Hugging Face 推出 GOLD:让不同模型家族也能做知识蒸馏

Hugging Face 推出 GOLD:让不同模型家族也能做知识蒸馏

用户11563501
发布于 2026-06-23 10:22:19
发布于 2026-06-23 10:22:19
在最近Thinking Machines的新文章(见文末)里指出一种很有用的模型压缩技术——在线策略蒸馏(On-Policy Distillation),它通过从高性能“教师”模型的概率分布中转移知识来训练一个小的“学生”模型。这使得学生能够模仿教师的任务性能,同时显著减少大小和延迟。它让小模型在特定领域达到大模型的表现,成本却只有传统方法的十分之一。

但这里有一个知识蒸馏一直存在的痛点:老师和学生必须用同一套分词器。这意味着你不能让 Llama 向 Qwen 学习,也不能让 Gemma 向其他模型取经。这就好比一个说中文的老师,只能教懂中文的学生。
Hugging Face 的研究团队刚刚解决了这个问题。他们提出的 GOLD(General On-Policy Logit Distillation)方法,让任意两个模型之间(即使它们来自完全不同的模型家族)都能进行在线知识蒸馏,不管它们用的是什么分词器。
技术核心
出现这一问题的根源在于不对齐,比如:同一句话"Hugging Face is awesome!",在不同分词器下会变成完全不同的 token 序列:
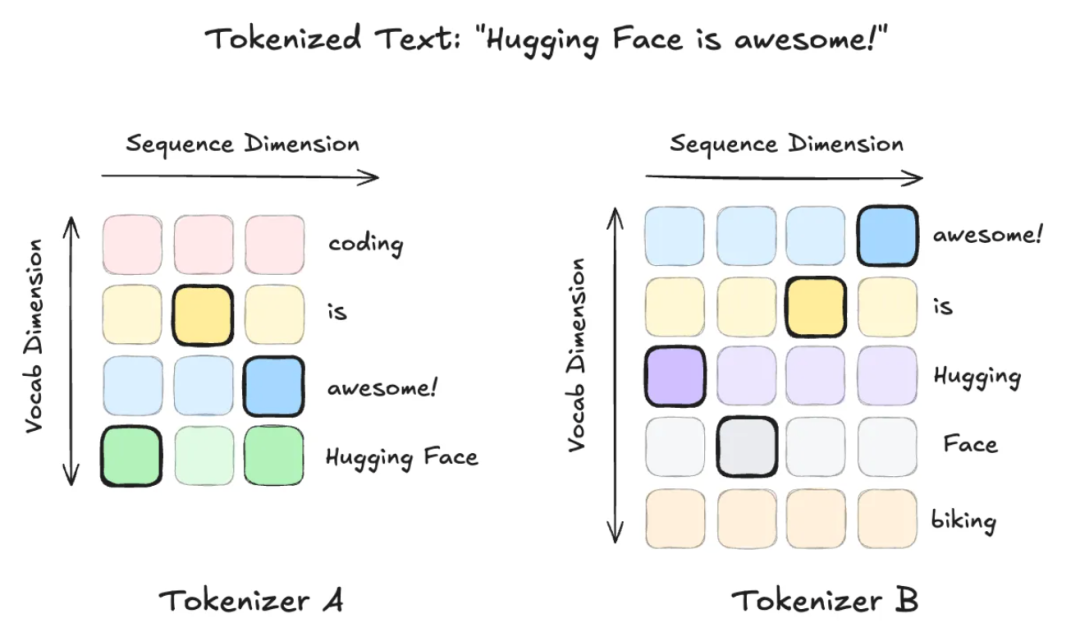
