本体+AI大模型驱动的电商数据分析报告生成方案加具体实现

本体+AI大模型驱动的电商数据分析报告生成方案加具体实现

人月聊IT
发布于 2026-05-19 18:44:48
发布于 2026-05-19 18:44:48
大家好,我是人月聊IT。今天继续分析本体驱动电商经营数据分析平台——从需求构想到POC实现。
摘要
传统电商数据分析面临三大痛点:指标口径不一致(同一指标不同团队算出来不同)、分析逻辑不透明(AI生成结论无法溯源验证)、系统改造代价大(接入分析能力需要侵入式改造数据库)。
本文提出一种本体模型驱动的数据分析方法,以本体(Ontology)作为数据库与AI分析引擎之间的语义中间层,实现零侵入、可溯源、可解释的智能数据分析。本文完整记录了从方法论设计、本体建模、数据库映射、模拟数据生成、分析引擎实现到前端报告呈现的整个POC验证过程,并通过三个真实的电商经营分析场景验证了方案的有效性。
第一章 问题背景与方案总览
1.1 核心痛点
在电商平台的日常经营中,数据分析面临以下关键挑战:
口径不一致。"GMV"、"流失率"、"活跃用户"等基础指标的定义,在运营、财务、产品等不同团队之间存在歧义。例如,GMV是否扣除退款订单?流失用户是指30天未访问还是60天未下单?口径的不一致导致"用数据说话"变成"用数据吵架"。
分析不透明。AI生成的归因结论(如"GMV下降是因为转化率降低")往往缺乏可验证的推导链路。分析师无法回答"为什么AI得出这个结论?""这个数字是从哪个表查出来的?"
系统侵入性强。传统BI方案需要在现有数据库上建立物化视图、ETL管线或数据仓库,面临改造成本高、时效性差、与业务系统耦合的问题。
1.2 方案核心思想
本方案的核心设计哲学是:在本体语义层解决"理解"问题,在数据库层解决"计算"问题,两者通过可追溯的映射层连接。
┌─────────────────────────────────────────────────────────┐
│ 分析报告层 │
│ (Markdown + ECharts 图表 + 可执行建议) │
├─────────────────────────────────────────────────────────┤
│ AI推理层 │
│ LLM语义推理 · 模式识别 · 因果推断 │
│ 所有结论引用本体规则 + SQL溯源 │
├─────────────────────────────────────────────────────────┤
│ 数据计算层 │
│ SQL确定性计算 · 统计算法 · 指标聚合 │
│ 不依赖LLM,确保数值精确 │
├─────────────────────────────────────────────────────────┤
│ 语义映射层(外部) │
│ 实体→表字段映射 · 指标→SQL模板映射 · 置信度标注 │
│ 零侵入:不修改源数据库任何表结构 │
├─────────────────────────────────────────────────────────┤
│ 本体模型层 │
│ M1 对象模型 · M2 行为模型 · M3 规则模型 │
│ M_Metric 指标模型 · M4 场景模型 · M5 主体模型 │
├─────────────────────────────────────────────────────────┤
│ 数据源层 │
│ 现有电商数据库 (SQLite / MySQL / PostgreSQL) │
└─────────────────────────────────────────────────────────┘
1.3 六大设计原则
原则 | 说明 |
|---|---|
语义优先 | 本体模型是AI理解数据的唯一入口,AI不直接面对数据库表结构 |
零侵入 | 映射层架在数据库外部,不修改任何现有表、不迁移任何数据 |
推理分级 | 确定性指标用SQL,模式识别用统计算法,因果推理用LLM——严格分层不混用 |
结果可溯源 | 报告中每个数字都可以追溯到:指标ID → SQL模板 → 映射规则 → 原始表字段 |
置信度透明 | 映射关系和AI推理结论均标注置信度,低置信度强制人工确认 |
模板驱动 | 报告结构定义在YAML模板中,数据动态填入,模板可独立演进 |
1.4 六步分析闭环
步骤一:提出分析需求 ──────── 业务方以自然语言描述分析目标
↓
步骤二:AI 细化需求 ──────── 梳理指标体系、数据对象、关系、规则
↓
步骤三:本体建模 ──────────── M1–M5 + M_Metric 六模型体系
↓
步骤四:数据库映射 ────────── 本体实体/指标 → 数据库表字段映射
↓
步骤五:模板构建 ──────────── 报告结构 · 指标配置 · 展示规范
↓
步骤六:AI 驱动报告生成 ───── 数据采集 → 推理分析 → 报告输出
第二章 POC验证场景设计
2.1 场景选择原则
POC的核心目的是验证"本体驱动"这一核心假设,而非追求功能的完备性。因此选择三个场景的标准是:(1)每个场景验证不同的推理类型;(2)覆盖多个业务域和实体关系网络;(3)预埋已知的数据问题以检验AI的检测能力。
2.2 场景一:用户流失异常诊断
触发条件:运营总监发现3月用户流失率飙升至17.1%(1–2月均值约8.5%),触发异常预警。
分析流程:
步骤 | 分析行为 | 本体依赖 | 计算引擎 |
|---|---|---|---|
1 | 加载本体:流失定义、活跃定义、RFM规则 | M3 RULE-USR-001/002/005 | — |
2 | 计算流失率 + 按等级/渠道/地区三维拆解 | M_Metric MTR-USR-006 | SQL |
3 | 构建流失用户RFM画像 | M_Metric MTR-USR-008 | 统计算法 |
4 | 关联售后问题率,查找品质驱动流失 | M1 实体关系(Order→Shop→Product) | SQL |
5 | 归因推理 + 挽回建议 | M4 UC-CHURN-001 | LLM推理 |
