当 AI 学会 解释自己——可解释人工智能如何驱动药物研发

当 AI 学会 解释自己——可解释人工智能如何驱动药物研发

DrugIntel
发布于 2026-05-26 19:53:24
发布于 2026-05-26 19:53:24

文献信息
- • 标题:Drug discovery with explainable artificial intelligence
- • 作者:José Jiménez-Luna, Francesca Grisoni, Gisbert Schneider
- • 机构:ETH Zurich(瑞士联邦理工学院)
- • 期刊:Nature Machine Intelligence,Vol. 2,2020年10月,pp. 573–584
- • DOI:10.1038/s42256-020-00236-4
一、背景:深度学习的"黑箱"困境
近年来,深度学习在药物研发领域取得了令人瞩目的进展。与传统机器学习和定量构效关系(QSAR)方法相比,深度神经网络在以下任务中展现出强大能力:
- • 分子活性预测:捕捉化学结构与生物活性之间的复杂非线性关系
- • 分子生成设计:从头设计具有特定药理性质的全新化合物
- • 化学合成规划:预测反应路径、指导逆合成分析
- • 蛋白质结构预测:为靶点识别提供结构基础
- • 药物-靶点相互作用预测:加速靶点确认与验证
然而,深度学习的强大能力往往以可解释性的丧失为代价。模型捕捉输入(化学结构表示)与输出(生物活性读数)之间复杂关系的能力越强,其内部决策逻辑对人类而言就越晦涩。
这一矛盾在药物研发中尤为突出。药物化学家长期依赖"经验法则"(rules of thumb)将生物活性与理化性质关联,这种对可解释、可验证模型的需求,在某些情境下甚至优先于模型精度本身。此外,"为错误原因给出正确答案"的Clever Hans效应在深度学习中普遍存在,若不加以识别,可能导致结论性错误。
正是在这一背景下,可解释人工智能(Explainable AI, XAI)成为药物研发领域亟待攻克的核心议题。
二、XAI 的定义与核心诉求
本文作者认为,一个面向药物设计的 XAI 系统,至少应具备以下四项核心属性:
属性 | 含义 | 药研意义 |
|---|---|---|
透明性(Transparency) | 系统如何得出某一特定答案 | 让化学家理解模型决策路径,增强信任 |
合理性(Justification) | 为何所给答案是可接受的 | 确保预测符合已知药物化学规律 |
