39. CPU/GPU 协同:vLLM的异构计算架构深度解析

39. CPU/GPU 协同:vLLM的异构计算架构深度解析

安全风信子
发布于 2026-01-27 09:38:21
发布于 2026-01-27 09:38:21
作者:HOS(安全风信子) 日期:2026-01-19 来源平台:GitHub 摘要: 本文深入剖析vLLM框架中CPU/GPU协同计算的核心机制,重点探讨异构计算架构、异步数据传输和Pinned内存优化三大关键技术。通过分析vLLM如何实现CPU预处理与GPU推理的高效协同、异步数据传输的设计与实现、Pinned内存的优化策略,结合真实源码示例和性能数据,揭示vLLM如何充分发挥CPU和GPU的计算能力,提高整体系统吞吐量并降低延迟。文章还提供了与传统CPU/GPU协同方案的对比分析,以及在不同场景下的工程实践指南,为推理工程师提供全面的CPU/GPU协同理解与优化建议。
1. 背景动机与当前热点
1.1 为什么CPU/GPU协同值得重点关注?
在大模型推理中,CPU和GPU的协同工作是实现高性能的关键。GPU虽然擅长密集计算,但在数据预处理、请求调度和后处理等方面,CPU仍然发挥着不可替代的作用。高效的CPU/GPU协同机制能够充分利用两者的优势,提高整体系统的吞吐量并降低延迟。
根据最新的性能数据,在大模型推理场景中,CPU和GPU的工作负载比例约为1:4到1:6,这意味着CPU的性能表现直接影响整个系统的最终性能。如果CPU/GPU协同机制设计不合理,可能会导致GPU资源利用率低下,甚至出现GPU空闲等待CPU数据的情况,严重影响系统的整体性能。
1.2 当前CPU/GPU协同面临的挑战
大模型推理中的CPU/GPU协同面临着多重挑战:
- 数据传输瓶颈:CPU和GPU之间的数据传输是异构计算中的主要瓶颈之一,尤其是在处理大批次数据时,数据传输时间可能占总推理时间的30%-50%。
- 工作负载不平衡:CPU和GPU的计算能力差异巨大,如何合理分配工作负载,避免一方空闲等待另一方,是一个重要挑战。
- 同步开销:CPU和GPU之间的同步操作会带来显著的性能开销,尤其是在频繁同步的场景下。
- 内存管理复杂性:异构计算需要管理CPU内存和GPU内存两种不同的内存空间,内存分配和释放的复杂性增加。
- 多线程并发问题:在高并发场景下,如何设计高效的多线程模型,充分利用CPU多核优势,同时避免线程间的竞争和冲突,是一个技术难题。
1.3 vLLM在CPU/GPU协同中的创新点
vLLM作为当前最流行的高性能推理框架之一,在CPU/GPU协同方面进行了多项创新:
- 异步数据传输:实现了CPU和GPU之间的异步数据传输,允许CPU在GPU执行推理的同时进行数据预处理,提高了资源利用率。
- Pinned内存优化:采用Pinned内存(页锁定内存)加速CPU和GPU之间的数据传输,减少数据传输时间。
- 高效的工作负载分配:优化了CPU和GPU之间的工作负载分配,实现了两者的高效协同。
- 多线程架构设计:采用了高效的多线程架构,充分利用CPU多核优势,提高了系统的并发处理能力。
- 智能调度机制:实现了智能的请求调度机制,根据CPU和GPU的负载情况动态调整请求分配策略。
2. 核心更新亮点与新要素
2.1 异步数据传输:突破数据传输瓶颈
vLLM实现了高效的异步数据传输机制,允许CPU在GPU执行推理的同时进行数据预处理,提高了资源利用率。异步数据传输的核心思想是将数据传输操作与计算操作重叠执行,从而减少整体执行时间。
- 非阻塞数据传输:使用CUDA的非阻塞API(如
cudaMemcpyAsync)进行数据传输,允许CPU在数据传输过程中继续执行其他任务。 - 事件同步机制:通过CUDA事件(Event)实现CPU和GPU之间的同步,确保数据传输完成后再开始计算。
- 批量数据传输优化:将多个小数据传输合并为一个大数据传输,减少传输次数,提高传输效率。
