过了治理闸门,别再按 token 单价选模型了

过了治理闸门,别再按 token 单价选模型了

用户10097875
发布于 2026-06-25 16:12:41
发布于 2026-06-25 16:12:41
点击上方 「模型之外的事」 蓝字,关注并星标。以后这类 AI 落地 / 模型治理 / 受监管行业选型 的长文,会第一时间出现在你的订阅里。
上一篇我说,受监管行业的 AI 选型,真正的闸门不在 benchmark 层,而在它前面的 governance 层——真实业务数据能不能离开境内受控环境,数据怎么留,厂商行为怎么变,政策风险会不会直接拿走你的可用性。
文章发出去,后台收到最多的一句追问是:
“道理我认。可过了治理闸门,具体怎么选?八家模型摆在面前,我总得有个挑法吧。”
很多人挑法很统一——打开一张 token 价目表,从最便宜或者分数最高的那一行开始往下看。
我的判断:在受监管行业,从价目表开始挑模型,这一步本身就错了。
不是价目表不重要。是 token 单价这个东西,会骗你三次。它骗你的方式,跟超市货架上的标价骗你一模一样——标的是“每克多少钱”,你吃的是“一顿饭多少钱”,中间隔着三层你没算进去的账。下面一层一层拆给你看。

token 单价骗你三次:标价 vs 落地价
一、第一次骗你:你按 token 付钱,客户按汉字办事
token 不是字。这是第一个被跳过的常识。
你给客户报价、做成本测算,脑子里想的是“一份业务材料大概几千字”;但模型计费,算的是 token。这两个单位之间的换算比,每家还不一样——而且境内境外差得很明显。
DeepSeek 官方文档写得很直白:一个中文字符大约 0.6 个 token。换句话说,1 个 token 大约装下 1.6 到 1.7 个汉字。Qwen、GLM、豆包这些国产模型,词表里中文占比高,量级大致相近——但各家官方没逐一给出换算口径,这点我只能说“接近”,不替它们打包票。
境外模型要分新旧看。以英文为中心的旧版 tokenizer(旧版 Claude、GPT-4o 这一代)切中文切得碎——第三方实测,同样内容中文比英文要多吃一成到六成的 token,商业新闻类文本最极端能到六成。但要公道说一句:新一代在收窄,Claude 从 4.7 起换了 tokenizer,中文劣势基本抹平。所以“境外中文更费 token”是个正在缩小、且因模型而异的现象,不是铁律。
把这件事翻译成钱:tokenizer 这层差异,顶多让境外模型的真实单价再贵一点;真正拉开差距的不是它,是单价本身的数量级差——这个留到第三层说。但有一点你现在就得记住:你按 token 付钱,客户按汉字办事,中间还隔着一个每家都不一样、还在变的换算比。
反常识一:别拿一张混着 token 标价的表直接横向比价——先把单位统一换成“每百万汉字”再比。光这一步,排名就可能变。
二、第二次骗你:价目表上一半的行,你根本不许选
假设你真把单位换算干净了,开始横向比价。第二次骗局来了——你比的那张表里,有一半的候选,对你的核心数据根本不可用。
这不是“贵一点”的问题,是“不在候选集里”的问题。
上一篇讲过数据边界,这里接着说,但口径得和上篇对齐——数据出境不等于法律上绝对禁止。国家网信办的规则里,安全评估、标准合同、个人信息保护认证,都是合规出境的路径。问题在于:对真实的金融交易、医疗记录、合同凭证、客户身份信息,这些境外模型没有境内合规节点、没有备案,走完那套出境评估的成本和周期,远高于“换个境内模型”。所以现实里的默认动作是——这类核心数据不进境外模型链路,除非你确实走完了评估、或做了脱敏。Claude、GPT、Gemini、Grok 在这一步默认被划到候选集之外:不是因为分数低,是因为它们解决的是另一个市场的问题。
划完之后,真正能进监管行业核心场景的,就剩下两类:
能私有化、数据不出域的:Qwen、DeepSeek、GLM——开源权重,可以部署在你自己的机房或金融云里,也有上国产算力(昇腾)的公开落地案例(注:多是研究 / 评测案例,生产环境的吞吐和精度得自己做 POC,别拿别人的 demo 当 SLA)。