信息量(Informativeness) | 向决策者提供新的洞见 | 揭示未知构效关系,驱动假说生成 |
不确定性估计(Uncertainty Estimation) | 量化预测的可靠程度 | 指导主动学习,规避高风险决策 |
此外,XAI 生成的解释可从两个维度分类:
- • 全局解释(Global):总结输入特征在整个模型中的重要性分布
- • 局部解释(Local):针对单个预测实例给出特征归因
两者各有用武之地,在实际应用中往往需要结合使用。
三、五大方法流派:系统梳理与深度解析
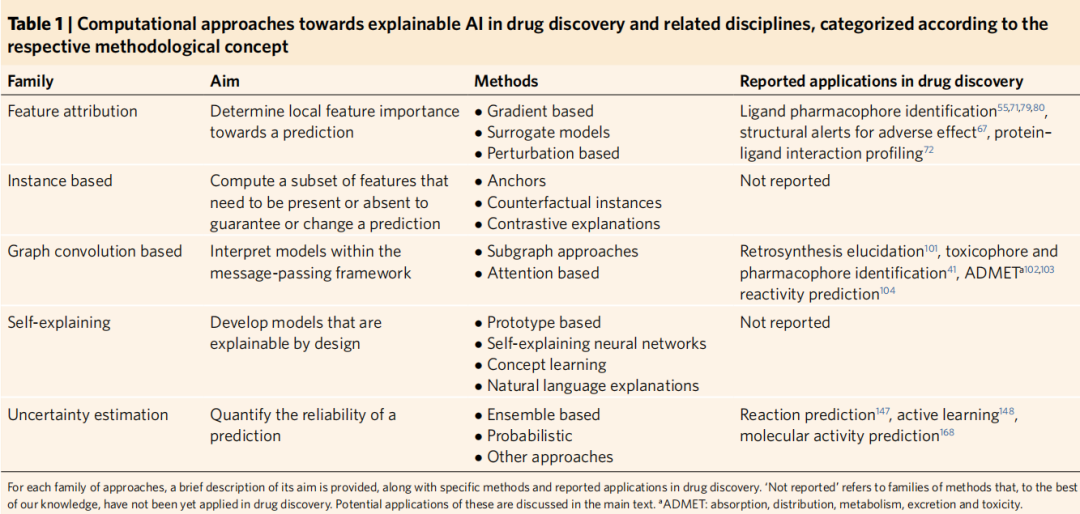
3.1 特征归因方法(Feature Attribution Methods)
特征归因是目前在药物发现中应用最广泛的 XAI 技术族。其核心目标是:给定一个模型 ,构造一个归因函数 ,输出每个输入特征对最终预测的贡献程度。
该大类下包含三个子类:
3.1.1 梯度法(Gradient-based)
通过计算模型输出对输入的偏导数 来衡量特征重要性。代表方法包括集成梯度(Integrated Gradients)和 SmoothGrad。梯度法依赖反向传播,计算效率高,但多项研究指出其可能仅能部分重构原始特征,存在误读风险。
药研应用:McCloskey 等人使用集成梯度检测神经网络模型中对配体结合相关的药效团(pharmacophore),但同时发现模型存在学习虚假关联的问题,强调了 XAI 验证的必要性。
3.1.2 代理模型法(Surrogate Model-based)
核心思路是构建一个可解释的近似模型 来拟合原始复杂模型 。加性特征归因方法(Additive Feature Attribution)是该子类的主流框架:
其中 代表第 个特征的重要性系数。代表方法包括:
- • LIME(Local Interpretable Model-agnostic Explanations):局部线性近似
- • SHAP(Shapley Additive Explanations):基于博弈论 Shapley 值,理论基础坚实
- • DeepLIFT:通过参考基准比较激活差异
- • 层级相关性传播(LRP):逐层反向传播相关性分数
全局代理模型(如决策树或决策集)则尝试整体描述模型 的计算逻辑,适用于对模型整体行为的宏观理解。
3.1.3 扰动法(Perturbation-based)
