DDR内存带宽提升新解:MRDIMM


阅读收获
- 理解内存墙危机的本质:CPU核心数与PCIe带宽的爆发式增长 vs 单核可用内存带宽的持续下降
- 掌握MRDIMM的核心技术原理:通过多路复用芯片(MCD/MDB)实现双Rank并行访问,在主机视角下达成带宽翻倍
- 认识MRDIMM实测性能:在12通道8800 MT/s配置下实现743 GB/s峰值带宽,较顶级DDR5 RDIMM提升40%以上
- 了解部署权衡:高带宽伴随18-21W单条功耗的显著上升,需重新评估机房供电与散热设计
全文概览
当你的AI训练模型因为数据供给不及时而频繁等待,当数据库查询因内存带宽不足而频繁卡顿——这背后可能隐藏着一个被忽视的系统危机:内存墙。过去十年,CPU核心数呈指数级爆发增长,PCIe带宽同样实现了爆发式扩张,但系统内存总带宽的增速却明显滞后。更令人忧虑的是,分摊到每个CPU核心的可用内存带宽不增反降,从2009年的约8GB/s降至2026年的4GB/s左右。这意味着计算资源正在被内存瓶颈逐步蚕食。面对这一困局,业界正在探索一条"低成本、高收益"的突围路径:MRDIMM。它如何在不改变底层DRIM颗粒物理速度限制的情况下实现带宽翻倍?相比HBM等昂贵方案,它的工程价值体现在何处?
👉 划线高亮 观点批注
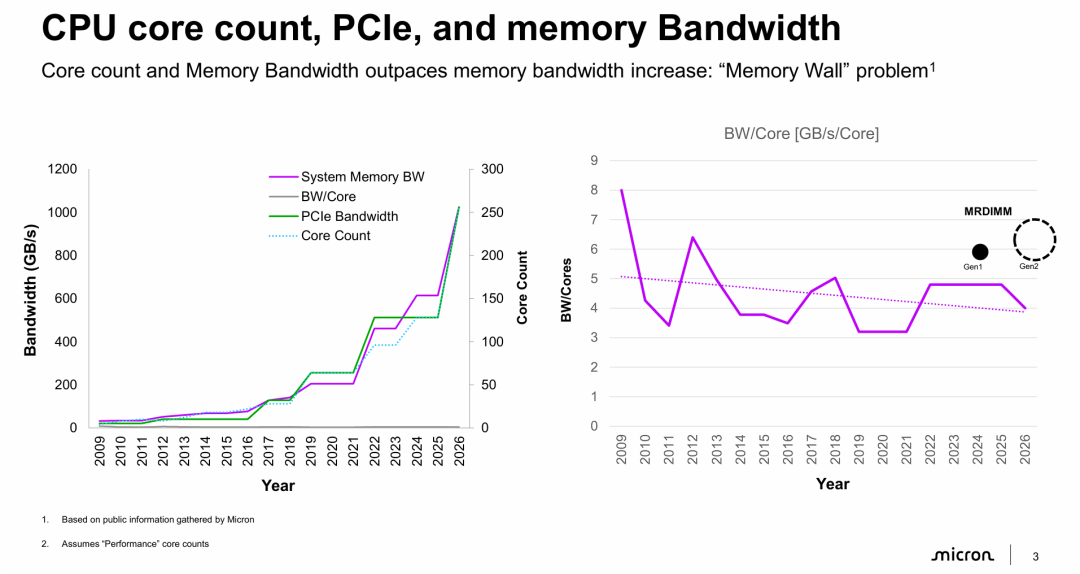
CPU核心数、PCIe带宽与内存带宽的对比
CPU核心数、PCIe带宽与内存带宽的对比
图例与曲线:
- 紫色实线 (System Memory BW): 系统内存总带宽。虽然在增长,但斜率相对较缓。
- 绿色实线 (PCIe Bandwidth): PCIe总带宽。近年来呈现爆发式指数增长。
图片的核心观点是论证“内存墙”危机的真实存在,并指出单核带宽性能正在倒退。
- 计算与IO飞速发展,内存掉队: 在过去及未来几年(2009-2026),CPU的核心数量(算力)和PCIe带宽(I/O吞吐能力)呈现指数级爆发增长,而系统内存总带宽的增长速度相对滞后。
