TerraSynth:打通 AI 药物设计与化学合成之间的壁垒

TerraSynth:打通 AI 药物设计与化学合成之间的壁垒

DrugIntel
发布于 2026-06-24 14:05:08
发布于 2026-06-24 14:05:08
AI 设计了分子,然后呢?——TerraSynth 的回答
文献来源:Terray Therapeutics 技术博文 标题:TerraSynth: Accelerating the Synthesis of AI-designed Small Molecules 发布日期:2026 年 6 月 11 日 作者团队:Miles Wang-Henderson, Zack Strater, John Parkhill, Matthew Katcher, Narbe Mardirossian 原文链接:https://www.terraytx.ai/news-and-research/terrasynth
导读摘要
本文介绍了 Terray Therapeutics 最新发布的生成式合成规划模型 TerraSynth,其核心创新在于将 AI 分子设计与合成路线规划融为一体,从根本上解决了药物研发 DMTA 循环中"合成"环节长期以来的效率瓶颈。
主要成果如下:
- • 在 ChEMBL 数据集上,分子重建率较次优基线(ReaSyn)高出 67%(53.8% vs 32.1%)
- • 推理速度约为 0.05 秒/分子,较次优基线快约 1000 倍
- • 在 17 个内部真实药物研发项目中,AI 设计分子的实验室合成速度提升 2–4 倍
- • 优化版工作流下,4 周内合成完成率达 90%,较无约束基线的 8 周达到 50% 完成率有质的飞跃
一、问题的本质:DMTA 循环的隐形瓶颈
现代小分子药物研发的核心迭代机制是 DMTA 循环(Design-Make-Test-Analyze,设计—合成—测试—分析)。这一循环决定了一个项目从苗头化合物(hit)到临床前候选分子(clinical candidate)所需的时间与资源。
长期以来,"设计"(Design)步骤被视为主要瓶颈,AI 的大规模应用将其大幅加速。然而,随着设计端效率提升,一个长期被忽视的矛盾逐渐浮出水面:
AI 能在几分钟内生成数千个虚拟候选分子,但合成这些分子往往需要数周乃至数月, 甚至完全合成不了。
导致这一问题的结构性原因有三:
- 1. AI 设计的分子往往结构新颖、合成路径未知:现有 AI 分子生成模型(如基于 SMILES/图神经网络的变分自编码器)大多在化学空间中自由探索,并不考虑目标分子是否存在可执行的合成路径。
- 2. 逆合成搜索引擎速度慢、覆盖率有限:传统逆合成工具(如 AiZynthFinder)采用 MCTS 递归搜索,每个分子平均需 ~30 秒,且无法用于生成新分子,仅能评估。
- 3. 设计与合成的信息鸿沟未被弥合:设计员在提出分子时缺乏合成可行性的即时反馈,导致大量优化资源浪费在"无法被合成"的方向上。
TerraSynth 正是为解决这一结构性矛盾而生。
二、TerraSynth 的技术框架
2.1 定位:生成式合成规划器,而非逆合成搜索引擎
理解 TerraSynth 的第一步,是明确其与传统逆合成工具的根本差异:
维度 | 逆合成搜索引擎(如 AiZynthFinder) | TerraSynth(生成式合成规划器) |
|---|---|---|
输入 | 目标分子 | 分子潜空间中的向量 |
输出 | 合成路线 | 分子 + 合成路线(联合生成) |
