从 KL 的方向看 SFT 与 RL:模型到底是在"学会做",还是在"学会选"

从 KL 的方向看 SFT 与 RL:模型到底是在"学会做",还是在"学会选"

小陡坡香菜
发布于 2026-05-19 18:13:57
发布于 2026-05-19 18:13:57
最近在看RL相关的几篇论文,发现和KL关联紧密,然后就深入看了下KL,Reverse KL与SFT,RL的对应关系,结合与ChatGPT的交互思考,整理文章如下。
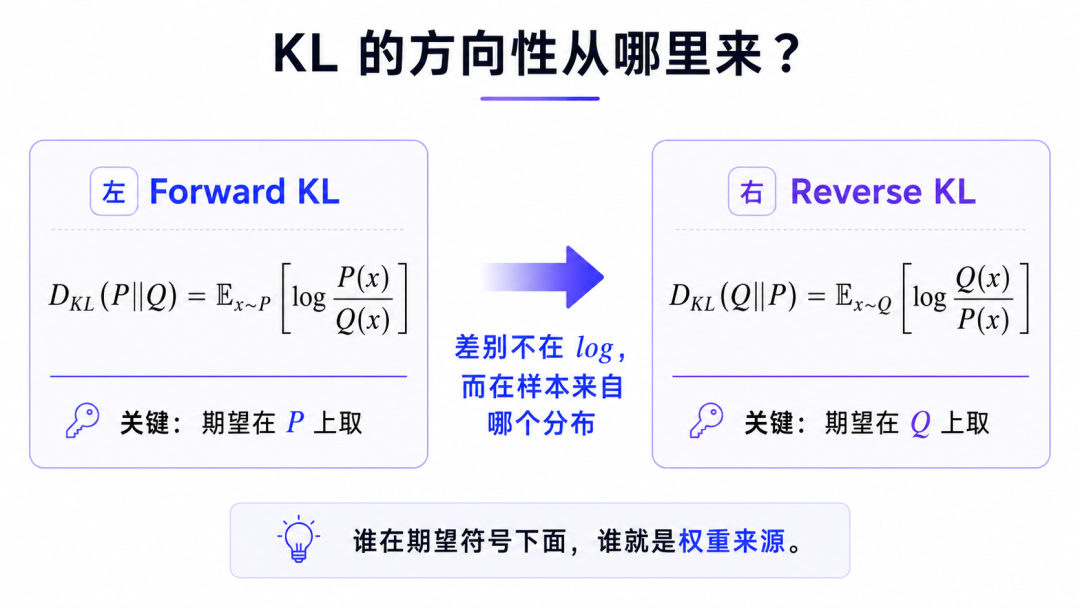
如果只看公式,KL 散度很容易让人困惑。它明明长得像两个分布之间的距离,却又不满足对称性:
方向一换,训练行为就完全不同了。
如果把这个方向性放到大模型后训练里有更明显的映射关系。SFT 为什么常被理解成 Forward KL?RL / RLHF 为什么又更接近 Reverse KL?on-policy distillation 为什么和传统蒸馏不一样? 这些问题背后,其实都在问同一件事:
期望到底是在谁的分布上取的?
也就是:样本从哪里来?轨迹由谁产生?模型是在解释别人的答案,还是在修正自己生成出来的答案?
