柯尔莫哥洛夫-阿诺德网络(KANs):理论基础、架构范式与应用前景综述
原创
柯尔莫哥洛夫-阿诺德网络(KANs):理论基础、架构范式与应用前景综述
原创
走向未来
发布于 2026-01-12 10:07:30
发布于 2026-01-12 10:07:30
万字长文详解KAN:理论基础、架构范式与应用前景
走向未来
在人工智能发展的历史长河中,多层感知机(MLP)作为连接主义的基石,长期占据着统治地位。然而,随着科学计算、物理建模以及高精度函数逼近需求的日益增长,传统MLP在参数效率、可解释性以及高频信号捕捉能力上的局限性逐渐显现。就在此时,Kolmogorov-Arnold Networks(KANs)作为一种基于柯尔莫哥洛夫-阿诺德叠加定理(KST)的全新架构应运而生。这不仅仅是神经网络架构的一次微调,更是对函数逼近本质的一次深刻回归与重构。我们正处于一个从通用近似向结构化叠加范式转移的关键节点,KANs的出现标志着人工智能在处理复杂连续系统时,开始具备了更深厚的数学底蕴和更灵动的适应能力。
通过对最新文献《A Practitioner's Guide to Kolmogorov-Arnold Networks》的深度研读与剖析(注:该报告全文可以从【走向未来】知识星球中获取),我们发现KANs正在经历大爆发式的演进。从早期的理论雏形到如今涵盖样条函数、多项式、小波、傅里叶等多种基函数的庞大族群,KANs不仅在理论上挑战了MLP的霸主地位,更在实际应用中展现出了惊人的潜力。本文将摒弃浅层的技术罗列,深入到KANs的数学肌理,探讨其如何通过基函数的选择重塑学习的本质,并基于深厚的技术积累,展望其对未来AI基础设施、芯片设计及智能体系统的深远影响。我们坚信,KANs并非昙花一现的学术玩具,而是通向下一代高能效、高可解释性人工智能的重要桥梁。
1希尔伯特第十三问题与KST的现代回响
要真正理解KANs的革命性,我们必须回到1900年。大卫·希尔伯特提出的第十三问题,质疑是否存在无法用二元函数叠加表示的三元函数。半个多世纪后,柯尔莫哥洛夫和阿诺德用惊人的数学定理给出了否定的答案:任何多元连续函数都可以表示为单变量连续函数的有限叠加。这就是著名的柯尔莫哥洛夫-阿诺德叠加定理(KST)。

b/010.jpg
