企业为什么必须构建自己的 Skills 体系

企业为什么必须构建自己的 Skills 体系

AI智享空间
发布于 2026-05-15 19:59:00
发布于 2026-05-15 19:59:00
有一家做了十年企业服务的公司,去年花了大价钱买了一套“AI 测试平台”。
用了三个月,业务测试负责人来找我说了一句话:“工具挺聪明的,但它不认识我们。”
这句话我反复想了很久。那套平台的 AI 能力并不弱——它能生成用例、能分析覆盖率、能给出回归建议。但每一次输出,都需要工程师花大量时间“纠偏”:删掉那些不符合业务逻辑的用例,补上那些 AI 不知道的历史坑,调整那些跟团队习惯完全不搭的格式……
效率反而不如从前。
这家公司踩的坑,背后有一个清晰的原因:他们在用一个通用的 AI,处理一个高度特异化的业务。两者之间,缺少一座桥梁。这座桥梁,就是企业自己的 Skills 体系。
这篇文章想说清楚一件事:在 AI 工具已经触手可及的今天,企业真正的护城河不是“用不用 AI”,而是“有没有把自己的知识和经验,系统性地注入 AI 的决策过程”。
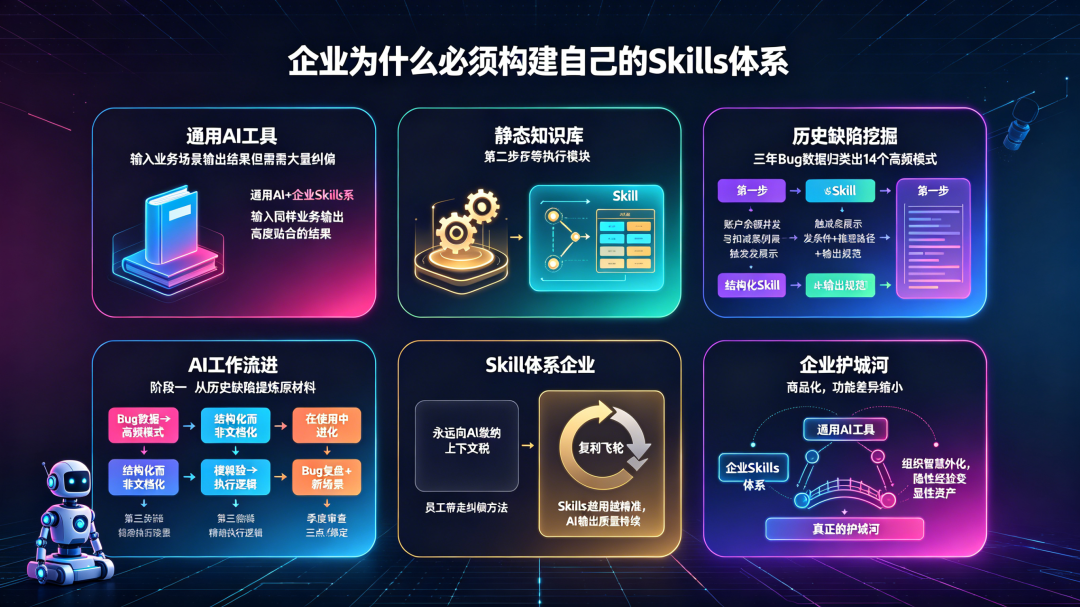
一、通用 AI 的天花板:它永远不够“懂你”
1.1 通用能力与特异业务之间的结构性鸿沟
今天的大模型能做的事情已经很多——写代码、生成文档、分析日志、设计方案。但凡是跟“你们公司”有关的事情,它就开始力不从心。
原因很简单:它的训练数据里没有你们的业务规则、没有你们踩过的坑、没有你们系统特有的边界条件。
拿测试场景举例。一个通用 AI 知道“支付模块要测幂等性”,但它不知道:
- 你们的支付系统有一个特殊的“预扣款”状态,在这个状态下的重试逻辑跟正常支付完全不同
- 你们曾经因为某个第三方回调的编码问题踩过一个大坑,那个场景必须单独覆盖
- 你们的测试用例需要按照某个内部模板输出,才能直接导入 Jira
这些东西,没有人告诉它,它不会知道。通用 AI 给你的,是行业的平均水平。而你们团队积累的,是超越平均水平的特异价值。
1.2 “纠偏成本”吞噬了 AI 带来的效率红利
很多企业引入 AI 工具之后,发现实际体验跟预期有落差——不是 AI 不够聪明,而是“纠偏”这件事本身消耗了大量人力。
生成 100 条用例,要删掉 30 条不符合业务的,要补上 20 条 AI 遗漏的,要改掉 15 条格式不对的……最终的净收益远低于预期。
这不是 AI 工具的问题,这是使用方式的问题。没有 Skills 体系的 AI,只是一个聪明的外包,而不是一个懂业务的同事。
二、Skills 体系是什么:不是知识库,是“可运行的经验”
2.1 一个关键的概念区分
很多人听到“构建 Skills 体系”,第一反应是“哦,就是整理一个知识库嘛”。这个理解差了一个量级。
知识库是静态的——它存放信息,等着人去查。Skills 是动态的——它封装判断逻辑,可以被调用、被执行、被集成到工作流里。
打个比方:知识库是一本食谱书,Skills 是一个会做饭的厨师。前者告诉你怎么做,后者直接给你端上来一道菜。
一个结构完整的 Skill,包含三个核心要素:
- 触发条件:什么情况下这个 Skill 应该被激活(例如:当接口有写操作且业务存在重试机制时)
- 推理路径:在这个情况下,应该按什么逻辑思考和决策(例如:识别幂等约束 → 构造重复请求 → 验证预期行为)