能否设计新分子 | ❌ 否 | ✅ 是 |
速度 | ~30 秒/分子 | ~0.05 秒/分子 |
用于优化器内循环 | ❌ 否 | ✅ 是 |
TerraSynth 是一个前向合成规划器(forward synthesis planner):它从原料出发,以"正向"的方式生成路线直至产物,而非像逆合成引擎那样从目标分子反向拆解。这一特性使其能够与分子设计优化器无缝集成。
2.2 架构设计
TerraSynth 的核心架构要素如下:
(1)基础分子表示:COATI
TerraSynth 依托 Terray 自研的小分子多模态基础模型 COATI(Contrastive AI for Chemistry)。COATI 能够对 SMILES 字符串、分子图和三维点云进行联合嵌入,产出统一的分子潜向量。TerraSynth 的分子"输入"和"输出"均通过 COATI 的潜空间进行编解码。
(2)自回归解码器
TerraSynth 是一个 20 亿参数(2B) 的自回归 Transformer 解码器,以后缀表示法(post-fix notation)对合成路线进行 token 化序列建模。每条路线被表示为原料构件(building block)、反应类型(reaction)和中间产物(intermediate)的有序 token 序列,由堆栈弹出机制管理中间体的消耗与生成。
(3)数据引擎与预训练
TerraSynth 使用自研数据引擎生成约 300 亿(~30B) 高质量路线 token 进行预训练,每条合成路线最多包含 6 步反应,支持线性与收敛两种路线拓扑。数据引擎的核心约束是 260 种经工业验证的化学转化反应模板,结合可购原料库(building-block catalog)采样,确保路线的化学真实性。
(4)强化学习后训练(RL Post-training)
为进一步提升路线质量,TerraSynth 引入了基于规则的 RL 后训练,以可解释奖励函数(reward function)惩罚常见合成化学违规,重点关注三类问题:
- • 路线经济性(Route Economy):冗余步骤、不必要的中间体构建
- • 化学选择性(Chemoselectivity):在含多个官能团的分子上错误选择反应位点
- • 位点选择性(Site-selectivity):在结构相似的候选位点间做出错误选择
RL 采用"轻度偏离策略(lightly off-policy)"设置:行为策略通过测试时搜索(TTS)采样高质量重建路线,再通过**遮罩重要性采样(Masked Importance Sampling, seq-MIS)**过滤似然比偏差过大的轨迹,从而在质量收益与训练稳定性之间取得平衡。
后训练在 Enamine REAL N=1,000 子集上的效果如下:
失效类型 | 基础模型均值 | 后训练后均值 | 改善幅度 |
|---|---|---|---|
路线经济性 | 0.50 | 0.14 | −72% |
化学选择性 | 0.40 | 0.30 | −25% |
位点选择性 | 0.43 | 0.28 | −35% |
三、三大核心能力
TerraSynth 的设计围绕三个相互制约、缺一不可的核心维度展开:
3.1 表达力(Expressiveness):覆盖药化学空间
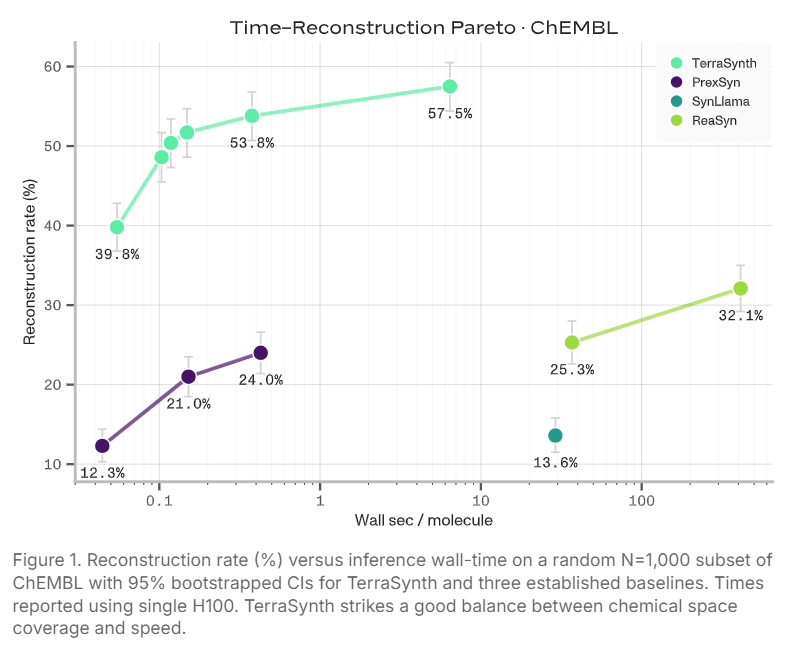
表达力以重建率(Reconstruction Rate)衡量:给定一个目标分子,合成规划器能否输出至少一条路线使产物与目标完全匹配(精确 canonical SMILES 匹配)?
