开源UserBank:重新定义AI时代的个人数据主权

开源UserBank:重新定义AI时代的个人数据主权

mixlab
发布于 2026-03-24 20:30:05
发布于 2026-03-24 20:30:05
最近我统计了一个数据:我在各个AI平台上累计对话超过数千小时,产生了超过上千万字的高质量内容。这些内容包括我的技术见解、学习心得、人生感悟、创意灵感...
但这些构成"数字化的我"的珍贵数据,却零零散散地放在各个平台里,成了一个个数据孤岛。
更可怕的是,即使是同一个AI,新开一个对话窗口,之前的一切就都消失了。我们在不断地向AI重复介绍自己,却永远无法让它真正认识我们。
就像把钱分别存在了不同的银行,却没有一个统一的账户来管理。
这个想法其实酝酿了7年
2018年,我在写《AI改变设计》时就意识到了这个问题。人工智能与设计(2)-面向用户的人工智能系统底层设计
那时候我提出:"若要使人工智能得到更快发展,需要分析和了解更多完整数据。" 我设想每个人都应该有一个数据仓库,它能存储和整理不同应用厂商的数据,而人工智能可以利用数据进行自我优化和分析出该名用户的特征。
我当时写道:
例如我们手机里的淘宝和京东,用户使用它们时的动机和场景不一样,所以它们所得的用户画像仅是该名用户的一部分,不能完全代表该名用户。如果淘宝和京东将各自的数据保存到个人数据仓库,人工智能将数据整理完后为淘宝和京东输出已授权的完整用户画像,那么淘宝和京东可以为该名用户提供更多的个性化服务,创造更多收益。
6年后的今天,AI的能力已经远超当年的想象,但数据孤岛的问题却变得更加严重。
每个AI平台都在努力了解你,但它们看到的都只是碎片。更讽刺的是,互联网的初衷本是去中心化——Tim Berners-Lee(万维网发明者)曾说:"将网络设计成去中心化的,每个人都可以参与进来,拥有自己的域名和网络服务器。"
现在,是时候把这个7年前的设想变成现实了。
UserBank:不只是工具,更是一种认知架构
UserBank = Unified Smart Experience Records Bank(统一智能体验记录银行)
为什么叫"银行"?因为我想提供的不仅仅是一个存储工具,而是一个像银行一样安全、可信、标准化的"数据保险箱"。你的数据不应该是"寄存"在各个平台,而应该存在你自己的银行里。
MCP协议:AI数据世界的USB接口
