Litefuse 正式发布!Doris 原生 Agent 可观测平台来了

Litefuse 正式发布!Doris 原生 Agent 可观测平台来了

一臻数据
发布于 2026-05-25 16:52:27
发布于 2026-05-25 16:52:27
你的 Agent 其实是个黑盒
传统软件出了问题,翻日志、看报错栈、复现一下,基本能定位。但 Agent 不是这么工作的。
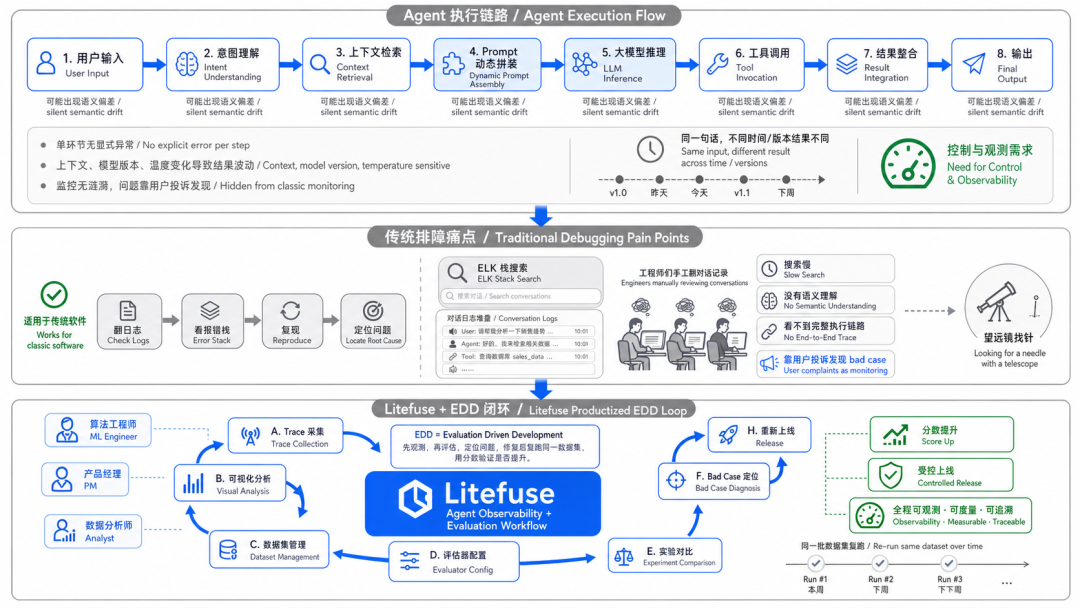
一次完整的 Agent 执行,链路可能是这样的:用户输入 → 意图理解 → 上下文检索 → Prompt 动态拼装 → 大模型推理 → 工具调用 → 结果整合 → 输出。
每一个环节都可能出问题,但每一个环节单独看又没有异常。
更麻烦的是,同样一句话,换个上下文、换个模型版本、温度参数稍微变一下,输出可能就完全不同。
Agent 犯错从来不是系统崩了,而是它在某个角落悄悄给出了一个语义上的偏差,而这个偏差在你的监控大盘上,连个涟漪都不会泛起。
很多团队发现 bad case 的方式,不是靠监控,而是靠用户投诉。这件事本身就挺尴尬的。
有个做 AI 客服的朋友跟我说,他们团队三个工程师,每周有两天在手工翻对话记录找问题。不是不想自动化,是根本没有合适的工具。
他们用的是传统 ELK 栈,搜索慢、没有语义理解、也看不到完整的 Agent 执行链路:"就像在用望远镜找针,找到了也不知道为什么针会在那里。"
这个痛点,正是 Litefuse 想解决的核心问题。
在聊 Litefuse 之前,有必要先说清楚一个概念——EDD,Evaluation Driven Development。
大家都熟悉 TDD,测试驱动开发。写测试、跑用例、代码通过、重构,这套方法论在传统软件里行之有效。
但放到 Agent 上,TDD 只能保证代码逻辑没问题,保证不了 Agent 说的话有没有问题。
Agent 的核心质量问题不是接口返回 200,而是:回答准不准?工具调没调对?任务路径合不合理?上下文有没有腐化?