然而,历史的吊诡之处在于,KST在很长一段时间内被视为数学上的病态存在。因为KST构造出的内部函数往往是极其不光滑的、分形的,甚至是处处不可微的。这使得早期的学者认为KST对神经网络毫无实用价值。正如文献中所指出的,现代KANs实际上是受KST启发而非对其的精确实现。这是一个至关重要的区分。现代KANs用光滑的、可学习的基函数(如B样条)替代了KST中那些怪异的通用内部函数,并放弃了KST中对分离性的严格要求。
这种背叛恰恰是KANs成功的关键。通过引入平滑性,KANs将一个纯粹的数学存在性定理转化为了一种高效的计算架构。在传统的核方法视角下,浅层的KANs在解决一维问题时,在数学上等价于经典的核回归模型。当我们把目光投向高维空间时,差异便显现出来。传统的核方法依赖于张量积或径向基函数来构建多变量特征,这直接导致了维数灾难。而KANs通过层级化的叠加结构,避免了显式的张量积构造,从而以加法结构逼近乘法交互。这种结构上的精妙之处在于,它通过深度的复合,将多变量函数的复杂性分解为一系列单变量函数的组合,这种分解方式在本质上更符合物理世界的构成规律。
更深层次的分析表明,深度KANs中的系数耦合是非线性的。在多层结构中,每一层的参数变化都会通过复合函数非线性地传递到最终输出。这意味着,深度KANs的参数空间具有极其丰富的拓扑结构,能够通过参数的微小扰动实现函数形态的剧烈变化。这种非线性系数耦合机制,赋予了KANs在参数数量远少于MLP的情况下,依然拥有极强表达能力的数学基础。我们观察到,KANs实际上是在进行一种自适应的坐标变换,每一层都在为下一层寻找最优的单变量基函数表示,这种级联的坐标变换能力,正是其超越传统核方法的根本原因。
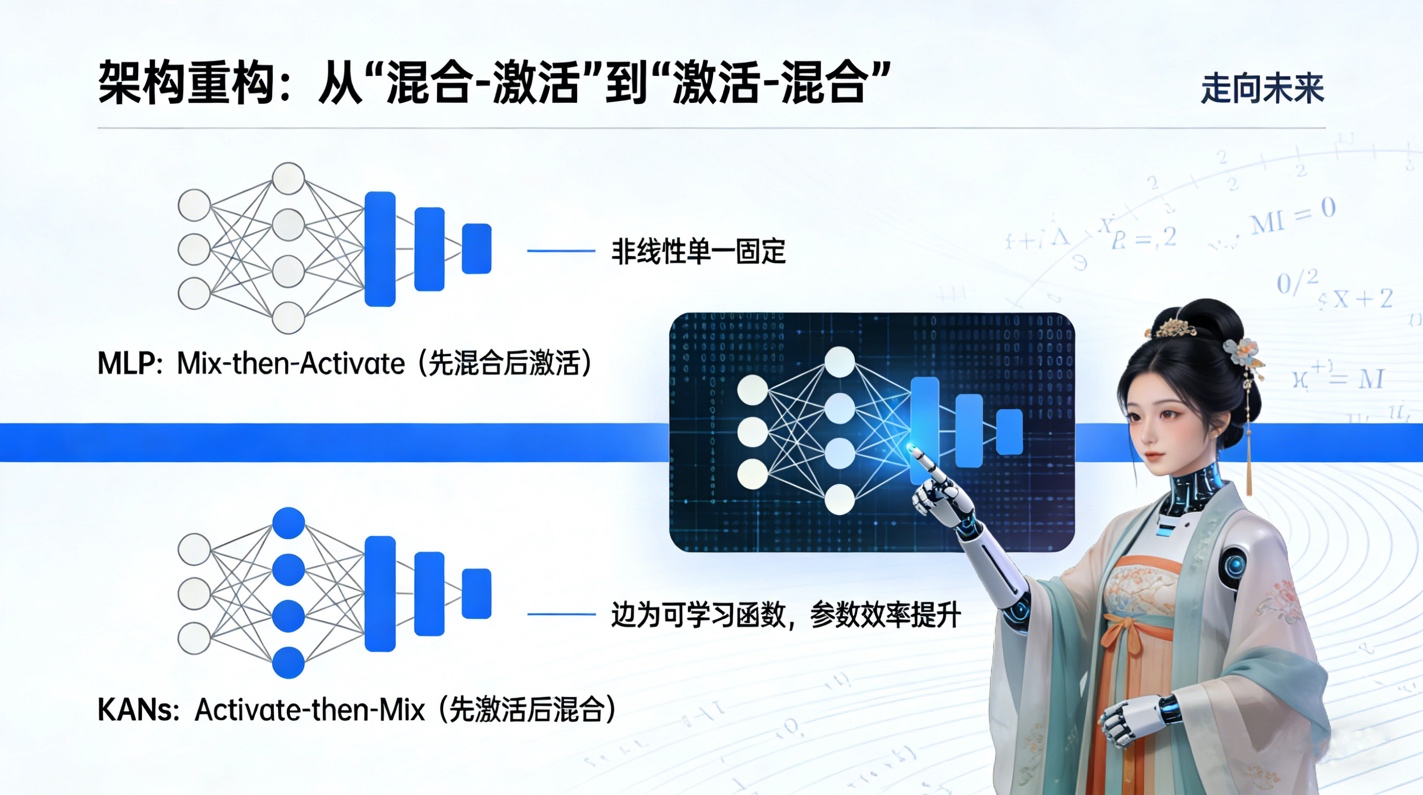
2从混合-激活到激活-混合的范式转移
多层感知机(MLP)的核心哲学是混合后激活(Mix-then-Activate)。即先通过线性矩阵乘法混合输入特征,然后通过固定的非线性激活函数(如ReLU或Sigmoid)进行变换。这种设计的优势在于矩阵乘法极易在GPU上并行化,但其缺陷也同样明显:非线性被限制在节点上,且形式单一固定。