- 单核带宽(BW/Core)不仅没涨,反而在降: 这是最关键的洞察。虽然内存总带宽在增加,但由于CPU核心数增加得更快,分摊到每个核心上的可用内存带宽实际上是在减少的(从2009年的峰值约8GB/s降至2026年的4GB/s左右)。这意味着每个CPU核心“喂不饱”,计算资源被内存瓶颈限制。
- 技术演进的紧迫性(MRDIMM): 右侧图表末尾特别标注了 MRDIMM,表明业界(美光)正在推出如MRDIMM(多路复用列双列直插式内存模块)等新技术,试图打破DDR内存的物理瓶颈,提升带宽密度,以扭转单核带宽下降的趋势,缓解内存墙问题。
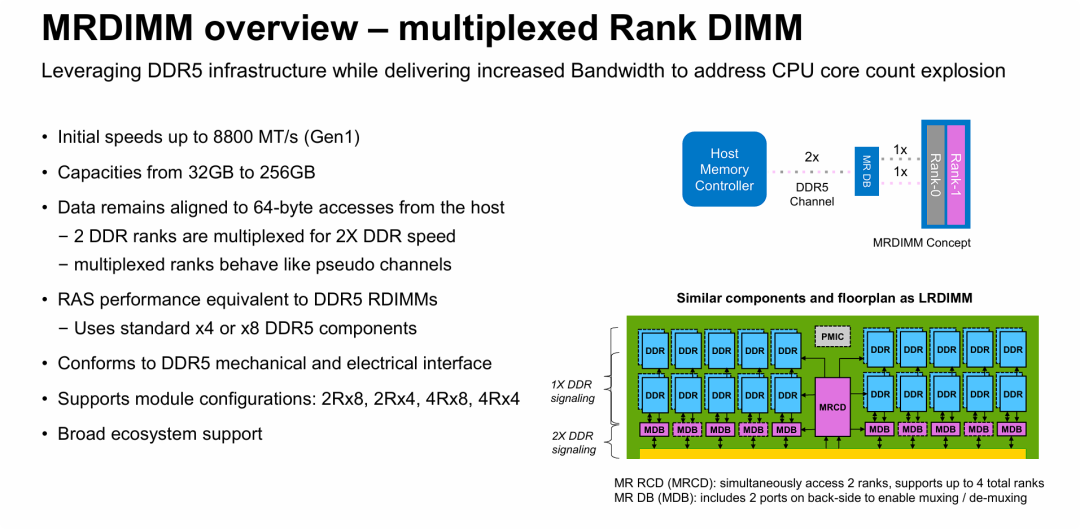
MRDIMM 概览 —— 多路复用 Rank DIMM
MRDIMM 概览 —— 多路复用 Rank DIMM
关键特性列表 (Key Specifications)
- 速度 (Speed): 第一代 (Gen1) 起始速度高达 8800 MT/s。这显著高于标准 DDR5 的主流速率(如 4800/5600 MT/s)。
- 容量 (Capacities): 提供 32GB 到 256GB 的容量选择,覆盖主流服务器需求。
- 数据访问机制:
- 数据保持与主机的 64-byte 访问对齐(符合标准 Cache Line 大小)。
- 核心机制: 2个 DDR Ranks(列)被多路复用 (Multiplexed),从而实现 2倍于标准 DDR 的速度。
- 这些被多路复用的 Ranks 表现得像“伪通道 (pseudo channels)”。
- RAS 特性 (可靠性、可用性、可维护性): 性能与 DDR5 RDIMM 相当,且使用标准的 x4 或 x8 DDR5 颗粒组件。
- 兼容性: 符合 DDR5 的机械和电气接口标准(意味着物理插槽兼容)。
- 模组配置: 支持 2Rx8, 2Rx4, 4Rx8, 4Rx4 等常见配置。
===
图片的核心在于展示 MRDIMM 如何作为一种“中间件技术”,在不改变底层 DRAM 物理速度限制的情况下,大幅提升系统带宽。