TerraSynth 在多个基准数据集上的表现如下(M=256 采样,标准变体):
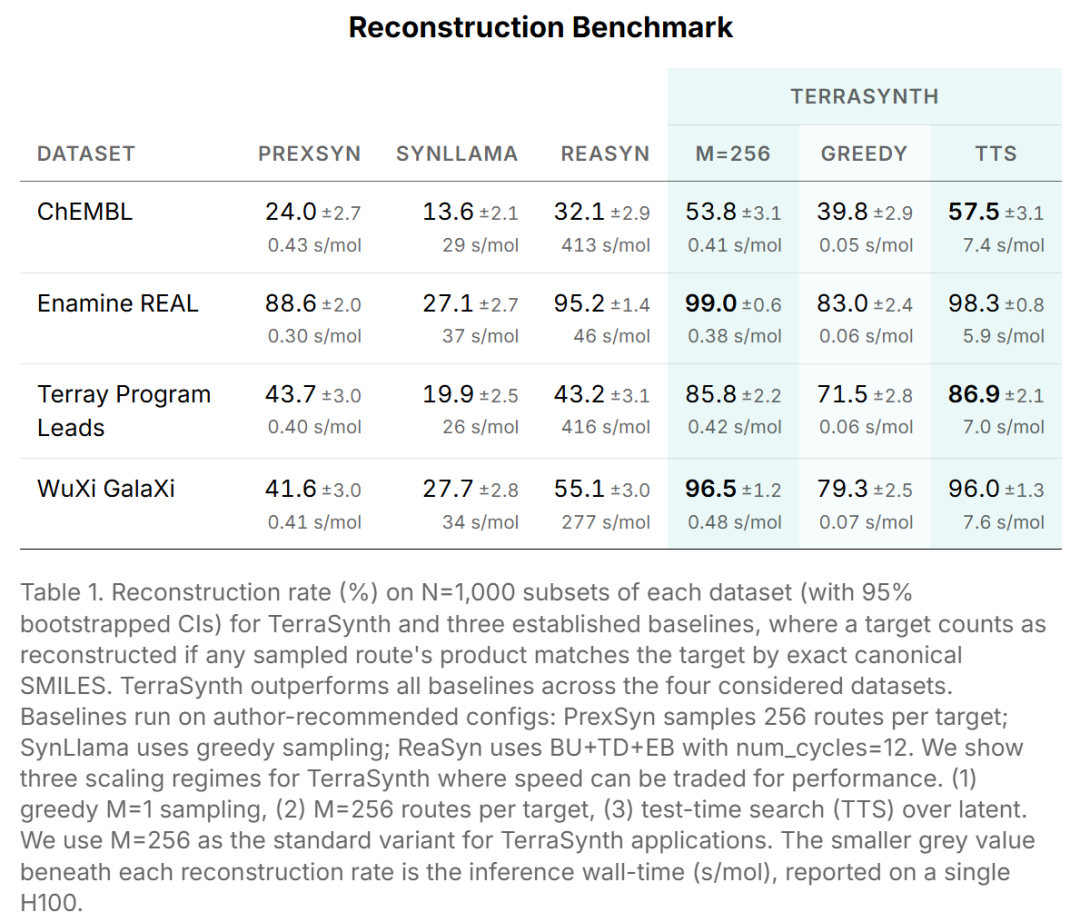
数据集 | PrexSyn | SynLlama | ReaSyn | TerraSynth |
|---|---|---|---|---|
ChEMBL | 24.0% (0.43 s/mol) | 13.6% (29 s/mol) | 32.1% (413 s/mol) | 53.8% (0.41 s/mol) |
Enamine REAL | 88.6% (0.30 s/mol) | 27.1% (37 s/mol) | 95.2% (46 s/mol) | 99.0% (0.38 s/mol) |
Terray 内部候选分子 | 43.7% (0.40 s/mol) | 19.9% (26 s/mol) | 43.2% (416 s/mol) | 85.8% (0.42 s/mol) |
WuXi GalaXi | 41.6% (0.41 s/mol) | 27.7% (34 s/mol) | 55.1% (277 s/mol) | 96.5% (0.48 s/mol) |
特别值得关注的是 WuXi GalaXi 和 Terray 内部分子这两个数据集——它们代表了真实药物研发中的复杂化学结构,TerraSynth 在这两个数据集上的重建率分别为 96.5% 和 85.8%,远超所有基线。相比之下,ReaSyn 在 WuXi GalaXi 上仅为 55.1%,且推理耗时约是 TerraSynth 的 600 倍。
TerraSynth 还支持测试时扩展(Test-Time Search, TTS):通过在 COATI 条件潜空间上进行搜索,以额外计算换取更高重建率(ChEMBL 上 TTS 模式可达 57.5%)。
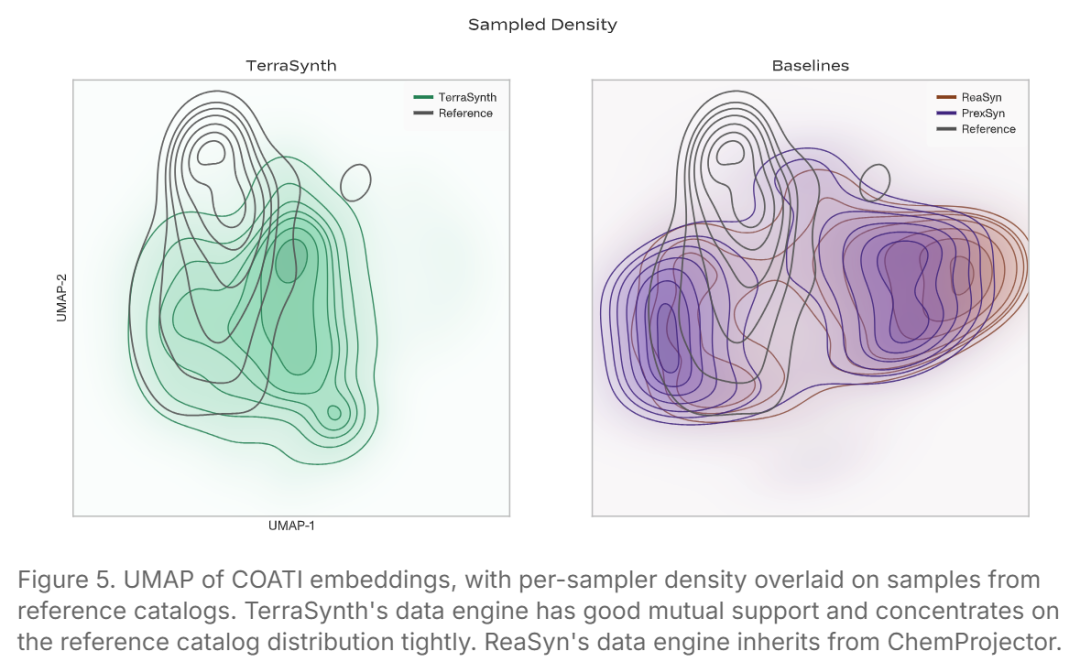
数据引擎的关键优势
TerraSynth 数据引擎生成的分子在化学空间分布上更接近药物化学的真实需求。通过 COATI 嵌入后 UMAP 降维可视化,TerraSynth 的预训练数据与 ChEMBL/Enamine REAL/WuXi GalaXi 的参考分布高度重合;MMD 和 FID 指标均优于同类基线(MMD: 0.023 vs PrexSyn 0.028 vs ReaSyn 0.050,以 ChEMBL 为参考)。

