MoWE:混合气象专家模型


MoWE:混合气象专家模型

https://arxiv.org/abs/2509.09052
一、引言:数据驱动天气预报的发展与挑战
近年来,人工智能技术在气象预报领域取得了革命性进展。基于深度学习的天气预测模型,如FourCastNet、Pangu-Weather和GraphCast等,已经展现出超越传统数值天气预报(NWP)系统的潜力。这些模型通过分析历史再分析数据(如ERA5)学习大气动力学模式,能够以更低的计算成本生成高质量预报。
然而,随着研究的深入,这一领域开始面临性能提升的瓶颈。尽管不断有新模型提出,但它们在某些指标上的表现逐渐趋同,很难出现某个模型在所有变量、所有地区和所有预报时长上都明显优于其他模型的情况。这种性能饱和现象促使研究者开始思考新的突破方向。
传统数值天气预报领域早已认识到单一模型的局限性,发展了多模式集合预报系统,通过整合多个独立模型的预测结果来提高预报准确性和可靠性。受此启发,本文作者提出了一个新颖的思路:不追求训练一个更强大的单一模型,而是开发一个能够智能融合现有优秀模型输出的框架——混合气象专家模型(Mixture of Weather Experts, MoWE)。
MoWE的核心思想是承认不同模型在不同情境下各有优势,并通过学习算法动态地组合这些模型的输出,从而产生比任何单一模型都更准确的预报。这种方法不仅能够提升预报性能,还能以相对较低的计算成本实现这一目标,因为它不需要从头训练庞大的天气预报模型,而是利用已有的预训练模型作为"专家"。
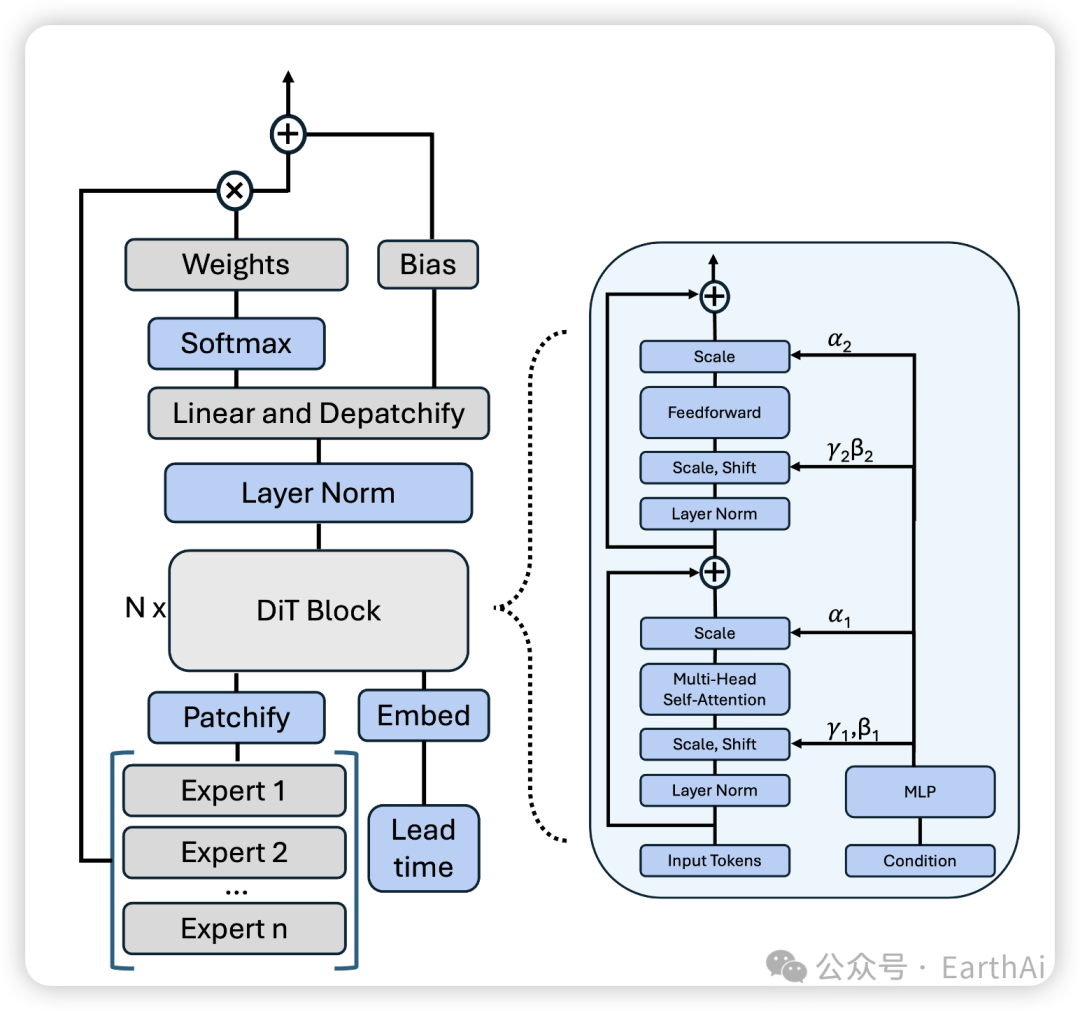
Figure 1: A diagram illustrating the architecture of the Mixture-of-Weather Experts (MoWE).
