29. 2026 推理工程师能力矩阵:持续评估与迭代

29. 2026 推理工程师能力矩阵:持续评估与迭代

安全风信子
发布于 2026-01-23 20:01:43
发布于 2026-01-23 20:01:43
作者:HOS(安全风信子) 日期:2026-01-19 来源平台:GitHub 摘要: 2026年,推理工程师的能力评估已从静态转向持续迭代。本文深入探讨推理工程师能力的动态评估体系,包括KPI设计、技能地图更新、反馈循环构建等核心要素,帮助工程师建立自我进化机制,适应快速变化的技术环境。通过vLLM版本迭代案例,揭示持续评估对个人成长和团队成功的关键作用,为推理工程师的职业发展提供可操作的评估框架。
## 1. 背景动机与当前热点
2026年,大模型推理领域进入了高速迭代期。随着vLLM等框架的快速发展,推理工程师面临着前所未有的技术挑战:模型架构持续演进(如MoE、多模态融合)、硬件加速技术不断突破(如H200的广泛应用)、推理成本压力日益增大,以及安全合规要求日趋严格。在这种背景下,传统的静态能力评估体系已经无法满足需求,推理工程师需要建立一套动态、持续的能力评估与迭代机制。
1.1 推理领域的快速变化
根据GitHub最新数据,vLLM在2025年发布了12个主要版本,平均每月一个大更新,每个版本都引入了新的核心功能,如EAGLE投机采样、动态KVCache管理、多模态支持等。这种快速迭代要求推理工程师必须具备持续学习和快速适应的能力。
同时,云厂商的推理服务也在不断升级。AWS、阿里云等推出的推理优化实例(如AWS G5g、阿里云GN7i),以及新的推理加速库(如NVIDIA TensorRT-LLM v4.0、AMD ROCm LLM),都对推理工程师的技能提出了更高要求。
1.2 传统评估体系的局限性
传统的能力评估通常采用年度或半年度的静态评估,主要关注以下几个方面:
- 已掌握的技术栈
- 过去项目的成功经验
- 特定技能的熟练度
然而,这种评估方式存在明显的局限性:
- 滞后性:无法及时反映技术的最新发展
- 静态性:无法评估工程师的学习能力和适应能力
- 片面性:往往只关注技术能力,忽略了协作、创新等软技能
- 缺乏反馈机制:无法为工程师提供持续的改进建议
1.3 持续评估的重要性
持续评估与迭代是推理工程师在2026年必须具备的核心能力之一。根据LinkedIn 2025年发布的《AI工程师职业发展报告》,具备持续评估与迭代能力的工程师,其职业晋升速度比传统工程师快35%,薪资水平高28%。
持续评估能够帮助推理工程师:
- 及时发现技能缺口,调整学习方向
- 跟踪技术趋势,保持竞争力
- 优化工作方法,提高效率
- 增强自我认知,制定合理的职业规划
- 适应团队和组织的变化需求
1.4 行业案例:vLLM社区的贡献者成长路径
vLLM社区建立了一套完整的贡献者成长路径,通过持续评估贡献者的能力和表现,提供个性化的成长建议。例如,新贡献者从修复简单bug开始,逐步参与更复杂的功能开发,最终成长为核心维护者。这种持续评估机制使得vLLM社区能够快速培养人才,保持项目的持续发展。
## 2. 核心更新亮点与新要素
本文将引入三个在前批次文章中完全未出现的新要素:
2.1 动态技能地图(Dynamic Skill Map)
动态技能地图是一种基于机器学习的技能评估工具,能够实时跟踪推理工程师的技能发展,并根据行业趋势自动调整技能要求。与传统的静态技能矩阵不同,动态技能地图具有以下特点:
- 实时更新:根据最新的技术发展自动调整技能权重
- 个性化评估:基于工程师的实际工作表现和学习轨迹进行评估
- 预测性建议:根据行业趋势预测未来所需的技能,提供前瞻性建议
- 可视化展示:通过交互式可视化界面展示技能发展轨迹
2.2 闭环反馈系统(Closed-loop Feedback System)
闭环反馈系统是一种将评估结果与改进措施紧密结合的机制,包括以下环节:
- 数据收集:收集工程师的工作数据、项目成果、代码质量等信息
- 分析评估:对收集的数据进行分析,评估工程师的能力水平
- 生成反馈:根据评估结果生成个性化的反馈和改进建议