通过修改或遮蔽输入的特定部分,观察模型输出的变化来评估特征重要性。方法包括特征掩蔽(feature masking)、扰动分析(perturbation analysis)、响应随机化(response randomization)等。优点是可直接估计特征重要性,缺点是计算开销随特征数量增加而显著增大。
关键局限:特征归因方法的可解释性,根本上受限于所选择的分子表示(输入特征)。若使用"不透明"的分子描述符,即便归因结果精确,对化学家而言也难以理解。作者强烈建议使用对化学家具有直接意义的表示,如 SMILES 字符串中的原子-键类型、分子图等。
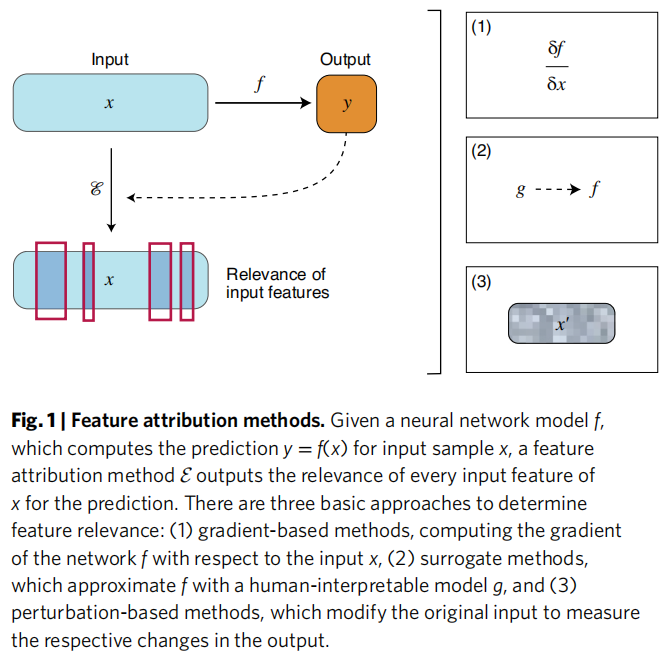
3.2 实例推理方法(Instance-based Methods)
实例推理方法从反事实推理(Counterfactual Reasoning)的视角出发,回答"如果……会怎样"的问题。其核心是计算一个特征子集,该子集的存在(或缺席)能保证(或改变)模型预测。
3.2.1 锚点算法(Anchors)
构建一组 if-then 规则,保证满足该规则集的样本以概率 被分类为目标类别:
锚点方法明确建模了解释的"覆盖范围"(coverage),这是其区别于其他局部方法的重要特性。
3.2.2 反事实实例搜索(Counterfactual Instance Search)
给定模型 和原始样本 ,寻找距 最近且被 分为不同类别的样本 :
第一项驱动预测改变,第二项约束 与 在特征空间中保持邻近。改进版本引入自编码器架构,使反事实样本更贴近真实数据分布。
3.2.3 对比解释方法(Contrastive Explanations)
同时生成"相关正例"(Pertinent Positives,保证正预测所需的最小特征集)和"相关负例"(Pertinent Negatives,保证区分其他类别所需的最小缺失特征集),形成形如"样本 x 被分为 y 类,因为特征 {x₁,...,xₖ} 存在,且特征 {xₘ,...,xₚ} 缺失"的解释。
潜在药研应用(文中指出尚未有实际应用报道):
- • 活性悬崖(Activity Cliff)预测:识别导致生物活性骤变的微小结构变化
- • 基于片段的虚拟筛选:高亮最小活性片段
- • 苗头化合物到先导化合物优化(Hit-to-Lead):识别最小必要结构改变
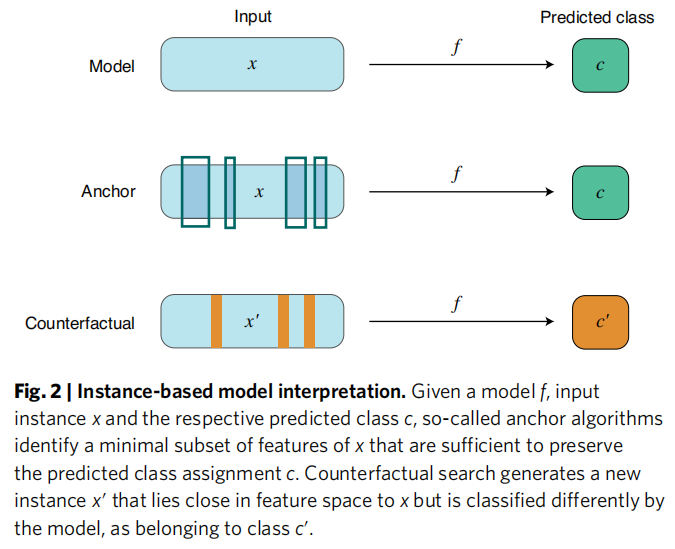
3.3 图卷积方法(Graph Convolution-based Methods)