- 核心技术原理:并行换高速 MRDIMM 的魔法在于 “多路复用 (Multiplexing)” 。它在模组上引入了特殊的芯片(MRCD 和 MDB),允许主机控制器同时访问两个 Rank 的内存颗粒。
- 主机端视角: 看到的是一条带宽翻倍(如 8800 MT/s)的高速通道。
- 颗粒端视角: 仍然工作在标准的舒适速率(如 4400 MT/s)。
- 结果: 通过并行操作两个 Rank,实现了系统总带宽的翻倍。
- 务实的工程妥协(低成本、高收益): 与 HBM(高带宽内存)等昂贵且封装复杂的方案不同,MRDIMM 选择了一条兼容现有生态的路线:
- 它沿用了标准的 DDR5 颗粒。
- 它沿用了标准的 DDR5 物理插槽和电气接口。
- 它沿用了类似 LRDIMM 的板级布局。 这意味着数据中心无需更换主板或采购特制的高昂内存颗粒,就能获得显著的带宽提升,是解决上一张PPT中“内存墙”问题的高性价比方案。
- 性能目标明确: Gen1 阶段即达到 8800 MT/s,明确对标需要高吞吐量的 AI 推理和高性能计算(HPC)场景,填补了标准 DDR5 和 HBM 之间的巨大的带宽性能鸿沟。
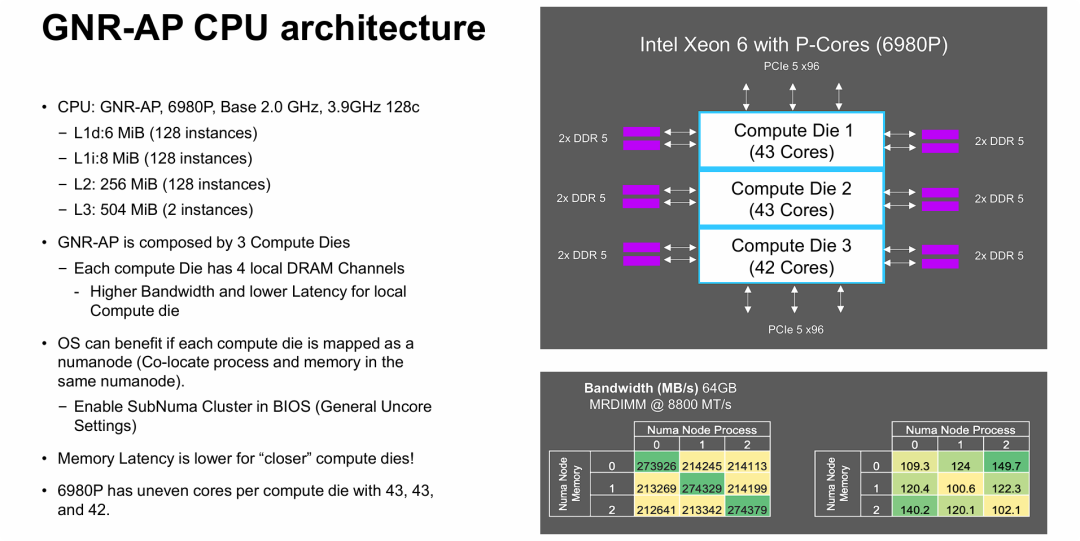
Intel Xeon 6 CPU 架构与 NUMA 拓扑
Intel Xeon 6 CPU 架构与 NUMA 拓扑
图片展示了高性能 CPU 如何通过 Chiplet 架构和 NUMA 优化来驾驭 MRDIMM 带来的巨大带宽。
- 架构决定性能: Intel Granite Rapids-AP 采用了 3 个计算晶片拼接的设计,这种物理分离导致了内存访问的“亲疏有别”(NUMA 效应)。
- 带宽与延迟的权衡: 虽然 MRDIMM 提供了 8800 MT/s 的超高接口速度,但要跑满这个性能,操作系统和软件必须感知硬件拓扑(SNC 设置),尽量让 CPU 核心访问直连的内存通道(Local Memory),否则会面临带宽下降和延迟增加。
右下性能矩阵表 (关键数据):
- 展示了 MRDIMM @ 8800 MT/s 下的性能。
