWSS),利用微环谐振器实现极低串扰和紧凑尺寸,实现了纳秒级(ns)甚至亚纳秒级切换速度,具备真正的“光包交换”潜力,是 CPO 时代的理想搭档, 目前的主要瓶颈在于插入损耗较高(需配合光放大器)和偏振敏感性。
维度 | 3D MEMS | Piezo | Robotic | SiPh |
|---|---|---|---|---|
产业代表 | Google/Lumentum | Huber/Suhner (Polatis) | Telescent | Enablence/Cambridge University |
切换机制 | 微镜翻转 | 压电对准 | 机械臂插拔 | 热光效应 |
切换速度 | ms | ns/µs | s | ns |
插入损耗 | <2dB | <1.5dB | <0.5dB | >3dB |
应用场景 | AI训练集群核心交换 | 量子网络、HFT | 物理层重构、运维 | CPO 集成、边缘交换 |
成熟度(2025) | 商用主流 | 特种商用 | 试商用 | 研发/早期商用 |
表1:四大技术流派横向对比矩阵
3、生态大融合 与行业展望
Google 的 OCS 核心 MEMS 芯片的制造上高度依赖瑞典MEMS 代工之王 Silex Microsystems—— Google OCS背后真正的“造镜人”。Silex 拥有全球最顶尖的纯 MEMS 代工工艺,能够实现复杂的 TSV(硅通孔)和晶圆级键合技术。Google 对 MEMS 镜面的平整度、一致性和良率要求极高,目前全球范围内能稳定承接此订单的代工厂屈指可数。
Lumentum (LITE.US)作为 Google 最大的光学组件供应商,不仅提供用于 TPU 互联的高功率激光器,更直接向Google供应MEMS模块 , 其最新发布的面相核心的300*300端口的 R300和 面向边缘/汇聚层的64*64端口的R64 系列OCS产品已经获得部分超大规模客户的送样检测, Lumentum 的角色正从纯组件供应商向子系统供应商转型,试图让Meta、 Oracle等Hyperscaler厂商 提供 标准化的光交换设备搭建类似 Google TPUv7 Ironwood 的全光集群,大幅降低了光计算的准入门槛。
作为全球光模块龙头中际旭创已深度布局 OCS 和 Silicon Photonics 领域。随着网络架构向全光演进,传统可插拔光模块的价值量面临被 CPO 稀释的风险。中际旭创通过研发光交换子系统及 ELS(外置光源)模块,提前占据光交换节点,防止价值链完全被芯片厂(如 NVIDIA、Broadcom)旁落。
随着可插拔光模块逼近功耗和密度的双重极限,OCS 技术的发展终将在某个奇点与CPO (Co-Packaged Optics)技术在未来的某个时间点交汇。
预计在2026-2028 年,CPO 技术将进入规模化商用阶段 。CPO 将光引擎直接封装在 GPU/TPU 的基板上,极大地缩短了电信号的传输距离(SerDes功耗降低 30% 以上),从而提高带宽密度。正如 Nvidia 在 OCP 峰会上通过数据模型所展示的(图4),在 CPO 时代引入 OCS,有望通过消除 spine层电交换机开销进而将网络能耗进一步降低 30%-40%。
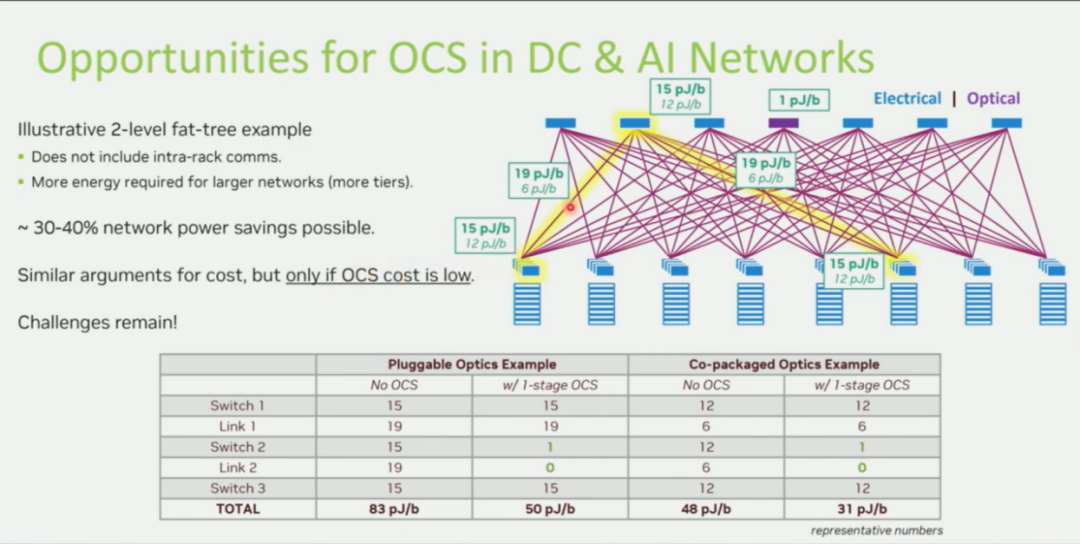
CPO 解决了芯片出光(Chip-to-Fiber)的密度问题 后单芯片带宽可达51.2T以上, 如此巨大的带宽如果继续使用电交换机进行汇聚,将导致交换机芯片过热且布线无法管理。因此,CPO 时代的计算节点将直接输出海量光纤,这些光纤必须直接接入 OCS 进行全光路由。NVIDIA在GTC 2025 上展示的基于硅光的 Spectrum-X/Quantum-X 概念,实际上已经预示了交换芯片内部集成光路的大趋势 。
或许不久的将来我们将看到数据中心架构演进为全面CPO计算单元+一层OCS交换层+编排调度控制层——数万个CPO计算节点通过高端口密度(可能基于 Robotic或高密度MEMS)的 OCS互联 , 编译器不仅生成计算拓扑,还能生成网络拓扑,对于每一个训练任务,OCS 都会物理地重构出一个最优的3D Torus 或 Dragonfly 拓扑。当CPO解决了出芯片的“第一公里”,OCS 解决了跨机柜的“最后一公里”, 真正实现 数据从 HBM 流出后将不再经历多次光电转换,而是直接在全光域内完成计算流转,构建起真正的行星级全光计算织物。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者