二、MoWE方法论深度解析
2.1 整体框架设计
MoWE采用了一种精巧的模型融合策略,其核心是一个基于Transformer架构的门控网络(gating network)。该系统接收多个专家模型的预测结果作为输入,并输出一组空间上变化的权重图,指示如何最佳地组合这些预测。
系统的数学表达如下:
Ŷ = Σ(i=1 to N)(W_i ⊙ E_i) + b其中E_i表示第i个专家模型的预测,W_i是对应的权重图,b是偏置项,⊙表示逐元素乘法。最终预测Ŷ是所有加权专家预测的总和加上偏置项。
这种设计的优势在于其灵活性和适应性。不同于静态权重分配(如简单平均),MoWE能够根据地理位置、气象变量和预报时长的不同,动态调整各专家模型的贡献程度。
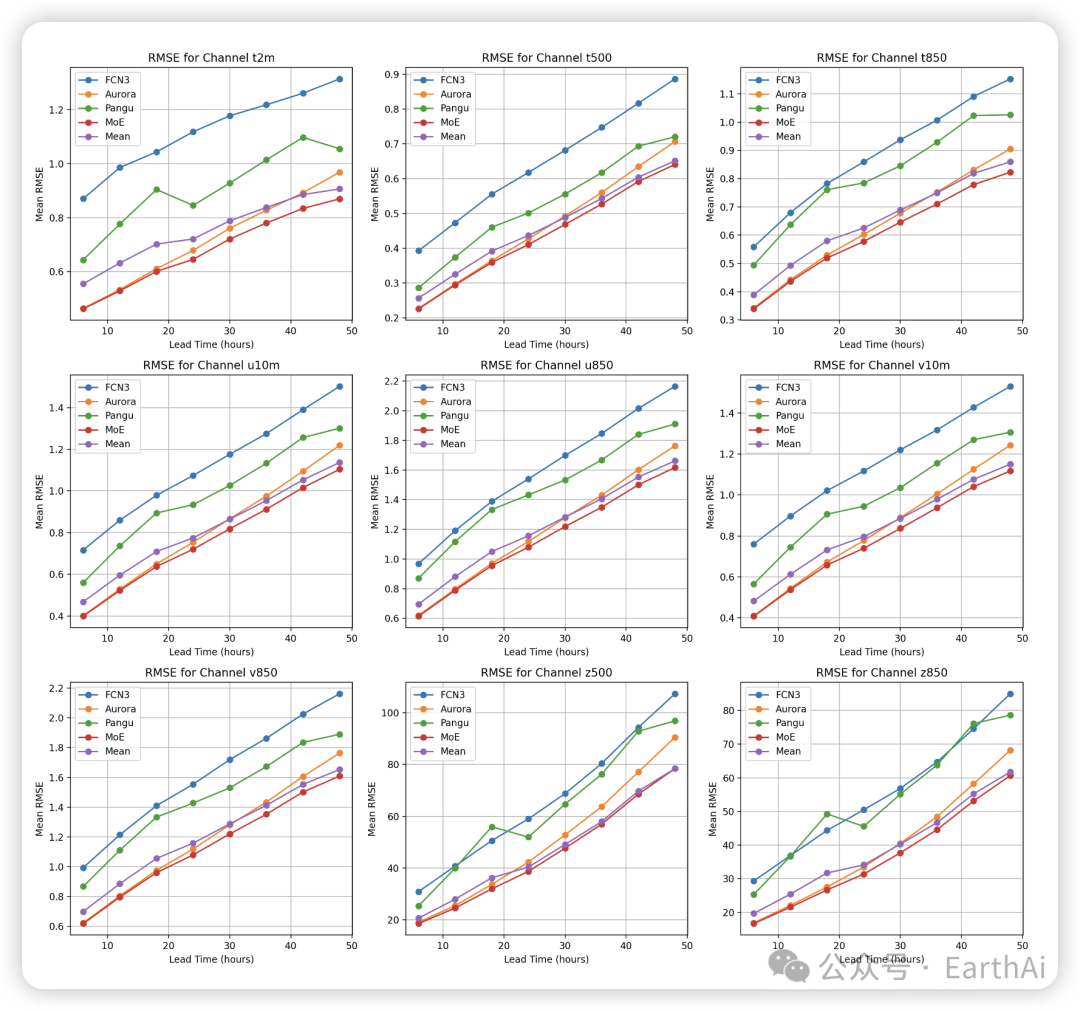
Figure 2: RMSE Comparison for Weather Forecasting Models.