实现这个愿景的关键技术是MCP(Model Context Protocol)。你可以把MCP想象成AI数据领域的USB接口——就像USB让各种设备都能连接到电脑一样,MCP让各种AI都能安全、标准化地访问你的数据。
有了MCP,不同平台之间的数据壁垒就被打破了。数据实时同步,体验自然就更连贯了。
为什么是这9种数据类型?从认知心理学说起
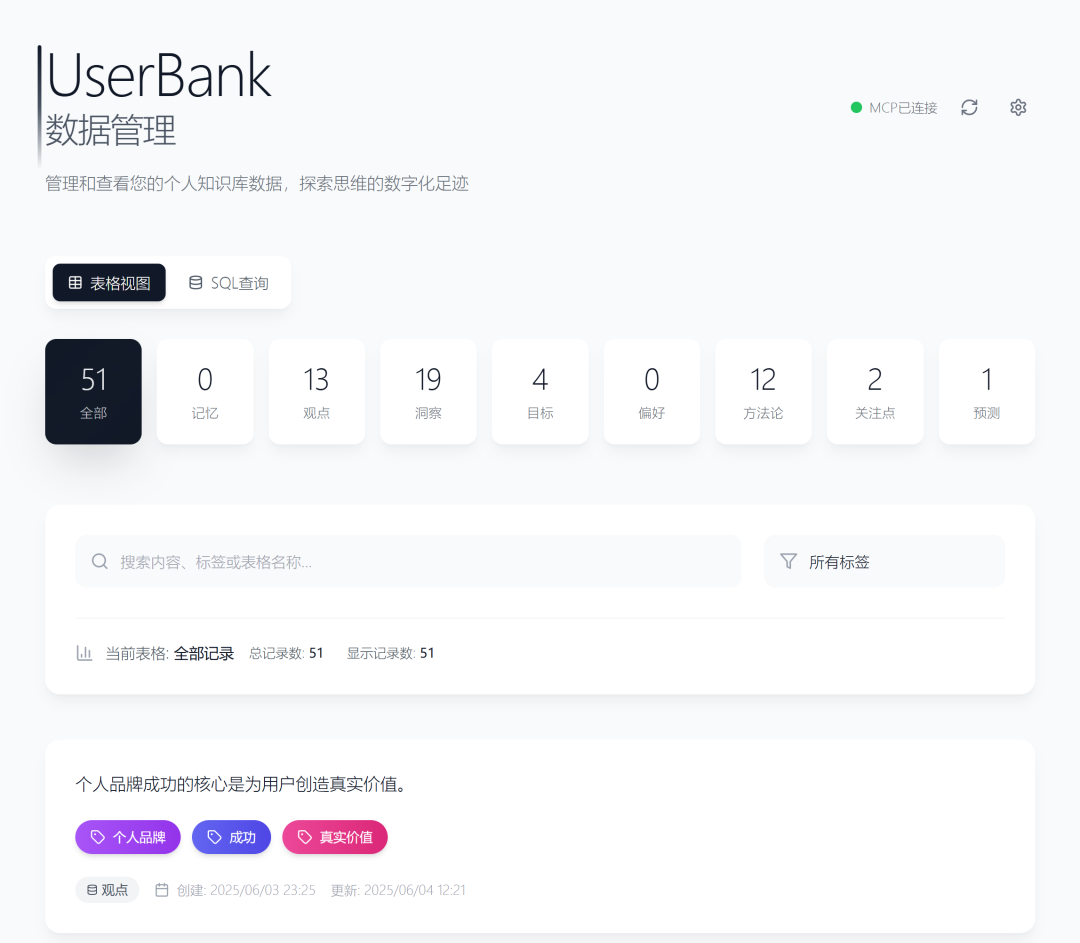
在UserBank中我选择了9种数据类型,它们分别是:
1. 👤 个人资料(Persona)- 自我认知的锚点
- 这是"我是谁"的基础定义
- 在认知心理学中,自我概念是一切认知的起点
- AI需要这个锚点来理解你的所有其他数据
2. 🧠 记忆(Memory)- 经验塑造的认知基础
- 分为6种类型,对应不同的认知加工方式
- 经历和事件:情景记忆,构成个人叙事
- 学习:语义记忆,知识体系的构建
- 互动:社交记忆,关系网络的映射
- 成就与错误:情绪记忆,驱动未来决策
3. 💭 观点(Viewpoint)- 价值体系的外显
- 你的信念、立场、价值观
- 这是判断和决策的依据
- AI通过理解你的观点,才能提供符合你价值观的建议
4. 💡 洞察(Insight)- 认知突破的结晶
- "啊哈时刻"的记录
- 代表你的创造性思维和问题解决能力
- 这些是你独特思维模式的体现
5. 🎯 目标(Goal)- 动机系统的映射
- 从长期愿景到日常任务的完整体系
- 反映你的动机、追求和优先级
- AI理解你的目标,才能真正帮助你
6. ❤️ 偏好(Preference)- 行为模式的编码
- 你的习惯、喜好、工作方式
- 这决定了AI应该如何与你交互
- 个性化体验的基础
7. 🛠️ 方法论(Methodology)- 思维模式的沉淀
- 你解决问题的独特方式
- 最佳实践和思维框架
- AI可以学习并应用你的方法论
8. 🔍 关注(Focus)- 注意力的分配图谱
- 当前的兴趣点和优先事项
- 反映你的认知资源分配
- 帮助AI理解什么对你最重要
9. 🔮 预测(Prediction)- 认知模型的验证循环
- 你对未来的判断和推测
- 通过验证不断优化你的认知模型
- AI可以学习你的预测模式,提供更好的决策支持
这9种数据类型,共同构成了一个完整的"认知数字孪生"。它不是简单的信息堆砌,而是对人类认知架构的数字化映射。
UserBank vs 传统知识管理工具:本质的不同
很多人问我,UserBank和Notion、Obsidian这些工具有什么区别?