KANs彻底颠覆了这一范式,提出了激活后混合(Activate-then-Mix)的全新理念。在KANs中,连接两个神经元的不再是简单的标量权重,而是一个可学习的非线性函数。这意味着,网络中的每一条边都变成了一个活跃的计算单元。这种结构上的反转带来了深远的影响。首先,它极大地提高了参数的利用效率。文献中的定理5和定理6通过严格的数学推导证明,KANs可以用更少的参数实现与极深ReLU网络相同的逼近精度。具体而言,KANs的参数复杂度随着宽度的增长呈二次方关系,而其诱导的等效MLP则需要四次方的宽度增长。
b/004.jpg
这种架构的改变还带来了可解释性的回归。在MLP中,权重矩阵往往是黑盒的,难以赋予物理意义。而在KANs中,边上的函数显式地描述了变量之间的变换关系。如果一个边上的函数被训练为零函数,我们可以明确地断定这两个变量之间不存在直接的因果联系。这种显式的稀疏性使得KANs在符号回归和物理规律发现方面具有天然的优势。
我们在分析中发现,KANs的这种架构实际上是在模拟一种广义的加法模型(GAM)。但与传统GAM不同的是,KANs通过多层堆叠,引入了强大的特征交互能力。每一层都在对上一层的输出进行非线性的一维变换,然后求和。这种过程在物理上对应于信号的波形整形与叠加。如果我们把信号看作是信息流,MLP是在不断地旋转和拉伸坐标系,而KANs则是在对信息流的波形进行精细的雕刻。这种对波形的直接操控能力,使得KANs在处理具有复杂波形特征的时间序列和物理场数据时,展现出了比MLP更敏锐的捕捉能力。
3 基函数的艺术:设计空间的无限维度
KANs的灵魂在于边上的可学习函数。这一模块化的设计使得基函数的选择成为了KANs设计的核心轴心。文献中详细梳理了包括B样条、切比雪夫多项式、雅可比多项式、ReLU、高斯径向基(RBF)、傅里叶级数以及小波等多种基函数。这不仅仅是数学工具的罗列,每一种基函数的引入都代表了对特定数据结构先验知识的嵌入。

b/001.jpg
3.1. B样条:局部性的胜利与边界的智慧
B样条(B-splines)是KANs最经典的基函数选择。其紧支集特性意味着每个参数只影响函数的局部行为,这为网络提供了极佳的局部控制能力。当我们需要修改函数在某个区间的形态时,不会牵一发而动全身地影响到其他区域。文献中提到了一个关键的技术细节:网格扩展(Grid Extension)。通过在定义域边界外填充额外的节点,B样条能够保持边界处的全多项式支撑,从而避免了边界效应导致的精度下降。这种对边界处理的细腻程度,展示了KANs在处理实际工程问题时的成熟度。