2.2 门控网络架构
门控网络是MoWE的核心组件,其基于Vision Transformer(ViT)架构,专门设计用于处理气象场数据。该网络的输入是由所有专家模型的预测堆叠形成的多通道"图像",其中每个通道对应一个专家模型对一个气象变量的预测。
网络的处理流程如下:
- 1. 输入预处理:将多个专家的预测结果沿通道维度拼接,形成高维张量
- 2. 分块嵌入:将输入图像划分为固定大小的 patches,并通过线性投影转换为序列形式
- 3. 位置编码:为每个patch添加位置信息,保留空间结构
- 4. Transformer编码:通过多层Transformer块处理序列数据,捕获远程依赖关系
- 5. 输出投影:将处理后的序列映射回原始空间维度,生成权重图和偏置项
门控网络还引入了条件机制,使权重生成过程能够考虑预报时长信息。这是通过自适应层归一化(Adaptive Layer Normalization)实现的,该技术将预报时长信息作为调制参数,影响网络中的特征标准化过程。
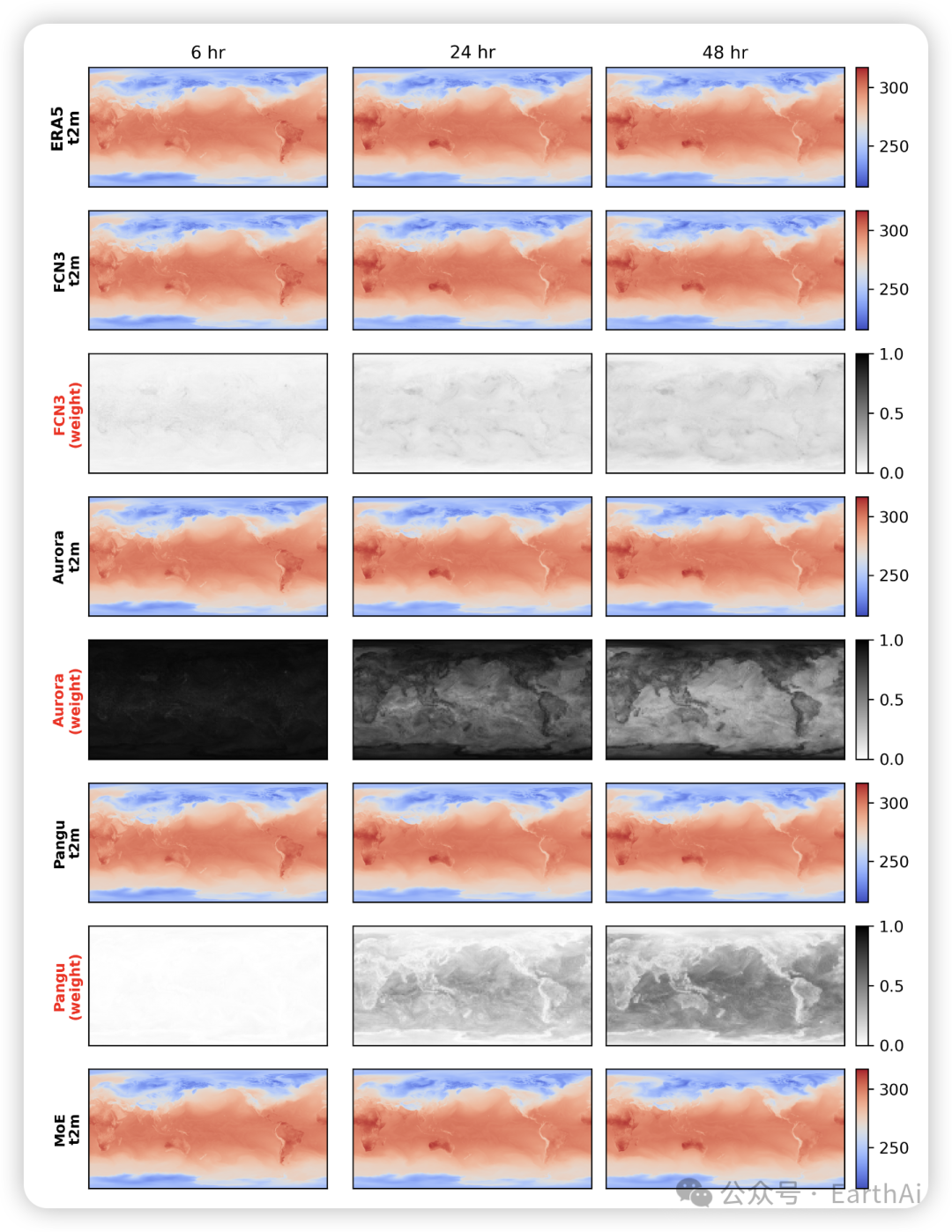
Figure 3: This image displays 2 m temperature (K) for ERA5, forecasts at 6-hour, 24-hour, and 48-hour from various models ( FCN3, Aurora, Pangu, and MoWE) along with the learned weights for FCN3, Aurora, and Pangu in the MoWE.
2.3 专家模型选择策略
作者精心选择了三个具有代表性的天气预报模型作为MoWE的专家:
- 1. Pangu-Weather:采用3D神经网络结构,将大气视为三维数据立方体,能同时捕获垂直和水平方向的气象模式。其训练采用分层时间聚合策略,为不同预报时长训练专门化的模型。
- 2. Aurora:基于Swin Transformer架构,结合Perceiver编码器-解码器设计,能够处理多样化的大气数据。采用两阶段训练策略:先在ERA5和模拟数据上进行预训练学习通用大气动力学,然后针对特定任务(如高分辨率预报)进行微调。
- 3. FCN3:使用球形神经算子和隐马尔可夫模型生成概率性预报。通过采样不同噪声实现生成集合预报,训练目标是最小化连续排名概率得分(CRPS)。虽然其确定性指标略逊于前两者,但集合预报技能领先。
这些模型在架构、训练目标和预报特性上各有不同,提供了互补的优势,为MoWE的有效融合奠定了基础。
2.4 训练策略与数据流程
MoWE的训练过程经过精心设计,以最大限度地利用可用数据同时控制计算成本。训练数据涵盖1980-2014年期间的ERA5再分析数据,使用2015年数据作为测试集。
训练流程的关键特点:
- • 专家模型的预测是预先计算并存储的,大大减少了训练时的计算需求