要回答这几个问题,我们需要先从理解 KL 散度的方向性开始。
先理解 KL:方向来自"期望在哪个分布上取"
KL 散度的基本形式是:
离散情况下展开就是:
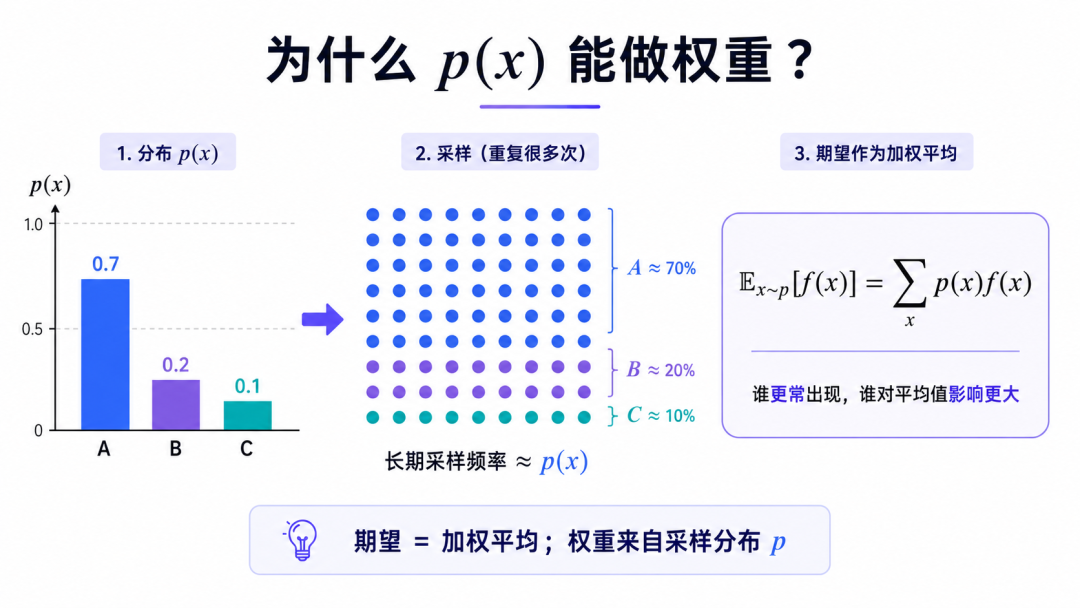
理解这个公式方向的关键因素是 。
它的意思不是随便比较 和 ,而是:
从 这个分布里采样 ,然后计算 的均值。
所以 会出现在求和式前面,成为每个位置的权重。
这不是因为 额外被赋予了权重身份,而是因为样本本来就是从 中来的。某个 在 里越常出现,它在长期采样平均中出现得就越多,对最终 KL 的影响也就越大。
换句话说:
谁在期望符号下面(下标位置),谁就是权重来源。
如果写的是 ,那就是在 上取期望,重点关注 会采样到的地方。
如果写的是 ,那就是在 上取期望,重点关注 会采样到的地方。
这就是 KL 非对称性的根源。
差异不在 本身,而在样本来自哪个分布。
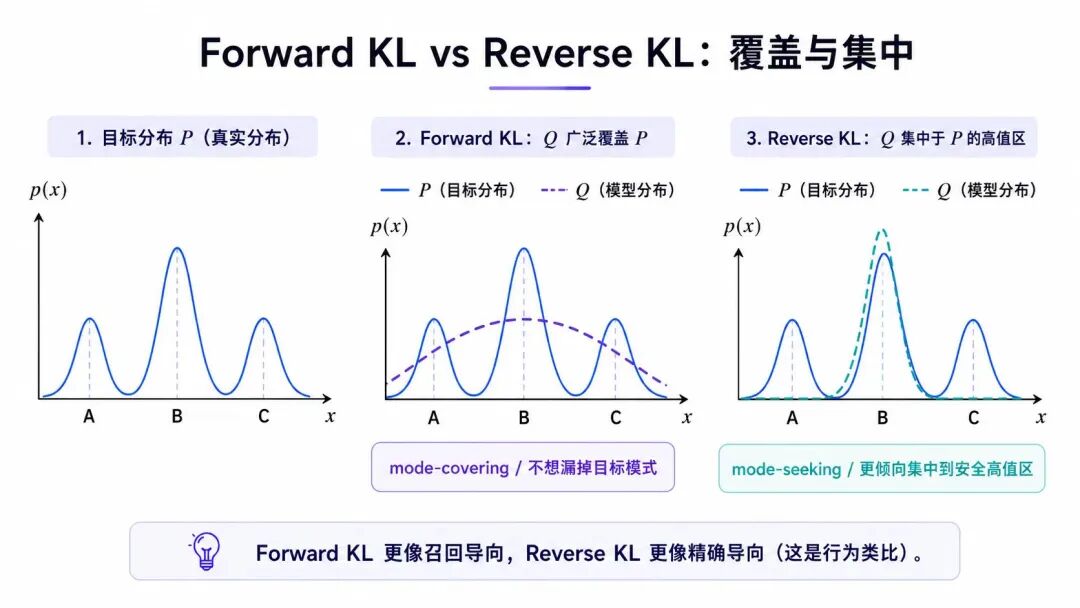
Forward KL:目标有的,模型别漏掉
如果我们把 看成目标分布,把 看成模型分布,那么:
就是 Forward KL。
它问的问题是:
目标分布 会出现的地方,模型分布 有没有覆盖到?