- 输出规范:最终产出什么格式的结果(例如:符合公司模板的测试用例,包含优先级标注)
这三要素缺一不可。缺了触发条件,Skill 没有人知道什么时候用;缺了推理路径,Skill 变成了结论的罗列;缺了输出规范,Skill 产出的东西还是需要大量二次加工。
2.2 Skills 体系的价值:把人的判断力变成组织的资产
一个企业积累的测试经验,本质上住在两个地方:人的脑子里,和历史 Bug 记录里。
前者随人员流动而流失,后者因为格式混乱而难以复用。
Skills 体系做的事情,是把这两个地方的价值结构化地萃取出来,让它以一种可以被 AI 直接调用的形式存在于组织层面,而不再依附于某几个关键人。
这不是工具问题,这是组织能力的重构。
三、一个完整的案例:某金融科技公司的 Skills 落地实践
3.1 背景:高速扩张带来的质量隐患
某金融科技公司,业务团队从 50 人扩张到 200 人,时间不到两年。测试团队的规模同步扩大了三倍,但线上事故的频率并没有同比下降——反而出现了一个让人不安的趋势:新加入的测试工程师,总是在重复踩老工程师几年前踩过的同一批坑。
根本原因是:老工程师的经验没有被系统化地传递下去。
3.2 第一步:找到最有价值的“经验结晶点”
他们做的第一件事,不是立刻开始搭建 Skills,而是花了两周时间做了一件很朴素的事:把过去三年所有标注为“本可避免”的线上 Bug 捞出来,分类整理。
最终归纳出 14 个高频缺陷模式,覆盖了超过 60% 的历史漏测场景。
这 14 个模式,就是他们第一批 Skills 的原材料。
3.3 第二步:将缺陷模式结构化为 Skills
以其中一个为例:账户余额并发扣减问题。
历史上,这个问题导致过两次线上资损。每次复盘的结论都是“并发场景测试覆盖不足”。但这个结论太模糊,新人不知道“并发场景”具体指什么、怎么测。
他们把它结构化为一个 Skill:
【触发条件】 当接口涉及账户余额变更(扣款、充值、转账), 且业务场景存在用户可能发起多次操作的情况时触发。 【推理路径】 1. 识别余额变更的加锁机制(数据库行锁 / 分布式锁 / 乐观锁) 2. 根据加锁机制构造对应的并发压力测试场景: - 数据库行锁:同一账户,10线程并发扣款,验证最终余额正确性 - 乐观锁:同一账户,并发请求中验证版本号冲突的处理逻辑 3. 验证余额不足时的并发行为(是否会出现负数余额) 【输出规范】 必须包含3个用例:正常并发扣款、余额不足并发、混合并发(部分成功部分失败) 优先级:全部标注 P0这个 Skill 任何人看完都知道:在什么情况下触发、按什么步骤测、最终交付什么。
3.4 第三步:接入 AI 工作流,验证效果
将这 14 个 Skills 配置为 AI 工作流的上下文之后,他们做了一次对照实验:
- 用“纯通用 AI”生成某新功能的测试用例:耗时 20 分钟,人工纠偏 40 分钟,最终合格率约 55%
- 用“AI + Skills 体系”生成同一功能的测试用例:耗时 15 分钟,人工纠偏 10 分钟,最终合格率约 82%
更重要的是,后者在并发场景、余额边界、异常状态处理等历史高风险区域的覆盖,几乎不需要人工补充——因为那些判断逻辑,已经被编码进了 Skills 里。
四、企业构建 Skills 体系的三个阶段
4.1 阶段一:从历史缺陷中提炼原材料
不要从零开始想“我们应该有哪些 Skills”。这条路会让你陷入无休止的讨论。