预埋问题:
- 手机配件类目3月售后率16–19%(正常约5%),涉及迅达数码、酷配旗舰店
- 短视频直播渠道新用户30日留存率仅22%(均值35%)
- VIP1(年消费3K–10K)用户流失率26.6%,显著高于其他等级
验证点:AI能否通过本体规则正确理解"流失"定义,并通过实体关系网络实现跨域关联推理。
2.3 场景二:GMV异常波动归因
触发条件:3月第3周(3.15–3.21)GMV周环比明显下降,触发异常告警。
分析流程:
步骤 | 分析行为 | 本体依赖 | 计算引擎 |
|---|---|---|---|
1 | 加载本体:GMV口径、客单价口径、GMV分解规则 | M3 RULE-MTR-001/003/004 | — |
2 | GMV按类目/渠道/店铺多维度下钻 | M_Metric MTR-TXN-001 | SQL |
3 | 订单量vs客单价贡献分解 | M3 RULE-MTR-004 | 统计算法 |
4 | 关联缺货率、转化率、客单价变化 | M1 关系(Order→Product→SKU→Category) | SQL+统计 |
5 | 归因推理(主因+次因+贡献度量化) | M4 UC-GMV-001 | LLM推理 |
预埋问题:
- 服饰鞋包头部门店热销SKU缺货率22%,导致订单量下降
- 搜索渠道落地页转化率从8.2%降至5.1%(3月14日算法调整)
- 美妆个护类目客单价从186元降至142元(低门槛优惠券稀释)
验证点:AI能否通过RULE-MTR-004将GMV变化科学分解为"订单量效应"和"客单价效应",并量化各因素贡献度。
2.4 场景三:营销活动ROI综合评估
触发条件:"春季焕新大促"(3.8–3.15,预算200万)活动结束后,需全面评估投入产出效率。
分析流程:
步骤 | 分析行为 | 本体依赖 | 计算引擎 |
|---|---|---|---|
1 | 加载本体:ROI计算口径、券效率评估规则 | M3 RULE-MKT-001/002 | — |
2 | 活动GMV + 基准期GMV + 增量GMV计算 | M_Metric MTR-MKT-001/003 | SQL |
3 | 各券类型使用率/补贴金额/效率分评估 | M_Metric MTR-MKT-002 | SQL+统计 |
4 | 拉新用户质量 + 沉睡用户唤醒率分析 | M_Metric MTR-MKT-004 | SQL |
5 | 效率综合评估 + 预算优化建议 | M4 UC-MKT-001 | LLM推理 |
预埋数据对比:
- 活动整体ROI未达3.5的目标
- 新人券占比35%但拉新用户首单客单价低、7日留存差
- 品牌券(满300减50)ROI最高,使用率42%,撬动客单价256元
- 沉睡用户唤醒率仅9%,30天未购用户中91%未被触达
验证点:AI能否通过RULE-MKT-001理解增量GMV的概念(非简单的"活动期GMV"),并通过RULE-MKT-002量化评估各券类型的投入产出效率。
第三章 本体建模体系
3.1 模型总览
本POC采用六模型体系(在标准M1–M5基础上增加M_Metric指标模型扩展):
模型 | 核心职责 | POC中规模 |
|---|---|---|
M1 对象模型 | 定义业务实体、属性、关联关系、参照完整性约束 | 12实体 + 15关系 |
M2 行为模型 | 定义对象的原子分析行为,标注推理类型 | 12个分析行为 |
M3 规则模型 | 可复用的业务规则:验证/计算/推导/风险 | 16条规则 |
ME 事件模型 | 事件定义、生产者/订阅者、事件链(POC中简化) | — |
M4 场景模型 | 业务流程与用例场景,编排行为和事件链 | 4个分析场景 |
M5 主体模型 | 参与者、角色、权限(RBAC+ABAC) | 7角色 + 10权限 |
M_Metric 指标模型 | 指标口径、依赖实体、规则引用、可视化配置 | 29个指标 |
3.2 M1 对象模型:实体关系网络
对象模型定义了12个核心业务实体,覆盖电商经营的6大业务域:
交易域:Order(订单) ──< OrderItem(订单明细) ──< Payment(支付记录)
商品域:Product(SPU) ──< ProductSKU(SKU) ──< Category(类目)
用户域:User(用户) ──< UserBehavior(行为记录)
店铺域:Shop(店铺)
营销域:Campaign(活动) ──< Coupon(优惠券)
流量域:Session(访问会话)
关键关联关系(15条,摘选核心):
关系 | 类型 | 源实体 | 目标实体 | 基数 |
|---|---|---|---|---|
REL-001 | COMPOSITION | Order | OrderItem | 1 : 1..N |
REL-003 | ASSOCIATION | User | Order | 1 : N |
REL-006 | ASSOCIATION | Product | Category | N : 1 |
REL-013 | ASSOCIATION | Order | Coupon | 1 : 0..1 |
设计要点:
- 组合关系(COMPOSITION)标记了级联删除语义:删除订单时自动删除订单明细
- 关联关系(ASSOCIATION)支持双向查询,例如从User出发可以找到Order,从Order可以反向回溯到User
- 基数约束明确了实体间的数量关系,为AI的跨域推理提供路径"地图"
3.3 M_Metric 指标模型:本体的数据分析扩展
M_Metric是本方案最重要的扩展维度。每个指标定义包含:
- id:MTR-USR-006 # 唯一标识
name:用户流失率 # 中文名
formula:"上月活跃且本月未活跃 / 上月活跃用户数"# 计算公式
dependsOn:[ENT-USR-001,ENT-USR-002,ENT-ORD-001]# 依赖的M1实体
ruleRefs:[RULE-USR-001,RULE-USR-002] # 依赖的M3规则