- 带宽表 (左表): 对角线数据(本地访问,如 Node 0 访问 Node 0)最高,约为 274 GB/s。非对角线(跨片访问)下降至约 212-214 GB/s。
- 延迟表 (右表): 对角线数据(本地访问)最低,约 100-109 ns。跨片访问延迟增加至 120-149 ns。
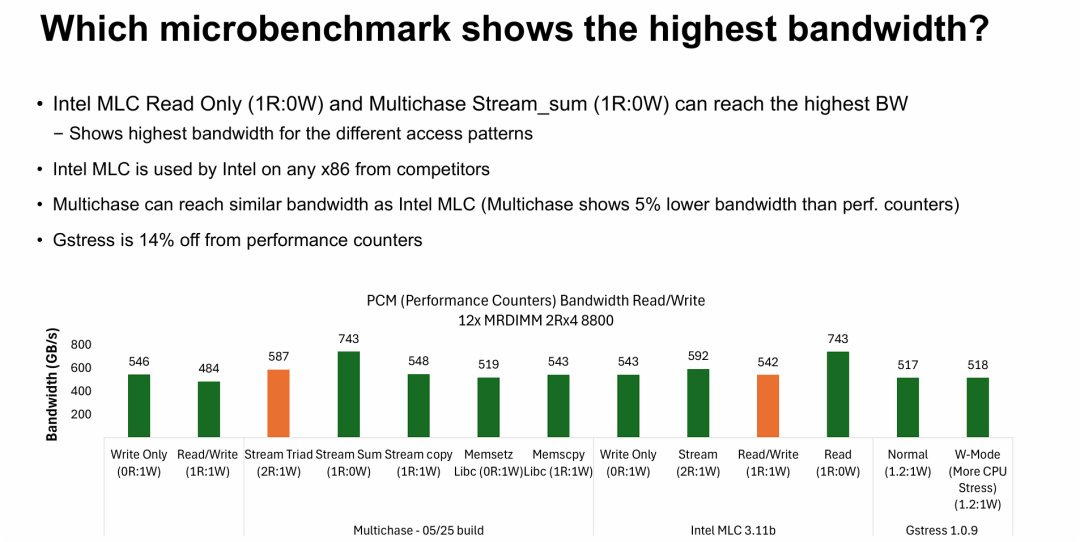
哪个微基准测试能展示出最高带宽?
哪个微基准测试能展示出最高带宽?
图片的核心观点是验证了 MRDIMM 系统的实测峰值性能,并确立了性能测试的方法论标准。
- 实测性能落地: 在 12通道、8800 MT/s 的 MRDIMM 配置下,单路 CPU 的实测内存带宽峰值可以达到 743 GB/s。这个数据验证了之前 PPT 中理论架构的性能潜力。
- 纯读模式(Read Only)决定上限: 数据清晰地表明,100% 纯读(1R:0W) 的访问模式(如 Stream Sum 或 MLC Read)是触达内存墙天花板的最佳路径。一旦引入写入操作(如 1R:1W 或 2R:1W),有效带宽会显著下降(降至 500-600 GB/s 区间)。
- 测试工具的选择至关重要: 在进行高性能存储或内存系统验收时,工具选错了,性能就“没”了。
- 推荐: Intel MLC 是首选的“黄金标准”,Multichase 也是可靠的替代品。
- 避坑: Gstress 在此类超高带宽场景下存在瓶颈,无法反映硬件真实能力。
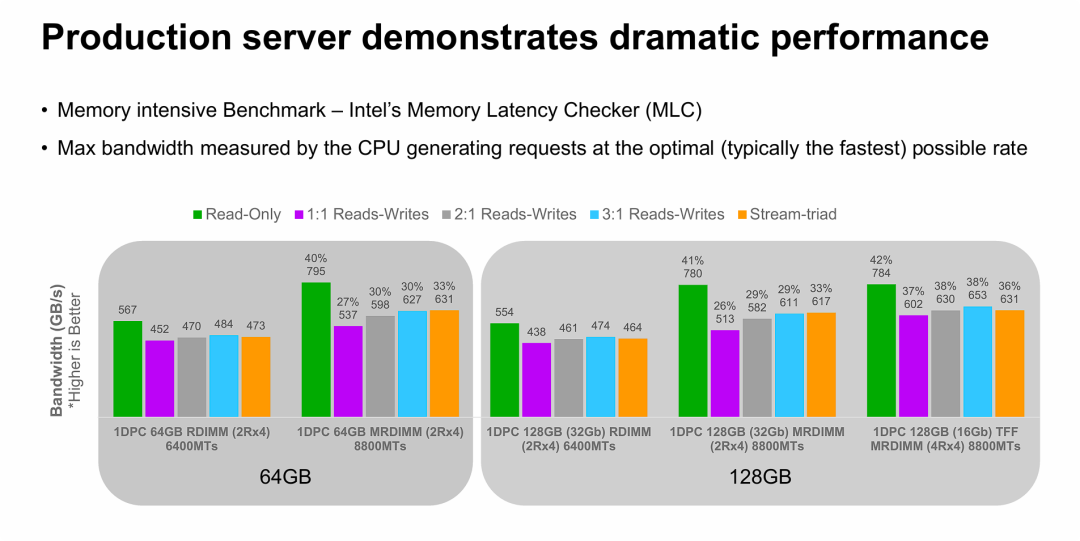
生产场景的IO带宽测试
生产场景的IO带宽测试
- 图表类型: 分组柱状图,对比不同内存配置在不同读写模式下的带宽(GB/s)。
- 颜色代表读写模式(访问模型):
- 🟩 绿色 (Read-Only): 纯读模式,通常带宽最高。
- 🟪 紫色 (1:1 Reads-Writes): 读写混合,负载最重。
- ⬜ 灰色 (2:1 Reads-Writes)
- 🟦 蓝色 (3:1 Reads-Writes)
- 🟧 橙色 (Stream-triad): 典型的内存流测试模式。
