突破轻量检测瓶颈:为YOLO注入增强特征融合与优化感受野的新动力
原创
突破轻量检测瓶颈:为YOLO注入增强特征融合与优化感受野的新动力
原创
AI小怪兽
发布于 2026-02-10 12:48:23
发布于 2026-02-10 12:48:23
本文的核心贡献可归纳为以下四点:
1)提出HP-CSE模块:设计了一种混合池化卷积压缩激励模块,通过结合最大池化与平均池化,并利用1x1卷积替代全连接层,以极低的计算成本实现了更精细的多尺度通道注意力,有效提升了特征融合的质量。
2)提出D2S-RFB模块:构建了一种深度双级感受野块,通过采用深度可分离卷积和两级膨胀卷积结构,在显著扩大模型感受野以捕获更多上下文信息的同时,保持了模块的轻量化和计算高效性。
3)提供通用集成方法论:提出了一种将上述模块无缝集成到现有轻量级目标检测器(如YOLOv7-tiny至YOLOv12-n)骨干网络与颈部的方法,证明了其跨架构的通用性与即插即用特性。
4)实现显著性能提升:经验证,集成此双模块的模型在MS COCO等基准数据集上实现了平均精度(mAP)最高达4%的显著提升,同时在NVIDIA Jetson Nano等边缘设备上仍能维持实时推理速度,有效平衡了精度与效率。
博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
- YOLO算法结构性创新:于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
- 技术生态建设与知识传播:独立运营 “计算机视觉大作战” 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
- 荣获腾讯云年度影响力作者与创作之星奖项,内容质量与专业性获行业权威平台认证。
- 全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
- 具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 “让每一行代码都有温度” 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
原理介绍

论文:https://www.sciencedirect.com/science/article/pii/S0925231226001256
摘要:在使用416像素输入图像分辨率的情况下,对五种最新的"你只看一次"(YOLO)模型纳米架构进行测试,其平均性能提升仅为0.3%,其中最大提升出现在YOLOv12-n与YOLOv11-n之间,达到0.8%。实际应用通常需要在边缘设备上实现实时推理,因此提升轻量级目标检测器的精度既尤为困难又至关重要。本文展示了如何通过高效的特征融合与感受野扩展来实现这一目标。我们提出了两个模块,在计算开销较小的前提下,将平均精度均值(mAP)提升最高达4%。第一个模块名为混合池化卷积压缩激励模块(HP-CSE),用于增强特征间的通道关联性;第二个模块名为深度双级感受野模块(D2S-RFB),用于扩大感受野范围。我们提出了一种将这两个模块集成到轻量级目标检测器架构中的方法,并通过将其融入YOLO系列最新的六种模型中,验证了其跨架构的通用性。我们在MS COCO数据集上训练这些模型,并在NVIDIA Jetson Nano上评估其实时性能。例如,将HP-CSE和D2S-RFB应用于YOLOv7-tiny和YOLOv12-n时,mAP分别提升了3.6%和1.7%,同时在NVIDIA Jetson Nano上仍能达到每秒8-9帧的处理速度。
核心代码如下:
import math
from copy import copy
from pathlib import Path
import numpy as np
import pandas as pd
import requests
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.ops import DeformConv2d
from PIL import Image
from torch.cuda import amp
from utils.datasets import letterbox
from utils.general import non_max_suppression, make_divisible, scale_coords, increment_path, xyxy2xywh
from utils.plots import color_list, plot_one_box
from utils.torch_utils import time_synchronized
class ST2CSPA(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(ST2CSPA, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32
self.m = SwinTransformer2Block(c_, c_, num_heads, n)
#self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.m(self.cv1(x))
y2 = self.cv2(x)
return self.cv3(torch.cat((y1, y2), dim=1))
class ST2CSPB(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(ST2CSPB, self).__init__()
c_ = int(c2) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32
self.m = SwinTransformer2Block(c_, c_, num_heads, n)
#self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
x1 = self.cv1(x)
y1 = self.m(x1)
y2 = self.cv2(x1)
return self.cv3(torch.cat((y1, y2), dim=1))
class ST2CSPC(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(ST2CSPC, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 1, 1)
self.cv4 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32
self.m = SwinTransformer2Block(c_, c_, num_heads, n)
#self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(torch.cat((y1, y2), dim=1))
##### end of swin transformer v2 #####
#SE_original
class SE_Block(nn.Module):
"credits: https://github.com/moskomule/senet.pytorch/blob/master/senet/se_module.py#L4"
def __init__(self, c, r=16):
super().__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Linear(c, c // r, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c // r, c, bias=False),
nn.Sigmoid()
)
def forward(self, x):
bs, c, _, _ = x.shape
y = self.squeeze(x).view(bs, c)
y = self.excitation(y).view(bs, c, 1, 1)
return x * y.expand_as(x)
#SE_ceymo from https://ieeexplore.ieee.org/abstract/document/10398733
class SEv2_Block(nn.Module):
def __init__(self, c, r=16):
super().__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Linear(c, c // r, bias=False),
nn.Mish(inplace=True),
nn.Linear(c // r, c, bias=False),
nn.Sigmoid()
)
def forward(self, x):
bs, c, _, _ = x.shape
y = self.squeeze(x).view(bs, c)
y = self.excitation(y).view(bs, c, 1, 1)
return x * y.expand_as(x)
#CSE from https://github.com/dbacea/ecf-yolov7-tiny
class CSE(nn.Module):
def __init__(self, c, r=16):
super().__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
c_o = c // r
self.excitation = nn.Sequential(
nn.Conv1d(c, c_o, 1, 1, 0, 1, 1, False),
nn.Mish(),
nn.Conv1d(c_o, c, 1, 1, 0, 1, 1, False),
nn.Sigmoid()
)
self.conv = Conv(c, c, 1, 1, None, 1, nn.Mish())
def forward(self, x):
bs, c, _, _ = x.shape
y = self.squeeze(x).view(bs, c)
y = torch.unsqueeze(y, 2)
y = self.excitation(y).view(bs, c, 1, 1)
y = x * y.expand_as(x)
y = self.conv(y)
return y
class ConvDilated(nn.Module):
# dilated convolution
def __init__(self, c1, c2, k=1, s=1, p=None, d=1, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, dilation, groups
super(ConvDilated, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), dilation=d, groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
#CBAM from https://github.com/Peachypie98/CBAM
class SAM(nn.Module):
def __init__(self, bias=False):
super(SAM, self).__init__()
self.bias = bias
self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3, dilation=1, bias=self.bias)
def forward(self, x):
max = torch.max(x,1)[0].unsqueeze(1)
avg = torch.mean(x,1).unsqueeze(1)
concat = torch.cat((max,avg), dim=1)
output = self.conv(concat)
output = F.sigmoid(output) * x
return output
#CBAM from https://github.com/Peachypie98/CBAM
class CAM(nn.Module):
def __init__(self, channels, r):
super(CAM, self).__init__()
self.channels = channels
self.r = r
self.linear = nn.Sequential(
nn.Linear(in_features=self.channels, out_features=self.channels//self.r, bias=True),
nn.ReLU(inplace=True),
nn.Linear(in_features=self.channels//self.r, out_features=self.channels, bias=True))
def forward(self, x):
max = F.adaptive_max_pool2d(x, output_size=1)
avg = F.adaptive_avg_pool2d(x, output_size=1)
b, c, _, _ = x.size()
linear_max = self.linear(max.view(b,c)).view(b, c, 1, 1)
linear_avg = self.linear(avg.view(b,c)).view(b, c, 1, 1)
output = linear_max + linear_avg
output = F.sigmoid(output) * x
return output
#CBAM from https://github.com/Peachypie98/CBAM
class CBAM(nn.Module):
def __init__(self, channels, r):
super(CBAM, self).__init__()
self.channels = channels
self.r = r
self.sam = SAM(bias=False)
self.cam = CAM(channels=self.channels, r=self.r)
def forward(self, x):
output = self.cam(x)
output = self.sam(output)
return output + x
#only needed for compatibility reasons with already trained models (see the weight files included in the repo), this block is the same as the HP-CSE.
