DeepSeek-V4-Flash 本地部署,2 x H20(96GB版本),性能简测

DeepSeek-V4-Flash 本地部署,2 x H20(96GB版本),性能简测

Ai学习的老章
发布于 2026-05-08 12:16:04
发布于 2026-05-08 12:16:04
继续看看 V4,本文看下 DeepSeek-V4-Flash 本地部署
我的设备
- CPU:Intel Xeon Platinum 8457C
- 内存:480 GiB
- GPU:2 x NVIDIA H20,单卡显存 96 GB
- 驱动版本:580.126.09
- CUDA 版本:13.0
- 系统盘:100G
- 数据盘:1T
1、模型下载
模型文件 160GB
国内网络,模型下载
modelscope download --model deepseek-ai/DeepSeek-V4-Flash --local_dir /data/models/DeepSeek-V4-Flash
2、vLLM Docker 镜像准备
安装vllm-nightly我从没有成功过,只有Docker最省心
docker pull vllm/vllm-openai:deepseekv4-cu129
3、启动脚本

大家也看到了,即便是 Flash,能跑得起的设备也很少,AMD 全军覆没
看了几个 issues,消费级英伟达显卡也都不配
上面的启动脚本我的 2xH20 自然也不配,启动 N 次,都是 OOM
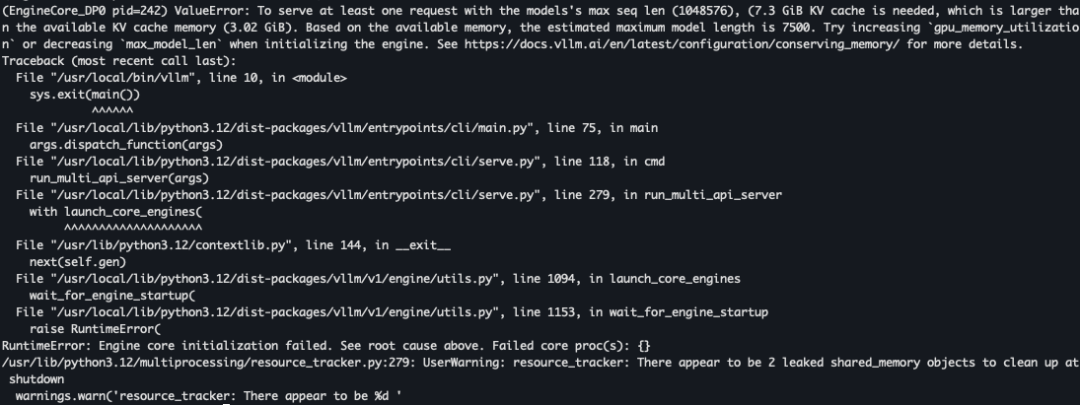
不断试错之后,实际使用的脚本:
docker run -d \
--name vllm-deepseek-v4-flash \
--restart unless-stopped \
--gpus all \
--privileged \
--ipc=host \
-p 8000:8000 \
-v /data/models:/models:ro \
-e VLLM_ENGINE_READY_TIMEOUT_S=3600 \
vllm/vllm-openai:deepseekv4-cu129 \
/models/DeepSeek-V4-Flash \
--trust-remote-code \
--kv-cache-dtype fp8 \
--block-size 256 \
--enable-expert-parallel \
--data-parallel-size 2 \
--gpu-memory-utilization 0.95 \
--max-model-len 7000 \
--tokenizer-mode deepseek_v4 \
--tool-call-parser deepseek_v4 \