我们进一步深入思考发现,B样条的网格自适应能力是其超越固定网格方法的关键。通过在训练过程中动态地调整节点位置(Free-knot adaptation)或增加节点数量,KANs能够自动地将计算资源集中在函数变化剧烈或梯度陡峭的区域。这种机制与自适应有限元方法(FEM)有着异曲同工之妙,暗示了KANs在数值计算领域的巨大潜力。
3.2. 多项式族:谱精度的追求与数值稳定性的博弈
对于全局光滑或具有特定振荡模式的函数,B样条的局部逼近可能显得效率低下。此时,切比雪夫(Chebyshev)和雅可比(Jacobi)等多项式基函数便登上了舞台。切比雪夫多项式以其在逼近论中的最优性质而闻名,能够有效克服龙格现象。然而,深度网络中多项式的级联会导致输出值的剧烈发散。文献中提到的Tanh归一化技术是一个极其精彩的工程创新。通过将输入映射到[-1, 1]区间,不仅利用了切比雪夫多项式的最佳逼近域,还巧妙地利用了Tanh函数的饱和特性来抑制梯度的爆炸。
更进一步,分数阶雅可比KANs(fKAN)和有理KANs(rKAN)的引入,打破了整数阶多项式的桎梏。特别是对于具有奇点或长尾分布的物理场,有理函数的引入极大地扩展了网络的表达能力。这实际上是在告诉我们,神经网络的基函数设计应当回归到函数逼近论的本源,根据目标函数的解析性质来定制基函数,而非盲目地使用通用的ReLU。
3.3. 高斯RBF与小波:时频分析的视角
高斯径向基函数(RBF)将核方法的思想引入了KANs。其无限光滑性和指数衰减特性,使其在处理平滑且局部集中的特征时表现优异。文献中提到的FastKAN通过高斯函数逼近B样条,既保留了局部性,又利用了高斯函数的计算高效性。而小波KANs(Wav-KAN)则引入了多尺度分析的视角。通过学习小波的尺度和平移参数,网络能够同时捕捉信号的低频轮廓和高频细节。这对于地震信号处理、湍流模拟等具有多尺度特征的问题具有革命性的意义。
3.4. 傅里叶与谱偏置的修正
传统的MLP存在著名的谱偏置现象,即倾向于先学习低频分量,难以捕捉高频细节。傅里叶KANs通过直接在边上引入正弦和余弦函数,显式地赋予了网络处理高频振荡的能力。这不仅缓解了谱偏置,还为解决高频偏微分方程提供了一种强有力的工具。我们认为,这种显式的频域建模能力,使得KANs在通信信号处理和声学建模领域将大有可为。
4 科学计算的利器:物理信息KANs (PIKANs) 的崛起