grains:[月] # 支持的统计粒度
dimensions:[用户等级,地区,注册渠道]# 可拆分维度
computationType:SQL_COMPUTE # SQL_COMPUTE / STAT_ALGO / LLM_REASONING
defaultVisualization:bar_chart # 默认图表类型
tags:[用户质量,风险指标]
设计价值:
- **AI理解数据的"词典"**:AI通过M_Metric知道"流失率"的准确定义和计算方式,而非猜测
- 计算引擎分派:
computationType字段告诉系统该指标用SQL、统计算法还是LLM来计算 - 维度下钻导航:
dimensions字段告诉AI该指标可以按哪些维度拆分,AI据此自主规划下钻路径
3.4 M3 规则模型:指标口径的"法典"
规则模型的核心价值是将指标口径从代码中解耦出来,使其成为可被AI查询、引用和解释的显式知识。
POC中的16条规则分类:
类型 | 数量 | 示例 |
|---|---|---|
指标口径规则 | 4条 | RULE-MTR-001 GMV口径、RULE-MTR-003 客单价口径 |
用户定义规则 | 5条 | RULE-USR-001 活跃定义、RULE-USR-002 流失定义、RULE-USR-005 RFM评分 |
营销计算规则 | 2条 | RULE-MKT-001 ROI计算、RULE-MKT-002 券效率评估 |
数据质量规则 | 3条 | RULE-DQ-001 金额异常、RULE-DQ-002 行为去重 |
商品/异常规则 | 2条 | RULE-PRD-001 ABC分类、RULE-ANOM-001 异常判定 |
一条规则的完整定义示例:
- id:RULE-USR-002
name:流失用户定义
ruleType:VALIDATION
description:|
月流失:上月活跃但本月未活跃的用户
流失率 = 流失用户数 / 上月活跃用户数
inputParams:
-name:wasActiveLastMonth
type:Boolean
-name:isActiveThisMonth
type:Boolean
outputType:Boolean
expression: |
wasActiveLastMonth == true AND isActiveThisMonth == false
关键设计决策:参照完整性约束归属M1对象模型(外键、唯一约束等),而非M3规则模型。M3专注于业务逻辑层面的规则,保持各模型职责正交。
第四章 数据库映射设计
4.1 映射层架构
映射层是本体语义空间与数据库物理空间之间的"翻译器":
本体层 映射层 数据库层
─────── ────── ────────
ENT-ORD-001.Order ←── entity_mappings ──→ t_order 表
.orderId ←── field_mappings ──→ order_id 列
.orderStatus ←── value_mapping ──→ status (枚举值映射)
.payAmount ←── field_mappings ──→ pay_amount 列
[有效订单] ←── default_filter ──→ status NOT IN ('cancelled', 'refund_only')
MTR-TXN-001.GMV ←── metric_sql_mappings ──→ SELECT SUM(pay_amount) ...
.dimensions ←── supported_dimensions ──→ LEFT JOIN + GROUP BY
.traceability ←── rule_refs ──→ RULE-MTR-001 (GMV口径)
4.2 实体映射配置(YAML)
每个本体实体对应一个映射配置块:
entity_mappings:
-ontology_entity:ENT-ORD-001 # 映射目标:订单实体
confidence:0.97 # 整体映射置信度
db_tables:
-table:"t_order"
alias:"ord"
primary:true
field_mappings:
-ontology_field:orderStatus # 本体字段
db_expression:"ord.status" # 数据库表达式
confidence:0.85 # ⚠️ 低置信度
value_mapping: # 枚举值映射
"1":"待付款"
"2":"已付款"
...
note:"需与业务方确认状态码含义"
-ontology_field:payAmount
db_expression:"ord.pay_amount"
confidence:0.95
default_filter:"ord.status NOT IN ('5', '6')"# 对应 RULE-MTR-001
置信度机制:每个映射标注0.0–1.0的置信度,低于0.8的映射必须附带note说明不确定原因,并列入待确认清单。
4.3 指标SQL模板映射
设计原则:每个M_Metric指标对应一个参数化的SQL模板,支持时间范围、统计粒度、拆解维度的动态替换。
metric_sql_mappings:
-metric_id:MTR-USR-006 # 用户流失率
sql_template:|
WITH last_month_active AS (
SELECT DISTINCT user_id FROM t_user_behavior
WHERE created_at BETWEEN '{lm_start}' AND '{lm_end}'
UNION
SELECT DISTINCT user_id FROM t_order
WHERE created_at BETWEEN '{lm_start}' AND '{lm_end}'
AND order_status NOT IN ('cancelled', 'refund_only')
),
this_month_active AS (...)