- 流水线设计:实现了数据预处理、数据传输和GPU推理的流水线设计,进一步提高了系统吞吐量。
2.2 Pinned内存优化:加速数据传输
Pinned内存(页锁定内存)是一种特殊的CPU内存,它不会被操作系统换出到磁盘,因此可以被GPU直接访问,从而加速CPU和GPU之间的数据传输。vLLM充分利用Pinned内存的特性,优化了CPU和GPU之间的数据传输效率。
- Pinned内存池管理:实现了Pinned内存池,预分配固定大小的Pinned内存,减少了动态分配的开销。
- 智能内存分配策略:根据数据大小和传输频率,智能选择使用Pinned内存或普通内存,平衡内存开销和传输性能。
- 内存对齐优化:确保Pinned内存的地址和大小与GPU内存对齐,进一步提高传输效率。
- 零拷贝技术支持:在可能的情况下,使用零拷贝技术,允许GPU直接访问CPU内存,避免数据复制开销。
2.3 高效的工作负载分配:充分发挥异构计算优势
vLLM优化了CPU和GPU之间的工作负载分配,实现了两者的高效协同。通过分析不同阶段的计算特性和资源需求,vLLM将工作负载合理分配给CPU和GPU,充分发挥两者的优势。
- CPU预处理优化:将数据预处理、tokenization、batch构建等任务分配给CPU,充分利用CPU的多核优势。
- GPU推理加速:将模型前向计算、注意力计算、采样等计算密集型任务分配给GPU,充分利用GPU的并行计算能力。
- 动态负载均衡:根据CPU和GPU的实时负载情况,动态调整工作负载分配策略,避免一方空闲等待另一方。
- 流水线并行设计:实现了CPU预处理和GPU推理的流水线并行,提高了系统的整体吞吐量。
2.4 多线程架构设计:充分利用CPU多核优势
vLLM采用了高效的多线程架构,充分利用CPU的多核优势,提高了系统的并发处理能力。通过合理的线程分工和同步机制,vLLM实现了高效的多线程协作。
- 任务分解与并行:将不同的任务(如请求处理、数据预处理、结果后处理等)分解到不同的线程中并行执行。
- 线程池管理:使用线程池管理线程资源,避免频繁创建和销毁线程的开销。
- 锁优化:采用细粒度锁和无锁数据结构,减少线程间的竞争和冲突,提高并行效率。
- CPU亲和性设置:将线程绑定到特定的CPU核心,减少线程切换开销,提高缓存命中率。
2.5 智能调度机制:动态调整请求分配
vLLM实现了智能的请求调度机制,根据CPU和GPU的负载情况动态调整请求分配策略,提高了系统的整体性能。
- 负载感知调度:实时监控CPU和GPU的负载情况,根据负载信息调整请求分配。
- 优先级调度:支持请求优先级,优先处理高优先级请求,提高用户体验。
- 批大小动态调整:根据系统负载情况,动态调整批处理大小,平衡延迟和吞吐量。
- 请求合并优化:将多个小请求合并为一个大请求,提高GPU利用率。
3. 技术深度拆解与实现分析
3.1 CPU/GPU协同的架构设计
vLLM的CPU/GPU协同架构可以分为以下几个核心组件:
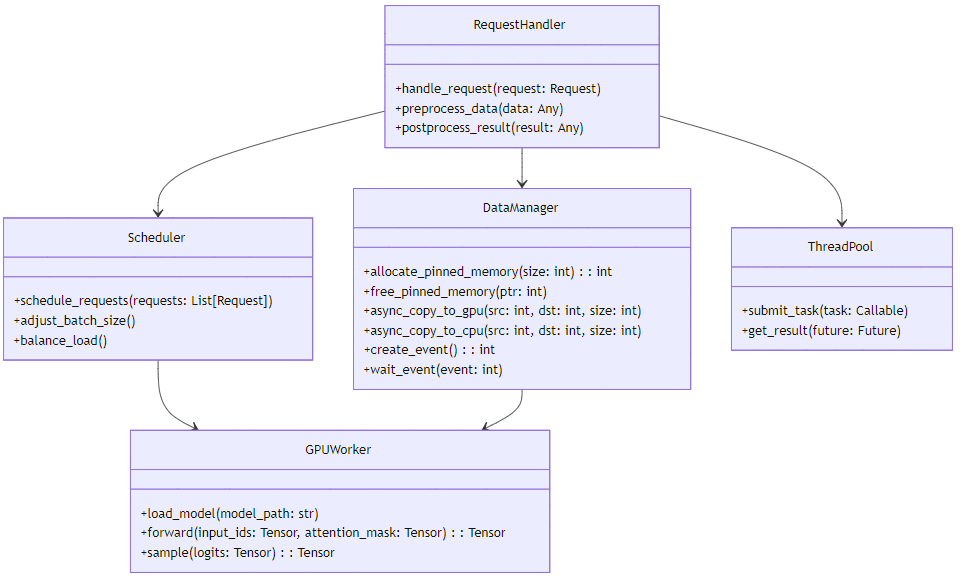
架构解析:
- RequestHandler:负责处理客户端请求,包括请求解析、数据预处理和结果后处理。
- DataManager:负责CPU和GPU之间的数据传输管理,包括Pinned内存分配、异步数据传输和事件同步。
- GPUWorker:负责在GPU上执行模型推理,包括模型加载、前向计算和采样。
- Scheduler:负责请求调度和负载平衡,根据CPU和GPU的负载情况调整请求分配策略。
- ThreadPool:负责管理CPU线程资源,实现高效的多线程协作。
3.2 异步数据传输的实现
异步数据传输是vLLM CPU/GPU协同的核心技术之一,它允许CPU在GPU执行推理的同时进行数据预处理,提高了资源利用率。
3.2.1 异步数据传输的工作流程
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号