如果说MLP是数据驱动的通用近似器,那么KANs则是物理规律的天然描述语言。在科学计算领域,物理信息神经网络(PINNs)已经取得了巨大成功,但PIKANs(Physics-Informed KANs)的出现将其推向了新的高度。

b/006.jpg
4.1. 精度与收敛速度的双重飞跃
文献中的大量实验数据表明,在求解偏微分方程(PDE)时,PIKANs展现出了比传统PINNs更快的收敛速度和更高的精度。这并非偶然。PDE的解往往具有特定的光滑性或奇异性结构,而KANs通过选择合适的基函数(如用于激波的Sinc基或用于光滑流场的谱基),能够更高效地逼近这些解。更重要的是,KANs的导数计算可以通过基函数的解析导数直接获得,避免了自动微分在高阶导数计算时的误差累积和计算开销。
4.2. 谱偏置的克服与高频问题的攻克
如前所述,MLP在处理具有高频振荡解的PDE(如亥姆霍兹方程或高雷诺数流体)时往往束手无策。PIKANs通过引入高频基函数或多尺度小波基,从根本上改变了神经正切核(NTK)的特征值分布。分析表明,KANs的NTK谱通常比MLP更平坦,这意味着各个频率分量的收敛速度更加一致。这种良好的条件数使得PIKANs在面对刚性方程时表现得更加鲁棒。
4.3. 自适应与多保真度建模
在流体力学等复杂问题中,流场的特征往往随时间和空间剧烈变化。PIKANs结合了残差自适应采样(RAD)和网格自适应策略,能够自动将计算资源聚焦在激波面或边界层等关键区域。这种动态的资源分配机制,使得模型在保持计算量不变的情况下,大幅提升了关键区域的解析度。此外,利用多保真度训练框架,KANs可以先在低精度数据上学习流场的大致轮廓,再利用少量高精度数据修正局部细节,这种由粗到精的学习过程符合人类认知的规律,也极大地降低了对昂贵实验数据的依赖。
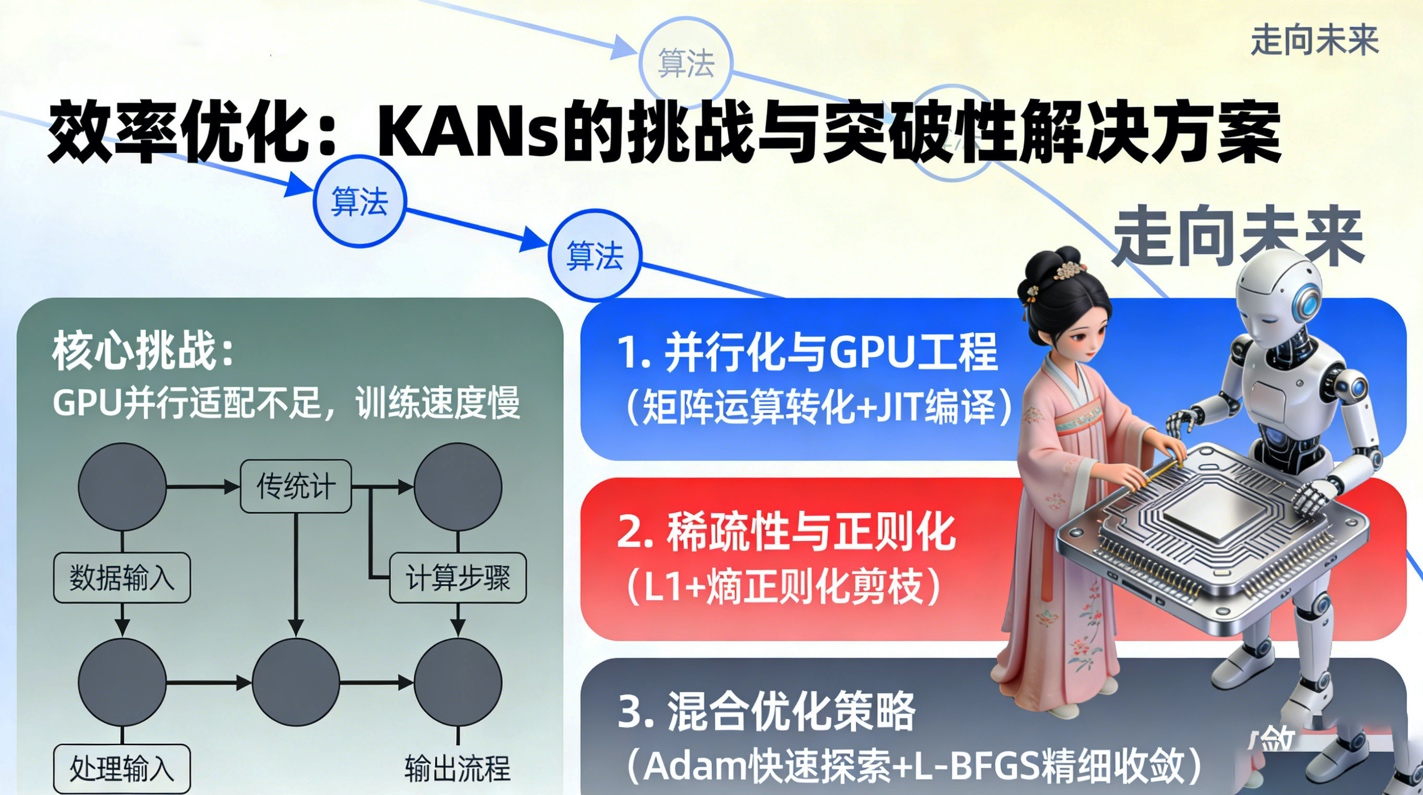
5 效率与优化的辩证:挑战与对策
尽管KANs在理论和精度上表现出色,但我们必须诚实地面对其在计算效率上的挑战。由于KANs无法像MLP那样直接利用现有的矩阵乘法加速库(如cuBLAS),其训练速度在早期实现中往往慢于MLP。然而,文献中展示的一系列优化技术正在迅速填补这一鸿沟。
b/008.jpg
5.1. 并行化与GPU工程
