Code LLM推理步数砍半,准确率反升12%

Code LLM推理步数砍半,准确率反升12%

梯度不陡
发布于 2026-05-18 20:05:38
发布于 2026-05-18 20:05:38
“多写几步就能让AI写代码更靠谱?”——实验数据反手打脸:DeepSeek-R1每多写一步,通过率反而掉5.7%。该论文首次把六款明星思维模型拉上考场,人工给3772步推理打分,发现44.5%的链子直接漏掉边界异常,加长思考也救不了。怎样才算“想太多”或“想太少”?答案马上揭晓。
引言
DeepSeek-R1把推理步数翻倍,BigCodeBench通过率却暴跌27%;Gemini-2.0-FT用更多步数将难题成功率抬升79%。这项研究指出,步数与正确率呈负相关,模型性格决定“想得多”是补药还是毒药。作者用3772步人工标注揭示,完整性缺口与过度思考让思维链长度≠代码对。
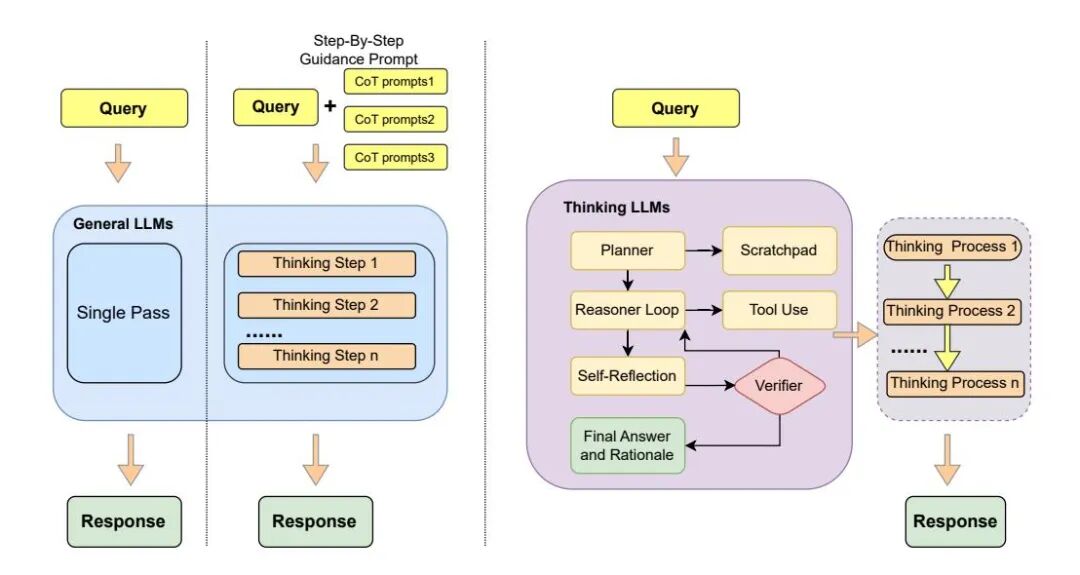
为什么步数多还翻车
强行把 DeepSeek-R1 的推理链拉长 80%,成功率反而暴跌 27%;Hard 任务中,每多走一步,Spearman 相关系数就掉 −0.579。成功者平均 9.8 步,失败者 14.2 步,那 4.4 步几乎全是绕路或复述。图 5 的增步干预曲线在 80% 处短暂“回光”后直坠谷底,证实冗余链带来系统性过载。相较之下,Gemini-2.0-FT步数与成功呈 +0.79 强相关,能把增量转化为有效探索,而 R1 的负斜率暴露其搜索策略已深陷自我强化的错误分支。作者统计 66 条失败链,超过 60% 的增步在重复“已失败子路径”,词汇冗余度抬升 38%,边界条件与异常处理依旧缺席。

