Deepseek-R1 训练过程,两步四阶段,一图搞定!


Deepseek 是怎样炼成的?
就像怎样把大象放进冰箱里,总共分两步。
step 1:仅通过强化学习RL,获得推理能力涌现,借此得到大量高质量Cot微调数据。
step2:能力迁移!将v3 retrain 一发,得到全能型模型R1。最后还以一个蒸馏,附赠了些小模型。
看似简单,每一步都很关键!下面展开讲讲。
1,推理能力涌现时刻
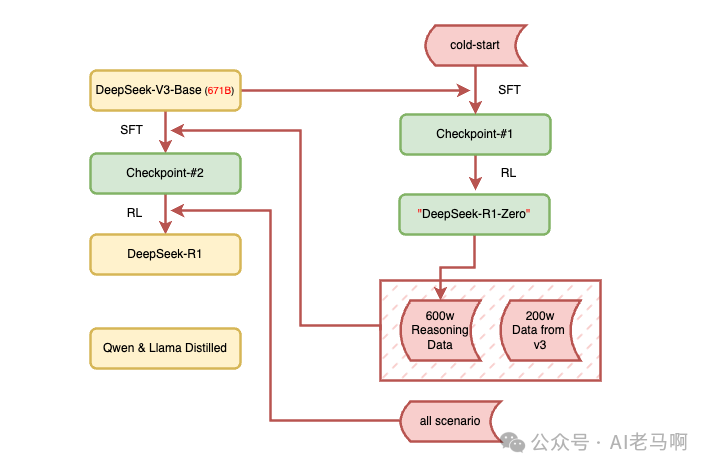
stage-1:SFT,修正过程
训练范式:DeepSeek-V3-base (671B) + cold-start.
目标:1) 使RL训练的前期阶段变得稳定,2)进一步增强推理能力
cold-start 数据构成:
类型:长cot高质量,可读性强且人工double-check数据
量级:千级别
来源:DeepSeek-R1-ZeRo
格式:|special_token|<reasoning process>|special_token|<summary>stage-2:RL (GRPO)
训练范式:收效后的 checkpoint-#1 + 推理数据
目标:获得通现的推理能力。
创新:
Before 大模型训练必备阶段,预训练PT-SFT-RL,总体的步骤是这三步。在SFT阶段需要大量的标注数据,费时费力。
Now 使用base大模型直接强化学习RL!
总结:deepseek 发现在 DeepSeek-V3-Base上仅仅使用RL,就可以得到推理能力非常强的模型 DeepSeek-R1-Zero,这完全打破了之前
模型训练的范式,也是其最大的创新点之一。
经过stage-2训练后的模型基本可用,已经解决了,结果可阅读性差和结果中存在多语种混合的情况!
反思的过程:
- • 在DeepSeek-v3-Base模型上,通过RL获得了推理能力的涌现,但是存在一些的小瑕疵!
- • 通过在进行RL之前,进行cold-start的监智学习,可以得到解决! 此时的模型,已经具有了很强的推理能力,且可读性ok,多语言混杂的问题也已经基本解决。此时它只能算是个偏科生,在一些非推理问题上可能还存在一定问题,昨办?
- • 偏科没有问题,只要你擅长,我就可以利用模型产生大量高质量的推理Cot数据!有了数据,是否就可以把它的能力迁移到其他模型。说干就干!
- • 使用rejection sampling 等策略产生了600W 高质量的Cot数据,又在训练基座v3模型的数据中挑出200W 的非推理数据,总共800W 的数据。到这里,数据已经准备好了,就差东风了。
2,Retrain 一发!
stage-3:SFT
训练范式:DeepSeek-V3-Base + 800W数据
目标:使基座模型获得涌现推理能力,同时具有良好非推理问题的回答能力。
获得模型:checkpoint-#2 (Pre-DeepSeek-R1)
方式:使用之前准备好的800w数据对base模型V3微调了两个epoch,等模型收敛之后,就得到了pre版的 R1模型 Pre-Deepseek-R1。
现在的模型能力基本是ok的,但是还需要再经过一次的RL奖励过程,对齐人类偏好,消除有毒有害内容,最终得到R1模型。
stage-4:RL
训练范式:checkpoint-#2 + 全场景数据
目标:考虑全场景,与人的偏好进一步的对齐消除有毒有害内容。
获得模型:满血版 DeepSeek-R1
3,总结
阶段 | 作用 | 数据 |
|---|---|---|
stage1-SFT | 稳定RL过程,增强可读性,解决多语言问题 | 千级别cold-start |
stage2-RL | 获得涌现的推理能力 | 数学等领域推理数据 |
stage3-SFT | 使用推理和非推理数据,获得全面能力的提升 | 600w推理数据+200w非推理数据 |
stage4-RL | 对齐人类便好,消除有毒有害内容 | 全场景多样化prompt数据 |
思考题: 小模型使用这种的RL策略是否也能,实现推理能力的涌现 Aha moment!
大概率是不行的!论文在Qwen-32B-Base上做了实验,效果远没有使用蒸馏的效果好。
原因: 幼儿园的小朋友不能说有了电脑就会做大学的题目,因为他自身(intrinsic development) 就没有储备足够的知识。只有基础知识都具备了,才能通过强化学习激发出来!所以就理解为什么base模型是671B了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号