- • 采用随机采样策略,从不同初始条件和预报时长中抽取批次数据
- • 损失函数使用均方误差(MSE),直接优化预报准确性
- • 支持自回归推演,可在每个时间步动态融合专家预测
这种设计使得MoWE能够以相对较小的计算成本实现性能提升,只需要训练轻量级的门控网络而不是庞大的天气预报模型。
三、实验设计与分析
3.1 实验设置
作者设计了全面的实验来评估MoWE的性能。实验涵盖了多个气象变量(温度、风速、位势高度等)和预报时长(6小时至48小时),并与以下基线方法进行比较:
- • 各个专家模型的单独性能
- • 简单平均融合策略
- • 不同规模的MoWE变体(Base和Small)
评估指标主要使用均方根误差(RMSE),这是气象预报中广泛使用的准确性度量标准。所有实验均使用2015年的数据作为测试集,确保结果的可比性和可靠性。
3.2 结果分析
MoWE在所有测试变量和预报时长上都表现出了一致性的性能提升。具体而言:
短期预报(6小时):MoWE的性能接近最佳专家(Aurora),权重重心明显偏向该模型。这反映了Aurora在短期预报上的优势,也表明门控网络能够正确识别这种优势。
中期预报(24-48小时):MoWE展现出最显著的性能提升,RMSE比最佳单一专家低达10%。权重分布变得更加均衡,表明多个专家在这个时间尺度上都提供了有价值的信息。
变量间比较:MoWE对所有测试变量都带来了改善,但对不同变量的改善程度有所不同。这表明门控网络能够学习到变量特定的融合策略。
3.3 权重可视化分析
通过对学习到的权重进行可视化分析,作者发现了几个有趣的现象:
- 1. 时间依赖性:权重分布随预报时长变化,短期偏向Aurora,中长期更加均衡
- 2. 空间模式:权重分布展现出地理相关性,如沿海地区和内陆地区的模式不同
- 3. 物理一致性:权重分布与已知的气象现象(如风暴路径、高压系统)存在关联
这些发现表明,MoWE不仅仅是在进行数学上的优化,而是在学习 physically-informed 的融合策略,能够根据气象系统的实际行为调整各专家的贡献。
3.4 模型规模消融实验
作者通过训练不同规模的MoWE模型(Base-25M参数和Small-9M参数)来研究模型容量对性能的影响。结果显示,Base模型相比Small模型有轻微但一致的性能提升,表明更大的容量有助于学习更精细的融合策略。
然而,即使是参数较少的Small模型也显著优于所有基线方法,这表明MoWE框架的有效性主要来自于其设计理念而非单纯的模型容量。这一发现尤其重要,因为它意味着MoWE可以在计算资源有限的环境中仍然提供性能提升。
四、讨论与启示
4.1 方法论贡献
MoWE代表了天气预报范式的重要转变:从追求单一的"最佳模型"转向协同利用多个模型的优势。这种方法有以下几个重要贡献:
- 1. 性能提升:通过智能融合多个专家模型的输出,MoWE实现了显著且一致的预报准确性改善