- Y轴: 带宽 (Bandwidth),单位 GB/s,数值越高越好。
图片的核心观点是用实测数据证明 MRDIMM 能够带来最高约 40% 的带宽提升,打破了传统 DDR5 的性能天花板。
- 40% 的性能提升: 这是最关键的数字。无论是在 64GB 还是 128GB 容量下,MRDIMM (8800 MT/s) 相比于目前顶级的标准 DDR5 RDIMM (6400 MT/s),在纯读带宽上都实现了 40% 以上 的增长(从 ~560 GB/s 跃升至 ~790 GB/s)。
- 多种IO特征下领先: 不仅仅是纯读模式(跑分通常最高),在各种混合读写模式(1:1, 2:1, Stream-triad)下,MRDIMM 的性能都全面大幅领先。例如在最严苛的 1:1 读写混合场景下,依然保持了约 27%-37% 的优势。
- 大容量不掉速: 对比左右两组数据可以看出,当内存容量从 64GB 翻倍到 128GB 时,MRDIMM 的性能表现非常稳定(795 GB/s vs 784 GB/s),几乎没有衰减。这对于需要大内存容量的 AI 训练和数据库应用来说至关重要。
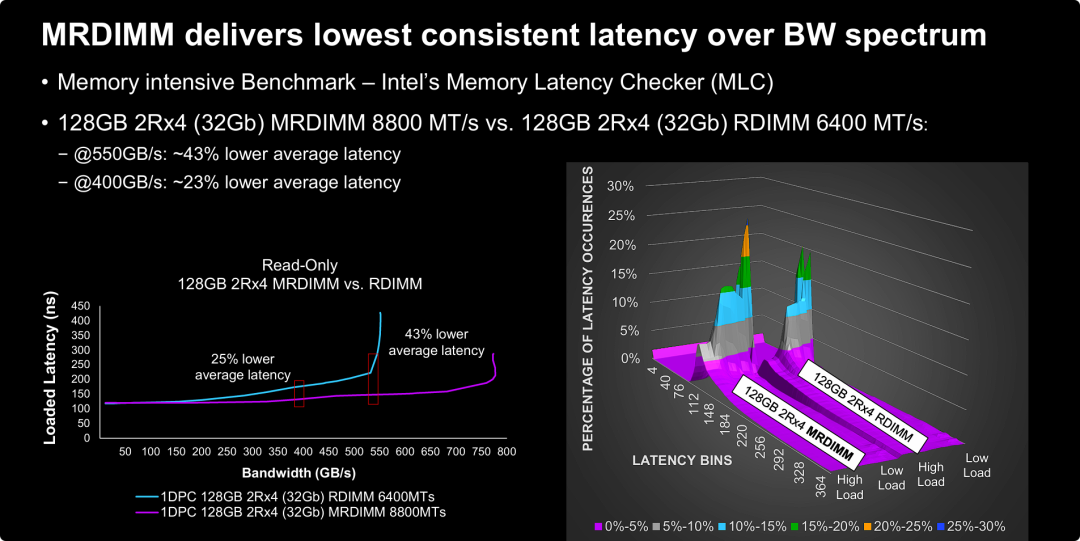
MRDIMM 内存访问时延
MRDIMM 内存访问时延
MRDIMM 解决了“高带宽下的延迟恶化”问题,提供了企业级的服务质量(QoS)。
- 拒绝拥堵(推迟饱和点): 标准的 DDR5 RDIMM 在带宽跑到 550 GB/s 时就会进入“饱和拥堵区”,延迟瞬间失控。而 MRDIMM 由于其 8800 MT/s 的超高通道能力,将这个饱和点推迟到了 800 GB/s 以后。这意味着在同样的业务负载下,MRDIMM 的“公路”更宽,车流跑得更顺畅。
- 极致的稳定性(一致性): 对于数据库和实时交易系统来说,"平均延迟"低固然好,但"最大延迟"(抖动)低更重要。右侧的 3D 图证明,MRDIMM 即使在满负荷运转时,也能保证每次数据存取的响应时间高度一致,避免了业务请求忽快忽慢的现象。