--enable-auto-tool-choice \
--enforce-eager
模型默认 max seq len 是 1048576,完全搞不动,所以我这里 --max-model-len 只设 7K
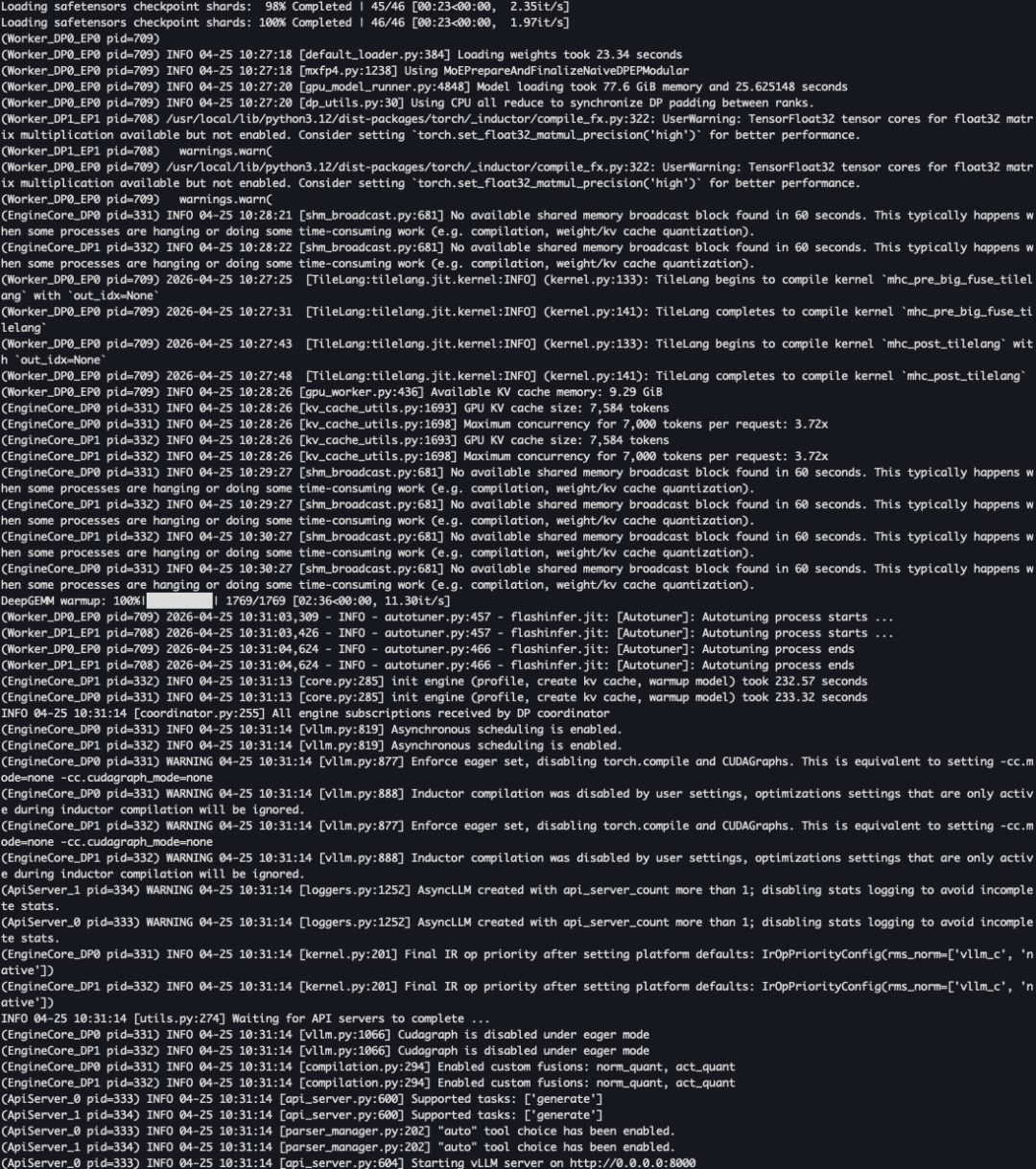
启动正常,几个日志关键信息分享一下:
1、模型原始 Safetensors 权重文件高达 148.66 GiB(EXT4 文件系统显示的 size),但在启用 FP8 量化 和 Expert Parallelism(EP) 后,单个 Worker 进程(Rank)加载的权重被压缩到了 77.6 GiB
2、扣除权重和系统预留后,只剩下了约 9.29 GiB 用于缓存
3、并发能力,日志显示 Maximum concurrency for 7,000 tokens perrequest: 3.72x。这意味着在长文本(7k tokens)情况下,系统仅能支持约 3.72 个并发请求
4、模型总共有 256 个专家,通过并行配置,每个 Worker 维护 128 个。这样做既利用了多卡的算力,又分摊了专家权重的显存压力
5、日志显示 Using DeepSeek's fp8_ds_mla KV cacheformat。这是 DeepSeek 的“独门绝技”,通过低秩压缩技术(Multi-head Latent Attention),在 FP8 模式下极大地缓解了内存带宽压力(扩展阅读:DeepSeek 开源周,完结,撒花)
6、日志还可以看到 TileLang 完成了 mhc_pre_big_fuse_tilelang 等内核的编译
7、启动速度:整个引擎初始化(Profile + Cache 创建 + Warmup)耗时约 233 秒。对于这种规模的模型,这个速度表现尚可,大部分时间花在了 DeepGEMM warmup(2 分 36 秒)
性能情况
效果就别追求了,看看性能
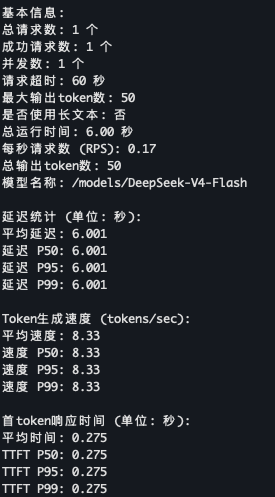
平均生成速度 8.33!!!遥遥领先的卡吗?
哦哦,不对是 H20
难以置信,要知道我测试 Qwen3.5/3.6 本地部署,4090 都是 150t/s 的啊
关闭思考
查了一下 DeepSeek API 文档,可以关闭思考

写了一个脚本再测、,对比思考与非思考下性能,各跑 10 次取平均,同样的 prompt,max_tokens=1024
结果如下:

后续更新:启动脚本DP改成TP 关闭enforce-eager模式 速度来到 20Token/s 关闭思考之后生成速度甚至可以到70+,还不错!我要继续调试一下,看能否再提升!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号