分子图(Molecular Graph)是分子拓扑结构最自然的数学表示——原子为节点,化学键为边。图卷积神经网络(Graph Convolutional Neural Networks, GCNNs)作为神经消息传递(Neural Message-Passing)算法的特例,天然与这一表示契合,为可解释性创造了得天独厚的条件。
3.3.1 子图识别方法(Subgraph Identification)
GNNExplainer 是代表性的模型无关方法。给定节点 ,通过最大化互信息(Mutual Information)目标,识别对预测 贡献最大的子图 及节点特征 :
案例:GNNExplainer 在鼠伤寒沙门氏菌致突变性数据集上识别出多个已知致突变官能团(芳香族/杂芳香族硝基化合物),与文献结果高度一致。
3.3.2 注意力机制方法(Attention-based)
在图卷积的消息传递框架中引入注意力系数 ,使节点 在第 层的隐表示由其邻居特征的加权和计算:
注意力系数作为边级别的"重要性"指标,可直接可视化,指示哪些原子间相互作用对预测贡献最大。
已报道应用:
- • 溶解度、极性、合成可及性预测(识别相关分子子结构)
- • 化学反应性预测(识别合适反应伴侣和活化试剂)
- • 逆合成路径预测与可视化
- • ADMET(吸收、分布、代谢、排泄与毒性)性质预测
3.4 自解释方法(Self-explaining Approaches)
前述方法均属于事后解释(Post Hoc Interpretation),即先训练模型,再附加解释机制。自解释方法则将可解释性内置于模型设计之中,是更具前瞻性的研究方向。
3.4.1 基于原型的推理(Prototype-based Reasoning)
以贝叶斯案例模型(Bayesian Case Model)为代表,学习数据集中最具代表性的"原型"样本及其关键特征,以原型为基础进行预测,模拟人类"基于案例推理"的决策方式。神经网络版本(原型层网络)在隐空间中存储可学习的原型向量,通过编码距离进行预测。
3.4.2 自解释神经网络(Self-Explaining Neural Networks)
联合学习类别预测和特征-概念映射,网络由三部分组成:(1) 将原始输入映射为可解释概念的子网络;(2) 为每个概念生成系数的参数化器;(3) 聚合前两部分输出的汇聚函数。
3.4.3 概念激活向量测试(TCAV)
计算网络层激活相对于输入方向的导数,量化某一人类可解释概念(如"有芳香环")对特定预测的重要程度。