Tokenizer A:[3, 1, 2] Tokenizer B:[2, 3, 1, 0] 这种不匹配造成两个核心问题:序列长度不同,token ID 也不对应。之前的方法,如ULD(Universal Logit Distillation)只能简单截断到最短长度,丢失信息还容易错位。
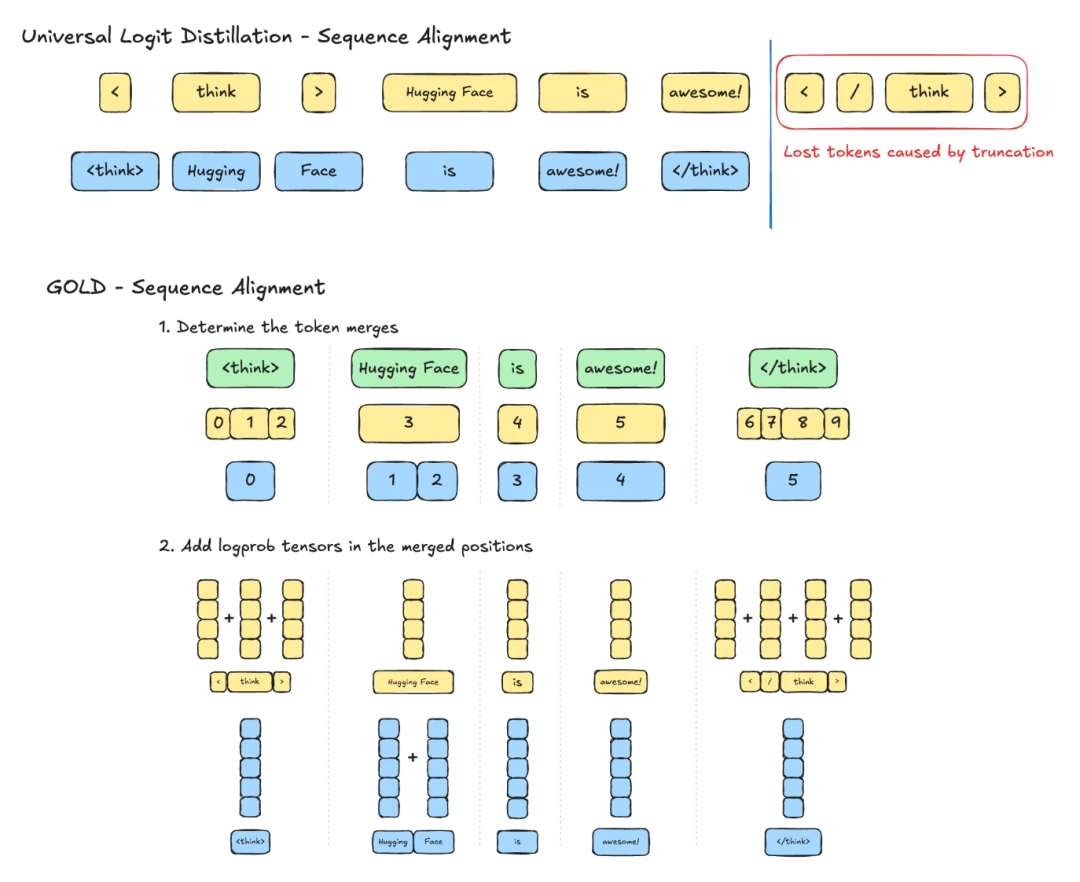
GOLD 通过三步解决跨分词器蒸馏:
- 增量解码:同时解码教师和学生模型的 token,获取各自的概率分布
- 文本对齐:将相同可见文本的片段分组,识别需要合并的 token 位置
- 概率合并:在每组内合并相关概率,通过对数概率求和保持语义完整性
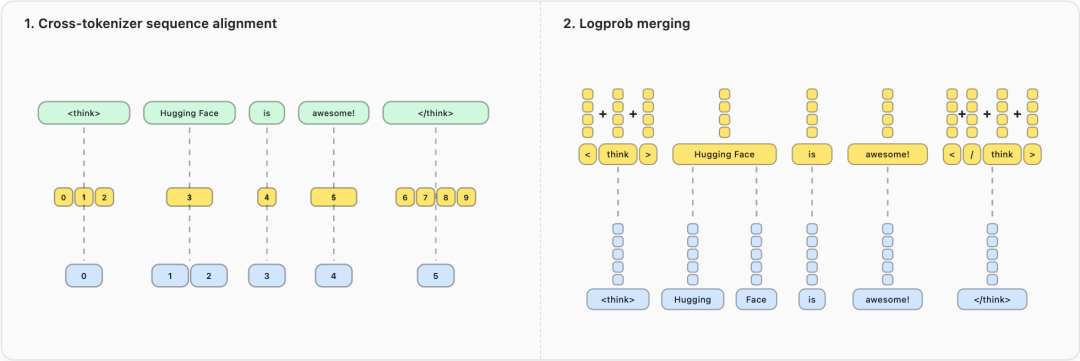
具体来说:
- 序列对齐:不再简单截断到最短长度,而是识别需要合并的 token,通过对数概率求和来合并语义相关的片段。这样"Hugging"和" Face"可以合并成一个完整的概念。
- 词汇对齐:先找出两个分词器中相同的 token(即使 ID 不同),对这些 token 使用直接映射;对无法匹配的部分,才回退到 ULD 的排序方法。最终损失函数结合两部分:L_GOLD = w1 * L_GKD + w2 * L_ULD
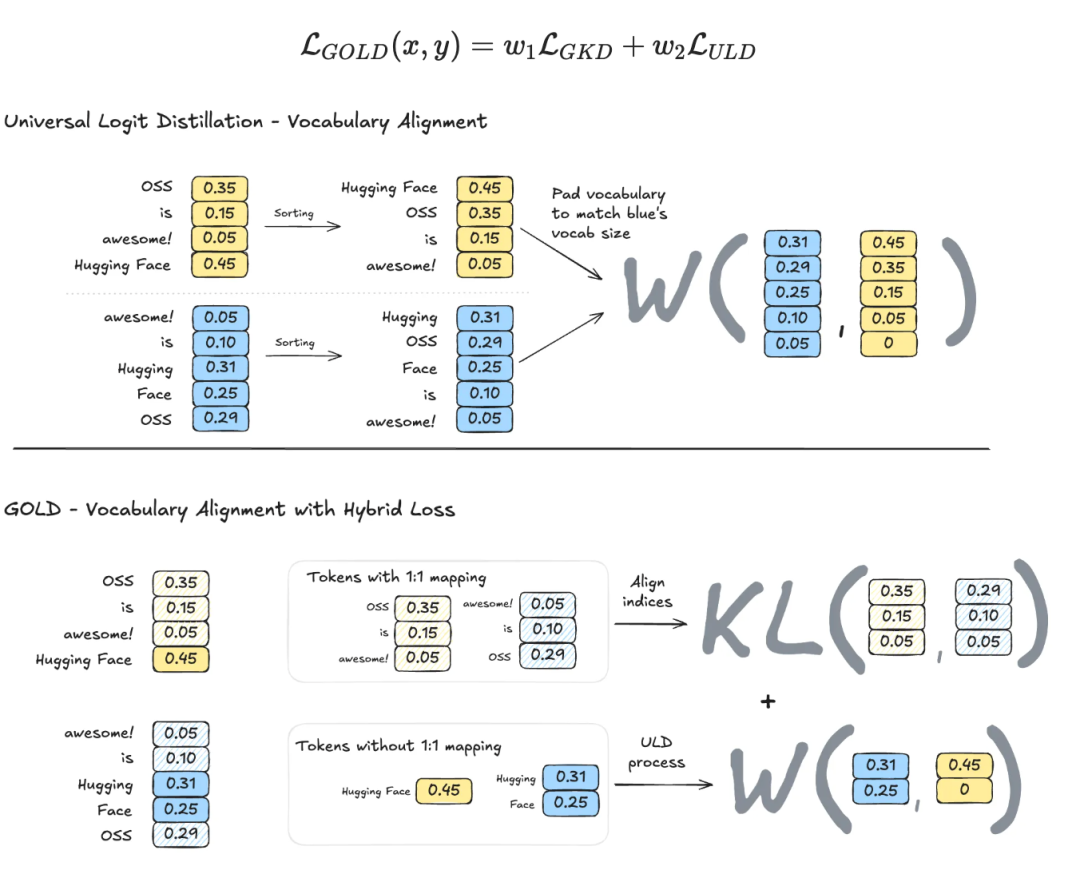
这样即使 token 边界不同,也能保证在完整输出上计算损失函数。
实验效果
数学任务跨家族蒸馏:用 Qwen 教师模型指导 LLaMA 学生模型,在数学任务上表现良好,甚至超过了 GRPO 方法。
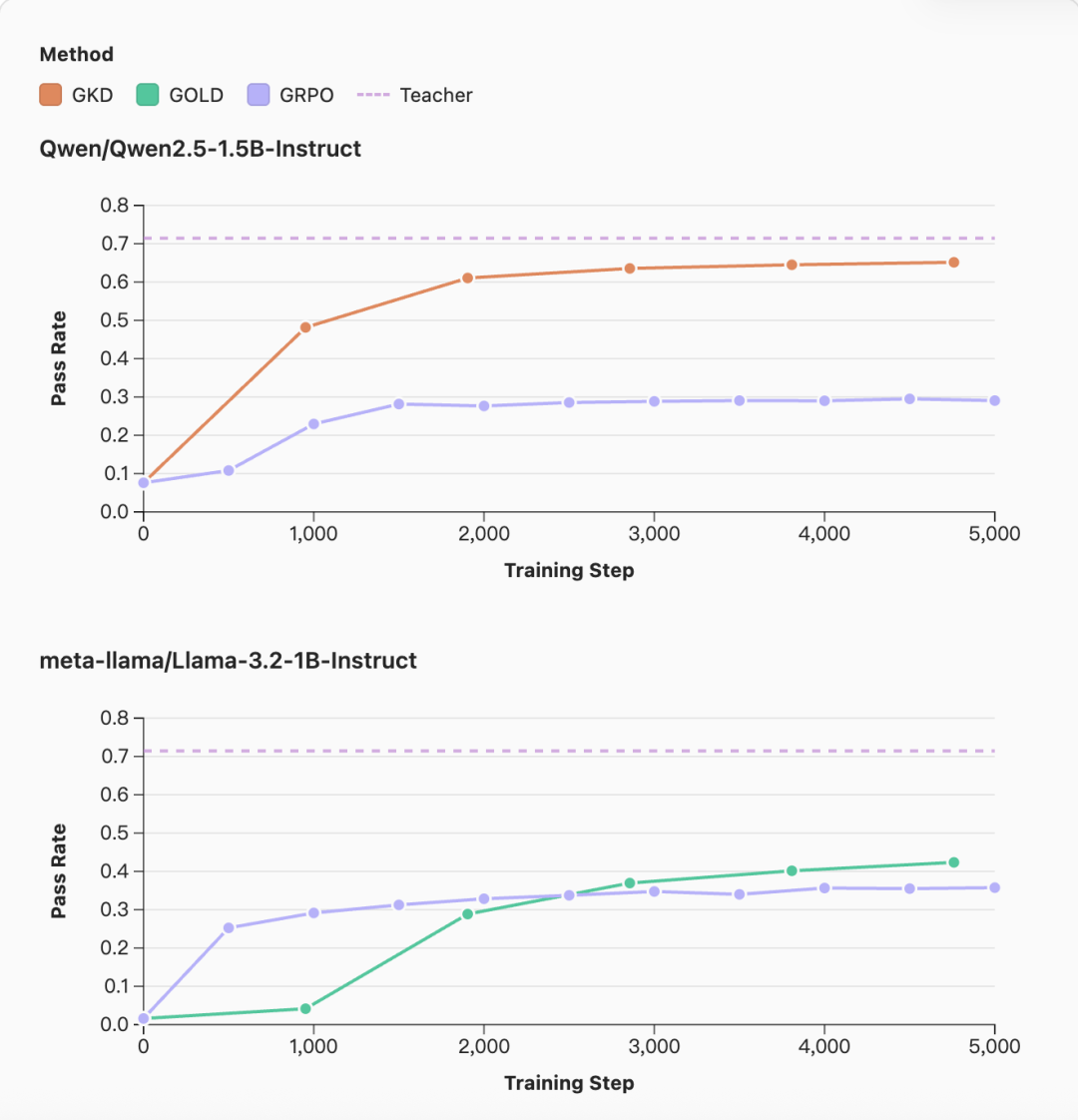
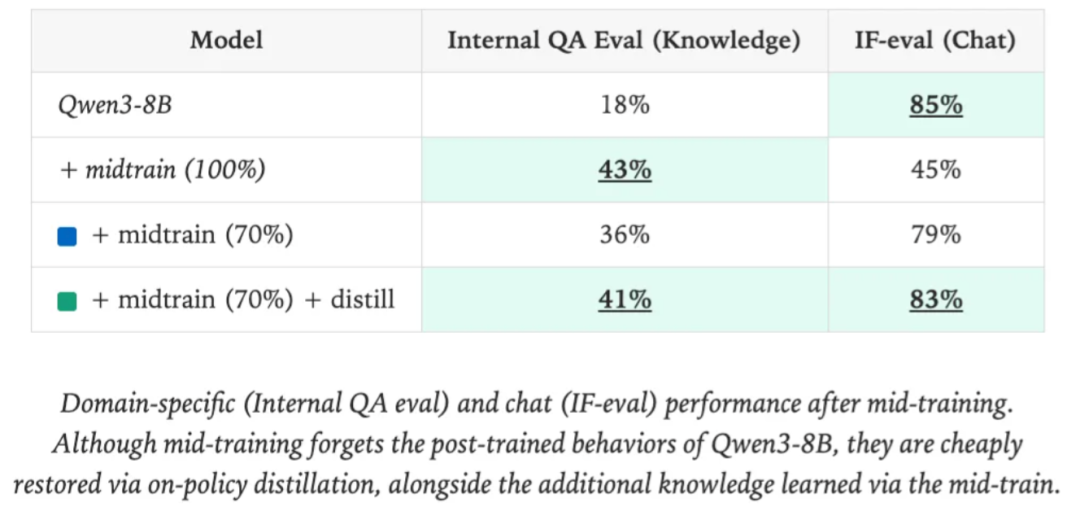