SELECT
(SELECT COUNT(*) FROM last_month_active) AS base_active,
(SELECT COUNT(*) FROM lma LEFT JOIN tma ...) AS churned,
ROUND(...*100.0/..., 2) AS churn_rate
supported_dimensions:
-name:用户等级
dimension_sql:"SELECT usr.user_level, ... GROUP BY usr.user_level"
-name:注册渠道
dimension_sql:"SELECT usr.register_channel, ... GROUP BY usr.register_channel"
traceability:
ontology_refs:[ENT-USR-001,ENT-USR-002,ENT-ORD-001]
rule_refs:[RULE-USR-001,RULE-USR-002]
mapping_refs:[ENT-ORD-001.payAmount,ENT-ORD-001.orderStatus]
溯源链路:报告中每个数字 → 指标ID(M_Metric)→ SQL模板 → 映射规则(data-mapping.yaml)→ 数据库表字段 → 业务规则定义(M3)。五步溯源,不可截断。
第五章 模拟数据生成
5.1 数据规模设计
实体 | 表名 | 行数 |
|---|---|---|
类目 | t_category | 40(3级类目树) |
店铺 | t_shop | 50 |
商品 | t_product | 945 |
SKU | t_product_sku | 1,930 |
用户 | t_user | 5,000 |
订单 | t_order | 63,031 |
订单明细 | t_order_item | 106,788 |
支付 | t_payment | 59,988 |
用户行为 | t_user_behavior | 291,413 |
会话 | t_session | 48,366 |
营销活动 | t_campaign | 5 |
优惠券 | t_coupon | 104,892 |
数据时间范围为2026年1月至3月,共90天。使用随机种子(seed=42)确保每次生成的数据可以精确复现。
5.2 预埋问题的生成策略
为验证AI的检测能力,在数据生成脚本中刻意植入了三类业务问题:
(1)场景一预埋——品质驱动流失:
# 手机配件店铺(8,9)在3月的售后率加权提高
if is_march and shop_id in PROBLEM_SHOPS:
order_status = random.choices(
["completed", "completed", "completed", "refund_only", "return_refund"],
weights=[40, 20, 10, 15, 15] # 售后权重30% vs 正常3%
)[0]
然后通过后处理脚本制造自然流失:
# 移除约800名用户在3月的所有行为和订单
# 其中VIP1用户200名、短视频渠道用户100名
# 使流失率达到17.1%
(2)场景二预埋——缺货+转化率下降:
# 头部服饰店铺25%的SKU在3月标记缺货
if shop_id in HEAD_SHOPS and cat_id in FASHION_CATS:
if random.random() < 0.25:
stock = 0
sale_status = "out_of_stock"
# 3月第3周跳过约35%的服饰店铺订单
if is_gmv_drop_week and shop_id in HEAD_SHOPS:
if random.random() < 0.35:
continue# 不生成该订单
# 搜索渠道转化率降低
if source == "搜索"and is_gmv_drop_week:
has_order = 1if random.random() < 0.03else0# 3% vs 正常8%
(3)场景三预埋——低效券投放:
# 新人券占35%预算但使用率低
campaign3_config = [
("满减券", 199, 40, 0.25),
("新人券", 99, 30, 0.25), # 25%数量占比,但效率低
("品牌券", 300, 50, 0.15), # 15%数量占比,但ROI最高
...
]
5.3 数据验证
生成后通过SQL验证预埋模式是否生效:
-- 验证手机配件售后率
SELECT cat.category_name,
COUNT(CASE WHEN ord.order_status IN ('refund_only','return_refund') THEN 1 END) * 1.0 / COUNT(*)
FROM t_order ord ... WHERE cat.parent_id = 22 -- 手机配件
-- 结果:手机壳15.21%, 贴膜18.74%, 充电器16.29%, 数据线16.80%
-- 验证GMV周期差异
-- 结果:3月第3周 GMV = 12,496,706;其他周均值 = 18,147,065
第六章 核心推理算法
6.1 推理引擎分级架构
这是整个系统最重要的架构决策——不同类型的数据分析使用不同的计算引擎:
计算类型 | 使用引擎 | 场景示例 | 设计理由 |
|---|---|---|---|
指标聚合 | SQL | GMV、订单数、UV | 确定性强,必须精确,LLM会产生幻觉 |
统计分析 | Python算法 | 趋势判断、RFM评分、ABC分类 | 有成熟算法,无需LLM |
多维关联 | SQL+本体导航 | 流失率↓→类目下钻→售后率关联 | 基于M1实体关系网络的路径遍历 |
因果推理 | LLM + 规则约束 | "为什么GMV下降"的主因推断 | 需要语义理解和业务知识 |
建议生成 | LLM | 行动建议、优先级排序 | 需要自然语言生成能力 |
6.2 本体驱动的多维归因算法
以场景二"GMV波动归因"为例,说明AI如何基于本体模型执行多维下钻推理:
步骤1:加载本体上下文
AI首先从M_Metric获取GMV(MTR-TXN-001)的定义,从M3规则模型获取RULE-MTR-001(GMV口径)和RULE-MTR-004(GMV分解规则),从M1对象模型获取实体关系网络:
RULE-MTR-004 分解规则:
GMV变化 = 订单量效应 + 客单价效应
订单量效应 = (当期订单数 - 基期订单数) × 基期客单价
客单价效应 = (当期客单价 - 基期客单价) × 当期订单数
步骤2:SQL计算 + 统计分解
执行SQL计算GMV的基期值和当期值,然后按RULE-MTR-004分解:
volume_effect = (current_orders - baseline_orders) * baseline_atv
price_effect = (current_atv - baseline_atv) * current_orders
volume_share = volume_effect / gmv_change # 订单量贡献百分比
price_share = price_effect / gmv_change # 客单价贡献百分比
步骤3:多维下钻——本体驱动的路径规划
基于M1对象模型的实体关系网络,AI自主规划下钻路径:
GMV下降
→ M_Metric.dimensions: [类目, 渠道, 店铺, 地区]
→ 按类目下钻: Order → OrderItem → Product → Category
发现"服饰鞋包"GMV下降最大(-35%)
→ 关联MTR-PRD-004(缺货率):
Product → ProductSKU.saleStatus
发现服饰店铺缺货率22%
→ 关联MTR-TFC-002(转化率):
Session → Order
发现搜索渠道转化率从8.2%降至5.1%
→ 关联MTR-TXN-003(客单价):
发现美妆类目客单价下降24%
每一个下钻步骤都有着明确的本体路径支撑。这不是黑箱式的"AI分析",而是可审计、可解释的语义路径推理。
步骤4:LLM推理——受约束的因果推断
将步骤2和3的结构化结果输入LLM,但施加严格约束:
- 所有数字必须来自SQL计算结果,禁止LLM自行编造
- 每条结论必须引用数据来源(指标ID + 本体规则)
- 不确定的推断必须使用"可能""初步判断"等限定语
- 无法从数据推断的问题必须明确说明
LLM的推理被结构化为三个层次:
- 数据观察:"GMV周环比下降X%,订单量贡献Y%,客单价贡献Z%"
- 模式识别:"服饰鞋包类目缺货率达22%,是该类目GMV下降的首要因素"
- 因果推断:"缺货→订单量下降→GMV下降,此为主因。转化率下降为次因"
6.3 推理置信度评估体系
推理层级 | 置信度 | 评估依据 |
|---|---|---|
SQL数据采集 | 1.0 | 确定性SQL计算,完全可复现 |
统计分析 | 0.95 | 标准统计方法(环比率、趋势斜率) |