class CSE_CAMv1(nn.Module):
def __init__(self, c, r):
super(CSE_CAMv1, self).__init__()
c_o = c // r
self.maxsqueeze = nn.AdaptiveMaxPool2d(1)
self.avgsqueeze = nn.AdaptiveAvgPool2d(1)
self.conv = Conv(c, c, 1, 1, None, 1, nn.Mish())
self.linear = nn.Sequential(
nn.Conv1d(c, c_o, 1, 1, 0, 1, 1, False),
nn.Mish(),
nn.Conv1d(c_o, c, 1, 1, 0, 1, 1, False))
def forward(self, x):
b, c, _, _ = x.size()
max = self.maxsqueeze(x).view(b,c)
avg = self.avgsqueeze(x).view(b,c)
max = torch.unsqueeze(max, 2)
avg = torch.unsqueeze(avg, 2)
linear_max = self.linear(max).view(b, c, 1, 1)
linear_avg = self.linear(avg).view(b, c, 1, 1)
output = linear_max + linear_avg
output = F.sigmoid(output) * x
output = self.conv(output)
return output
class HP-CSE(nn.Module):
def __init__(self, c, r):
super(HP-CSE, self).__init__()
c_o = c // r
self.maxsqueeze = nn.AdaptiveMaxPool2d(1)
self.avgsqueeze = nn.AdaptiveAvgPool2d(1)
self.conv = Conv(c, c, 1, 1, None, 1, nn.Mish())
self.linear = nn.Sequential(
nn.Conv1d(c, c_o, 1, 1, 0, 1, 1, False),
nn.Mish(),
nn.Conv1d(c_o, c, 1, 1, 0, 1, 1, False))
def forward(self, x):
b, c, _, _ = x.size()
max = self.maxsqueeze(x).view(b,c)
avg = self.avgsqueeze(x).view(b,c)
max = torch.unsqueeze(max, 2)
avg = torch.unsqueeze(avg, 2)
linear_max = self.linear(max).view(b, c, 1, 1)
linear_avg = self.linear(avg).view(b, c, 1, 1)
output = linear_max + linear_avg
output = F.sigmoid(output) * x
output = self.conv(output)
return output
class DepthwiseSeparableConv(nn.Module):
def __init__(self, nin, kernels_per_layer, nout, act=True):
super(DepthwiseSeparableConv, self).__init__()
self.depthwise = nn.Conv2d(nin, nin * kernels_per_layer, kernel_size=3, padding=1, groups=nin)
self.pointwise = nn.Conv2d(nin * kernels_per_layer, nout, kernel_size=1)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
out = self.depthwise(x)
out = self.pointwise(out)
return self.act(out)
class DepthwiseSeparableConvBN(nn.Module):
def __init__(self, nin, kernels_per_layer, nout, act=True):
super(DepthwiseSeparableConvBN, self).__init__()
self.depthwise = nn.Conv2d(nin, nin * kernels_per_layer, kernel_size=3, padding=1, groups=nin)
self.pointwise = nn.Conv2d(nin * kernels_per_layer, nout, kernel_size=1)
self.bn = nn.BatchNorm2d(nout)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
out = self.depthwise(x)
out = self.pointwise(out)
return self.act(self.bn(out))
def fuseforward(self, x):
out = self.depthwise(x)
out = self.pointwise(out)
return self.act(out)
class DepthwiseSeparableDilatedConvBN(nn.Module):
def __init__(self, nin, kernels_per_layer, nout, kernel_size=3, p=None, d=1, act=True):
super(DepthwiseSeparableDilatedConvBN, self).__init__()
self.depthwise = nn.Conv2d(nin, nin * kernels_per_layer, kernel_size=kernel_size, padding=autopad(kernel_size, p), dilation=d, groups=nin)
self.pointwise = nn.Conv2d(nin * kernels_per_layer, nout, kernel_size=1)
self.bn = nn.BatchNorm2d(nout)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
out = self.depthwise(x)
out = self.pointwise(out)
return self.act(self.bn(out))
def fuseforward(self, x):
out = self.depthwise(x)
out = self.pointwise(out)
return self.act(out)1 引言