- 2. 计算效率:相比于训练新的天气预报模型,MoWE只需要训练轻量级的门控网络,大大降低了计算成本
- 3. 可扩展性:框架设计允许轻松集成新的专家模型,随着更多优秀模型的涌现,MoWE的性能有望进一步提升
- 4. 可解释性:通过学习到的权重分布,可以洞察各专家模型在不同情境下的相对优势,为模型改进提供指导
4.2 实际应用价值
MoWE不仅具有学术价值,还有重要的实际应用潜力:
- 1. 业务预报系统:MoWE可以集成到业务预报流程中,通过组合多个操作模型的输出提高预报准确性
- 2. 资源优化:通过选择性地使用专家模型(例如在某些区域或情况下跳过计算昂贵的模型),可以在保持性能的同时减少计算资源需求
- 3. 模型评估:权重分析可以为模型开发提供反馈,帮助识别各模型的优势和劣势区域
- 4. 不确定性量化:通过扩展概率性版本,MoWE有可能提供更可靠的不确定性估计
4.3 局限性与未来方向
作者也坦诚讨论了MoWE当前的局限性以及未来的改进方向:
当前局限性:
- • 依赖预计算的专家预测,限制了滚动预报的长度
- • 专家和变量数量增加时,简单的通道拼接策略可能变得不可行
- • 目前只考虑了确定性预报,尚未充分利用概率性信息
未来方向:
- • 开发在线训练版本,实时生成专家预测而非依赖预计算结果
- • 引入压缩机制(如Perceiver IO)处理高维输入
- • 扩展至概率性预报框架,提供不确定性信息
- • 纳入传统数值天气预报模型作为专家,实现数据驱动与物理模型的融合
五、结论与展望
MoWE代表了一种新颖且有效的天气预报范式,通过智能融合多个专家模型的输出,实现了显著的性能提升。该方法的核心优势在于其能够根据具体的气象情境动态调整各专家的贡献,从而产生比任何单一模型都更准确的预报。
这项工作的重要意义不仅在于其具体的性能提升,更在于它为我们提供了应对数据驱动天气预报性能平台期的新思路。随着优秀天气预报模型数量的不断增加,如何协同利用这些模型的能力将变得越来越重要。MoWE为此提供了一个可行的技术路径。
展望未来,MoWE框架有几个有前景的发展方向。首先是扩展至概率性预报,通过利用专家模型的不确定性信息提供更可靠的预报产品。其次是集成传统数值天气预报模型,实现数据驱动方法与物理模型的优势互补。最后是开发更高效的门控机制,适应不断增长的专家数量和气象变量。
总之,MoWE标志着天气预报研究从"模型竞争"向"模型协作"的重要转变,为下一代天气预报系统的发展指明了方向。通过社区共同努力和模型间的智能协作,我们有望构建更加准确、可靠和高效的天气预报能力,更好地服务社会和经济需求。
END
声明:欢迎转载、转发。气象学家公众号转载信息旨在传播交流,其内容由作者负责,不代表本号观点。文中部分图片来源于网络,如涉及内容、版权和其他问题,请联系小编处理。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号