根本区别在于:知识管理工具是为人类阅读设计的,UserBank是为AI理解设计的。
维度 | 传统知识管理 | UserBank |
|---|---|---|
设计目标 | 人类组织和查阅 | AI理解和应用 |
数据结构 | 文档、笔记、标签 | 认知模型的9个维度 |
使用方式 | 人主动查询 | AI主动理解 |
价值体现 | 知识的存储 | 智慧的激活 |
连接方式 | 人工建立链接 | MCP协议自动连接 |
隐私控制 | 全有或全无 | 细粒度的权限控制 |
举个例子:
- 在Notion中,你记录:"我认为代码可读性比性能更重要"
- 在UserBank中,这成为一个Viewpoint,所有AI在帮你写代码时都会遵循这个原则
数据的复利效应:当UserBank积累越多
这是UserBank最迷人的地方——数据的复利效应。
第一个月:AI开始认识你
- 了解你的基本信息和偏好
- 记住几个重要的对话
- 简单的个性化回应
第六个月:AI开始理解你
- 掌握你的思维模式
- 预测你的需求
- 提供深度个性化的建议
第一年:AI成为你的认知延伸
- 深刻理解你的价值观和目标
- 主动提醒和建议
- 成为真正的思维伙伴
更重要的是跨AI协作:
早上:Claude帮你做深度研究↓研究结果自动保存到UserBank中午:ChatGPT基于上午的研究写报告↓报告要点更新到UserBank晚上:Cursor基于全天的工作写代码↓代码经验沉淀到UserBank每个AI都在前一个的基础上工作,而不是从零开始
真实场景:告别重复,让AI真正理解你
让我用一个每个人都会遇到的场景来说明:
昨天,你在ChatGPT里花了2小时讨论新项目的架构。今天,你想在Claude里继续深入一些技术细节。
没有UserBank的世界:
你:"Claude,我想继续讨论昨天的项目架构..."Claude:"什么项目?能详细介绍一下背景吗?"你:(深吸一口气,开始重复昨天说过的所有内容...)
有了UserBank的世界:
你:"继续昨天的架构讨论,我想深入聊聊微服务拆分"Claude:[通过MCP读取你的记忆]"我看到你昨天确定了用Event-Driven架构,现在我们来讨论如何基于业务边界进行服务拆分..."
看到区别了吗?你不用再费劲把昨天的背景重复一遍。AI已经知道你们聊到哪了,可以直接接上话。
技术架构:轻量但强大
UserBank Desktop基于Tauri 2.0构建
- 为什么选Tauri?因为它轻量、高性能、跨平台
- 安装包小,运行快,不会成为你电脑的负担
- Windows、Mac、Linux都能完美运行
UserBank Core使用Python开发
- 灵活、可扩展、易于理解
- 可以单独部署,不一定要和桌面应用绑定
- 完整的MCP支持,清晰的API设计
隐私设计:简单但有效
我特意设计了极简的隐私控制:
只有两个级别:公开(public)/ 私有(private)
为什么这么简单?因为:
- 认知负担最小化:你不需要为每条数据思考复杂的权限
- 决策快速:要么分享,要么不分享,没有中间状态
- 安全默认:新数据默认私有,你主动选择公开
更重要的是本地存储:
- 所有数据存在你的电脑上
- SQLite数据库,随时可以查看
- 支持完整导出,格式开放
- 没有任何云端同步
这意味着:即使UserBank项目消失了,你的数据依然完全属于你。
如何开始使用UserBank
UserBank Desktop是一个即下即用的桌面应用:
- 下载安装
- 访问 https://github.com/MixLabPro/userbank/releases
- 下载对应你系统的安装包
- 双击安装,就像安装其他软件一样简单
- 需要的前置条件
- 一个支持MCP的AI客户端(如Claude Desktop、Cursor)
- 这些AI工具会通过MCP协议连接到UserBank
- 开始使用
- 在UserBank中添加你的数据
- 在AI客户端中配置MCP连接
- AI立即就能访问你的完整认知档案
整个过程不超过5分钟。
面向未来:当AI真正理解你时会发生什么?