这些问题,传统单元测试覆盖不到。
EDD 的逻辑是这样的:先观测 Agent 在真实环境里怎么跑,然后用评估器对输出打分,找出 bad case,定位问题所在,改完之后用同一批数据集再跑一遍,看分数有没有上来,上来了再上线。
听起来很朴素,但这个闭环背后需要一整套基础设施支撑:Trace 采集、可视化分析、数据集管理、评估器配置、实验对比……每一块单独做都不难,难的是把它们串成一个顺畅的工作流,让算法工程师、产品经理、数据分析师都能用得起来。
Litefuse 做的事,就是把这个闭环产品化。
Litefuse:Doris 原生 Agent 可观测平台
说到 Litefuse 的底层技术选型,这里值得重点展开,因为这是 Litefuse 区别于同类产品最有意思的地方。
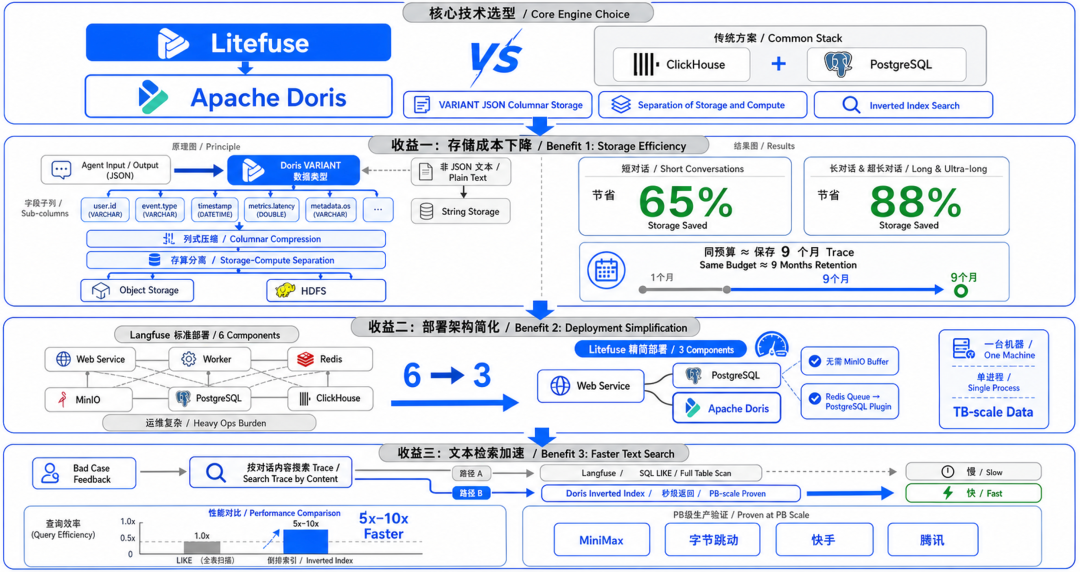
Litefuse 选择了 Apache Doris 作为核心数据引擎,而不是行业里更常见的 ClickHouse + PostgreSQL 组合。
这个决定直接带来了三个肉眼可见的收益:
第一个是存储成本。
在真实的 Agent 对话数据测试中,短对话场景 Litefuse 比 Langfuse 节省 65% 的存储空间,长对话和超长对话场景直接省了 88%。
背后的原理是 Doris 的 VARIANT 数据类型——Agent 的 input/output 绝大多数是 JSON 格式,VARIANT 会把 JSON 拆成字段子列存储,充分利用列式存储的压缩优势;对于非 JSON 的文本,也能自适应降级成字符串存储,不需要开发者做任何额外处理。
再加上 Doris 的存算分离模式,数据只需要写入一次、存一份,不需要多副本冗余,存储空间和写入计算资源都砍掉一半。
数据最终落在对象存储或 HDFS 上,存储单价本身就便宜,综合下来成本差距就拉开了。
对一个几万月活的 Agent 产品,这 88% 意味着?