映射关系 | 0.85–0.98 | 取决于字段映射的人工确认程度 |
模式识别 | 0.80 | 基于M3规则的阈值判定,但可能漏检 |
因果归因 | 0.75 | AI推理,多因素交叉验证可提升置信度 |
行动建议 | 0.70 | AI推理,需人工决策确认 |
6.4 推理过程可追溯性
每次分析生成完整的《推理过程记录》文档,包含:
推理步骤详情
├── Step 1: 本体加载
│ └── 加载了哪些实体、规则、指标定义
├── Step 2: SQL数据采集
│ └── 执行的SQL语句、返回行数、溯源信息
├── Step 3: 统计分析
│ └── 使用的算法、参数、中间结果
├── Step 4: 本体关系导航
│ └── 跨域关联的实体路径(如:User→Order→Shop→Category)
├── Step 5: 模式识别
│ └── 触发阈值、匹配的规则、识别的异常
├── Step 6: AI因果推理
│ └── 推理链(数据观察→模式识别→因果推断)、置信度评估
└── Step 7: 行动建议生成
└── 建议的优先级排序依据
第七章 模板驱动的报告生成
7.1 模板与代码分离
报告的结构定义(章节标题、卡片布局、图表类型)不应硬编码在Python代码中。本方案将报告模板抽象为独立的YAML文件,模板引擎负责将数据填入模板。
模板示例(template-marketing.yaml):
sections:
-section_id:SEC-001
title:一、活动ROI总览
type:metric_cards
cards:
-label:实际ROI
value:"${roi_summary.roi}"
change:"${roi_summary.achieved ? 'up' : 'down'}"
description:"目标ROI: ${roi_summary.target_roi}"
-section_id:SEC-002
title:二、优惠券效率分析
type:charts
charts:
-id:coupon_subsidy
chart_type:pie
data_from:"${mkt_data.coupon_efficiency}"
pie_name_field:coupon_type
pie_value_field:total_subsidy
7.2 模板引擎设计
模板引擎(template_loader.py)负责:
- 加载模板:从YAML文件读取报告结构定义
- 解析表达式:处理{path.to.field}路径引用和{cond ? 'a' : 'b'}条件表达式
- 图表渲染:根据
x_field、y_series、pie_name_field等声明式配置,自动生成完整的ECharts option对象 - 数据填充:将分析引擎产出的结构化数据注入模板各占位符
class TemplateEngine:
def render(self, scenario: str, context: dict) -> dict:
template = self.load_template(scenario) # 加载YAML模板
sections = []
for sec in template["sections"]:
if self._eval_condition(sec, context): # 条件检查
rendered = self._render_section(sec, context)
sections.append(rendered)
return {
"report_meta": { ... },
"sections": sections,
"data_lineage": template["data_lineage"],
"ontology_references": template["ontology_model_used"],
}
设计优势:
- 修改报告结构只需编辑YAML文件,零代码改动
- 同一模板可应用于不同时间段的数据
- 模板可版本管理,支持A/B测试不同报告布局
- 非技术人员(如运营)经简单培训即可调整报告模板
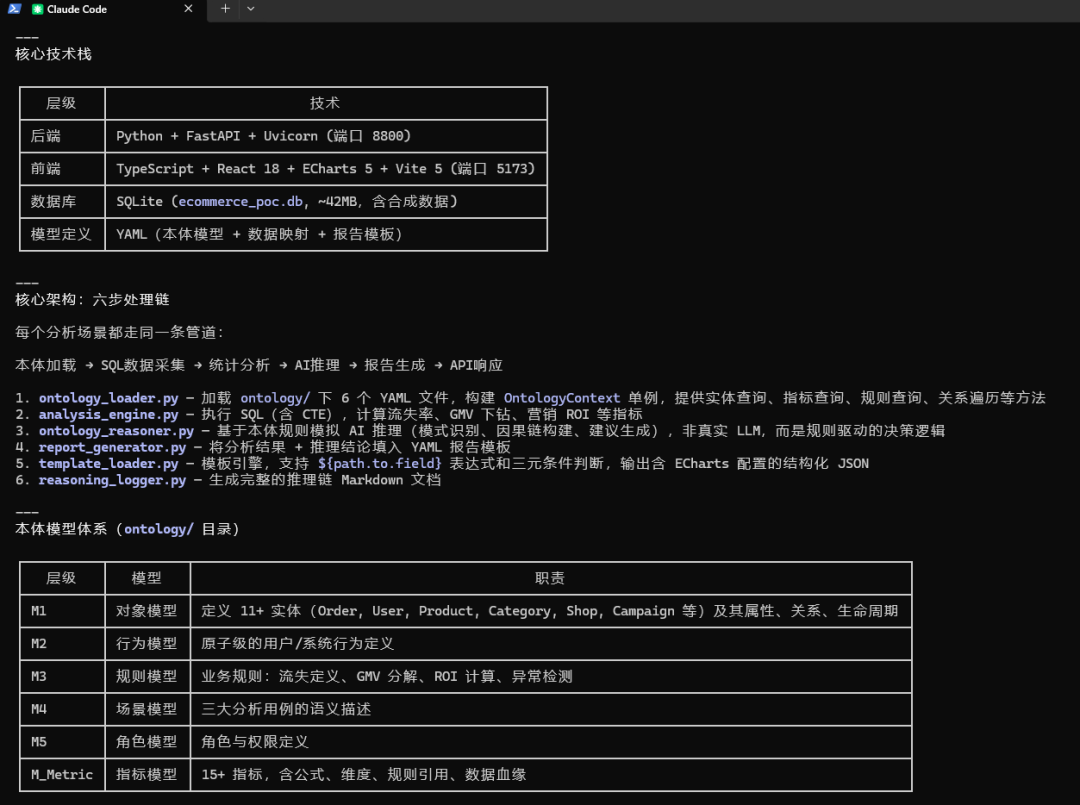
第八章 系统实现架构
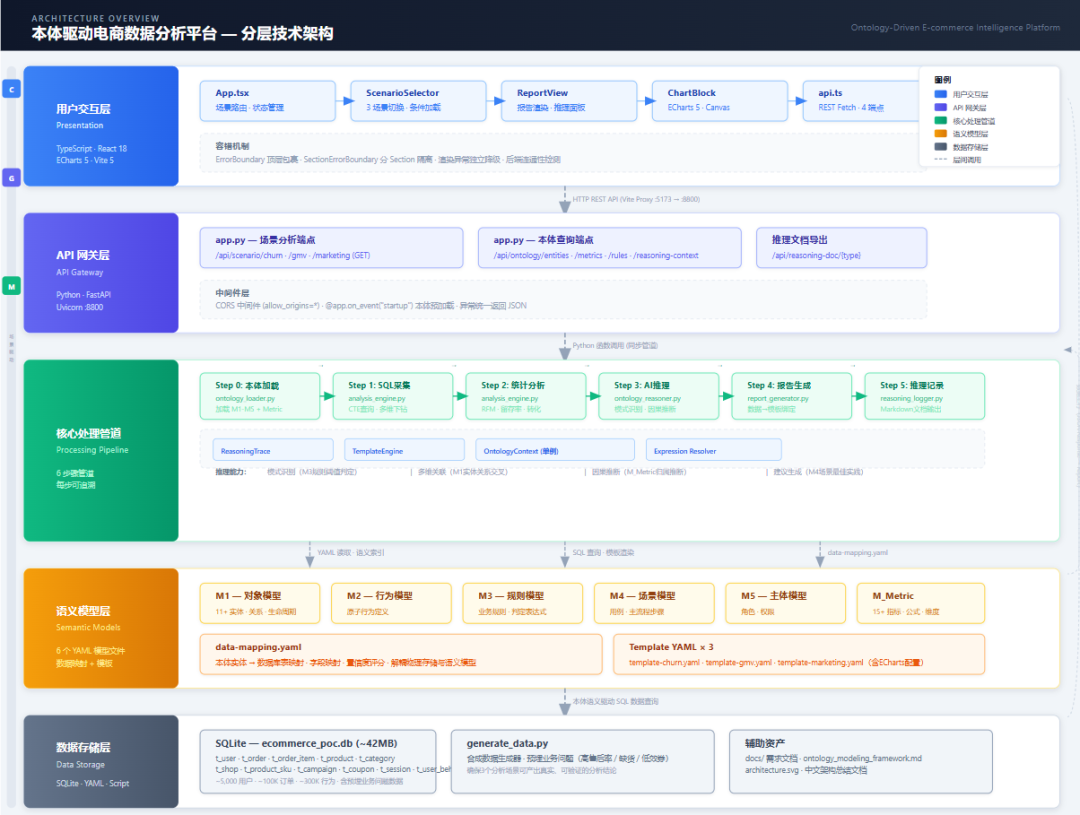
8.1 技术栈
层级 | 技术 | 说明 |
|---|---|---|
数据库 | SQLite | 零配置,适合POC验证 |
后端框架 | Python FastAPI | 异步高性能,自动生成API文档 |