如果某个位置 ,但 ,那么惩罚会非常大。因为目标分布认为这个地方会出现,但模型几乎不给概率。
所以 Forward KL 最害怕的是:
目标有,模型没有。
这会带来一种典型训练倾向:
尽量覆盖目标分布里的所有模式。
如果目标分布里有 三种合理答案模式,Forward KL 会倾向于让模型都学到。哪怕某些模式不够优雅、不够高奖励,只要它们在数据分布里出现过,模型就会被推动去覆盖。
所以 Forward KL 经常被称为:
- • mode-covering
- • mass-covering
如果用检索里的直觉类比,它更像"重召回"。
它关心的是:
别漏掉目标分布里的东西。
但这个类比只是帮助理解,不能严格等同于分类指标里的 recall。
Reverse KL:模型生成的,目标要认可
反过来看Reverse KL:
如果 是模型分布, 是目标分布,那么这就是 Reverse KL。
它问的问题变成:
模型自己会生成的地方,目标分布 是否认可?
如果某个位置 ,但 ,那么惩罚会非常大。因为模型跑到了目标分布不支持的区域。
所以 Reverse KL 最害怕的是:
模型有,目标不认可。
这会带来另一种训练倾向:
与其覆盖所有可能模式,不如集中到少数更安全、更高价值、更被目标分布认可的模式上。
如果目标分布里有 三个峰,Reverse KL 可能只选择其中一个最高、最稳、最容易获得奖励的峰,而放弃其他模式。
所以 Reverse KL 经常被称为:
- • mode-seeking
- • mode-selecting
如果用检索里的直觉类比,它更像"重精确"。
它关心的是:
模型生成出来的东西,尽量都要落在目标认可的区域里。
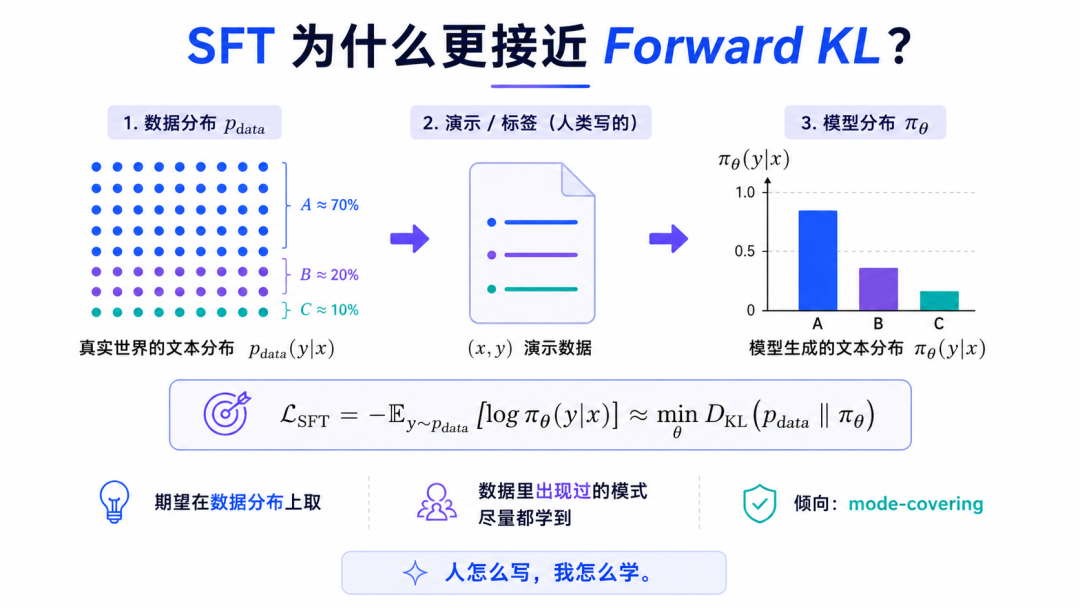
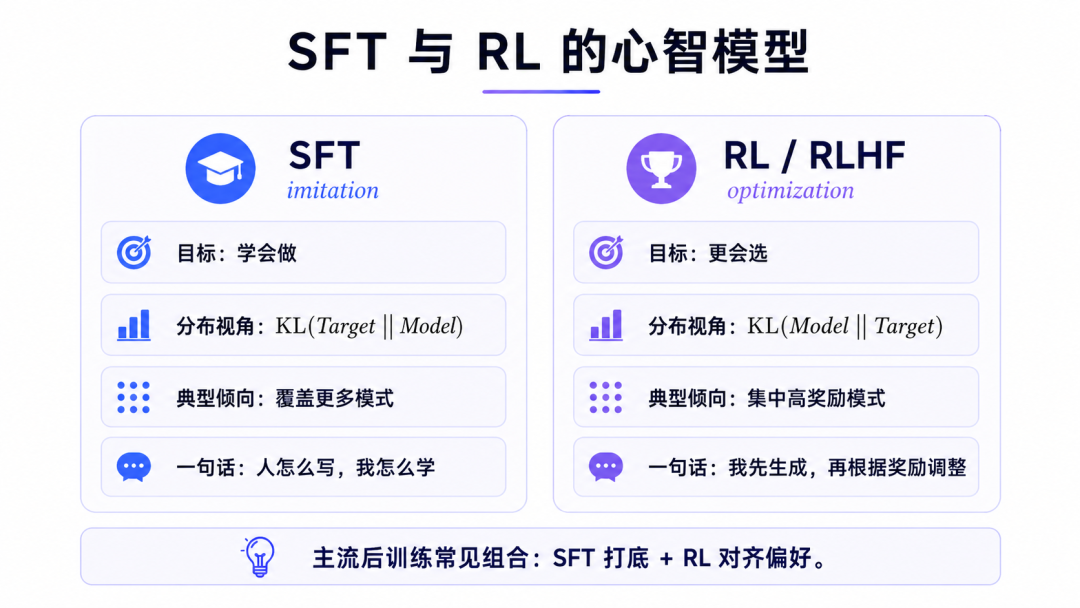
SFT 为什么更接近 Forward KL
SFT 的训练形式通常是:
给定输入 和人工标注答案 ,让模型最大化 的概率。
也就是最小化:
这里的期望是在数据分布 上取的。
也就是说:
- • 训练样本来自数据分布。
- • 答案由人类标注或已有数据提供。
- • 模型要做的是在这些答案上提高概率。
从 KL 角度看,SFT 可以近似理解为最小化:
也就是:
这里 Target 是数据分布,Model 是模型分布。
所以 SFT 的基本行为是:
数据里出现过的答案模式,模型尽量都要学到。
它更像模仿学习。
- • 人怎么写,我怎么学。
- • 老师给了什么答案,我就提升这些答案的概率。
- • 数据分布覆盖了哪些表达方式,我就尽量拟合哪些表达方式。
这也是为什么 SFT 能让模型学会格式、任务、风格、指令跟随能力,却不一定能让模型在多个候选答案里总是选出最优的那个。
因为 SFT 的核心不是"选择最优",而是"拟合示范"。
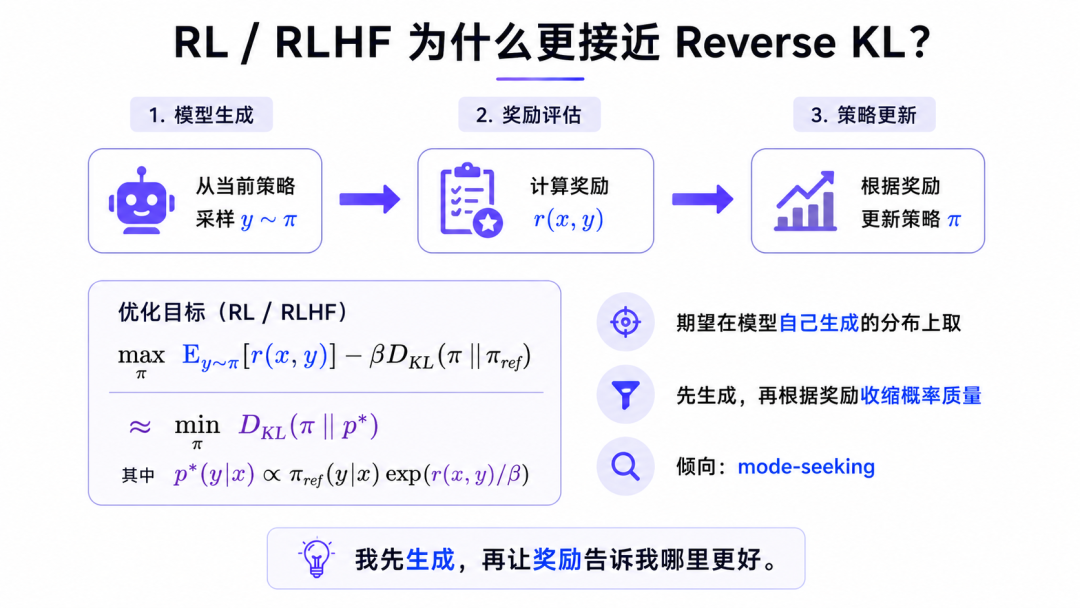
RL为什么更接近 Reverse KL
RL的结构与SFT不一样。
它不是只拿人工答案让模型照着学,而是让模型自己生成,然后通过 reward、偏好模型、verifier 或环境反馈来评价生成结果。
一个常见的 KL 正则化 RLHF 目标可以写成:
这里最重要的是 ,也就是期望在当前模型策略 上取。
- • 模型先生成。
- • 奖励再评价。
- • 策略再更新。
进一步看,这个目标可以等价理解成模型在靠近一个 reward 诱导出来的目标分布:
这里要做两步小推导。先抛开神经网络,问一个问题:如果 可以是任意分布,什么样的 能让上面这个目标取最大值?
把目标对固定的 展开成求和形式,加上归一化约束 ,用拉格朗日乘子求最优解:
整理之后,可以得到闭式最优解:
其中 是归一化常数,保证 是合法分布。
省掉 不写,就是常见的"正比于"形式:
这个 长什么样,其实理解起来也比较直观:
从 出发(SFT 模型本来的语言习惯),把每个回答 按奖励 做指数加权—奖励高的 被抬起来,奖励低的被压下去。 控制加权的锐度: 越小,reweighting 越剧烈,越偏向高奖励答案; 越大,越保留 的原貌。
它不是纯 reward-maximizer(那种会塌缩到单点,丢掉所有多样性),也不是 本身(那样根本没用上奖励),而是两者之间的最优折中分布。
第二步:既然 是最优解,把它代回原目标,可以证明:
也就是说,原目标和这个 KL 之间只差一个与 无关的常数 。所以优化上可以严格等价:
于是优化目标可以写成近似:
这就是 Reverse KL 的形式:
其中 Model 是当前策略 ,Target 是由 reward 和 reference policy 共同诱导出来的理想分布 。
所以 RL / RLHF 的核心行为是:
模型先暴露自己的生成分布,再根据奖励信号把概率质量推向更高价值的区域。
这和 SFT 的行为很不一样。
SFT 是:
人类答案已经在那里,模型去拟合。
RL 是:
模型自己先生成候选,再根据奖励筛选、强化、压缩。
因此 RL 更像"学会选"。
在多个可能答案里,哪些更有帮助,哪些更安全,哪些更符合偏好,哪些更能拿到高奖励,模型会逐渐把概率集中到这些区域。
传统蒸馏、on-policy distillation 与 KL 方向
因为最近on-policy distillation比较火,此处做一点延伸思考,这也是最近在看一篇OPD论文时所想到的:
KL 和 Reverse KL 好像和传统蒸馏、on-policy distillation 对应上了。一个是去 target 上采样,以 target 为轨迹标准。一个是去 model 上采样,以 model 为轨迹标准。
这个直觉大方向是对的,但"以 model 为轨迹标准"这句话描述不太精确。
更准确地说:
传统蒸馏 / SFT
在 teacher / data / target 分布上取样。
老师生成轨迹,或者数据提供轨迹。学生在这些轨迹上学习老师的分布。这是 off-policy 于学生 的,因为训练轨迹不是学生自己走出来的。
on-policy distillation / RL
在 student / model / policy 分布上取样。
学生自己生成轨迹,把自己真实会遇到的状态、错误、偏差暴露出来。老师、奖励模型或 verifier 再对这些轨迹给反馈。这是 on-policy 于学生 的,因为训练轨迹来自学生当前策略。
但需要注意:
model 采样,不等于 model 是标准。
在 on-policy distillation 里,学生生成的轨迹只是"训练发生的位置",不是"正确答案的来源"。
真正的标准仍然来自 teacher。
- • 学生走到哪里,老师就在哪里给反馈。
- • 学生生成什么,老师就在这些生成内容上给出 logits、偏好、纠错信号或奖励。
所以更准确的表达是:
- • 传统蒸馏:老师先走,学生学老师走过的路。
- • on-policy distillation:学生先走,老师在学生真实走到的位置上纠偏。
- • RL / RLHF:模型先生成,奖励告诉模型哪些生成更值得保留。
这样对应之后也会发现KL真的无处不在,与RL有着紧密关联。而在后两者RL中,model 只是轨迹来源,不是评价标准。
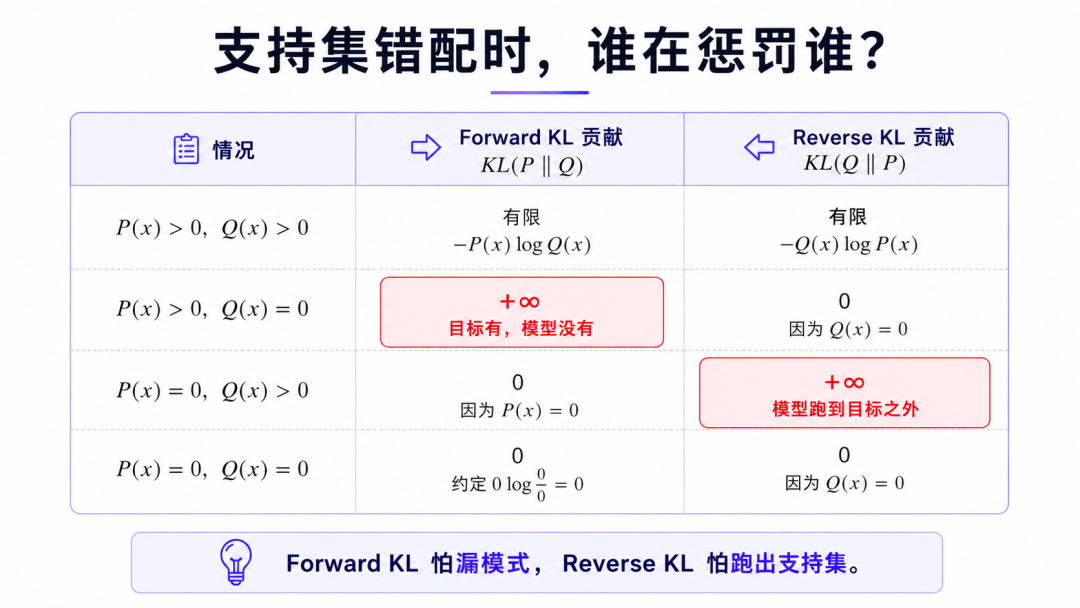
支持集错配:为什么方向会改变惩罚对象
KL 的方向之所以重要,是因为它在支持集错配时惩罚对象完全不同。
看 Forward KL 。
如果 ,但 ,那么:
这说明:
目标分布认为 会出现,但模型完全不给概率。
Forward KL 会严重惩罚这种情况。所以它怕漏掉目标模式。
但如果 ,,那么这一项是:
按照极限约定,这一项不产生惩罚。因为 根本不会采样到这个地方。
再看 Reverse KL 。
如果 ,但 ,那么:
这说明:
模型会生成 ,但目标分布完全不认可。
Reverse KL 会严重惩罚这种情况。所以它怕模型跑到目标分布之外。
这就是两种 KL 行为差异的数学根源。
- • Forward KL:怕目标有、模型没有。
- • Reverse KL:怕模型有、目标不认。
为什么这会影响大模型后训练
理解这件事后,就能更清楚地看 SFT 和 RL 在后训练里的分工。
SFT 主要解决的是:
- • 模型会不会按照人类示范去做。
- • 模型能不能学会任务格式。
- • 模型能不能覆盖训练数据中的回答方式。
- • 模型能不能建立基本的指令跟随能力。
所以 SFT 更像打底。
它把模型从预训练的续写器,拉到一个能理解指令、能按格式回答、能模仿人类示范的状态。
但 SFT 的问题也很明显。
- • 如果数据里有噪声,模型会学噪声。
- • 如果数据里有平庸答案,模型会学平庸答案。
- • 如果数据里多种风格混杂,模型会把这些风格都吸收进去。
- • 如果任务需要在多个答案中选优,SFT 本身不一定提供足够强的选择压力。
RL / RLHF 主要解决的是:
- • 模型在多个可能答案中,能不能更偏向高质量答案。
- • 模型能不能减少明显不符合偏好的输出。
- • 模型能不能把概率质量集中到更安全、更有用、更符合人类偏好的区域。