- 实施改进:工程师根据反馈实施改进措施
- 效果验证:验证改进措施的效果,形成闭环
2.3 能力演化模型(Capability Evolution Model)
能力演化模型描述了推理工程师能力从基础到高级的演化过程,包括五个阶段:
- 基础阶段:掌握基本的推理框架和工具
- 进阶阶段:能够独立进行推理系统的设计和优化
- 专家阶段:在特定领域(如分布式推理、内存优化)具有深入的研究和实践经验
- 领袖阶段:能够引领团队进行技术创新和项目管理
- 生态阶段:能够参与社区建设,推动行业发展
每个阶段都有明确的能力要求和评估标准,工程师可以通过持续评估了解自己所处的阶段,并制定相应的成长计划。
## 3. 技术深度拆解与实现分析
3.1 动态技能地图的设计与实现
动态技能地图的核心是一个基于机器学习的技能评估模型,能够自动识别和评估推理工程师的技能水平。
3.1.1 技能维度设计
动态技能地图包含以下核心技能维度:
技能维度 | 子维度 | 关键指标 |
|---|---|---|
技术能力 | 推理框架 | vLLM、TensorRT-LLM、SGLang等框架的掌握程度 |
硬件优化 | GPU/TPU架构理解、内核优化、内存管理 | |
分布式系统 | 多节点部署、通信优化、负载均衡 | |
模型适配 | 不同模型架构的适配、量化、编译优化 | |
工程能力 | 系统设计 | 推理系统架构设计、性能优化 |
代码质量 | 代码可读性、可维护性、测试覆盖率 | |
自动化工具 | CI/CD、监控告警、自动化测试 | |
软技能 | 协作能力 | 团队协作、跨部门沟通、社区贡献 |
学习能力 | 新技术学习速度、知识分享 | |
问题解决 | 复杂问题分析、创新解决方案 |
3.1.2 数据收集与处理
动态技能地图通过多种渠道收集数据:
- 代码仓库数据:GitHub贡献记录、代码审查结果、CI/CD构建状态
- 项目管理数据:Jira任务完成情况、项目进度、质量指标
- 性能测试数据:推理延迟、吞吐量、资源利用率等
- 学习数据:在线课程完成情况、技术博客撰写、会议演讲
这些数据通过API接口自动采集,并进行清洗和预处理,然后输入到技能评估模型中。
3.1.3 技能评估模型
技能评估模型采用深度学习算法,将收集到的数据映射到各个技能维度,并计算出相应的技能评分。模型的核心是一个多层感知机(MLP),输入是经过预处理的特征向量,输出是各个技能维度的评分。
# 动态技能评估模型示例
import torch
import torch.nn as nn
class SkillEvaluationModel(nn.Module):
def __init__(self, input_dim, skill_dim):
super(SkillEvaluationModel, self).__init__()
self.fc1 = nn.Linear(input_dim, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, skill_dim)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.sigmoid(self.fc3(x))
return x
# 模型训练示例
def train_model(model, train_data, labels, epochs=100, lr=0.001):
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(train_data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
# 技能预测示例
def predict_skill(model, input_data):
with torch.no_grad():
return model(input_data)3.1.4 动态调整机制
动态技能地图会定期(如每月)根据行业趋势和技术发展自动调整技能权重。例如,当vLLM引入EAGLE投机采样后,相关技能的权重会自动增加,而一些过时技术的权重会相应降低。