现代KANs的实现已经开始深度利用GPU的并行能力。通过将B样条或多项式的计算转化为矩阵运算,或者利用JAX等现代框架的即时编译(JIT)技术,KANs的训练速度已经得到了数量级的提升。例如,ReLU-KAN和FastKAN等变体,通过简化基函数形式,使其更适合在GPU上进行大规模并行计算。这表明,KANs的效率问题并非架构本身固有的缺陷,而是软件生态尚未完全适配的结果。
5.2. 稀疏性与正则化
KANs的另一个优势在于其天然的稀疏性。通过引入L1正则化和熵正则化,我们可以诱导网络在训练过程中自动剪枝,去除不必要的连接。这不仅降低了推理时的计算量,更重要的是提高了模型的泛化能力。在深度学习中,过参数化往往导致过拟合,而KANs通过基函数的稀疏选择和连接的稀疏化,实现了一种奥卡姆剃刀式的模型压缩。
5.3. 优化器与损失地形
值得注意的是,KANs的损失函数地形往往比MLP更加复杂和崎岖。这导致传统的Adam优化器在某些情况下可能陷入局部最优。文献建议采用混合优化策略,即先用Adam进行快速探索,再用L-BFGS等二阶优化算法进行精细收敛。这种策略有效地结合了一阶方法的鲁棒性和二阶方法的精准性,解决了KANs训练难的问题。
6 创新洞察:KANs对未来AI生态的深远影响
基于对上传文件的深度分析以及深厚的技术积累,我们在此提出一系列具有前瞻性的创新洞察。这些观点不仅是对现有技术的总结,更是对未来发展趋势的预测。
6.1. 硬件层面的重构:从TPU到KPU
目前的AI芯片(如GPU和TPU)主要是为稠密矩阵乘法设计的,这完美契合了Transformer和MLP的需求。然而,随着KANs的兴起,未来的AI芯片架构可能需要发生根本性的变革。我们预测,将会出现专门为样条插值、多项式求值和非线性函数组合优化的处理单元——我们不妨称之为KPU(Kolmogorov Processing Unit)。这种芯片将内置高效的查找表(LUT)和流水线化的基函数计算逻辑,从而在硬件底层释放KANs的高效能潜力。这不仅会改变芯片设计的格局,更将推动EDA工具和指令集架构的演进。

b/009.jpg
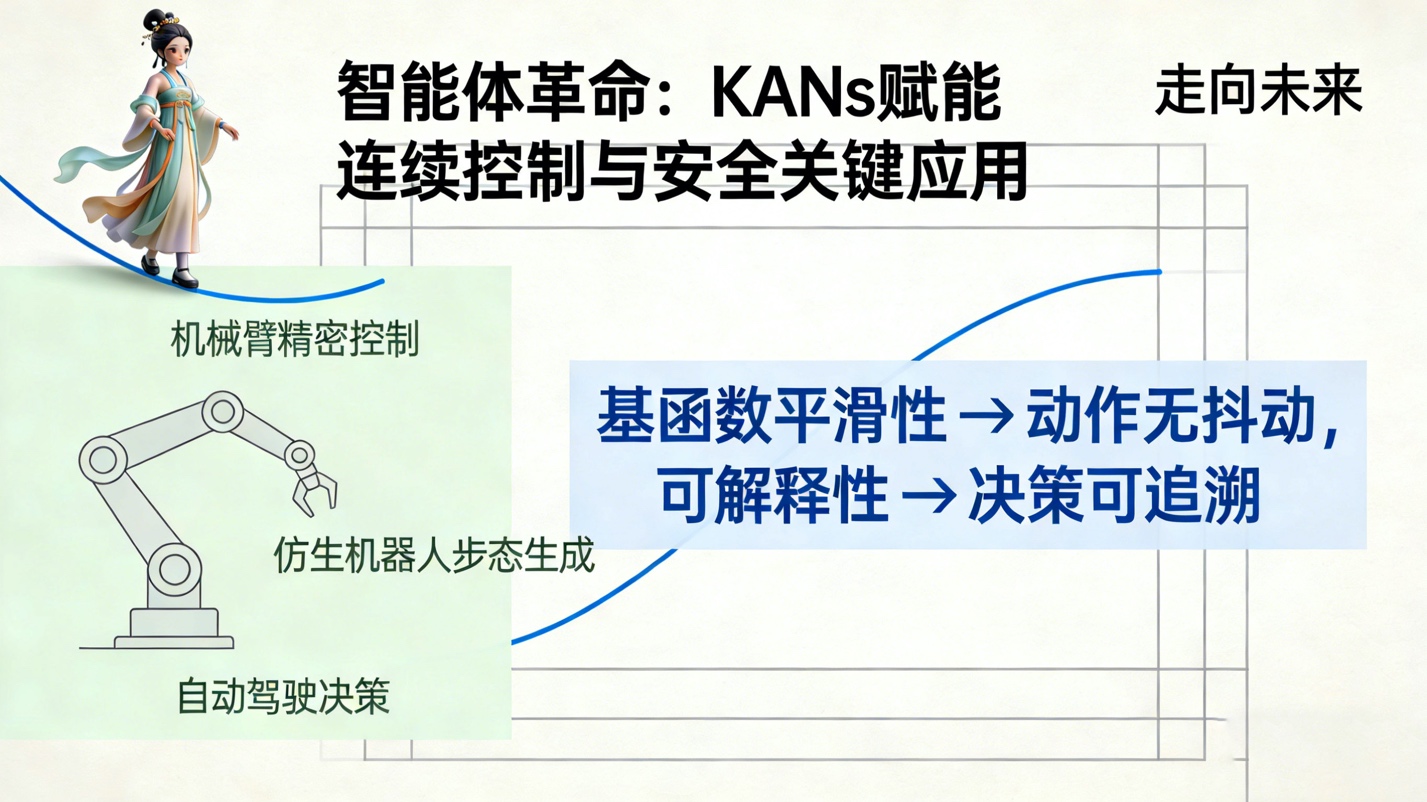
6.2. 智能体与连续控制的革命