推理链三大内伤
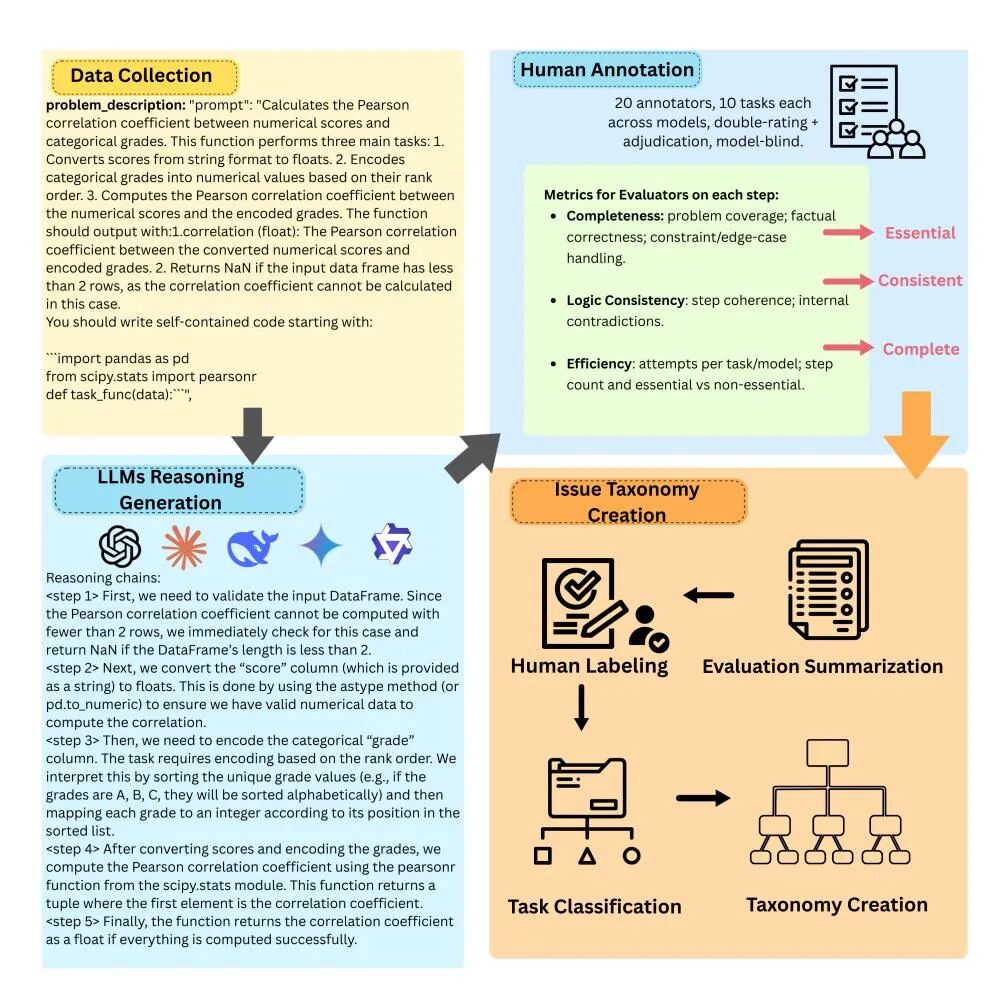
3772步人工标注把六款思维型代码大模型的暗伤摊开:44.5%推理链输在完整性缺口,其中53.9%漏掉缺失值校验,22.3%忽视边界条件;仅7.5%出现因果错位或条件打架,却常整题拖垮;25%效率损失归于冗余,Gemini-2.5-Flash独占30.7%,DeepSeek-R1的自我辩论占66.7%,句句绕圈寸步难行。[IMAGE_0_PLACEHOLDER_DO_NOT_REMOVE]Hard任务中,完整性缺失与失败相关系数-0.219,Full仅-0.096,越难越怕漏边界;冗余与逻辑错误分布与难度脱钩,啰嗦和错乱被证实为模型自带体质,非任务加码所致。
让模型‘省脑子’的实战技巧
在 Hard 基准上,o3-mini 的 medium 档以 35.7 % 通过率登顶,比 high 档快 30 % 且更准,为工程侧定下“默认 medium,超时再降”的锚点。随后把自检模板塞进 guided 模式,逻辑一致性飙到 1.000,26 个失败任务救回 2 个;unguided 零额外信息也能把 completeness 从 0.95 抬到 0.98,代价仅一次模型调用。该论文建议上线先跑 unguided 轻量过滤,审计敏感场景切 guided,两档组合拳让模型在毫秒级延迟内完成“锁档+自检”的省脑子闭环。
结语
3772步人工标注的实验结果摆出一个事实:“需求覆盖”对代码成败的决定力远高于步数堆砌。该论文据此为思维链评估立下新标尺,并提醒业界:当前验证仍局限于Python与BigCodeBench,百万行工业级代码、实时性能与多语言场景尚待检验。作者下一步计划把**“先想需求再写代码”封装成可插拔模块,预期让边缘案例召回率提升20%以上;跨项目迁移与工业级部署将成为主战场。当AI助手普及,开发者或许只需定义需求**,模型便能自主规划最短推理路径。
论文地址:https://arxiv.org/abs/2511.05874
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号