个性化(领域)蒸馏:先用 SFT 提升模型的代码能力,然后用蒸馏恢复 IFEval 分数。这验证了前面提到的"专业能力与通用能力平衡"问题的解决方案。
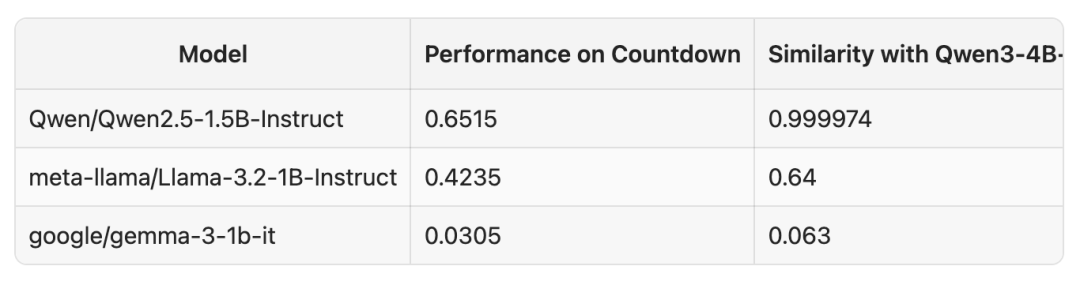
同时需要指出的是,分词器相似度确实影响效果,但仍然强于强化学习。Llama-3.2-1B 与 Qwen3-4B 的相似度 0.64,最终成绩 0.42;Gemma-3-1b 相似度只有 0.063,表现相应较差。
使用方法
GOLD 已经集成到 TRL 库中,使用相当简单:
from trl.experimental.gold import GOLDConfig, GOLDTrainer
trainer = GOLDTrainer(
model="meta-llama/Llama-3.2-1B-Instruct",
teacher_model="Qwen/Qwen2.5-0.5B-Instruct",
args=GOLDConfig(
output_dir="gold-model",
use_uld_loss=True,
teacher_tokenizer_name_or_path="Qwen/Qwen2.5-0.5B-Instruct"
),
train_dataset=train_dataset,
)
trainer.train()
更多:https://huggingface.co/docs/trl/main/en/gold_trainer
想要在自己的场景尝试在线策略知识蒸馏,官方给出了如下是利用Accelerate训练的(Accelerate是什么?可以阅读此书:)配置用例:
- SFT配置:
accelerate launch \
--config_file examples/accelerate_configs/multi_gpu.yaml trl/scripts/sft.py \
--model_name_or_path Qwen/Qwen3-4B-Instruct-2507 \
--dtype auto \
--attn_implementation kernels-community/flash-attn \
--dataset_name open-r1/codeforces-cots \
--dataset_config solutions_decontaminated \
--bf16 \
--gradient_checkpointing \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 32 \
--learning_rate 1e-5 \
--num_train_epochs 1 \
--max_length 16384 \
--logging_steps 1 \
--report_to trackio \
--trackio_project Qwen3-4B-SFT-Codeforces \
--output_dir data/Qwen3-4B-SFT-Codeforces \
--push_to_hub \
--hub_model_id <your-username>/Qwen3-4B-SFT-Codeforces \
--seed 42 \
--warmup_ratio 0.05 \
--lr_scheduler_type cosine_with_min_lr \
--use_liger_kernel
- 蒸馏配置:
accelerate launch \
--config_file examples/accelerate_configs/multi_gpu.yaml trl/experimental/gold/gold.py \
--model_name_or_path <sft-model> \
--dtype auto \
--attn_implementation kernels-community/flash-attn \
--dataset_name allenai/tulu-3-sft-mixture \
--dataset_train_split train \
--bf16 \
--learning_rate 1e-7 \
--gradient_checkpointing \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 64 \
--num_train_epochs 1 \
--eval_strategy steps \
--eval_steps 100 \
--temperature 1.0 \
--top_p 0.95 \
--top_k 0 \
--max_new_tokens 2048 \
--max_prompt_length 512 \
--lmbda 0.25 \
--beta 0.0 \
--use_uld_loss \
--use_extended_uld \
--uld_use_hybrid_loss \
--uld_crossentropy_weight 0.0 \
--uld_distillation_weight 1.0 \
--uld_student_temperature 1.0 \
--uld_teacher_temperature 1.0 \
--uld_hybrid_unmatched_weight 1.0 \
--uld_hybrid_matched_weight 1.0 \
--teacher_model_name_or_path Qwen/Qwen3-4B-Instruct-2507 \
--logging_steps 1 \
--push_to_hub \
--hub_model_id <your-username>/Qwen3-4B-GKD-Tulu \
--report_to trackio \
--trackio_project Qwen3-4B-GKD-Tulu \
--seed 42 \
--warmup_ratio 0.05 \
--lr_scheduler_type cosine_with_min_lr
小结
这一突破非常有实用价值。以前你只能在同一家族内做知识蒸馏,现在可以跨家族进行。在线策略蒸馏对于需要在资源受限环境下部署高性能模型的场景特别有用,可以用最好的模型作为教师,采各家所长,训练出适合自己场景的模型。
On-Policy Distillation:https://thinkingmachines.ai/blog/on-policy-distillation/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号