3.4.4 自然语言解释生成
深度网络与语言模型结合,直接生成人类可读的预测解释文本。受限于需要大量人工标注训练数据,在药研任务中的适用性尚存疑。
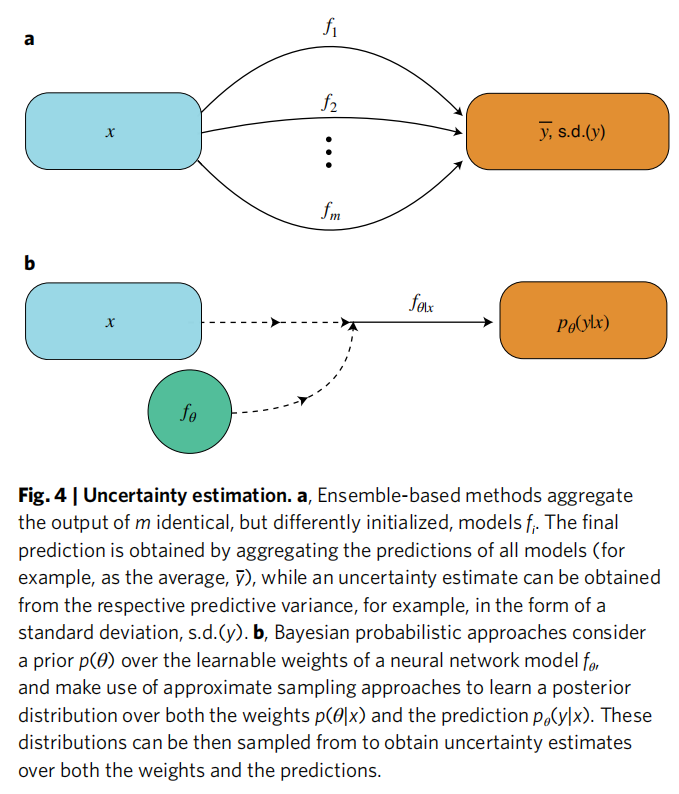
3.5 不确定性估计(Uncertainty Estimation)
不确定性估计是模型解释的另一维度,回答"这个预测可以相信到什么程度"的问题。
误差来源的区分
误差类型 | 来源 | 可减少性 |
|---|---|---|
认识论不确定性(Epistemic) | 模型选择和超参数的不确定性 | 可通过更多数据或更好模型减少 |
偶然论不确定性(Aleatoric) | 实验数据本身固有的噪声 | 不可减少,与建模无关 |
主要方法
集成方法(Ensemble-based):训练 个相同架构但不同初始化的模型,以预测均值为最终输出,以预测方差为不确定性估计。快照集成(Snapshot Ensembling)通过存储训练过程中的模型状态,降低计算开销。
概率方法(Probabilistic):将神经网络视为贝叶斯模型,对权重施加先验分布并推断后验。代表技术包括:
- • MC Dropout:以 Dropout 近似贝叶斯推断(Gal & Ghahramani, 2016)
- • 变分推断(Variational Inference)
- • 均值方差估计(Mean Variance Estimation):直接输出均值与方差
其他方法:信任分数(Trust Scores)、距离法(Distance-based)、LUBE 区间估计等。
药研中的应用:
- • 快照集成被用于建模 24 个生物活性数据集,表现与随机森林集成相当
- • Schwaller 等将不确定性估计整合进化学反应预测的 Transformer 模型
- • Zhang 等提出贝叶斯半监督图神经网络,在低数据场景下高效驱动主动学习
四、工作案例:XAI 解析细胞色素 P450 代谢
论文以 CYP3A4(一种参与约 75% 人体药物代谢的关键酶)为例,展示了 XAI 的实用价值。
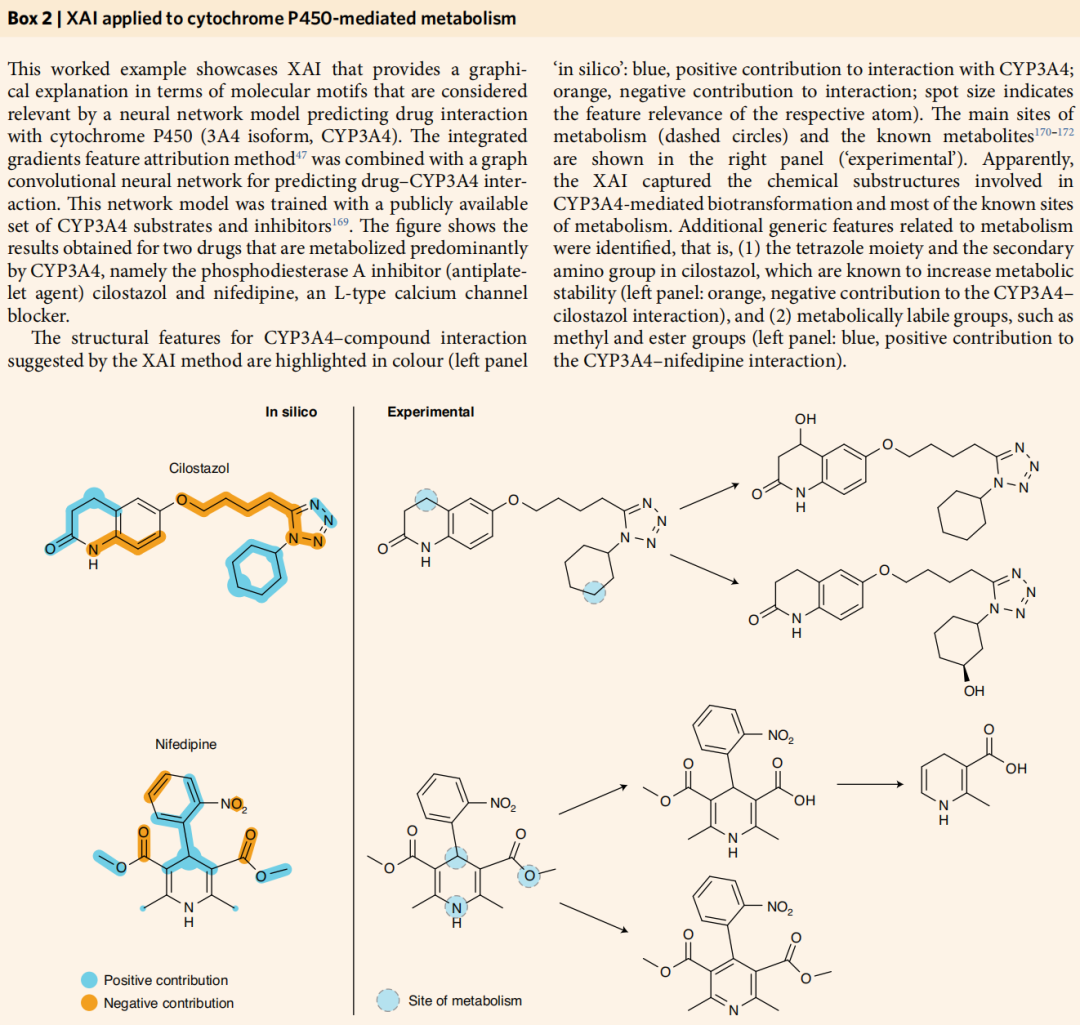
方法:集成梯度 + 图卷积神经网络,训练于公开的 CYP3A4 底物/抑制剂数据集
验证药物:
- • 西洛他唑(Cilostazol):磷酸二酯酶抑制剂(抗血小板)
- • 硝苯地平(Nifedipine):L 型钙通道阻滞剂
结果:
- • 模型成功捕捉到两种药物的主要代谢位点,与实验数据高度吻合