- • 模型能不能从"会做"进一步走向"更会选"。
所以 RL 更像偏好对齐和行为压缩。
它不是简单扩充能力,而是在已有能力空间里改变概率分布,把更好的行为提上来,把低奖励行为压下去。
这也是为什么可以说:
SFT 让模型学会做。 RL 让模型更会选。
更细一点说:
- • SFT 学的是 demonstration,RL 优化的是 preference / reward。
- • SFT 追求覆盖,RL 追求选择。
- • SFT 更像 imitation,RL 更像 optimization。
不是 RL 都简单等同于 Reverse KL
这里还需要加一个边界。
RL 对应 Reverse KL"这句话不是说所有传统 RL 天然都是 Reverse KL。
相对更准确的说法是:
在 KL-regularized RLHF、最大熵 RL、以及更一般的"期望奖励 + 熵/KL 正则"形式的目标中, RL 优化可以被等价改写成对某个 reward-induced target distribution 的 Reverse KL 最小化。
以上文推导的RLHF为例:
可以对应到:
其中:
这时说 RL 更接近 Reverse KL 是准确的。
但如果是一般传统 RL,只写成最大化累计奖励:
那它当然也是在当前策略上采样轨迹,但不一定天然就是 Reverse KL 形式。只有当你引入熵正则、KL 正则、reference policy 或 reward-induced distribution 的解释时,Reverse KL 的结构才会显现出来。
同样,on-policy distillation 也不能简单说一定就是 Reverse KL。
因为有些方法虽然轨迹来自 student,但在每个 student-generated context 上,仍然可能用 teacher-to-student 的 token-level KL:
这种情况下,它的"状态分布"是 on-policy 的,但"动作分布上的 KL 方向"未必是 Reverse KL。
所以要区分两层:
第一层:轨迹从哪里来?
如果轨迹来自 student / model,那它是 on-policy。
第二层:KL 方向怎么写?