3.2 可行性(Feasibility):合成路线化学上切实可执行
重建率高意味着模型能"覆盖"目标分子,但不等于输出的路线在化学上合理。TerraSynth 引入的 Solv 分级框架(来自 Terray 合作的 Syntax of Matter 文献)提供了系统性的评估维度:
- • Solv-1:模型输出了一条从可购原料到目标分子的路线(重建成功)
- • Solv-2C:路线在化学选择性上无误(不同官能团的区分正确)
- • Solv-2R:路线在位点选择性上无误(相同类型官能团的区分正确)
- • Solv-3:路线在实验层面真正可行(实际条件、产率、纯化方法均合理)
TerraSynth 目前已达到 Solv-2C 和 Solv-2R 水准,并将 Solv-3 列为下一阶段目标。
RL 后训练对选择性错误的定向改善是迈向 Solv-2 的关键一步。论文展示了一个典型案例:在酰胺化反应中,预训练模型选择了含有两个羧酸的原料,导致多产物问题;经后训练后,模型自动选择仅含一个羧酸的原料,规避了位点选择性陷阱。
3.3 可优化性(Optimizability):在合成约束下搜索活性分子
TerraSynth 的第三个核心优势是可嵌入设计优化器的内循环中使用。通过将 TerraSynth 替换 COATI 的无约束解码器,遗传算法(GA)优化器在搜索高活性分子的同时,自动确保每个提案分子具有合成路线。
论文以 BTK 激酶(UniProt Q06187)为靶点,使用 TerraBind(Terray 的通用效价预测模型)预测 pIC50,并以 AiZynthFinder(AZF)的独立逆合成结果作为合成可行性的无偏代理指标(unbiased proxy)进行验证:
指标 | 无约束基线(COATI 解码器) | TerraSynth |
|---|---|---|
AZF 中位路线步数 | 4 步 | 2 步 |
AZF 不可解分子比例 | 62% | 38% |
帕累托前沿(高效价 + 短路线) | 劣 | 优 |
TerraSynth 提案的分子在效价预测上与无约束基线相当,却以更短的合成路线实现,且更多分子可被独立逆合成引擎验证——这有力说明合成约束并未削弱分子质量,而是在同等质量下显著降低了合成复杂度。
四、真实验证:17 个内部药物研发项目的实测数据