在机器人和具身智能领域,动作空间往往是连续且高维的。传统的强化学习策略网络通常使用MLP,输出往往存在抖动或不平滑的问题。KANs由于其基函数的平滑性,天然适合作为连续控制策略的函数近似器。我们预见,基于KANs的强化学习智能体将在机械臂精密控制、仿生机器人步态生成等任务中表现出远超当前SOTA的平滑性和稳定性。更重要的是,KANs的可解释性使得我们能够分析智能体决策的数学依据,这对于安全关键型应用(如自动驾驶)至关重要。
b/003.jpg
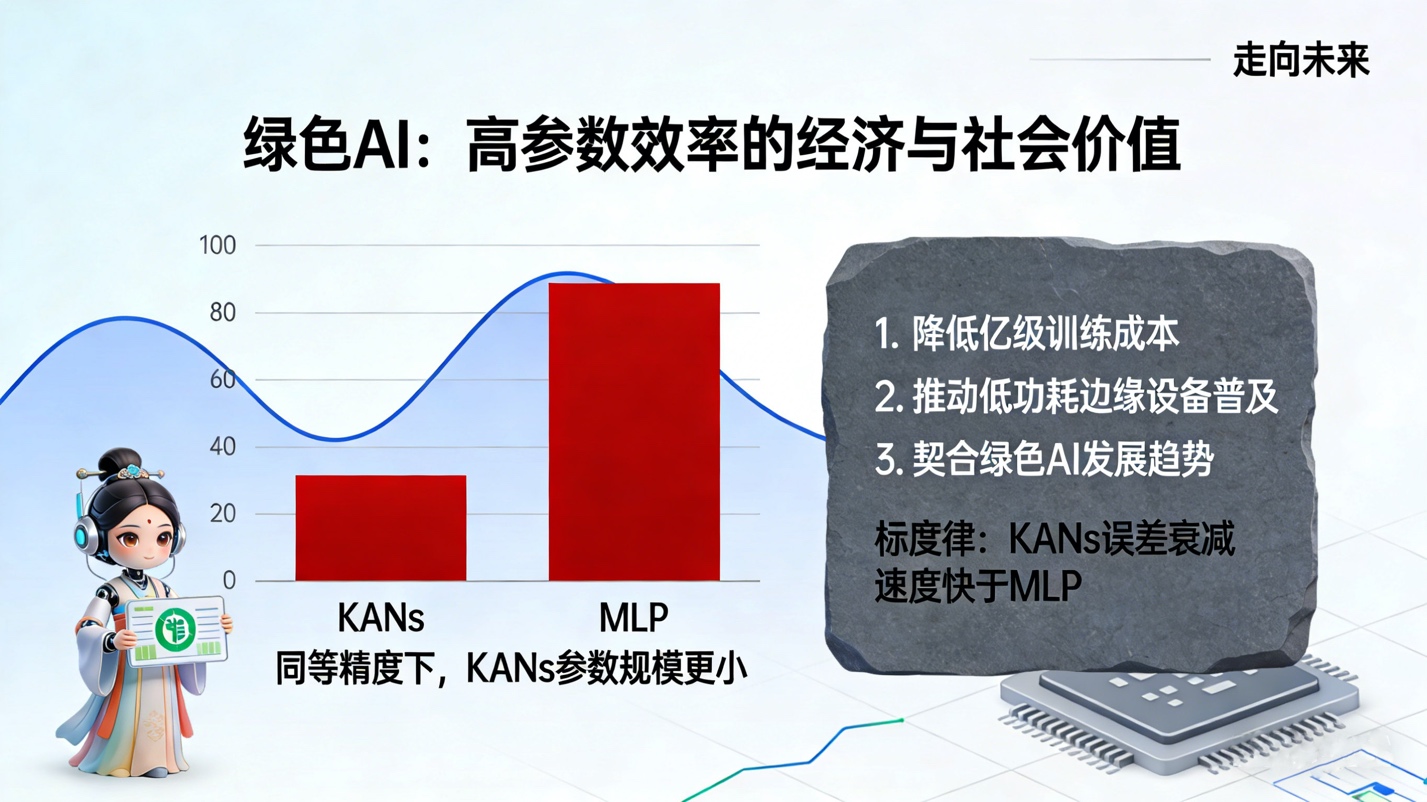
6.3. 绿色AI与经济价值
随着大模型参数量的指数级增长,能源消耗已成为制约AI发展的瓶颈。KANs的高参数效率(Parameter Efficiency)意味着在达到相同精度的情况下,我们可以使用规模小得多的网络。根据标度律(Scaling Laws)的分析,KANs的误差衰减速度快于MLP。这意味着,在未来的大模型训练中,采用KAN架构可能会显著降低算力成本和电力消耗。从经济角度评估,这将为企业节省数以亿计的训练成本,并推动AI技术向低功耗边缘设备的普及,具有巨大的经济价值和社会价值。
b/002.jpg
6.4. 科学发现的自动化引擎
KANs与符号回归的结合(KAN-SR)展示了从数据中自动蒸馏物理定律的可能性。与传统的符号回归相比,KANs提供了一个可微的搜索空间。正如《知识增强大模型》中所深刻指出的,大模型当前面临的幻觉与知识陈旧等固有特性,本质上源于参数化知识的黑盒特性。KANs的出现,实际上在架构层面为这一理念提供了全新的解法:我们可以想象一个自动化的科学发现引擎,它观察实验数据,通过训练稀疏KANs捕捉变量关系,然后将训练好的边函数映射回数学符号。这种机制实现了从外挂式知识增强到内生式架构增强的跨越,将数据中的隐性规律转化可解释与可追溯的演绎推理能力。这将极大地加速材料科学、生物医药和天体物理等领域的基础研究进程,让人工智能真正成为科学家值得信赖的副驾驶。
6.5. 多模态融合的新接口
在多模态大模型中,不同模态(文本、图像、音频)的数据分布差异巨大。MLP通常采用统一的线性层进行投影,这可能抹杀了模态间的精细结构差异。KANs允许为不同的输入维度学习不同的基函数,这为多模态融合提供了一种更灵活的接口。例如,对于高频的音频信号使用小波基,对于平滑的图像特征使用样条基。这种模态自适应的特征提取方式,有望突破当前多模态融合的瓶颈,带来感知能力的质的飞跃。
7 实践指南:如何选择你的KAN
基于文献中的Choose-Your-KAN指南及我们的分析,我们为从业者提炼出一套实用的决策框架:
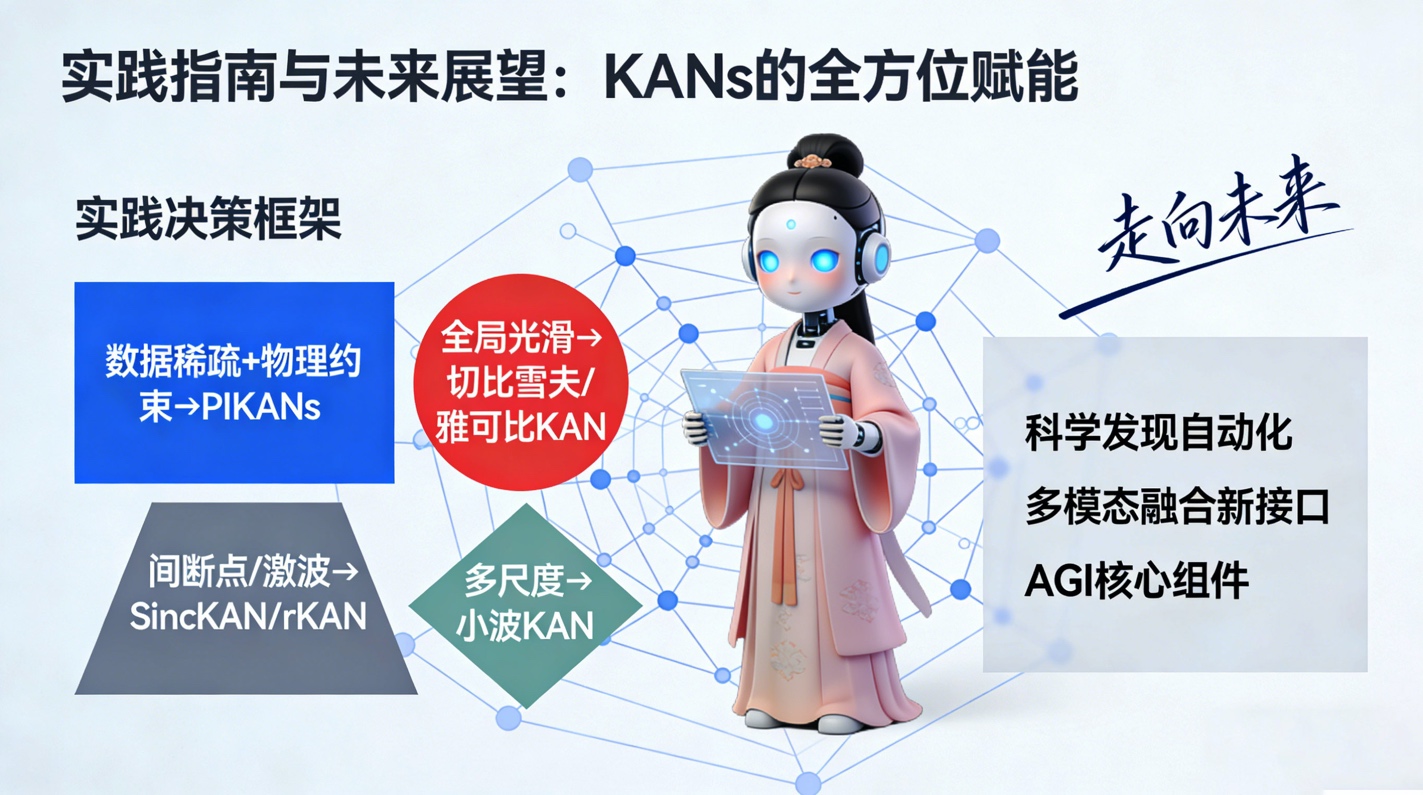
b/005.jpg
- 评估数据稀疏性与物理约束:如果数据稀缺且必须遵守物理守恒定律,首选PIKANs。利用其高阶导数的准确性,将PDE残差直接嵌入损失函数。
- 分析目标函数的光滑性:
- 对于全局光滑且具有谱特征的问题,选用切比雪夫KAN或雅可比KAN,并务必配合Tanh归一化。
- 对于存在间断点、激波或边界层的流体问题,选用SincKAN或有理rKAN,利用其捕捉奇异性的能力。
- 对于一般的回归或分类任务,B样条KAN(配合网格扩展)是稳健的默认选择。
- 考虑计算效率与硬件限制:如果主要瓶颈是推理速度,且部署在标准GPU上,优先考虑ReLU-KAN或FastKAN(基于高斯逼近)。这能最大程度利用现有的CUDA核心。
- 处理多尺度与高维问题:面对具有明显多尺度特征的时间序列或图像,小波KAN是最佳拍档。对于极高维问题,采用FBKAN(有限基域分解)或KKAN(Kurkova-KAN),通过分而治之的策略降低维度灾难的影响。
- 优化策略的定制:不要只依赖Adam。对于高精度的科学计算任务,实施预热+精调策略,即先用Adam快速下降,再切换到L-BFGS榨取最后一点精度。
结语
Kolmogorov-Arnold Networks的出现,绝非是深度学习工具箱中增加了一个微不足道的新组件,而是代表了我们对如何从数据中学习函数这一根本问题的重新思考。从KST的数学抽象到KANs的工程实现,我们见证了数学理论如何穿越百年的时光,在算力时代的土壤中开出绚烂的花朵。
KANs通过将非线性计算从节点转移到边,通过引入可学习的基函数,通过融合物理信息与数学先验,成功地在精度、效率和可解释性之间找到了一个新的平衡点。尽管目前KANs的生态系统尚处于起步阶段,但其展现出的生命力和潜力是无限的。我们有理由相信,随着硬件的适配、算法的优化以及理论的完善,KANs将在未来的科学发现、工业控制、乃至通用人工智能(AGI)的构建中扮演举足轻重的角色。这是一场属于数学家、计算机科学家和工程师的共同盛宴,而我们正站在新时代的门槛上,眺望着一个更加智能、更加精确、更加透明的未来。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号