- 提升生产效益: 43% 的延迟降低意味着 CPU 核心等待数据的时间减少了近一半。这直接提升了整个服务器的计算效率,使得用户在不增加 CPU 数量的情况下,能处理更多的并发任务。
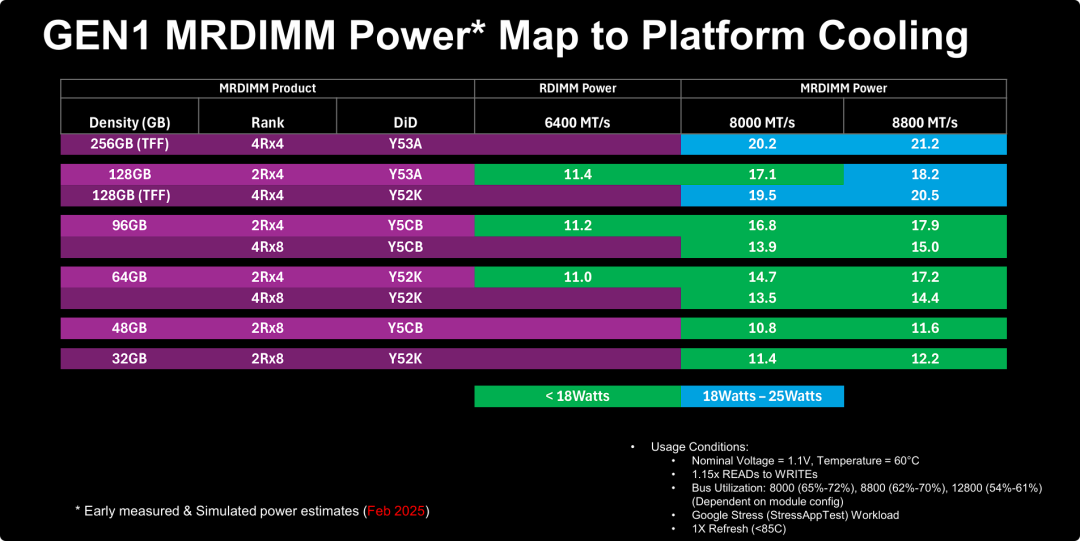
第一代 MRDIMM 内存功耗
第一代 MRDIMM 内存功耗
MRDIMM 的高性能是有代价的——显著增加的功耗要求系统散热设计必须升级。
- 功耗与性能的权衡 (Trade-off): MRDIMM 并没有打破物理定律。它通过多路复用芯片 (MDB) 和更高的速率实现了带宽飞跃,但也导致单条内存功耗从标准的 ~11W 激增至 ~18-21W。这意味着数据中心在部署 MRDIMM 时,必须重新计算机柜的供电预算。
- 散热设计的分水岭 (18W 阈值): 图表清晰地划定了一条“18W 警戒线”。
- 过去: 标准 RDIMM 都在线下的“绿色舒适区”,散热不是大问题。
- 现在: 想要享受 MRDIMM 8800 MT/s 的极致性能(尤其是 128GB 以上大容量),就必须跨入线上的“蓝色高压区”。这暗示了新一代服务器设计必须引入更强的散热方案(Platform Cooling)。
- 针对不同用户的策略:
- 对于追求极致性能的用户(如 AI 训练集群),必须接受 256GB @ 21.2W 的高功耗,并为此配备昂贵的散热系统。
- 对于主流用户,可能会选择 96GB 或 64GB 版本,或者降低运行频率到 8000 MT/s,以试图卡在 <18W 的绿色区域内,平衡性能与运维成本。
===
参考下表与DDR5同时期的CPU单路功耗,主板上按32个插槽满载的话,RDIMM 内存的功耗峰值在320w左右(接近1路CPU功耗),而RDIMM峰值接近640w。
代际 | 核心代号 | 支持内存 | 最高 TDP (单路) | 代表型号 | 备注 |
|---|---|---|---|---|---|
Xeon 6 (6900系列) | Granite Rapids-AP | DDR5 / MRDIMM | 500W | Xeon 6980P | PPT中出现的型号。这是目前功耗最高的Intel CPU之一,专为高性能计算设计。 |