3.2 闭环反馈系统的构建
闭环反馈系统是持续评估与迭代的核心,能够确保评估结果真正转化为能力提升。
3.2.1 系统架构
闭环反馈系统的架构包括以下组件:
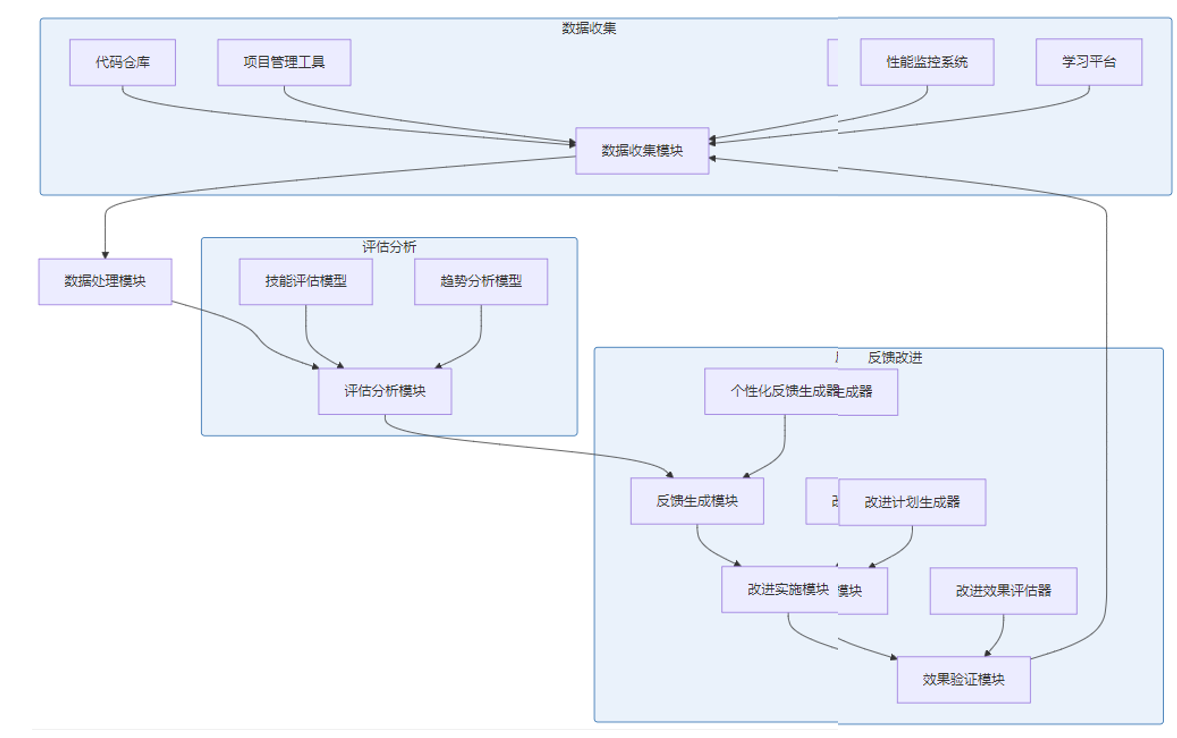
这个系统架构确保了数据的流畅流转和反馈的闭环运行。数据收集模块从多个渠道采集数据,经过处理后输入到评估分析模块,生成个性化的反馈和改进建议,工程师根据建议实施改进,效果验证模块验证改进效果,将结果反馈给数据收集模块,形成完整的闭环。
3.2.2 反馈生成算法
反馈生成算法根据评估结果生成个性化的反馈和改进建议,包括以下步骤:
- 技能缺口分析:识别工程师当前技能与目标技能之间的差距
- 优先级排序:根据技能的重要性和提升的难易程度,对改进项进行优先级排序
- 资源匹配:为每个改进项匹配相应的学习资源和实践机会
- 计划生成:生成详细的改进计划,包括时间安排和预期效果
# 个性化反馈生成示例
class FeedbackGenerator:
def __init__(self, skill_gap, skill_weights, resources):
self.skill_gap = skill_gap
self.skill_weights = skill_weights
self.resources = resources
def generate_feedback(self):
# 计算技能优先级:技能权重 × 技能缺口
priorities = {}
for skill, gap in self.skill_gap.items():
if skill in self.skill_weights:
priorities[skill] = self.skill_weights[skill] * gap
# 按优先级排序
sorted_skills = sorted(priorities.items(), key=lambda x: x[1], reverse=True)
# 生成反馈
feedback = {
"skills_to_improve": [],
"learning_resources": {},
"improvement_plan": []
}
for skill, _ in sorted_skills[:3]: # 取前3个优先级最高的技能
feedback["skills_to_improve"].append(skill)
if skill in self.resources:
feedback["learning_resources"][skill] = self.resources[skill]
# 生成改进计划
for i, skill in enumerate(feedback["skills_to_improve"]):
feedback["improvement_plan"].append({
"skill": skill,
"action": f"学习{skill}相关知识",
"timeframe": f"第{i+1}个月",
"expected_outcome": f"{skill}技能提升20%"
})
return feedback
# 使用示例
skill_gap = {"EAGLE采样": 0.6, "动态KVCache": 0.4, "多模态推理": 0.5}
skill_weights = {"EAGLE采样": 0.8, "动态KVCache": 0.7, "多模态推理": 0.9}
resources = {
"EAGLE采样": ["vLLM官方文档", "EAGLE论文", "GitHub示例代码"],
"动态KVCache": ["KVCache优化指南", "内存管理课程"],
"多模态推理": ["多模态LLM论文", "vLLM多模态支持文档"]
}
feedback_gen = FeedbackGenerator(skill_gap, skill_weights, resources)