实时目标检测是计算机视觉领域的研究焦点,旨在低延迟下精确识别并定位图像或视频流中的物体。尽管已有算法在此问题上取得了显著进展,但在边缘设备上实现准确的实时检测仍面临挑战。尽管架构有重大进步,但在最新的最先进(SOTA)模型中,轻量级目标检测器的检测性能仅得到边际改善。在416输入图像分辨率下,五种最新的YOLO模型纳米架构之间的平均性能提升为0.3%,最大提升(YOLOv12-n [1] 与 YOLOv11-n [2] 之间)为0.8%,如表1所示。
我们为增强特征融合和优化感受野而提出的两项架构改进,适用于轻量级目标检测器,可使其检测性能显著提高,同时在边缘设备上仍能实现实时检测性能。
首个"你只看一次"(YOLO)算法[7]的创新方法是实时目标检测研究的一个关键点。该方法开创了基于深度学习的模型路径,即单次处理整幅图像来检测物体及其位置。虽然YOLO已有超过十个版本[1–3,5–18],但轻量级YOLO模型的检测性能仍落后于较大模型。典型的YOLO检测流程在第一个检测阶段处理特征提取、边界框预测和置信度计算,而在第二阶段则可能使用非极大值抑制(NMS)等技术过滤冗余或重叠的检测。大多数研究都集中在改进检测的第一阶段(如本文工作),但第二阶段最近也受到越来越多的关注[1,2,6]。
众所周知,模型架构的设计对检测性能和推理速度都起着至关重要的作用。已有多种方法被提出来改进骨干网络的特征提取能力。尽管在这些主题上取得了显著进展,但仔细观察其效率和检测性能会发现YOLO模型内部仍存在计算冗余。以计算高效的方式扩大模型的感受野以及增加特征的异质性是前景广阔的研究方向。
本工作中,我们提出了两个计算高效的模块,分别改进轻量级目标检测器的骨干网络和颈部网络。对于颈部,我们展示了如何改进特征融合策略以及如何扩展多尺度特征融合。对于骨干网络,我们提出了一种轻量级方法来扩展架构首个卷积层的感受野。我们提出了一种将这两个模块插入轻量级目标检测器架构的方法,并通过将其应用于六个SOTA轻量级目标检测器(YOLOv7-tiny [14]、YOLOv8-n [3]、YOLOv9-t [5]、YOLOv10-n [6]、YOLOv11-n [2] 和 YOLOv12-n [1])来测试所提模块的性能。我们在市场上最具成本效益的GPU之一——NVIDIA Jetson Nano上演示了实时检测性能。我们通过在六个SOTA轻量级目标检测器上进行消融研究,证明添加HP-CSE和D2S-RFB比单纯增加模型容量更能提升检测精度。我们通过在Pascal VOC上评估在MS COCO上训练的模型,展示了其泛化能力。我们还系统性地评估并量化了我们的模型在不同遮挡水平下的检测性能。
本文将要使用的符号如表2所示。
我们的主要贡献如下:
- 我们引入了混合池化卷积压缩激励(HP-CSE)模块,它以最小的额外计算成本提升了多分辨率特征融合的能力。
- 我们提出了深度双级感受野模块(D2S-RFB),这是一个高效、低计算成本的模块,可扩大骨干网络的特征感受野和上下文信息。
- 我们引入了一种将这两个模块集成到轻量级目标检测器架构中的方法。我们通过将其集成到最佳的SOTA轻量级检测器中并带来明显的性能提升,证明了所提两个模块的通用性。将此方法应用于YOLOv7-tiny,使其在保持实时推理时间的同时,在416输入图像分辨率的轻量级目标检测器中达到SOTA检测性能。
本文组织结构如下。我们首先介绍关于实时目标检测器、特征融合和感受野的相关工作。第3节,介绍我们提出的模块、将其插入最新SOTA轻量级目标检测器的集成方法,以及应用于YOLOv7-tiny和YOLOv12-n的实际示例。第4节,分享我们的实验结果,主要关注指标为平均精度均值(mAP)、架构参数量、十亿浮点运算数(BFLOPS)和每秒帧数(FPS)。我们为每个模块进行了消融研究,将其引入六个SOTA轻量级目标检测器,将性能提升与简单扩展模型容量可能带来的提升进行比较,并将改进后的模型与已发表工作中的其他轻量级目标检测器进行比较。我们通过在Pascal VOC上评估在MS COCO上训练的改进模型,测试了其泛化能力。我们系统性地评估并量化了改进模型在不同遮挡水平下的检测性能。第5节,陈述我们研究工作的结论。
2 相关工作
本节首先介绍基于深度学习的2D图像SOTA实时目标检测(表3),随后是关于深度神经网络特征融合和感受野的相关研究。
2.1 实时目标检测
实时目标检测是最重要的计算机视觉任务之一,涉及以低计算成本进行物体识别与定位。基于深度学习的目标检测器已取得最佳检测性能,并吸引了最多的研究兴趣[1,2,6–11,14,17,19,23,24,26–30]。两阶段检测器将检测任务分为区域提议部分以及边界框确定和分类部分。两阶段检测器,如Fast-RCNN [26]、Faster-RCNN [27] 和 Mask-RCNN [28],通常不适合部署在边缘设备上,但能实现更精确的检测。与它们不同,单阶段检测器在速度和精度之间取得了良好平衡。这些模型在单个步骤中执行整个检测过程:感兴趣区域提议识别,以及边界框生成和分类。SSD [19]展示了一种有效的网络架构,通过将边界框输出空间离散化为具有多个纵横比和尺度的参考框集合,能够检测多尺度物体。RetinaNet [22]提出了焦点损失以改进类别不平衡问题。EfficientDet [23]利用了跨尺度连接和加权特征融合,并开发了一种复合缩放方法来获得不同尺寸的模型。MobileDets [24]表明,当常规卷积放置在正确位置时,其性能可以优于深度可分离倒残差结构。YOLO系列的单阶段实时模型可能是最受欢迎的[1–3,5–17]。
从最早的YOLO模型开始[7,8,10],典型架构由三部分组成:骨干网络、颈部网络和检测头。YOLOv4 [9]在骨干网络中引入了首次重大改变,用跨阶段局部网络(CSPNet)[31]替换了Darknet [10],并提出了改进的数据增强策略和增强的路径聚合网络(PAN)。Mini-YOLOv4-tiny [15]通过将激活函数切换为Mish [32]、引入轻量级的Mini跨阶段局部金字塔池化(MCSP-SPP)模块,并使用自定义策略来缩减卷积层的宽度,从而更新了YOLOv4-tiny架构。YOLOv6 [13]对网络颈部提出了一些更新,主要变化包括引入双向拼接(BiC)、简化的跨阶段局部空间金字塔池化-快速版(SimCSPSPPF),以及使用锚框辅助训练和自蒸馏策略。YOLOv7 [14]引入了"免费午餐袋"方法,有助于在推理时无需额外成本的情况下提高检测精度。此外,它通过将主要构建块切换为扩展高效层聚合网络(E-ELAN)来改变网络骨干。YOLOv8 [3]提出了轻量级的全连接跨阶段局部(C2f)模块以改进特征提取和融合。GOLD-YOLO [25]提出了一种改进多尺度特征融合的机制,他们称之为"收集与分发"(GD)。
YOLOv9 [5]引入了广义高效层聚合网络(GELAN),这是一种允许在骨干网络中更灵活地交换主要构建块的方法,并引入了可编程梯度信息(PGI)来增强训练过程。YOLOv10 [6]通过双重分配引入了无NMS(NMS-free)训练、轻量级分类头,并使用大核卷积来改进检测性能。ECF-YOLOv7-tiny [17]提出了卷积压缩激励(CSE)模块以改进架构颈部的特征融合,以及跨阶段局部上下文增强模块(CSP-CAM)以增大YOLOv7-tiny骨干网络的感受野。YOLOv11 [2]在网络的骨干和颈部都引入了计算高效的C3k2模块,该模块使用两个较小的卷积代替单个大卷积,同时比CSP瓶颈结构更紧凑。他们还引入了带空间注意力的跨阶段局部(C2PSA)模块,利用空间注意力使模型能更好地关注图像中的重要区域。YOLOv12 [1]提出了一个以注意力为中心的YOLO框架,能够在保持基于卷积神经网络(CNN)模型速度的同时提高检测性能。他们的提议依赖于区域注意力和残差高效层聚合网络(R-ELAN)以改进优化,以及FlashAttention [33,34]以实现更快的内存访问。尽管上述方法有助于提高检测性能,但其效率和效果仍有待完善。