正确的起点是:让 Bug 数据告诉你答案。
拉出过去一到两年内所有标注为“漏测”或“可避免”的线上问题,按照业务模块归类,找出重复出现的缺陷模式。这些模式,就是最值得被 Skill 化的候选项。
通常,20% 的缺陷模式覆盖了 60% 以上的漏测风险。先把这 20% 搞定,你的 Skills 体系就已经能产生可观的价值。
4.2 阶段二:结构化,而不是文档化
把缺陷模式变成 Skill,最容易犯的错误是写成文档——洋洋洒洒几百字,告诉读者“要注意并发问题”。
文档是给人读的,Skill 是给 AI 调用的。
结构化的要求:触发条件必须明确到“什么接口类型 + 什么业务场景”,推理路径必须是可操作的步骤序列,输出规范必须明确到用例格式和优先级标注规则。
这个过程很考验人——它要求你把模糊的“经验感”翻译成精确的“执行逻辑”。但这个翻译的过程本身,就是一次极有价值的团队知识沉淀。
4.3 阶段三:让 Skills 在使用中进化,而不是在维护中腐化
Skills 体系最大的敌人,不是构建难度,而是腐化速度。
解决方案只有一个:把 Skills 的更新,嵌入到已有的工作节点,而不是单独设立维护任务。
具体来说:
- 每次 Bug 复盘,结论中必须包含“对应哪个 Skill 需要更新”
- 每个新功能上线后的测试总结,必须包含“发现了哪些 Skill 未覆盖的新场景”
- 每季度做一次 Skills 有效性审查,删除过时的,合并冗余的,补充缺失的
这样,Skills 体系就变成了一个随业务生长的活体,而不是一个随时间死去的文档。
五、两种企业,两种未来
5.1 没有 Skills 体系的企业:永远在重复纳贡
没有 Skills 体系的企业,在 AI 时代的处境是这样的:
每次用 AI,都要花大量时间向它解释你们的业务背景。每一次新项目、新功能,这个解释过程重新来一遍。AI 产出的内容,每次都需要大量纠偏才能使用。员工离职,带走的不只是人,还有那套帮 AI 纠偏的方法。
这不是在使用 AI,这是在持续向 AI 缴纳“上下文税”。
5.2 有 Skills 体系的企业:构建复利飞轮
有 Skills 体系的企业,经历的是另一套逻辑:
第一批 Skills 建立后,AI 的输出质量立刻提升,纠偏成本下降。节省下来的时间,有一部分用于持续优化 Skills。Skills 越来越精准,AI 的输出越来越贴合业务。新人入职,依靠 Skills 驱动的 AI 辅助,上手速度大幅提升……
这是一个正向的复利飞轮。它的起点不高,但它会越转越快,而且对手很难在短期内复制——因为 Skills 体系沉淀的,是你们团队真实积累的业务经验,这不是买来的,也不是抄来的。
结语:AI 时代,真正的护城河是什么
AI 工具正在快速商品化。两年后,市面上的 AI 测试工具、AI 开发工具、AI 运营工具,功能差异会越来越小,价格会越来越透明。
在那个时代,谁的 AI 用得好?
不是买了最贵工具的企业。是那些把自己的业务知识、团队经验、历史教训,系统性地注入了 AI 决策过程的企业。
Skills 体系,本质上是一种组织智慧的外化。它让企业多年积累的隐性经验,变成一种可以被机器调用、可以被新人继承、可以跨团队复用的显性资产。
这件事越早做,复利越大。越晚做,追赶成本越高。
现在,你们团队的经验,住在哪里?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号