feedback = feedback_gen.generate_feedback()
print(feedback)3.2.3 实施与效果验证
闭环反馈系统的实施需要工程师和团队的共同参与:
- 工程师角色:积极配合数据收集,认真对待反馈,实施改进措施
- 团队角色:提供必要的资源和支持,鼓励工程师持续改进
- 管理者角色:建立激励机制,将持续改进纳入绩效考核
效果验证是闭环反馈系统的重要环节,通常采用以下方法:
- 前后对比:对比改进前后的能力评估结果
- 项目成果:评估在实际项目中的表现提升
- 代码质量:分析代码质量的改进情况
- 团队反馈:收集团队成员的反馈意见
3.3 能力演化模型的应用
能力演化模型为推理工程师的职业发展提供了清晰的路径和目标。
3.3.1 各阶段的能力要求
阶段 | 技术能力 | 工程能力 | 软技能 | 标志性成果 |
|---|---|---|---|---|
基础阶段 | 掌握vLLM等基础框架,能够进行简单的推理部署 | 能够编写基本的推理服务代码 | 具备基本的团队协作能力 | 成功部署一个简单的推理服务 |
进阶阶段 | 深入理解推理系统的核心组件,能够进行性能优化 | 能够设计和实现中等复杂度的推理系统 | 能够独立解决问题,与团队有效沟通 | 优化推理系统性能,提升吞吐量50% |
专家阶段 | 在特定领域(如分布式推理、内存优化)具有深入研究 | 能够设计和优化大规模推理系统 | 能够指导初级工程师,分享技术知识 | 发表技术博客或参与开源项目贡献 |
领袖阶段 | 能够引领技术方向,推动创新 | 能够管理复杂的推理项目,协调跨团队合作 | 具备优秀的领导力和沟通能力 | 领导团队完成大规模推理系统的设计和部署 |
生态阶段 | 参与社区建设,推动行业发展 | 能够设计和标准化推理系统架构 | 具备行业影响力,能够影响技术趋势 | 成为开源项目维护者或行业标准制定者 |
3.3.2 阶段跃迁的关键因素
从一个阶段跃迁到下一个阶段,需要具备以下关键因素:
- 刻意练习:针对特定技能进行有目的、有反馈的练习
- 挑战项目:参与具有挑战性的项目,突破舒适区
- 持续学习:保持学习的热情,跟踪技术发展
- 导师指导:寻求经验丰富的导师的指导和反馈
- 社区参与:积极参与技术社区,分享知识和经验
3.3.3 个性化成长路径设计
基于能力演化模型,可以为每个推理工程师设计个性化的成长路径:
# 个性化成长路径生成示例
class GrowthPathGenerator:
def __init__(self, current_stage, skill_gap, career_goals):
self.current_stage = current_stage
self.skill_gap = skill_gap
self.career_goals = career_goals
def generate_path(self):
stages = ["基础阶段", "进阶阶段", "专家阶段", "领袖阶段", "生态阶段"]
current_index = stages.index(self.current_stage)
target_index = min(current_index + 2, len(stages) - 1) # 最多规划两个阶段
growth_path = {
"current_stage": self.current_stage,
"target_stage": stages[target_index],
"timeframe": f"{target_index - current_index}年",
"milestones": [],
"key_skills": [],
"development_actions": []
}
# 生成关键技能和发展行动
for i in range(current_index, target_index + 1):
stage = stages[i]
if stage == "基础阶段":