与此同时,一种新的研究范式侧重于通过仿生网络架构实现超低功耗。其中一个例子是SU-YOLO [35],它为水下检测任务引入了脉冲神经网络(SNN)。该方法使用事件驱动框架和创新模块(如SpikeDenoiser和分离批量归一化(SeBN))来在嘈杂环境中实现高能效和鲁棒性。他们的方法主要针对特定领域应用和神经形态硬件进行优化。相比之下,我们在本文中提出的模块在传统CNN框架内运行,优先考虑最大检测精度和轻量化设计,以处理高方差、通用目的的数据集和任务。通过利用标准浮点运算,我们提出的模块对于主流边缘CPU和GPU上的通用目标检测部署仍然具有高度竞争力,填补了不同于高效率脉冲模型的操作利基。在本文中,我们探索了可添加到YOLO架构颈部和骨干网络的额外轻量级模块,以改进特征融合和特征上下文。
2.2 特征融合
对于目标检测,在大多数情况下,特征融合的概念指的是融合模型架构中来自不同深度的多尺度特征。这种融合有助于三个方面:提高检测性能、缓解梯度消失问题以及保留较小物体信息。特征金字塔网络(FPN)[36]是最早提出将更高层次的语义特征与较低层次特征合并的目标检测方法之一。神经架构搜索特征金字塔网络(NAS-FPN)[37]是在神经架构搜索中开发的一个模块,用于寻找融合自上而下和自下而上特征图的最佳方式。AugFPN [38]提出在融合中间层和顶层之间的语义信息时使用一致的监督。EfficientDet [23]提出学习每个特征的权重可能是有益的,因为不同的金字塔层可能对融合输出的贡献不同。压缩激励(SE)模块在SENet [39]中被引入,其中使用通道描述符提取全局信息,然后用于生成重新缩放初始输入图的每通道权重。卷积块注意力模块(CBAM)[40]是一个高效模块,在通道和空间维度上计算注意力图。空间注意力图通过使用大核卷积层获得,而对于通道注意力图,他们同时使用平均池化和最大池化,随后是一个全连接层。SE-YOLOv7-tiny [16]提出为来自不同金字塔层的拼接特征图学习每通道权重。CSE [17]将压缩激励(SE)中的所有全连接层替换为逐点卷积层,同时在输入重新缩放后添加了一个逐点卷积-批量归一化-Mish(CBM)块。C2PSA [2]在YOLOv11架构中引入了空间注意力的使用,通过对特征进行空间池化,提高了对不同尺寸和位置物体的检测精度。YOLOv12 [1]将区域注意力(A2模块)引入了YOLO系列模型。他们展示了通过将特征图等分为若干垂直和水平区域,可以避免计算密集型操作。他们还引入了R-ELAN,以帮助解决注意力机制引入的优化挑战。他们提出使用FlashAttention [33,34]来改善内存访问瓶颈。
PKINet [41]引入了上下文锚点注意力(CAA)模块。CAA通过捕获长程依赖关系来解决航拍图像中多样背景上下文的挑战。它通过在全局平均池化后采用一维条形卷积来实现这一点。条形卷积使网络能够建模中心物体与远处像素之间的空间关系,有效地将物体锚定在其全局环境中。
我们的模块设计方法侧重于通道级重新校准。我们做出此选择是因为在自然场景(例如MS COCO [4])中,物体通常与背景不同,使得特征区分(通道注意力)比长程空间上下文聚合(空间注意力)更为关键。此外,基于压缩激励(SE)的通道注意力模块增加的延迟可以忽略不计,对轻量级目标检测器特别有用,而像PKINet [41]中的CAA这样的方法可能会给轻量级目标检测器带来显著额外的计算成本。
在本工作中,我们设计了一个新模块HP-CSE,作为卷积压缩激励(CSE)[17]和[40]中通道注意力模块的混合体,以改进特征融合。
2.3 感受野
对于卷积层,感受野指的是输入层中对最终输出元素有贡献的元素区域。这种机制影响模型学习长距离空间特征关系的能力。感受野块(RFB)[42]引入了融合膨胀卷积输出以及逆高斯权重初始化的思想。受人类视觉机制启发的RFB模块首次应用于[43]中的目标检测网络。跨阶段局部感受野块(CSP-RFB)[44]为移动设备提出了一种重新设计的轻量级RFB块,其中主要使用逐点卷积,仅使用两个膨胀卷积。上下文增强模块(CAM)[45]使用三个膨胀卷积,比CSP-RFB [44]更紧凑。该块被添加到YOLOv5的颈部以改善特征的上下文信息。
YOLOv10 [6]使用大核深度可分离卷积作为扩大感受野的有效方法,但仅限于大型模型。CSP-CAM [17]提出了CSP-RFB [44]的紧凑版本,该版本使用三个膨胀卷积并对所有层应用Mish [32]激活。
PKINet [41]引入了多核Inception(PKI)块,该块使用不同尺寸的并行深度可分离卷积(无膨胀)来提取多尺度特征。PKINet的作者认为,对于物体通常极小且密集的遥感领域,膨胀卷积会受到"网格效应"的影响,可能遗漏局部信息。然而,在通用目标检测领域(例如MS COCO [4]),物体通常表现出连续的纹理和较大的空间范围。因此,我们选择膨胀卷积而不是Inception风格的块。膨胀使我们能够快速扩大感受野,以捕捉自然场景中常见的中大型物体所需的上下文信息,同时保持硬件友好且高效的模块设计。
在本工作中,我们基于CSP-CAM [17]构建,创建了一个更高效、更有效的模块来增加感受野,即深度双级感受野块(D2S-RFB)。本工作的贡献如下:1)将CSP-CAM [17]中的所有膨胀卷积切换为深度可分离卷积,2)增加一个第二阶段,其中使用两个核大小为5的深度可分离卷积。
2.4 目标检测的领域自适应
虽然我们的研究专注于通过架构优化来改进内在特征表示,但现实世界目标检测中一个独特且关键的挑战是领域偏移。当在源域(例如,白天图像)上训练的模型部署在具有不同分布的目标域(例如,夜间图像)时,就会发生这种偏移,从而显著降低性能。
该领域一个相关且重要的贡献是无监督领域自适应(UDA)方面的工作,其方法基于特征对齐技术[46,47]、自训练[48,49]和知识蒸馏[50,51]。该领域的最新进展之一是微调特征交互网络(FFINet)[51]。该论文通过全局-局部增强(GLA)来解决领域差距,以在低光照条件下获得更好的特征表示,以及基于联邦学习的微调特征交互(FFI)策略,以改进白天与低光照场景之间的特征对齐。
我们在本文中介绍的模块并非领域自适应技术;我们提出了对骨干特征提取器的基本架构增强。主要目标是通过扩展的感受野改进上下文理解,并通过自适应通道权重重新校准增强特征融合,从而为模型提供更强大的内在能力。
这两个研究流是相辅相成的:我们提出的模块改进了无论何种领域下提取的特征质量,而UDA则专注于在不同领域间对齐这些特征的分布。
3 提出的解决方案
本节将介绍所提出的模块HP-CSE和D2S-RFB的架构、在最新YOLO轻量级检测器中使用这些模块的方法论,以及将此方法论应用于两个YOLO-tiny模型(YOLOv7-tiny和YOLOv12-n)的详细示例。