这是一个让我激动又谨慎的问题。
激动的是无限可能:
- AI不再是工具,而是真正的认知伙伴
- 你的数字智慧可以传承,甚至超越生命的界限
- 个性化达到前所未有的深度
- 创造力的爆发:AI基于你的完整认知模式,帮你突破思维边界
谨慎的是潜在风险:
- 数据安全的重要性前所未有
- 隐私保护需要更严格的标准
- 对AI依赖的边界在哪里?
- 如何保持人的主体性?
这就是为什么UserBank必须开源、必须本地存储、必须用户完全控制。因为只有这样,我们才能在享受AI带来的革命性体验的同时,保护好自己最宝贵的资产——我们的认知和智慧。
这不仅是工具,更是一场认知革命
我创建UserBank,是因为我相信:
在AI时代,你的认知数据是你最宝贵的资产。
它不应该被锁在任何平台里,不应该被任何公司控制。它应该像你的思想一样自由,像你的记忆一样私密,像你的智慧一样能够传承。
开源:因为这关乎每个人的未来
我选择开源,不仅是为了透明和信任,更是因为:
- 这是所有人的事业:数据主权不是我一个人的战斗
- 集体智慧:最好的设计来自社区的共创
- 标准的力量:只有开源才能成为真正的标准
- 风险共担:社区的眼睛是最好的安全保障
开源也意味着,即使有一天我不在了,UserBank依然属于所有人。
加入我们:一起打造AI时代的数据标准
UserBank不应该只是一个工具,它应该成为一个协议,一个标准。
就像HTTP定义了网页的传输,SMTP定义了邮件的发送,我希望UserBank能定义AI时代个人数据的存储和访问标准。
我们需要你的力量
如果你是开发者:
- 帮助完善UserBank Core的功能
- 开发新的数据类型和API
- 为不同编程语言创建SDK
- 贡献更好的加密和隐私保护方案
如果你是产品设计师:
- 优化用户体验,让数据管理更简单
- 设计新的数据可视化方案
- 创造更直观的隐私控制界面
如果你是AI应用开发者:
- 在你的应用中集成MCP支持
- 分享你的使用案例和最佳实践
- 帮助定义新的数据交互标准
如果你是普通用户:
- 使用UserBank,提供反馈
- 向朋友介绍这个理念
- 参与社区讨论,分享你的想法
具体行动
⭐ Star我们的项目:每一个Star都是对这个理念的支持
- UserBank Core: https://github.com/MixLabPro/userbank-core
- UserBank Desktop: https://github.com/MixLabPro/userbank
🚀 立即使用:下载UserBank,开始构建你的认知数字孪生
💡 贡献代码:Fork项目,提交PR,每一行代码都在改变未来
📢 传播理念:写文章、录视频、做分享,让更多人知道数据主权的重要性
"让AI真正理解你,从拥有你自己的数据开始。"
这是UserBank的使命,也是我们共同的未来。
6年前,我在《AI改变设计》中写道:"数据仓库需要定制更多的隐私规则防止用户数据泄露,以及定制开放协议实现多元创新,避免被巨头垄断。"
今天,UserBank就是这个答案。但它不应该只是我的答案,它应该是我们所有人的答案。
未来的AI不应该是巨头的AI,而应该是每个人的AI。未来的数据不应该是平台的资产,而应该是个人的财富。
这需要我们每个人的努力。无论你是谁,无论你会什么,你都可以为这个愿景贡献力量。
让我们一起,重新定义AI时代的游戏规则。
Join us. Own your data. Shape the future.
UserBank正在快速成长,每一天都有新的进展。关注我们的GitHub,加入我们的社区,成为这场革命的一部分。记住:在AI时代,掌控数据就是掌控未来。而这个未来,需要我们一起创造。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号