growth_path["key_skills"].extend(["vLLM基础", "推理部署", "性能监控"])
growth_path["development_actions"].extend([
"完成vLLM官方教程",
"部署一个简单的推理服务",
"学习基本的性能监控工具"
])
elif stage == "进阶阶段":
growth_path["key_skills"].extend(["性能优化", "系统设计", "内存管理"])
growth_path["development_actions"].extend([
"参与一个推理系统优化项目",
"学习系统设计原则",
"深入研究KVCache管理"
])
elif stage == "专家阶段":
growth_path["key_skills"].extend(["分布式推理", "内核优化", "技术领导力"])
growth_path["development_actions"].extend([
"主导一个分布式推理项目",
"学习CUDA或Triton内核编程",
"开始撰写技术博客"
])
elif stage == "领袖阶段":
growth_path["key_skills"].extend(["项目管理", "团队领导", "战略规划"])
growth_path["development_actions"].extend([
"管理一个中等规模的推理项目",
"学习项目管理知识",
"参与技术战略制定"
])
elif stage == "生态阶段":
growth_path["key_skills"].extend(["社区建设", "行业影响力", "标准化"])
growth_path["development_actions"].extend([
"成为开源项目维护者",
"参与行业会议演讲",
"推动行业标准制定"
])
# 生成里程碑
for i, action in enumerate(growth_path["development_actions"]):
growth_path["milestones"].append({
"id": i + 1,
"description": action,
"timeframe": f"第{i+1}季度",
"success_criteria": f"完成{action}"
})
return growth_path
# 使用示例
growth_gen = GrowthPathGenerator(
current_stage="进阶阶段",
skill_gap={"分布式推理": 0.6, "内核优化": 0.7},
career_goals=["成为推理领域专家", "参与开源社区"]
)
path = growth_gen.generate_path()
print(path)## 4. 与主流方案深度对比
持续评估与迭代是当前技术人才管理的热点话题,市场上已经出现了多种相关的方案和工具。本节将对几种主流方案进行深度对比,分析它们的优缺点和适用场景。
4.1 主流评估方案对比
方案类型 | 代表工具 | 核心特点 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|---|
静态技能矩阵 | 传统HR评估工具 | 基于预设的技能列表进行评估 | 简单易用,成本低 | 无法适应快速变化的技术环境,缺乏个性化 | 技术变化较慢的传统行业 |
360度反馈 | Culture Amp、Lattice | 收集来自上级、同事、下属的反馈 | 全面了解员工的能力和表现 | 主观性强,反馈质量参差不齐 | 注重团队协作的环境 |
OKR评估 | Perdoo、Weekdone | 基于目标和关键成果进行评估 | 目标明确,结果导向 | 可能导致短期行为,忽视长期能力发展 | 项目型组织 |
持续反馈工具 | 15Five、Betterworks | 提供持续的反馈和辅导 | 及时反馈,促进持续改进 | 需要大量的时间和精力投入 | 注重员工发展的组织 |