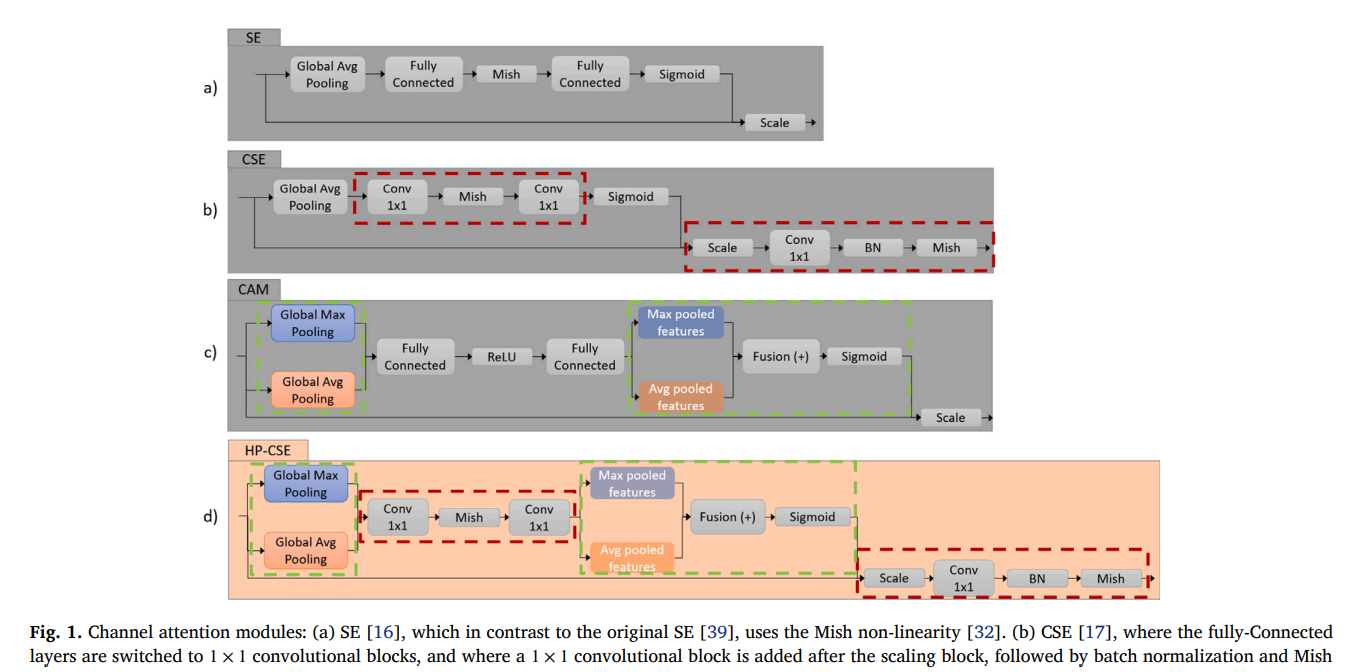
3.1 动机
在架构的颈部进行特征融合时,大多数轻量级目标检测器依赖于简单的加法这一经典方法,这种方法未考虑每个特征图的实际重要性。该方法隐式地假设不同分辨率和语义的特征具有同等重要性,已被证明会丢弃有用信息,并且在融合策略中表现次优[23, 39]。直到最近,才有少数研究工作开始集成通道和空间注意力机制[17, 23, 40],但这些机制相当粗糙,仍有改进空间。我们改进特征融合的想法是在通往每个融合节点的每个输入路径中插入混合通道注意力机制,从而产生按尺度和按通道的权重因子,在保持高效的同时实现更细粒度的控制。
绝大多数轻量级目标检测器在骨干网络中使用小核卷积,主要是为了保持低十亿浮点运算量(BFLOPS),并使边缘设备能够实现实时检测速度。在骨干网络中使用小核尺寸的缺点是感受野维度太小。堆叠3×3核卷积会限制有效感受野,并使模型偏向局部纹理,这可能损害那些受益于更广泛的形状/上下文线索的检测,特别是对于大物体、被遮挡物体和杂乱场景。所获得的有效感受野表现出减少的特征异质性,冗余度和特征过度局部化增加[23, 52]。轻量级目标检测器可以从更大的核卷积中大大受益,但必须始终牢记精度与速度的权衡。我们的研究旨在提高特征异质性和扩展感受野,这是通过使用膨胀卷积和增加核尺寸的卷积来实现的,同时通过使用深度可分离卷积和两级感受野扩展来保持较低的计算成本。
为了解决上述局限性,我们提出了HP-CSE和D2S-RFB模块,以及插入这些模块以最大化效能的方法论。
3.2 混合池化卷积压缩激励(HP-CSE)
我们提出的改进不同特征图分辨率和语义上下文的特征融合的方法称为HP-CSE。特征可以通过分配相等的贡献因子并将输入特征求和来聚合,如FPN[36]所提出的。这种方法已被证明会丢弃有用信息且表现次优。EfficientDet[23]表明,允许不同金字塔层级对聚合结果做出不等的贡献是有益的。然而,它使用了倾向于主导特征尺度的预定义连接模式,并且其对多尺度特征的多次双向传递重复聚合对于极轻量级部署可能相对较重。CBAM[40]提出同时使用通道注意力和空间注意力。其通道注意力模块使用一个共享网络来整合通过最大池化和平均池化提取的特征。其空间步骤使用固定的微小卷积并需要计算开销,使其在建模长程空间依赖性或尺度自适应融合方面能力有限。文献[16]中提出的SE块对来自不同金字塔深度的特征采用了逐通道融合策略,使用了标准全连接层和Mish非线性激活[32]。然而,该设计缺乏对缩放后特征的细化。CSE[17]基于相同的思路进行了改进,即将全连接层替换为1×1卷积层,并在缩放块之后添加了另一个CBM块,以细化缩放后的特征图。其通道注意力使用单一的全局描述符,丢弃了位置信息。这可能导致对全局统计贡献微小且可能被背景淹没的小型或细长物体的表征不足,从而在激励阶段过度抑制关键通道。
我们提出的HP-CSE模块被设计为CSE和CBAM的混合体,汲取了两者的优点。我们在图1中展示了所提出的HP-CSE的结构,以及其他相关通道注意力模块的结构。HP-CSE是一个通道注意力模块,它利用最大池化和平均池化来增强对输入特征图的压缩和特征提取。在我们的模块中,类似于文献[17]中的CSE模块,我们使用两个逐点卷积进行压缩部分,两者之间带有Mish激活[32]。我们通过添加CBAM[40]中的混合池化思想来扩展其特征提取能力。我们添加的共享网络以一种改进的方式整合了通过最大池化和平均池化获得的特征。在特征融合并应用Sigmoid激活后,获得的逐通道权重被应用于初始特征图以进行重新缩放。为了进一步扩展和探索通道间的关系,在重新缩放之后,我们添加了另一个逐点卷积,后接批量归一化和Mish激活[32]。
尽管我们也尝试过集成CBAM[40]中的空间注意力模块(SAM),但它并未改善检测性能。这可能是因为混合池化已经提供了该特定空间注意力模块带来的优势,而由于其卷积核的选择,空间注意力模块的远程建模能力有限。因此,对于我们的HP-CSE,我们决定仅使用通道注意力,因为它的影响最大。我们采用的方法能够以最小的额外计算成本和模型参数实现更好的特征融合。其他空间注意力模块与我们提出的模块的集成仍有待在未来单独的研究活动中进一步探讨。
3.3 深度双级感受野块(D2S-RFB)
鉴于准确的目标检测依赖于特征的上下文,该主题受到越来越多的研究关注。具有不同膨胀率的膨胀卷积是改进特征上下文最常用的块之一。CAM[45]将输入分支为三个部分,使用了核大小为3、膨胀率分别为1、3和5的膨胀卷积,然后是卷积-批量归一化-LeakyRelu(CBL)块以及通过求和进行的最终特征融合。其设计扩展了感受野,但没有对特征图进行细化或包含跳跃连接。CSP-RFB[44]提出了一个更新版本的RFB块,其中集成了CSP[31]的思想。他们首先使用两个核大小为3的CBL块,然后分支为五个部分。他们仅在两个分支中使用了膨胀卷积,核大小为3,膨胀率分别为3和5。除跳跃连接外,每个分支包含两个核大小为1的CBL块,其中一个分支包含三个CBL块。五个分支通过求和合并,然后经过另一个核大小为3的CBL块,最后与原始输入进行拼接。其设计比CAM更精细和复杂,但计算负载也显著更大。CSP-CAM[17]改进了CSP-RFB的架构,取消了前两个核大小为3的CBL块,将其中一个分支中的一个CBL块的核大小改为3,并去掉了最后的拼接块。他们还将所有层的激活函数都切换为Mish[32]。其设计比CSP-RFB更轻量和优化,但感受野扩展有限,因为他们只使用单级扩展,其中使用了核大小为3的卷积,且运算效率受到常规卷积的限制。
我们提出的D2S-RFB解决了上述结构的局限性,利用了深度可分离卷积和两阶段的感受野扩展。D2S-RFB的架构如图2所示,同时展示了其他SOTA相关模块的架构。在D2S-RFB中,我们基于CSP-CAM的结构构建,通过使其更高效并增加一个额外的阶段来增强其特征上下文能力。我们通过将所有核大小为3的卷积转换为深度可分离卷积来提高效率,即首先在每个通道上应用深度卷积,然后是逐点卷积、批量归一化和Mish[32]。这一改变使得模块更轻量化,检测性能仅有小幅下降。为了进一步增强提取特征的上下文,我们在模块中添加了第二阶段,它以CSP-CAM中最后一个核大小为3的CBM块的细化特征作为输入,并将其分支为三个部分。我们选择在此阶段内使用三个分支,作为额外计算影响与感受野扩展益处之间的权衡。底部分支是跳跃连接,而另外两个分支使用核大小为5、膨胀率分别为1和3的膨胀卷积。三个分支通过求和合并,然后是另一个核大小为3的CBM。
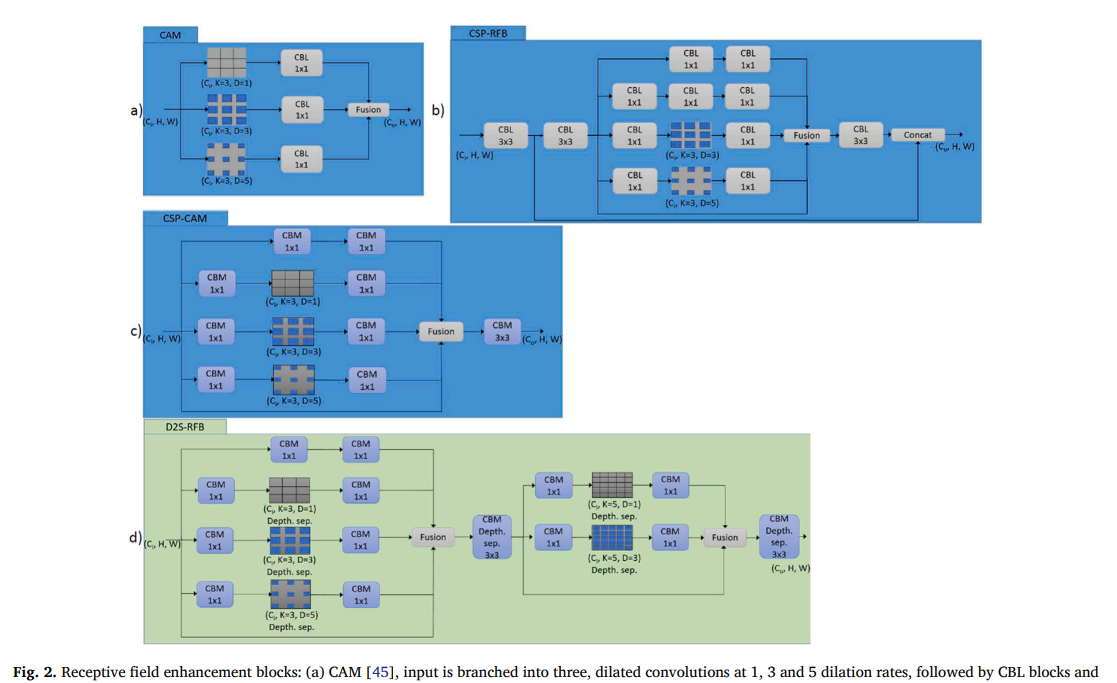
对于常规卷积,感受野等于核大小,而对于核大小为k×k、膨胀率为d、步长为s的膨胀卷积核,有效感受野变为𝑅𝐹 = 𝑑 ⋅ (𝑘 − 1) ⋅ 𝑠) + 1,以最小的参数开销显著扩展了范围。
在我们的D2S-RFB模块中,第一阶段中使用3×3核、膨胀率为3的膨胀卷积将感受野扩展到7,而使用3×3核、膨胀率为5的膨胀卷积将感受野扩展到11。在第二阶段,使用5×5核、膨胀率为3的膨胀卷积将感受野扩展到13。这使得网络能够以计算高效的方式有效吸收局部和全局空间信息,从而增强其捕获复杂模式和上下文依赖性的能力。第二阶段特别有效,因为它建立在第一阶段已经扩展的感受野之上,同时使用能更好地捕捉物体上下文性的更大卷积核。这种方法确保了特征表示的鲁棒性,对于具有内在空间意识依赖性的任务尤其有效。