性能基准之外,TerraSynth 最具说服力的证据来自 Terray 内部真实药物研发项目的前瞻性评估(prospective assessment)。
研究团队追踪了 17 个需要定制合成的项目,按时间节点分为三组:
第一组(8 个项目,N=112 个化合物)—— 无约束基线
AI 设计阶段不引入合成规划约束,分子由化学家自行评估合成可行性后推进。
第二组(5 个项目,N=72 个化合物)—— TerraSynth 初版
采用 TerraSynth 进行合成约束设计,但未做进一步工作流优化。
第三组(4 个项目,N=60 个化合物)—— TerraSynth 优化工作流
在 TerraSynth 基础上增加两项优化:
- 1. 共享中间体策略:对同一批次提案分子进行联合优化,使其共用关键合成中间体,降低整体合成复杂度
- 2. 化学家主动筛选:从每个项目的 22 个初始设计中,由药物化学家根据合成难度筛选出 15 个进入合成队列
累计合成完成率对比(关键节点):
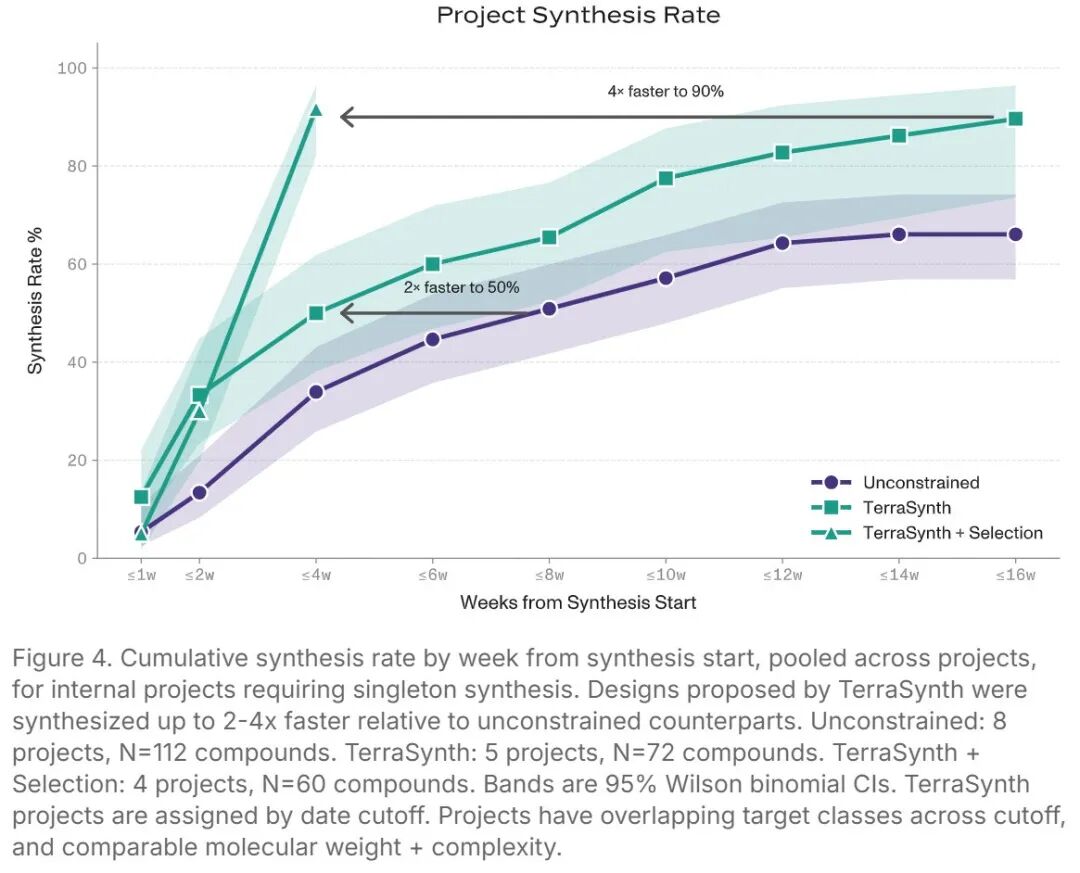
时间节点 | 无约束基线 | TerraSynth 初版 | TerraSynth 优化版 |
|---|---|---|---|
2 周 | 13% | 33%(↑ 2.5×) | 90%(↑ 7×) |
4 周 | ~35% | ~66% | 90% |
达到 50% 所需时间 | 8 周 | ~5 周 | <2 周 |
达到 90% 所需时间 | >16 周 | ~10 周 | 4 周 |
这意味着:每个 DMTA 迭代周期可节省数周乃至数月的合成等待时间。 在竞争激烈的新药研发赛道,这不仅是效率优化,更是战略性优势。
作者还特别指出,三组项目在目标靶点类别、分子量和复杂度上具有可比性,排除了混淆因素的影响,使对比具有较强的因果推断效力。
五、技术深度:数据引擎与"合成语言学"框架
5.1 数据引擎的设计哲学
TerraSynth 的预训练数据完全来自自建的合成路线采样引擎,而非公开数据库(公开的端到端标注合成路线数据极为稀缺)。
数据引擎的核心机制:从 260 种精选反应模板库和可购原料库出发,随机拼接相互兼容的反应步骤,生成(产物分子, 合成路线)元组作为预训练数据。这一机制的关键设计选择:
- • 反应模板是可行性的归纳偏置:只有在模板库中有对应记录的反应才会被采样,从根本上约束了模型的"想象空间"
- • 最多 6 步深度,支持收敛路线:覆盖了现代药化合成的主流复杂度范围