- • 额外识别出与代谢稳定性相关的通用特征:西洛他唑的四唑环和仲氨基(负贡献,增加代谢稳定性);硝苯地平的甲酯基和酯基(正贡献,为代谢活性位点)
这一案例表明,XAI 已能在真实药研场景中提供具有化学意义、且可被实验验证的解释。
五、当时现有软件工具
工具 | 描述 | 支持方法 |
|---|---|---|
Captum | PyTorch 官方可解释性扩展库 | 集成梯度、SHAP、LRP 等大多数特征归因方法 |
Alibi | 基于 scikit-learn / TensorFlow 的模型解释库 | 锚点算法、对比解释、反事实实例 |
六、挑战与局限
6.1 技术层面
- • 解释的多义性:同一模型和任务,可应用多种 XAI 方法,可能产生相互矛盾的解释
- • "开箱即用"的缺失:大多数方法需针对具体应用场景定制,缺乏标准化流程
- • 分子表示的制约:可解释性的上限由输入分子表示决定,"不透明"描述符(如哈希二进制指纹)严重限制解释质量
- • 应用域限制未被充分考虑:多数深度学习模型忽视了适用域(Applicability Domain)的评估,导致在域外样本上可能出现高置信度但错误的预测
6.2 实践层面
- • 领域知识不可或缺:需要深度学习专家与药物化学家的跨学科协作,才能判断哪些决策需要解释、什么样的解释是有意义的
- • 解释的非平凡性:XAI 生成的解释必须非平凡、非人工、对目标科学社区具有真实信息量
- • Clever Hans 问题:不确定性估计本身不足以规避模型"以错误理由给出正确答案"的风险,需与透明性和合理性评估结合
七、未来展望
作者指出,XAI 在药物发现中的未来发展将聚焦于以下方向:
- 1. 可解释分子表示的开发:构建对化学家直接有意义且适合机器学习的低层次表示(SMILES、氨基酸序列、三维体素表示),是未来数年的核心研究方向
- 2. 陪审团(Jury)共识方法:由于没有单一 XAI 方法能满足所有需求,融合多种算法和分子表示的组合方法将在短中期内扮演主导角色
- 3. 自解释方法的突破:将可解释性内置于模型设计,而非依赖事后解释,是长期理想目标
- 4. 开放社区与数据共享:MELLODDY 等联邦学习平台的兴起,有望推动跨机构的 XAI 方法开发、验证与接受
- 5. 适用域的系统整合:将适用域评估纳入 XAI 框架,成为预测可靠性的重要组成部分
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号