3.4 将HP-CSE和D2S-RFB集成到轻量级目标检测器中的方法论
我们提出的模块集成到轻量级目标检测器中的方式对其效能和效率有重要影响。我们插入这些块的方法论目标是最大化检测性能增益,同时保持原始网络架构。这意味着我们希望与原始实现中骨干网络的特征图数量以及特征图大小保持一致。
在图3中,我们展示了近期YOLO tiny模型(从YOLOv7-tiny到YOLOv12-n)的通用架构,其基于特定类型的下采样卷积、骨干特征提取块,然后是三个相互连接的颈部块和检测头分支(不同尺度)。两个提出的模块D2S-RFB和HP-CSE的插入点也在图3中描述。D2S-RFB应插入在下采样卷积之后、主要的骨干特征提取块之前。HP-CSE块在目标检测器的颈部部分很有用,在每个拼接块之后使用它们可以增加其有效性。对于D2S-RFB和HP-CSE,输出通道的数量应与模块的输入通道数相同,以确保效率并保持低BFLOPS。
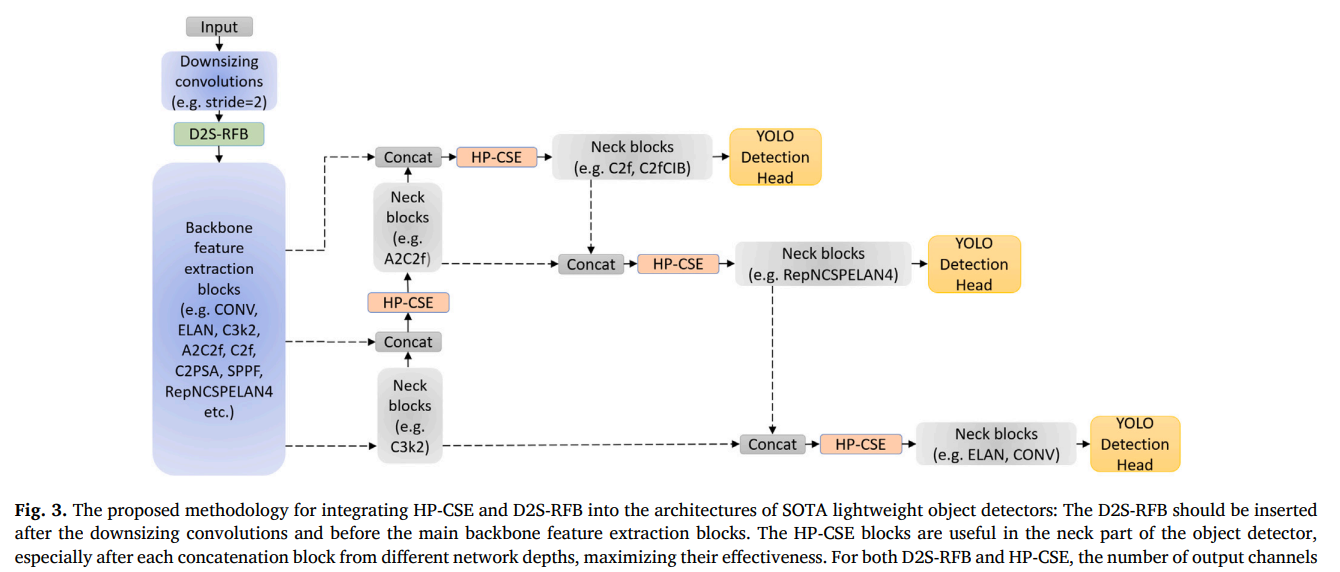
我们在六个SOTA轻量级目标检测器上测试该方法论,即YOLOv7-tiny[14]、YOLOv8-n[3]、YOLOv9-t[5]、YOLOv10-n[6]、YOLOv11-n[2]和YOLOv12-n[1]。在每个架构中,我们在骨干网络前添加一个D2S-RFB块,并在颈部添加数量不等的HP-CSE块(取决于模型架构)。我们根据每个原始模型架构中的卷积核数量来调整D2S-RFB块中的通道数。对于YOLOv7-tiny,我们使用64,对于所有其他模型,我们使用32。对于YOLOv7-tiny、YOLOv8-n、YOLOv10-n、YOLOv11-n和YOLOv12-n,HP-CSE块的数量为四个,而YOLOv9-t使用了六个这样的块。对于HP-CSE块,我们将压缩比设置为16。我们决定使用16的压缩比以尽可能保持模型小,同时限制模型缩减通常对检测性能产生的负面影响。我们的设计决策也基于对CSE[17]进行的模型缩放实验,该实验表明将压缩比设置为16对检测性能没有负面影响(获得相同的AP),同时将模型参数量减少21%,BFLOPS减少10%。
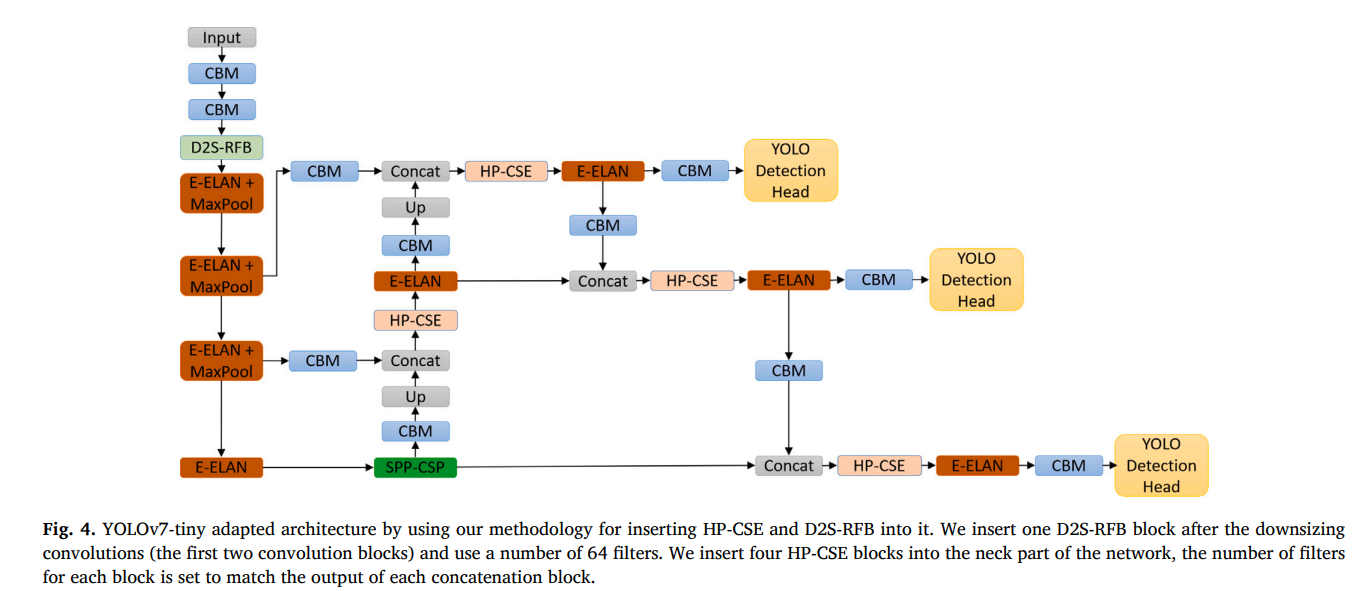
作为实际应用案例,我们展示了该方法论如何实际用于YOLOv7-tiny和YOLOv12-n。我们在图4中展示了应用我们提出的方法论后,YOLOv7-tiny的改进架构。获得的网络结构类似于ECF-YOLOv7-tiny[17],主要区别在于新的模块:一个D2S-RFB块和四个HP-CSE块。我们在图5中展示了我们带有HP-CSE和D2S-RFB的改进版YOLOv12-n架构。图4和图5中的YOLOv7-tiny和YOLOv12-n架构都是使用图3中所示的相同插入位置获得的,但其他块(卷积、骨干、颈部等)是原始模型架构特有的。
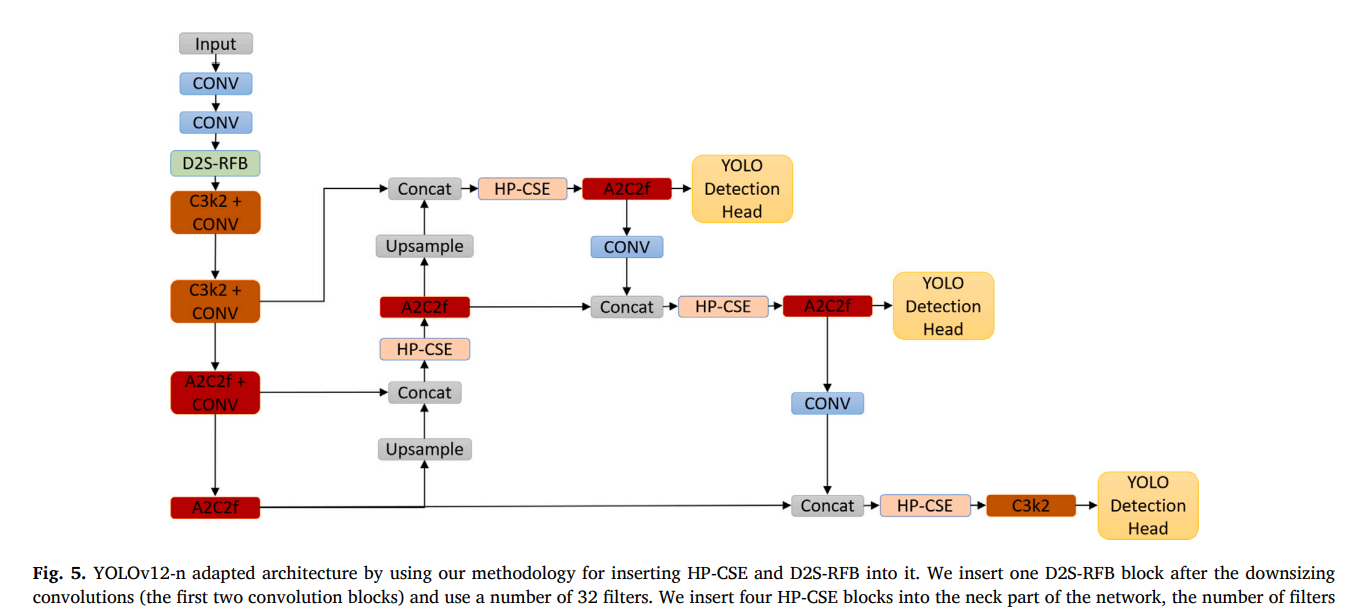
4 实验结果
本节将展示我们在实验中使用的配置和数据集。我们使用mAP、BFLOPS、参数量和FPS等指标评估性能并比较模型。我们对每个提出的模块进行了消融研究。我们通过将提出的模块和方法论引入几个SOTA轻量级目标检测器来证明其有效性。我们对简单增加模型容量与我们方法论之间的检测性能进行了比较研究。接下来,我们将与研究文献中的SOTA轻量级目标检测器进行性能比较。然后,我们在另一个数据集上测试模型的泛化能力。接着,我们系统性地评估并量化了不同遮挡水平下的检测性能。最后,我们进行了定性性能比较。
4.1 实验设置
我们使用PyTorch框架定义和训练模型,且均从零开始训练。为确保公平和有意义的比较,对于每个训练好的模型,我们使用了作者在研究论文中或官方公开代码库中指定的超参数设置。YOLOv7-tiny是我们为初步实验选择的基础架构。我们使用带动量0.937的随机梯度下降(SGD)作为优化器,同时将初始学习率设置为0.01。我们使用的输入图像尺寸为416×416,并将模型训练500个轮次。我们在NVIDIA A40 GPU上运行训练任务,批量大小设置为128。完整的训练超参数集如表4所示。我们使用NVIDIA Jetson Nano测量检测速度,选择它是因为它是市场上最具成本效益和能效的GPU之一。它具有128个核心,4GB内存,在使用FP-16精度时可以达到471 GFLOPs。我们使用PyTorch的FP-16设置和批量大小32来评估检测速度,且不使用TensorRT[53]。在表达FPS数时,我们决定不使用TensorRT,以便更好地了解在实际场景中部署模型时可以达到的最低速度,因为在所有情况下可能无法使用TensorRT。
4.2 实验数据集
我们在实验中使用知名的MS COCO 2017[4]。它包含122,265张图像,标注了80个物体类别。我们遵循2017年的数据划分建议,并根据数据集的评估指标报告结果。主要关注点是在IoU阈值为0.5时的mAP、IoU从0.5到0.95的10个值的平均值,以及分别针对小、中、大尺寸物体计算的AP。
为了检查训练好的模型的泛化能力,我们选择Pascal VOC 2007数据集[20]作为补充基准。在此数据集上,我们评估模型在分布偏移下的泛化能力。该数据集包含4952张测试集图像,涵盖20个常见物体类别。我们直接在Pascal VOC 2007测试集上评估在MS COCO数据集上训练好的模型。
4.3 优化器与激活函数
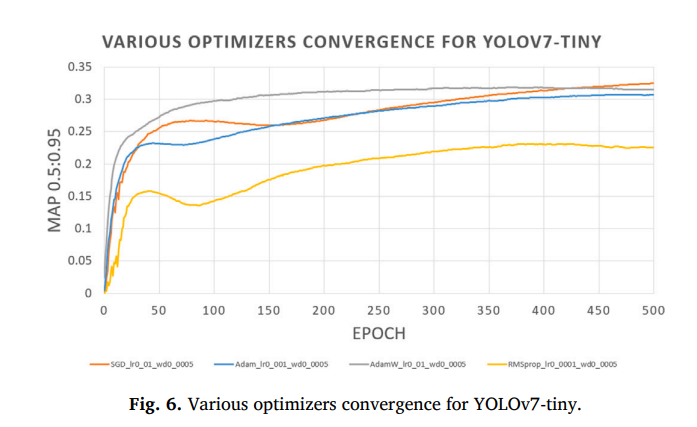
最新的六个SOTA YOLO目标检测模型都使用了SGD作为优化器,这表明该优化器已非常成熟,并且能为此特定的计算机视觉任务带来平滑的模型收敛。我们测试了使用Adam优化器,学习率0.001(如YOLOv7官方代码库所推荐),并训练了与SGD相同的500个轮次,但模型只达到了32.1%的𝐴𝑃𝑣𝑎𝑙_50-95,比使用SGD时低了1.5%。我们还使用AdamW和RMSprop优化器以及多种学习率和权重衰减进行了测试,训练了相同的500个轮次。在图6中,我们展示了四种优化器(SGD、Adam、AdamW和RMSprop)的最佳配置下,验证集mAP随训练轮次的收敛情况。图中可以清楚地看到SGD(橙色线)取得了最好的结果。基于这些原因,并为了与之前的YOLO版本保持一致,我们决定在后续所有实验中继续使用SGD作为优化器。
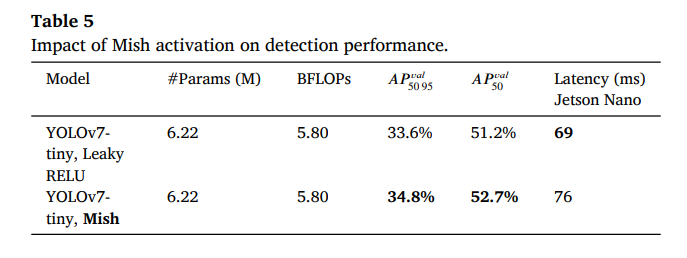
接下来,我们希望确定要使用的激活函数,我们比较了Leaky RELU和Mish[32]。我们在表5中显示,切换到Mish对参数数量和BFLOPs没有影响,同时将𝐴𝑃𝑣𝑎𝑙_50-95提高了1.2%,将𝐴𝑃𝑣𝑎𝑙_50提高了1.5%。由于Mish计算复杂度更高,使用Mish的模型的延迟增加了10%。我们认为这种权衡是可以接受的,在接下来的实验中,Mish将是我们模型架构中使用的激活函数。
4.4 混合池化卷积压缩激励(HP-CSE)
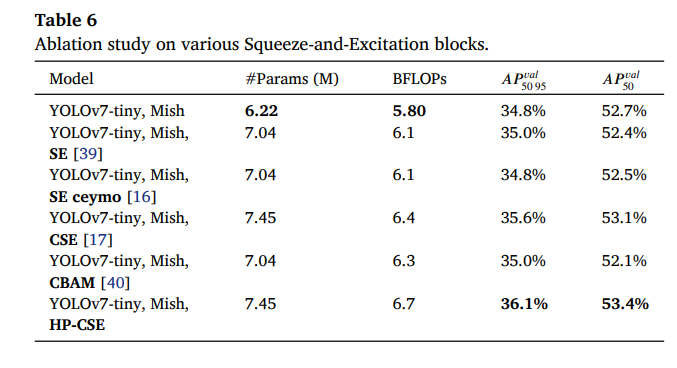
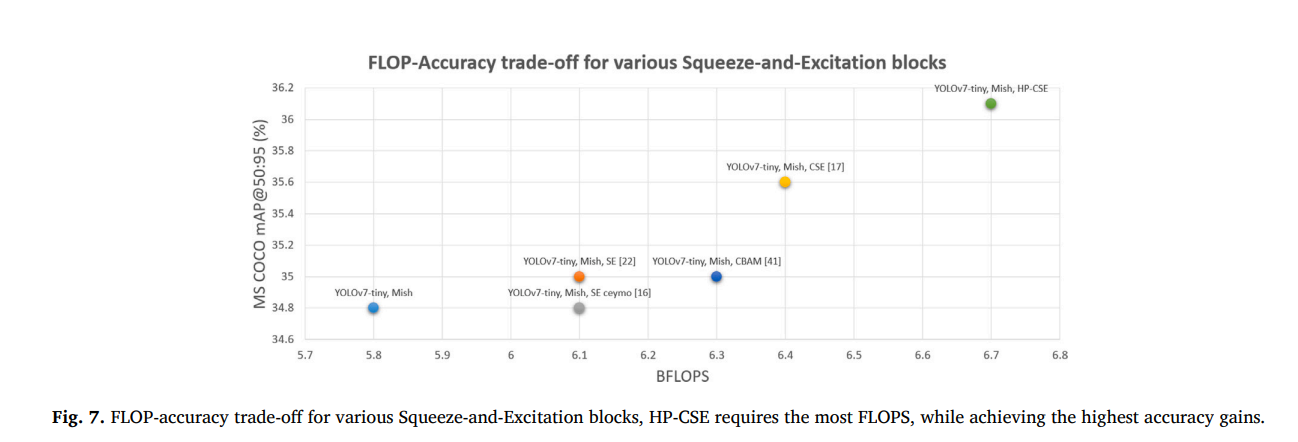