- • 与参考化学空间的分布对齐:通过 MMD/FID 定量评估数据引擎与 ChEMBL/REAL/WuXi 的分布距离,持续迭代优化采样策略
5.2 Solv 框架:合成规划的"有效性时代"
论文引用并拓展了 Syntax of Matter(Morgunov et al., 2026)中的 Solv 评估框架,为整个领域提供了系统性的模型质量评估坐标系。这一框架与 LLM 数学推理领域的"验证器训练"思路高度类似:
仅仅找到"某条"到达目标的路线(Solv-1)是不够的。在"有效性时代",我们要求路线必须在化学逻辑上正确(Solv-2),并最终在实验室中真正可行(Solv-3)。
RL 后训练阶段正是从 Solv-1 向 Solv-2 跃迁的关键工程实践,其思路与 LLM 的过程奖励模型(PRM)训练有异曲同工之妙。
六、横向比较:与现有方法的差异定位
TerraSynth 的论文对比了四个基线:
模型 | 方法类型 | 核心特征 | 主要局限 |
|---|---|---|---|
PrexSyn | 生成式合成规划器 | 速度较快,与 COATI 速度相近 | 化学空间覆盖率显著低于 TerraSynth |
SynLlama | LLM 微调合成规划器 | 基于大语言模型 | 速度慢(~30 s/mol),重建率低 |
ReaSyn | 生成式合成规划器 | 基于 ChemProjector 数据引擎 | 速度极慢(~277–416 s/mol),数据引擎覆盖率低 |
Synformer | 生成式合成规划器 | 早期工作 | 速度与覆盖率均不及 TerraSynth |
TerraSynth 的差异化定位可概括为:在药化相关化学空间内,以最高重建率 × 最快推理速度的组合,实现嵌入优化器内循环的工程级合成规划。
七、局限性与未来方向
7.1 当前局限
作者坦诚地指出了若干尚未解决的问题:
- • Solv-3 尚未实现:目前的 RL 奖励函数仍是基于规则的近似,无法覆盖实际实验条件(溶剂、温度、催化剂、产率等)的全部复杂性
- • 评估数据集的代表性:基准数据集(ChEMBL、Enamine REAL 等)与真实药物化学项目的化学空间存在差距
- • 强化学习奖励设计的局限:选择性错误的判断依赖启发式规则,复杂的保护基策略等高阶合成推理尚未被完全纳入
7.2 未来方向
团队公开的后续计划包括:
- • 解锁 Solv-3 能力:朝向实验可行路线的全闭环验证
- • 特定设计任务的后训练:针对特定靶点类别或化学系列的定向优化
- • 技术报告发布:即将发布更详尽的技术文档
八、意义与启示:一次药物研发范式的转变
TerraSynth 的最深层意义,不在于某一项技术指标的提升,而在于它重新定义了 AI 辅助药物设计的工作范式:
旧范式(顺序式):
AI 设计分子 → 合成可行性评估(事后、被动)→ 筛选 → 合成 → 测试
新范式(联合式):
AI 在合成约束的潜空间中联合优化分子与路线(实时、主动)→ 直接合成 → 测试
这一转变与计算机辅助设计(CAD)领域"可制造性设计(Design for Manufacturability, DFM)"的理念高度类似——设计与制造不再是顺序流程,而是在设计阶段就将制造约束内化为设计参数。
对于药物研发行业的从业者,TerraSynth 带来了以下实践启示:
- 1. 评估 AI 设计工具时,合成可行性是必选指标,而非可选项。单纯的分子生成质量(如 QED、SA score)已不足以评估工具的实用价值。
- 2. DMTA 循环的速度决定了竞争格局。2–4 倍的合成加速,意味着同等资源下可以探索更大的化学空间,发现更多有价值的苗头化合物。
- 3. 化学家的角色转变:从"判断哪些 AI 提案可合成"到"基于合成路线质量做优先排序",认知负担从否决式筛选转向优先级排序,效率将显著提升。
九、结语
TerraSynth 是当前 AI 药物发现领域少数几个在工业内部真实项目中得到系统性前瞻验证的方法之一。它的价值不只在于技术上,更在于提供了一套可落地的合成感知分子设计闭环,并以真实的 DMTA 加速数据证明了这一路线的工程可行性。
随着 Solv-3 能力的成熟与技术报告的发布,TerraSynth 所代表的"设计语言即合成语言"范式,有望成为下一代 AI 药物发现平台的标准配置。
📚 相关延伸阅读:
- • COATI 分子基础模型论文:JCIM, 2024
- • Syntax of Matter 框架:Morgunov et al., ChemRxiv 2026
- • PrexSyn:Luo & Coley, arXiv 2512.00384
- • AiZynthFinder:MolecularAI, GitHub
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号