你原本能保存一个月的 Trace,现在能保存将近九个月。或者同样的预算,你可以同时跑更多 Agent 实例,做更密集的效果评估。
第二个是部署架构。
Langfuse 的标准部署有 6 个组件:Web 服务、Worker、Redis、MinIO、PostgreSQL、ClickHouse。每一个都要运维,每一个都有出故障的可能,在私有化交付场景下这个负担非常重。
Litefuse 利用 Doris 的实时写入和服务端 group commit 能力,直接去掉了 MinIO 这个写入缓冲层,写入链路更短,数据实时性也更好。Redis 的异步队列功能用 PostgreSQL 插件替代。整体从 6 个组件压缩到 3 个,单机版甚至能合并成单进程形态,一台机器、一个进程,照样能处理 TB 级数据。
对于很多中小团队和私有化部署场景,这个简化程度是实质性的。
第三个是文本检索速度。
Agent 观测里有一个高频操作:某个用户反馈了 bad case,你需要根据对话内容去找到对应的 Trace。
Langfuse 的底层搜索用的是数据库 LIKE,数据量一大就是全表扫描,慢且吃资源。
Doris 从 2023 年开始支持倒排索引,搜索 Trace 的 input/output 文本能做到秒级返回,实测比 LIKE 方式快 5 到 10 倍。
MiniMax、字节跳动、快手、腾讯...这些公司已经在 PB 级生产环境里大规模用这个能力,稳定性有足够的背书。
一句 Prompt 就能接入
官网:https://litefuse.ai
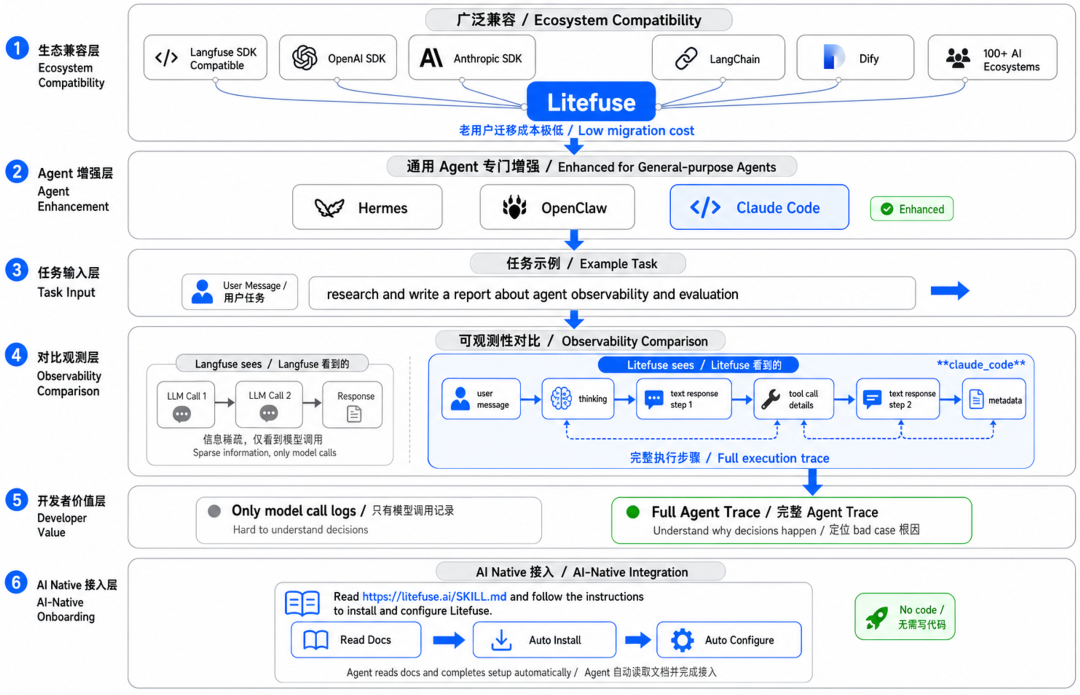
Litefuse 兼容 Langfuse SDK,支持 OpenAI SDK、Anthropic SDK、LangChain、Dify 等 100 多个 AI 生态,老用户迁移成本极低。
对于 Hermes、OpenClaw、Claude Code 这类通用 Agent,Litefuse 做了专门增强。
以 Claude Code 为例,当你给它一个任务:
“research and write a report about agent observability and evaluation
Langfuse 能看到的,大概就是若干次模型调用请求和响应。
Litefuse 能看到的,是完整的执行步骤:user message、thinking 过程、每一步的 text response、工具调用细节,以及所有元数据,统一放在 claude_code 层级字段下,方便后续查询和评估。
完整的 Agent Trace 和只有模型调用记录,对开发者来说差别不只是信息量,而是能不能真正理解 Agent 为什么做了某个决定。这是定位 bad case 根因的前提。
更简单的接入方式是:把下面这句话直接扔给你的 Agent:
Read https://litefuse.ai/SKILL.md and follow the instructions to install and configure Litefuse.
Agent 会自动读取配置文档、完成接入,全程不需要你写一行代码。
这个体验设计本身就很 AI Native 的。
结语
Agent 时代最大的工程挑战,已经从系统跑不跑得起来变成了Agent 做没做对事。前者有几十年的工具积累,后者现在才刚刚有像样的解法。
Litefuse 做的事并不神秘:把 Agent 的执行过程记录清楚,把效果评估的闭环做顺畅,把底层存储和检索的成本打下来。
但这三件事同时做好,并且用 Doris 把它们串在一起,是真正有工程价值的事情。
目前 Litefuse 已经上线 SaaS 服务(litefuse.cloud),提供 10 万条数据存储 1 个月的免费额度,阿里云 SelectDB 上也有独享实例可以开通。
如果你的团队正在做 Agent 开发,现在是试水的好时机——毕竟,不能量化的优化,都只是感觉良好而已。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号