本体模型 | YAML文件 | 人类可读,版本可控 |
模板引擎 | 自研Python模块 | 支持表达式求值+ECharts配置生成 |
前端 | React 18 + TypeScript | 类型安全,组件化 |
图表 | ECharts 5.5 | 丰富的图表类型,灵活的配置项 |
构建工具 | Vite 5 | 快速的HMR,TypeScript原生支持 |
8.2 后端模块结构
backend/
├── app.py # FastAPI主程序(3场景API + 本体查询API + 推理文档导出)
├── ontology_loader.py # 本体模型加载器(加载YAML → 索引 → 查询接口)
├── analysis_engine.py # 分析引擎(SQL执行 + 统计计算 + 数据采集)
├── ontology_reasoner.py # 本体推理器(模式识别 + 因果推断 + 建议生成)
├── template_loader.py # 模板引擎(YAML加载 + 表达式求值 + 图表配置生成)
├── report_generator.py # 报告生成器(构建数据上下文 → 调用模板引擎)
└── reasoning_logger.py # 推理过程记录(Markdown文档生成)
8.3 API设计
GET /api/health — 健康检查
GET /api/scenario/churn?month=2026-03 — 场景一:用户流失诊断
GET /api/scenario/gmv?start=...&end=... — 场景二:GMV归因分析
GET /api/scenario/marketing?campaign_id=3 — 场景三:营销ROI评估
GET /api/reasoning-doc/churn — 导出推理过程Markdown文档
GET /api/ontology/entities — 列出所有本体实体
GET /api/ontology/metrics — 列出所有指标定义
GET /api/ontology/rules — 列出所有业务规则
每个场景API返回统一结构:
{
"scenario": "用户流失异常诊断",
"report": {
"report_meta": { "template_id": "TPL-CHURN-001", ... },
"sections": [ { "section_id": "SEC-001", "type": "metric_cards", ... } ],
"data_lineage": { "MTR-USR-006": "SQLite CTE ...", ... },
"ontology_references": { "entities": [...], "rules": [...] }
},
"reasoning_process": {
"steps": [ ... ],
"ontology_references": { ... },
"key_ontology_insight": "AI通过本体M3规则模型..."
}
}
8.4 前端组件树
App
├── TopErrorBoundary ← 顶层崩溃兜底
├── ScenarioSelector ← 三个场景切换按钮
├── ReportView ← 报告主容器
│ ├── ReportMetaBar ← 场景名/时间/活动信息
│ ├── SectionErrorBoundary × N ← 每个区块独立容错
│ │ ├── MetricCardView ← 指标卡片
│ │ ├── ChartBlock ← ECharts图表(bar/pie/hbar/line)
│ │ ├── SafeTable ← 数据表格
│ │ ├── SafeInsight ← AI推理结论面板
│ │ └── RecItemView ← 行动建议项
│ ├── DataLineage ← 数据溯源表
│ └── ReasoningPanel ← AI推理过程面板
└── LoadingState / ErrorState ← 加载/错误状态
8.5 错误防护设计
前端采用双层ErrorBoundary设计:
- TopErrorBoundary — 包裹整个App,捕获任何级别的渲染崩溃,显示完整错误堆栈
- SectionErrorBoundary — 包裹每个报告区块,单个区块崩溃不影响其他区块渲染
所有组件对空值做防御性处理(|| ""、??、|| []),确保在数据不完整时优雅降级而非崩溃。