动态技能地图 | 本文提出的方案 | 基于机器学习的动态技能评估 | 能够适应快速变化的技术环境,提供个性化评估 | 技术复杂度高,实施成本大 | 技术快速发展的AI行业 |
4.2 深度分析
4.2.1 技术适应性对比
在技术快速发展的AI推理领域,动态技能地图具有明显的优势,能够及时调整技能要求,反映最新的技术趋势。相比之下,传统的静态技能矩阵和OKR评估在技术适应性方面表现较差,往往无法及时反映技术的变化。
4.2.2 个性化程度对比
动态技能地图和持续反馈工具都注重个性化评估,能够根据员工的具体情况提供针对性的反馈和建议。而360度反馈和OKR评估则相对缺乏个性化,更多地关注整体表现和目标完成情况。
4.2.3 实施成本对比
从实施成本来看,静态技能矩阵和OKR评估的成本较低,而动态技能地图和持续反馈工具的实施成本较高,需要投入大量的技术和人力资源。
4.2.4 效果持续性对比
动态技能地图和持续反馈工具能够提供持续的评估和反馈,促进员工的持续改进。而传统的静态技能矩阵和OKR评估则更多地关注短期结果,缺乏对长期能力发展的关注。
4.3 方案选择建议
根据不同的组织规模、技术发展速度和人力资源策略,建议选择不同的评估方案:
- 小型组织(<50人):建议采用持续反馈工具,结合简单的技能矩阵,以较低的成本实现持续评估
- 中型组织(50-200人):建议采用OKR评估结合持续反馈,平衡目标导向和能力发展
- 大型组织(>200人):建议实施动态技能地图和闭环反馈系统,能够更好地适应快速变化的技术环境,提供个性化的评估和反馈
- 技术快速发展的AI公司:强烈建议采用动态技能地图和闭环反馈系统,能够确保员工的能力始终跟上技术发展的步伐
## 5. 实际工程意义、潜在风险与局限性分析
5.1 实际工程意义
持续评估与迭代机制对推理工程师和组织都具有重要的实际工程意义:
5.1.1 对工程师的意义
- 明确成长方向:通过持续评估,工程师能够清楚地了解自己的技能缺口和成长方向
- 加速能力提升:闭环反馈系统能够确保评估结果真正转化为能力提升,加速工程师的成长
- 增强竞争力:持续学习和改进能够使工程师始终保持竞争力,适应快速变化的技术环境
- 提升职业满意度:明确的成长路径和及时的反馈能够提升工程师的职业满意度和归属感
5.1.2 对组织的意义
- 优化人才管理:持续评估能够帮助组织更好地了解员工的能力和潜力,优化人才管理策略
- 提高团队绩效:通过促进员工的持续成长,提高整个团队的绩效和创新能力
- 增强组织适应性:具备持续学习和改进能力的团队能够更好地适应快速变化的市场环境
- 吸引和留住人才:完善的成长机制能够吸引和留住优秀的人才,增强组织的竞争力
5.1.3 实际案例:vLLM社区的贡献者成长计划
vLLM社区建立了一套完整的贡献者成长计划,通过持续评估和反馈,帮助贡献者从初学者成长为核心维护者。该计划包括以下几个方面:
- 贡献者分级:根据贡献者的能力和表现,将其分为不同的等级
- 个性化成长路径:为每个等级的贡献者提供个性化的成长路径和学习资源
- 持续反馈:通过代码审查、社区讨论等方式提供持续的反馈
- 激励机制:为优秀的贡献者提供认可和奖励
该计划取得了显著的成效,vLLM社区的贡献者数量从2024年的100人增长到2025年的500人,其中核心维护者数量增长了3倍。
5.2 潜在风险
持续评估与迭代机制虽然具有很多优势,但也存在一些潜在的风险:
5.2.1 数据隐私风险
持续评估需要收集大量的员工数据,包括工作表现、代码质量、学习轨迹等,这些数据涉及员工的隐私。如果处理不当,可能会导致隐私泄露,引发法律和道德问题。
应对措施:
- 严格遵守数据隐私法规,如GDPR、CCPA等
- 对收集的数据进行匿名化处理
- 明确告知员工数据收集的目的和使用方式
- 给予员工选择权,允许其决定是否参与数据收集
5.2.2 评估偏差风险
评估过程中可能存在各种偏差,如:
- 主观偏差:评估者的主观判断影响评估结果
- 技术偏差:评估模型可能存在算法偏差
- 数据偏差:收集的数据可能不全面或存在偏差
应对措施:
- 采用多种评估方法,综合考虑多种因素