如果是 ,才是 Reverse KL。
如果是 ,仍然是 Forward KL,只是发生在 student 访问到的状态上。
这个区分很重要。否则容易把 "on-policy" 误解成 "必然 reverse KL"。
更准确的表达是:
- • on-policy 描述的是采样轨迹来自谁。
- • Forward / Reverse KL 描述的是分布比较的方向。 两者虽然相关,但不是同一个概念。
KL 方向形成的统一理解
现在可以把整条线串起来。
KL 不是一个普通距离,而是一个有方向的信息代价。
方向来自:
期望在哪个分布上取。
Forward KL
- • 样本来自 Target。
- • 模型要解释 Target。
- • 目标有的,模型别漏。
- • 行为倾向是 mode-covering。
对应到 SFT / 传统蒸馏,就是人类数据或老师输出作为学习轨迹,模型去拟合。
Reverse KL
- • 样本来自 Model。
- • 目标要评价 Model。
- • 模型生成的,目标要认可。
- • 行为倾向是 mode-seeking。
对应到 KL 正则化 RL / RLHF,就是模型自己生成,再由奖励或目标分布筛选,把概率集中到高奖励区域。
传统蒸馏与 on-policy distillation 的差别也可以从这里理解。
- • 传统蒸馏:teacher 生成,student 学。训练暴露的是 teacher 的轨迹。
- • on-policy distillation:student 生成,teacher 评。训练暴露的是 student 自己会走到的轨迹。
对应一句话总结:
不是谁更像"真理",而是谁在采样,谁在评价。
SFT / 传统蒸馏里,target 提供样本,model 负责拟合。 RL / on-policy 类方法里,model 提供样本,target / teacher / reward 负责评价。
这也就是从 KL 方向理解 SFT、RL 和 on-policy distillation 的关键。
结语
零零散散的思考了一堆,对KL和Reverse KL似乎也有了更深入的理解,用比较通俗的话来做下收尾。
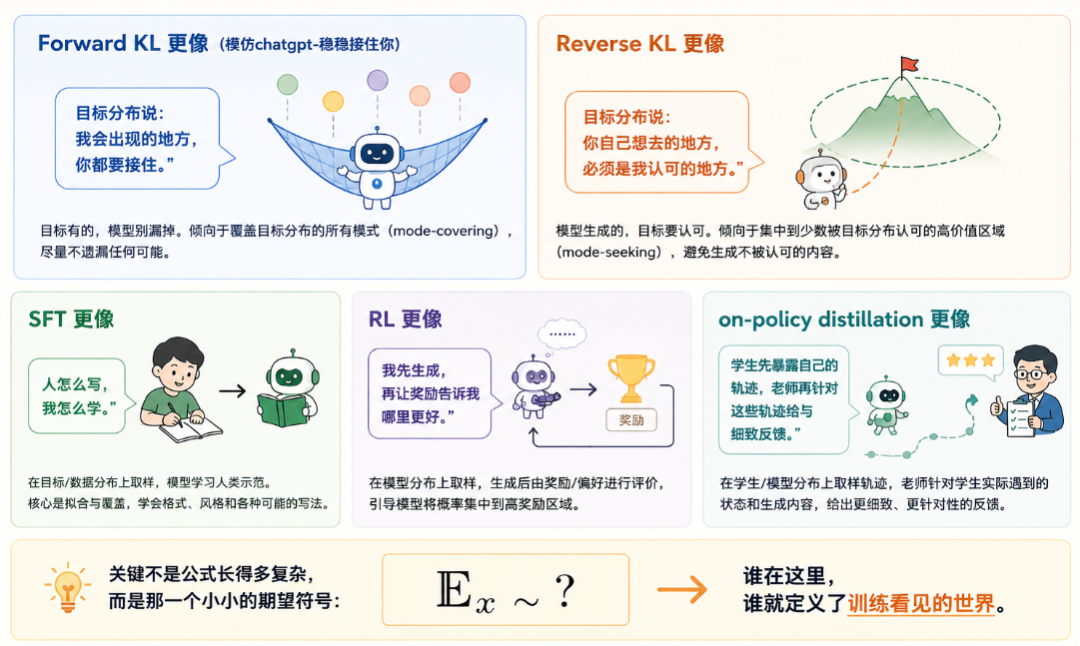
Forward KL 更像(模仿chatgpt-稳稳接住你):
目标分布说:"我会出现的地方,你都要接住。"
Reverse KL 更像:
目标分布说:"你自己想去的地方,必须是我认可的地方。"
SFT 更像:
人怎么写,我怎么学。
RL 更像:
我先生成,再让奖励告诉我哪里更好。
on-policy distillation 更像:
学生先暴露自己的轨迹,老师再针对这些轨迹给与细致反馈。
关键不是公式长得多复杂,而是那一个小小的期望符号:
谁在这里,谁就定义了训练看见的世界。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号