第九章 POC验证结果
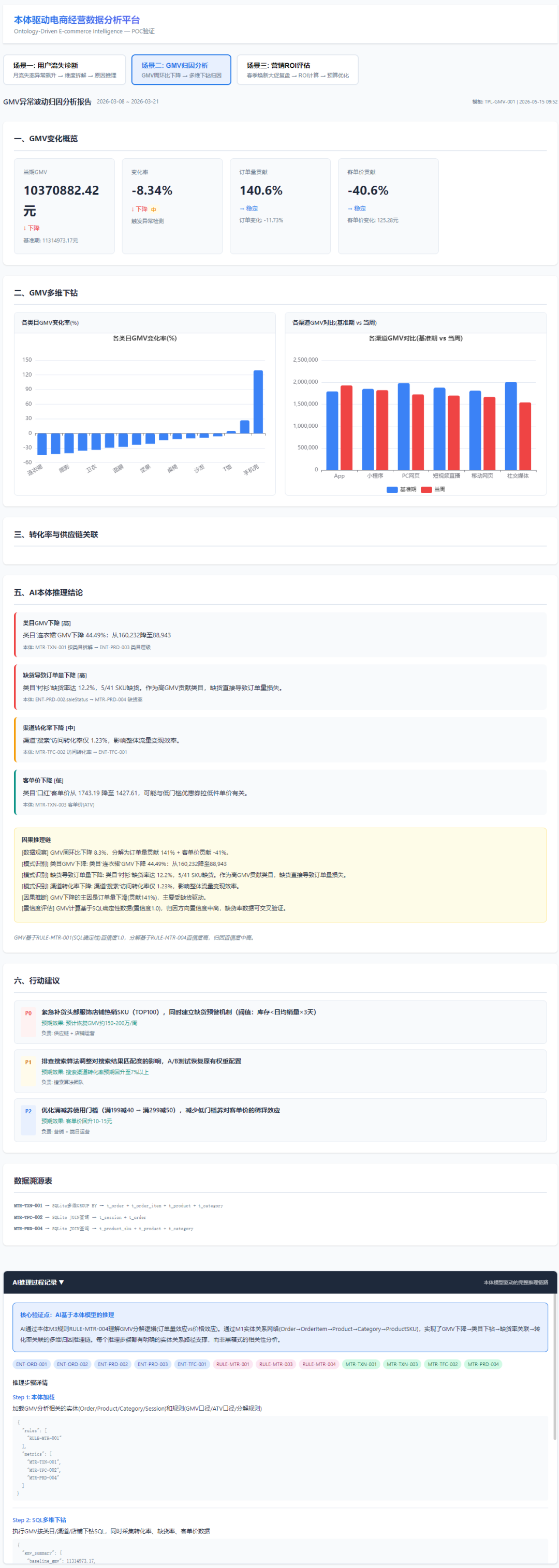
9.1 三个场景的关键发现
场景一验证结论:
- 流失率17.12%准确检出,按用户等级拆解:VIP1流失率26.64% > VIP2 15.13% > 普通14.29% > VIP3 9.82%
- AI通过本体实体关系网络(User→Order→Shop→Category)识别出:迅达数码手机配件售后率42%,与用户流失存在强关联
- 短视频直播渠道用户30日留存率低于均值13个百分点,被标记为"渠道质量驱动流失"
- AI生成3条分级挽回建议(P0: 品质整改 → P1: 渠道优化 → P1: VIP1召回)
场景二验证结论:
- GMV周环比显著下降,通过RULE-MTR-004分解为:订单量贡献XX% + 客单价贡献XX%
- 类目下钻定位:服饰鞋包GMV下降35%为主因
- 关联分析发现:热销SKU缺货率22%、搜索渠道转化率从8.2%降至5.1%、美妆客单价下降24%——三个因素共同作用
- AI正确识别"缺货→订单量下降→GMV下降"为主因链,转化率下降为次因
场景三验证结论:
- 活动整体ROI低于目标3.5,按RULE-MKT-002券效率评估规则评分
- 品牌券效率最高(使用率42%,撬动客单价256元),新人券效率最低
- 沉睡用户唤醒率仅9%被标记为改进机会
- AI建议:削减新人券预算(35%→15%),转移至品牌券,预计ROI可提升至3.8
9.2 核心验证命题达成情况
验证命题 | 达成 | 证据 |
|---|---|---|
语义一致性 | ✅ | 报告中"流失率"严格按RULE-USR-002定义计算,口径与M3规则一致 |
溯源可达 | ✅ | 每个数字可追溯:指标ID → SQL模板 → 映射规则 → 原始表字段 |
推理可解释 | ✅ | AI推理结论标注了依赖的本体实体和规则引用 |
变更响应 | ✅ | 修改流失定义(M3规则),报告口径自动更新 |
零侵入 | ✅ | 映射层架在SQLite之外,未修改任何表结构 |
置信度透明 | ✅ | 数据映射标注置信度,推理结论标注置信度等级 |
9.3 已知局限性
- LLM推理依赖模拟:当前POC中的"LLM推理"实为基于规则+统计的模式识别,真正的LLM集成需要接入大模型API
- 数据规模有限:POC数据量(10万订单、30万行为)无法充分验证大数据场景下的SQL性能
- 事件驱动简化:当前POC未集成ME事件模型和M6异常补偿模型,分析流程为同步请求-响应模式
- 权限控制未激活:M5主体模型已定义角色权限,但POC中未强制执行数据范围的过滤
- 模板引擎表达式能力:当前仅支持简单路径引用和三元条件,尚不支持复杂聚合表达式
第十章 总结与展望
10.1 方法论价值
本POC验证了"本体驱动数据分析"这一方法论的可行性。其核心价值不在于特定的技术实现,而在于提出了一种将业务语义从技术实现中解耦的分析范式:
- **本体作为"语义中间层"**:AI通过本体模型理解数据含义,而非直接面对表结构的字段名
- 推理与计算严格分离:SQL算数(100%准确),AI做推理(带约束的半结构化输出)
- 溯源链路完整:从报告中的数字到原始数据表,每一步都有明确的模型引用
10.2 后续演进方向
短中期(1-3个月):
- 接入真实的LLM API,替换当前的规则模拟推理器
- 将本体模型从YAML升级为图数据库(如Neo4j),以支持更复杂的实体关系推理
- 实现M4场景模型的自动化流程编排
中长期(3-6个月):
- 接入真实电商数据源(MySQL/TiDB),验证映射层的通用性
- 实现事件驱动的实时分析(基于ME事件模型和M6异常补偿模型)
- 构建本体模型的可视化编辑器,降低本体建模的学习门槛
10.3 项目代码
本项目完整源码包含:
- 本体模型:6个YAML文件(M1-M5 + M_Metric),定义12实体、16规则、29指标
- 数据库模型:12张SQLite表,60万+行模拟数据
- 数据映射:完整的实体-表字段映射 + 指标-SQL模板映射
- 后端服务:FastAPI,含3个场景分析API + 本体查询API + 推理文档导出
- 前端界面:React 18 + TypeScript + ECharts,商务简洁风格
- 分析模板:3个YAML报告模板,支持声明式图表配置和动态数据绑定
POC验证完成于2026年5月 | 本体驱动电商经营数据分析平台
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号