我们的初步实验是测试各种压缩激励(Squeeze-and-Excitation)块对整体目标检测性能的影响。我们将这些块的压缩因子配置为1,并在表6中展示了获得的结果。带有HP-CSE块的模型需要增加最多的模型参数和BFLOPS,但也获得了最佳的检测性能提升。与普通的YOLOv7-tiny相比,添加我们的HP-CSE块需要增加19.7%的模型参数和15.5%的BFLOPS,同时将𝐴𝑃𝑣𝑎𝑙_50-95提高了1.3%,将𝐴𝑃𝑣𝑎𝑙_50提高了0.7%。各种压缩激励块的FLOP-精度权衡如图7所示,其中可以观察到HP-CSE需要最多的FLOPS,同时获得了最高的精度增益。
4.5 HP-CSE前后的特征多样性分析
为了验证HP-CSE在减少特征冗余方面的有效性,我们分析了在包含HP-CSE的YOLOv7-tiny模型架构中,HP-CSE块提取的特征图的通道相关矩阵和互信息。图8显示了HP-CSE块之前通道间的皮尔逊相关系数和互信息(第一列),以及HP-CSE之后的结果(第二列)。
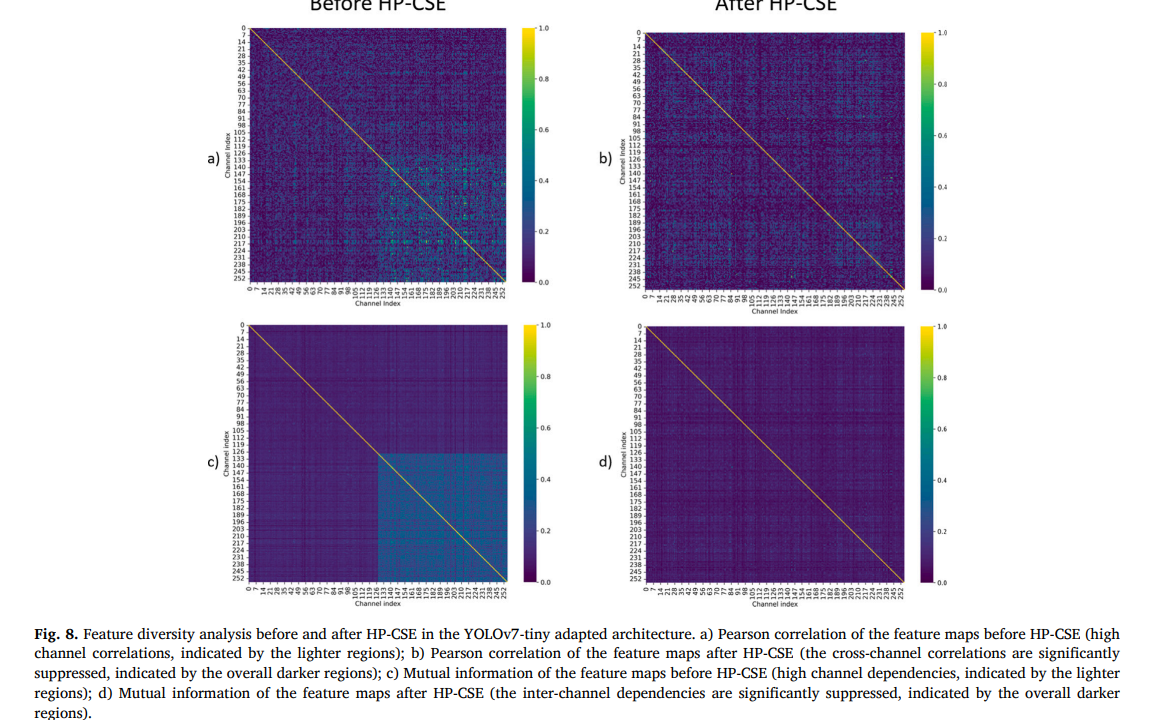
如图8所示,HP-CSE块之前的特征图表现出较高的通道互相关性(由较浅区域表示,特别是在通道范围的后半部分),表明存在显著冗余,多个通道编码了相似信息(见第一列a和c)。相反,第二列的图表(b和d)表明HP-CSE显著抑制了这些通道间的依赖性。这表明所提出的模块(HP-CSE)成功地重新校准了通道权重,使网络能够学习更多样化和更具区分性的特征。
4.6 深度双级感受野块(D2S-RFB)
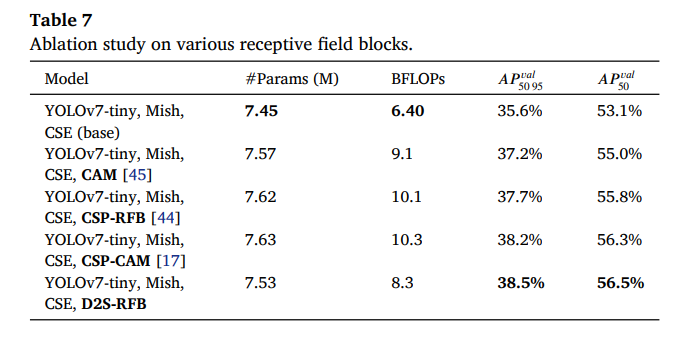
我们的下一组实验是关于网络架构骨干部分各层感受野大小的影响。我们研究了D2S-RFB相对于文献中其他几个块的有效性,并在表7中展示了这项消融研究的结果。为了在这些实验中进行更好的比较,我们选择带有CSE块[17]的YOLOv7-tiny作为基线。与包含其他模块的模型相比,包含D2S-RFB的模型具有最少的参数数量和最低的BFLOPS需求,同时实现了最佳的检测性能提升。与基线相比,带有D2S-RFB的模型参数增加了1%,BFLOPS增加了29.6%,同时将𝐴𝑃𝑣𝑎𝑙_50-95的检测性能提高了2.9%,将𝐴𝑃𝑣𝑎𝑙_50提高了3.4%。
4.7 HP-CSE和D2S-RFB在SOTA轻量级目标检测器中的跨架构泛化能力
为了证明我们提出的HP-CSE和D2S-RFB模块的跨架构泛化能力,我们将其引入到几个SOTA轻量级目标检测器中,即YOLOv7-tiny[14]、YOLOv8-n[3]、YOLOv9-t[5]、YOLOv10-n[6]、YOLOv11-n[2]和YOLOv12-n[1]。我们根据官方代码库提供的说明和配置,在输入尺寸416下从零开始训练模型。在每个架构中,我们在骨干部分添加一个D2S-RFB块,在颈部添加数量不等的HP-CSE块(取决于模型架构)。我们调整D2S-RFB块中的卷积核数量以匹配原始模型。对于YOLOv7-tiny,我们使用64,而对于所有其他模型,我们使用32。对于YOLOv7-tiny、YOLOv8-n、YOLOv10-n、YOLOv11-n和YOLOv12-n,HP-CSE块的数量为四个,而YOLOv9-t使用了六个这样的块。对于HP-CSE块,我们将压缩比设置为16。我们在表8中展示了将我们的模块添加到每个SOTA YOLO架构后的结果。
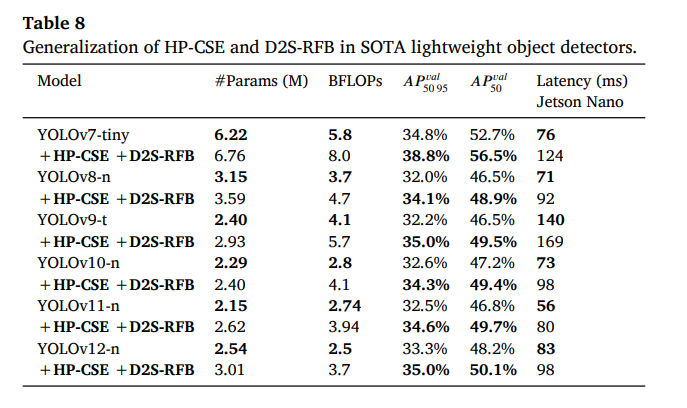
将我们提出的模块添加到SOTA轻量级目标检测器的架构中,使得每个模型的性能都得到了显著提升,同时只需要增加少量参数(最多0.5M)和少量额外的BFLOPS(通常为1.1,但对于YOLOv9-t最多为1.6 BFLOPS)。
检测性能提升最大的是YOLOv7-tiny。添加我们提出的HP-CSE和D2S-RFB使参数量增加了8.6%,BFLOPS增加了20.6%,但同时将𝐴𝑃𝑣𝑎𝑙_50-95的检测性能提高了4%,将𝐴𝑃𝑣𝑎𝑙_50提高了3.8%。添加HP-CSE和D2S-RFB对该系列最新的YOLO架构YOLOv12-n也非常有效。参数数量增加了18.5%,BFLOPS增加了48%,同时𝐴𝑃𝑣𝑎𝑙_50-95的检测性能提高了1.7%,𝐴𝑃𝑣𝑎𝑙_50提高了1.9%。最快的模型是YOLOv11-n,它在Jetson Nano上实现了56毫秒的延迟。在用HP-CSE和D2S-RFB改进后,延迟增加到80毫秒。我们还通过在Jetson Nano上进行推理时测量GPU功耗来评估能效。GPU的平均待机功耗为121毫瓦,而推理期间的平均功耗为390毫瓦。所有测试模型的能耗值都相当,这可能是因为它们都属于相同的轻量级模型类别。添加两个提出的模块不会影响模型的边缘部署能力。
4.8 模型容量增加的比较研究
为了证明添加HP-CSE和D2S-RFB比单纯增加模型容量更能提高检测精度,我们比较了几个SOTA轻量级目标检测器的实现结果,即YOLOv7-tiny[14]、YOLOv8-n[3]、YOLOv9-t[5]、YOLOv10-n[6]、YOLOv11-n[2]和YOLOv12-n[1]。为了确保模型容量增加比较的公平性,我们决定将每个架构的前3个骨干块中的卷积滤波器(卷积核)数量加倍。卷积核的加倍使我们能够获得与包含HP-CSE和D2S-RFB的模型相当的模型参数量和BFLOPS。
我们根据官方代码库提供的说明和配置,在输入尺寸416下从零开始训练模型。对于添加HP-CSE和D2S-RFB的实验,我们在骨干部分添加一个D2S-RFB块,并在颈部添加数量不等的HP-CSE块(取决于模型架构)。我们调整D2S-RFB块中的卷积核数量以匹配原始模型。对于YOLOv7-tiny,我们使用64,而对于所有其他模型,我们使用32。对于YOLOv7-tiny、YOLOv8-n、YOLOv10-n、YOLOv11-n和YOLOv12-n,HP-CSE块的数量为四个,而YOLOv9-t使用了六个这样的块。对于HP-CSE块,我们将压缩比设置为16。我们在表9中展示了每个SOTA YOLO架构所实现的结果。
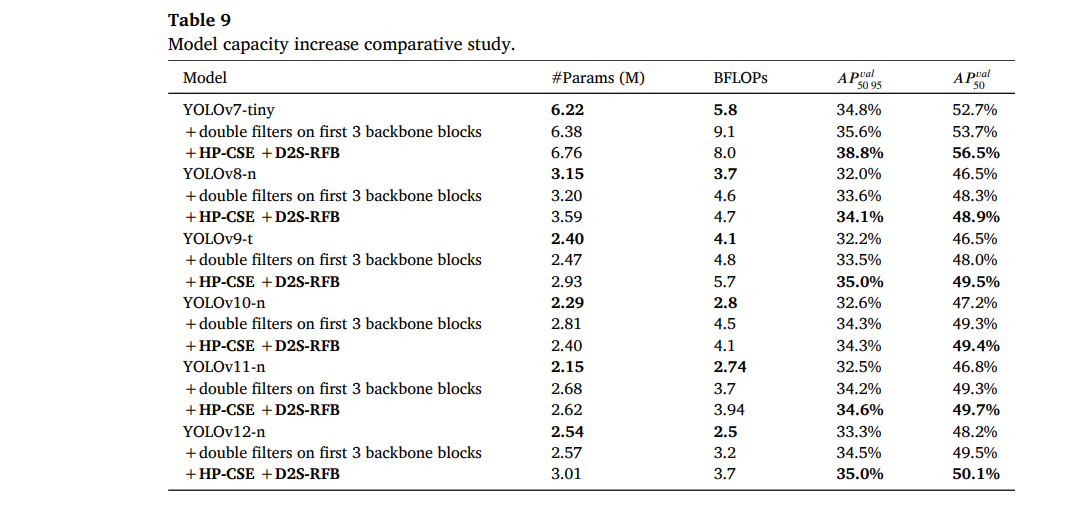
使用HP-CSE和D2S-RFB使得模型在𝐴𝑃𝑣𝑎𝑙_50-95上相比单纯增加模型容量平均提高了1.0%,这是YOLO模型五种最新纳米架构之间平均性能提升(0.3%)的三倍多。提升最大的是YOLOv7-tiny(3.2%)和YOLOv9-t(1.5%),而提升最小的是YOLOv12-n(0.5%)和YOLOv11-n(0.4%)。对于YOLOv10-n,当前3个骨干块的滤波器加倍时,获得的模型参数量增加了17%,BFLOPS增加了10%,但达到了与使用HP-CSE和D2S-RFB改进的模型相同的检测性能。所获得的结果表明,检测性能的改善部分归因于模型容量的增加,模块内块的结构和排列顺序也有重要贡献。
4.9 与最先进(SOTA)轻量级目标检测器的比较
为了与其他SOTA轻量级目标检测器比较,我们寻找在输入尺寸416上训练、BFLOPS少于10、并且在NVIDIA Jetson Nano上实现实时检测速度的模型。由于一些模型仅在640输入尺寸上训练,我们必须将它们重新在416输入尺寸上从零开始训练,即YOLOv8-n[3]、YOLOv9-t[5]、YOLOv10-n[6]、YOLOv11-n[2]和YOLOv12-n[1]。为了确保公平和有意义的比较,对于每个重新训练的模型,我们使用了作者在研究论文中或官方公开代码库中指定的超参数设置。对于YOLOv7-tiny,我们使用了作者在原始论文中报告的结果。我们在表10中展示了比较结果。