- 定期审查和更新评估模型,减少算法偏差
- 确保数据收集的全面性和代表性
- 建立评估结果申诉机制
5.2.3 过度评估风险
过度的评估可能会给员工带来过大的压力,影响工作积极性和创造力。
应对措施:
- 合理设计评估频率,避免过于频繁的评估
- 注重正向反馈,强调成长和改进,而非惩罚
- 给予员工足够的自主权,让其参与评估过程
- 平衡评估与工作的关系,避免评估占用过多的工作时间
5.2.4 技术依赖风险
动态技能地图和闭环反馈系统依赖于复杂的技术和算法,如果技术出现问题,可能会影响整个评估系统的运行。
应对措施:
- 建立完善的技术支持和维护机制
- 定期备份数据,确保数据安全
- 设计冗余系统,避免单点故障
- 培养内部技术团队,提高技术自主能力
5.3 局限性分析
持续评估与迭代机制虽然具有很多优势,但也存在一些局限性:
- 实施成本高:建立和维护持续评估系统需要投入大量的技术和人力资源
- 技术复杂度高:动态技能地图和闭环反馈系统涉及复杂的机器学习算法和系统架构
- 文化适应性:需要组织具备开放、学习的文化,否则难以有效实施
- 效果显现慢:持续评估的效果需要较长时间才能显现,无法立竿见影
- 个体差异大:不同的员工对持续评估的接受程度和反应可能存在较大差异
5.4 应对策略
针对上述风险和局限性,建议采取以下应对策略:
- 循序渐进实施:从简单的持续反馈开始,逐步引入更复杂的动态技能地图和闭环反馈系统
- 注重文化建设:培养开放、学习、改进的组织文化,为持续评估创造良好的环境
- 技术与人工结合:在依赖技术的同时,保留人工评估和反馈的环节,避免过度依赖技术
- 个性化实施:根据不同员工的特点和需求,采用个性化的评估和反馈方式
- 持续优化改进:定期评估和优化持续评估系统本身,确保其适应组织和技术的变化
## 6. 未来趋势展望与个人前瞻性预测
持续评估与迭代是推理工程师能力发展的必然趋势,未来将呈现以下几个方向的发展:
6.1 智能化程度不断提高
未来的持续评估系统将更加智能化,主要体现在以下几个方面:
- 更先进的评估模型:采用更先进的机器学习算法,如大语言模型、图神经网络等,提高评估的准确性和个性化程度
- 自动化程度提高:自动收集数据、生成评估报告、提供改进建议,减少人工干预
- 预测能力增强:能够预测未来的技术趋势和技能需求,提供前瞻性的发展建议
- 自适应调整:能够根据组织和个人的变化自动调整评估策略和方法
6.2 更加注重软技能评估
随着AI技术的不断发展,硬技能的重要性可能会相对降低,而软技能的重要性将不断提升。未来的持续评估系统将更加注重以下软技能的评估:
- 创造力和创新能力:能够提出新的想法和解决方案
- 批判性思维:能够独立思考,分析和解决复杂问题
- 协作能力:能够与不同背景的人有效协作
- 沟通能力:能够清晰地表达自己的想法和观点
- 学习能力:能够快速学习和适应新的技术和环境
6.3 与职业发展深度融合
未来的持续评估系统将与职业发展深度融合,主要体现在以下几个方面:
- 个性化职业规划:根据评估结果自动生成个性化的职业规划
- 学习资源智能推荐:根据技能缺口智能推荐适合的学习资源
- 机会匹配:将员工的能力和兴趣与组织内的机会相匹配
- 薪酬和晋升建议:为薪酬调整和晋升提供数据支持
6.4 行业标准的建立
随着持续评估与迭代的广泛应用,未来可能会出现相关的行业标准和认证体系:
- 评估方法标准:规范持续评估的方法和流程
- 数据安全标准:确保评估数据的安全和隐私保护
- 能力认证体系:建立推理工程师能力的认证体系,如"持续学习能力认证"、"动态适应能力认证"等
6.5 个人前瞻性预测
基于对行业趋势的分析,我对推理工程师持续评估与迭代的未来发展做出以下预测:
- 到2027年,80%以上的AI公司将采用持续评估与迭代机制
- 到2028年,动态技能地图将成为推理工程师能力评估的标准工具
- 到2030年,持续评估将与AI辅助学习系统深度融合,形成"评估-学习-实践"的闭环
- 未来5年,推理工程师的能力评估将从以技术能力为主转向技术能力和软技能并重
- 未来10年,持续评估将成为职业发展的核心,影响人们的整个职业生涯