5th Gen Xeon | Emerald Rapids | DDR5 | 385W | Xeon 8592+ | 相比上一代小幅提升,继续挖掘 DDR5 性能。 |
4th Gen Xeon | Sapphire Rapids | DDR5 | 350W | Xeon 8490H | Intel 首个支持 DDR5 的服务器平台,功耗门槛首次大幅提升至350W。 |
EPYC 9005 | Turin | DDR5 / MRDIMM | 500W | EPYC 9965 | |
EPYC 9004 | Genoa / Bergamo | DDR5 | 360W | EPYC 9654 |
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 在CXL协议日益成熟的当下,MRDIMM这类优化传统DDR通道带宽的技术,其长期战略价值是否会被CXL内存扩展方案所取代?
- Intel MLC测试为何能测出MRDIMM的真实带宽上限,而Gstress等工具却"测不准"?这是否意味着我们需要重新审视内存性能测试的方法论标准?
- 对于追求性能与功耗平衡的中小型数据中心,是选择MRDIMM的极致带宽,还是坚守标准DDR5的能效优势?
原文标题:Beyond bandwidth: MRDIMMs’edge in the data center revolution[1]
Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #DDR带宽提升
---【本文完】---
👇阅读原文,搜索🔍更多历史文章。

丰子恺-护生画集-众生
- https://files.futurememorystorage.com/proceedings/2025/20250807_DRAM-303-1_Potter.pdf ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号