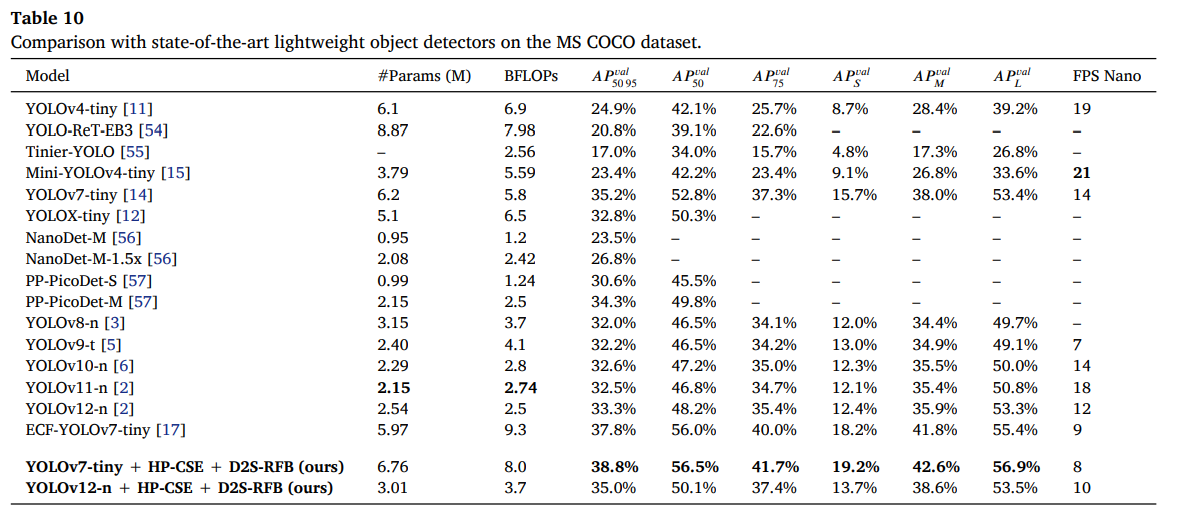
与非YOLO的轻量级目标检测器相比,如NanoDet-M-1.5x和PP-PicoDet-M,我们改进的YOLOv7-tiny参数量分别是它们的3.25倍和3.14倍,BFLOPS分别是3.30倍和3.2倍,同时将𝐴𝑃𝑣𝑎𝑙_50-95的检测性能显著提高了12.0%和4.5%。其他非YOLO轻量级目标检测器,如EfficientDet-lite和MobileDet,没有在416输入图像分辨率上的公开结果,因此我们无法进行公平比较。例如,MobileDet-CPU在输入尺寸320上训练,拥有385万个参数和0.51 BFLOPS,实现了24.2%的𝐴𝑃𝑣𝑎𝑙_50-95,比我们改进的YOLOv7-tiny低14.6%。EfficientDet-lite1在输入尺寸384上训练,拥有420万个参数,BFLOPS未报告,实现了31.5%的𝐴𝑃𝑣𝑎𝑙_50-95,比我们改进的YOLOv7-tiny低7.3%。EfficientDet-lite2在输入尺寸448上训练(高于我们使用的输入分辨率),拥有530万个参数,BFLOPS未报告,实现了35.1%的𝐴𝑃𝑣𝑎𝑙_50-95,比我们改进的YOLOv7-tiny低3.7%。
与该系列最新的轻量级成员YOLOv12-n相比,我们改进的YOLOv7-tiny参数量是其2.66倍,BFLOPS是其3.2倍,但它将𝐴𝑃𝑣𝑎𝑙_50-95的检测性能显著提高了5.5%,将𝐴𝑃𝑣𝑎𝑙_50提高了8.3%。YOLOv12-n在NVIDIA Jetson Nano上比我们的模型更快,达到12 FPS,比我们的模型多4 FPS。
即使与ECF-YOLOv7-tiny[17](目前输入尺寸416上性能最佳的轻量级目标检测器)相比,所提出的模块也带来了相关的改进,略大于最新SOTA轻量级检测器之间的平均性能提升(YOLOv7至YOLOv12之间为0.3%-0.8%)。我们改进的YOLOv7-tiny参数量增加了13.2%,需要的BFLOPS减少了14%,同时将𝐴𝑃𝑣𝑎𝑙_50-95的检测性能提高了1.0%,将𝐴𝑃𝑣𝑎𝑙_50提高了0.5%。对于高精度定位的物体,以及小尺寸和大尺寸物体,都实现了显著改进。𝐴𝑃𝑣𝑎𝑙_75提高了1.7%,𝐴𝑃𝑣𝑎𝑙_𝑆(小物体)提高了1.0%,𝐴𝑃𝑣𝑎𝑙_𝐿(大物体)提高了1.5%。我们改进的YOLOv7-tiny达到了8 FPS,因为硬件没有针对深度可分离卷积和膨胀卷积进行优化。如果使用TensorRT,该模型在Jetson Nano上可能达到约18 FPS。获得的结果表明,我们改进的YOLOv7-tiny在COCO数据集上以416输入分辨率实现了顶级的检测性能,同时保持了实时检测速度。
4.10 在Pascal VOC数据集上的模型泛化能力
为了展示训练好的模型的泛化能力,我们取在MS COCO数据集上训练的YOLOv7-tiny和改进版YOLOv7-tiny,在Pascal VOC 2007数据集的测试集上对它们进行评估。定量结果如表11所示。表中还包含了三个在Pascal VOC数据集上训练和评估的SOTA轻量级目标检测器,即YOLOv4-tiny、Trident YOLO和Mini-YOLOv4-tiny。我们在分析中纳入这些模型,是为了对416输入图像分辨率下评估集的预期平均检测性能提供一个粗略的概念。这三个模型𝐴𝑃𝑡𝑒𝑠𝑡_50的平均mAP为71.19%。在MS COCO上训练并在Pascal VOC测试集上评估的YOLOv7-tiny实现了80.1%的𝐴𝑃𝑡𝑒𝑠𝑡_50和55.7%的𝐴𝑃𝑡𝑒𝑠𝑡_50-95。改进的YOLOv7-tiny实现了83.1%的𝐴𝑃𝑡𝑒𝑠𝑡_50和60.6%的𝐴𝑃𝑡𝑒𝑠𝑡_50-95,与YOLOv7-tiny相比,两个指标都显示出显著提高的检测性能,这证明了模型增强的泛化能力。其检测性能也显著优于在Pascal VOC上训练的SOTA模型所达到的水平。改进版YOLOv7-tiny报告的结果是三个在MS COCO数据集上独立训练、配置完全相同的模型获得的平均结果。在MS COCO上,𝐴𝑃𝑡𝑒𝑠𝑡_50-95达到的标准偏差极低,为0.05%。对于Pascal VOC数据集,尽管三个模型没有在其上训练,达到的标准偏差为0.2%,这也非常低。这些结果显示了在与训练数据集不同的数据集上具有高度的一致性和模型泛化能力。
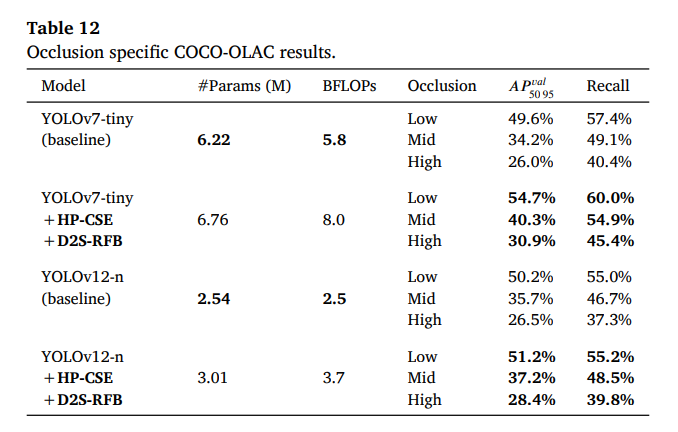
4.11 MS COCO上针对遮挡的专门评估
为了系统性地评估和量化不同遮挡水平下的检测性能,我们在MS COCO数据集的COCO-OLAC[58]划分上评估了YOLOv7-tiny和YOLOv12-n以及它们各自的改进版本。COCO-OLAC为MS COCO验证数据集提供了三个划分:高、中、低遮挡样本。使用给定的划分,我们为每个遮挡级别分别计算目标检测统计指标,并将结果呈现在表12中。可以观察到,所有模型在高遮挡数据上的表现都显著更差,而在低遮挡数据上则持续获得更好的结果。
与基线YOLOv7-tiny相比,改进的模型在所有遮挡级别上都取得了显著提升,甚至在高遮挡数据上也是如此(AP提升4.9%,召回率提升5.0%)。
与基线YOLOv12-n相比,改进的模型在所有遮挡级别上都取得了显著改善的结果,其中在高遮挡数据上观察到的改善最大(AP提升1.9%,召回率提升2.5%)。实验结果表明,使用我们的HP-CSE和D2S-RFB有助于解决轻量级目标检测中的遮挡问题,从而在被遮挡物体上实现更好的检测性能。
4.12 MS COCO上的定性性能比较
在图9中,我们展示了YOLOv7-tiny与改进版YOLOv7-tiny在MS COCO上的定性性能比较。所选示例突出了一些改进模型表现更鲁棒的情况,特别是对于被遮挡物体和距离相机较远的物体。这些示例展示了所提出的架构增强在实际应用中的潜力,可有效用于自动驾驶场景、交通和野生动物监测。
4.13 局限性与未来工作 尽管HP-CSE和D2S-RFB展示了有希望的结果,但它们也有局限性。我们提出的模块无法解决轻量级目标检测器的一些关键局限性。首先,对于受雾或大气污染影响的远处某些物体,检测仍然会失败,如图9中c组第二列图像上半部分的物体。其次,在物体与背景对比度低的场景中(见图9中c组第二列图像左上方的行人),我们的方法可能仍然无法正确检测物体。在未来的工作中,有潜力解决这些局限性的研究领域包括数据增强、领域自适应和改进的特征表示。此外,我们计划探索轻量级空间注意力模块,优化插入点以及通道注意力模块的数量。我们还打算以轻量化设计的方式改进感受野扩展模块。
5 结论
在这项研究工作中,我们提出了两个改进轻量级目标检测器检测性能的模块。混合池化卷积压缩激励(HP-CSE)模块高效地改进了特征融合,而深度双级感受野块(D2S-RFB)模块则有效扩大了感受野。我们展示了如何通过我们的方法论将模块插入到最新SOTA轻量级目标检测器的架构中以最大化其效能。通过我们的方法论,增强后的模型在保持NVIDIA Jetson Nano上实时检测速度的同时,实现了显著的检测性能提升。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号