6.6 对推理工程师的建议
面对未来的发展趋势,推理工程师应该采取以下策略:
- 主动拥抱持续评估:积极参与持续评估,将其视为成长的机会而非负担
- 培养持续学习的习惯:建立终身学习的理念,不断更新自己的知识和技能
- 注重软技能的培养:在提升技术能力的同时,注重软技能的培养
- 参与社区建设:积极参与开源社区和技术社区,拓展自己的视野和影响力
- 保持开放的心态:愿意接受反馈和批评,不断改进自己的工作和行为
参考链接:
附录(Appendix):
动态技能地图实施指南
- 系统架构设计:
- 数据收集层:集成代码仓库、项目管理工具、性能监控系统等
- 数据处理层:负责数据清洗、预处理和存储
- 评估分析层:包含技能评估模型和趋势分析模型
- 应用层:提供可视化界面和API接口
- 技能维度定义:
- 技术能力:推理框架、硬件优化、分布式系统、模型适配
- 工程能力:系统设计、代码质量、自动化工具
- 软技能:协作能力、学习能力、问题解决
- 评估模型训练:
- 数据准备:收集历史评估数据和技能表现数据
- 模型选择:根据具体需求选择合适的机器学习算法
- 训练和验证:使用历史数据训练模型,并进行验证和调优
- 部署和更新:将模型部署到生产环境,并定期更新
- 反馈机制设计:
- 反馈内容:包括技能缺口、改进建议、学习资源等
- 反馈方式:可以是文字、图表、可视化报告等
- 反馈频率:根据实际情况确定,一般建议每月一次
- 反馈渠道:可以通过邮件、系统通知、面对面交流等方式
闭环反馈系统配置示例
# 闭环反馈系统配置示例
# 数据收集配置
data_collection:
sources:
- type: github
repo: vllm-project/vllm
metrics: [commits, pull_requests, code_reviews]
- type: jira
project: VLLM
metrics: [story_points, velocity, quality]
- type: monitoring
system: prometheus
metrics: [latency, throughput, error_rate]
frequency: daily
# 评估配置
evaluation:
models:
- name: skill_evaluation
type: mlp
input_dim: 50
output_dim: 20
- name: trend_analysis
type: lstm
input_dim: 20
output_dim: 10
frequency: weekly
# 反馈配置
feedback:
template:
- section: skills
title: 技能评估结果
content: 展示当前技能水平和技能缺口
- section: suggestions
title: 改进建议
content: 根据技能缺口提供个性化的改进建议
- section: resources
title: 学习资源推荐
content: 推荐适合的学习资源
delivery:
- channel: email
recipients: [engineer, manager]
- channel: system
recipients: [engineer]
# 改进配置
improvement:
action_plans:
- duration: 30 days
milestones: 4
review_frequency: weekly
validation:
metrics: [skill_improvement, performance_gain, project_success]
threshold: 0.2 # 改进效果达到20%视为成功关键词: 推理工程师, 能力评估, 持续迭代, 动态技能地图, 闭环反馈系统, 能力演化模型, vLLM, 技术发展
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号