闭源但在境内的:豆包 / 火山引擎这类,数据在境内,但你只能用它的云,不能搬回自己家。
这里还藏着一个最容易踩的坑,我必须单独点出来——
反常识二:同一个模型的“企业 API”和“消费级 App”,是两套完全不同的数据条款。 以 DeepSeek 为例,它的消费级隐私政策保留了用你的数据训练、改进模型的权利,也提供了关闭的 opt-out 选项(是否默认开启、App 与 API 条款是否一致,以官方最新条款为准——这正是消费级和企业级最容易出入的地方)。但方向是清楚的:企业接入必须走 API 或私有化、签数据处理协议;绝不能让员工拿着 C 端 App,去处理客户材料、医疗记录或交易凭证。 ChatGPT、Gemini 的个人版也一样——消费级和企业级是两套条款,不能混用,各自都得单独核。
所以第二次骗局的真相是:价目表是全集,你能用的是子集。先用合规这把筛子,把全集砍成子集,再谈价格才有意义。
三、第三次骗你:单价便宜,不等于落地便宜
到这一步,你手里只剩三五个合规候选了。现在能比价了吧?
还不能。因为 token 单价是“标价”,真正决定你掏多少钱的是“落地价”——而在监管行业,这两者差得离谱。
选私有化(Qwen / DeepSeek / GLM 自己部署):你的账单里根本没有 token 单价这一项。你付的是 GPU 卡 / 算力、运维、还有最容易被低估的那块——Eval 维护:谁来持续验证模型在你业务上的准确率没有漂移。
选境内公有云(豆包 / 火山,或 Qwen / DeepSeek 的公有云 API):你看得到 token 单价了,但要叠上数据合规改造的成本——脱敏、隔离、审计、日志留存。
这跟上一篇治理优先的思路一脉相承:AI 项目真正的成本在 harness 工程,不在模型本身。 token 单价在私有化场景里几乎是个零头,在公有云场景里也只是账单的一角。盯着单价砍价,是在为最小的那块成本斤斤计较,放着最大的那块不管。
补一句,这里也回收第一层留的尾:就算把汉字比、缓存价这些都算进去,境外旗舰和国产主力之间是几十倍的单价差(旗舰每百万 token 几美元,国产主力几块到十几块人民币)。tokenizer 那一成到六成的差异,在这种数量级面前,是小数点后的事。真正的成本杠杆从来是单价的量级和私有化的 TCO,不是 tokenizer。
四、正确的顺序:不是比价格,是过四道筛子
把上面三次骗局倒过来,选型的正确顺序就出来了。它不是一张价目表,是四道有先后的筛子——顺序错了,你会在错误的候选集上算错误的账。
顺序 | 这道筛子问什么 | 筛掉谁 |
|---|---|---|
筛一 · 合规 | 真实业务数据能不能离开境内受控环境? | 境外四家(Claude/GPT/Gemini/Grok),核心数据场景默认不入候选(走完出境评估 / 脱敏除外) |
筛二 · 形态 | 要不要私有化 / 数据不出域? | 卡在“境内但不可私有化”的(豆包仅境内云);境外则更早出局 |
筛三 · 落地价 | 按“每百万汉字”算落地价,不是按 token 标价 | 看着便宜、换算后贵的;以及私有化 TCO 撑不住的 |
筛四 · 能力 | 到这才轮到比分数、比 benchmark | 能力不达标的 |
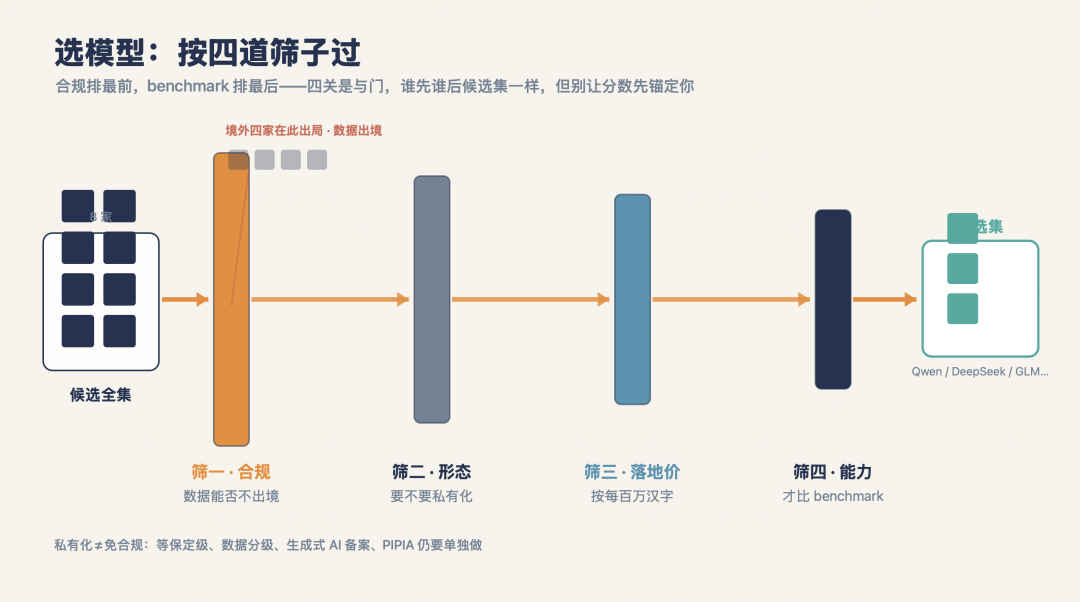
四道筛子:合规→形态→落地价→能力
两点要说清楚,免得这张表被误读。
一是,四道筛子是与门,不是排位赛——四关都得过,谁先谁后,最终候选集是一样的。我把 benchmark 放最后,说的是注意力顺序:别让分数先在你心里锚定预期。现实里很少有人真的“只看价目表”就拍板——招标流程里信创、等保本来就是硬条款。真正常见的失败不是“只看价”,是顺序错位:POC 先跑 benchmark、分数先把团队的预期钉死,合规和私有化被当成最后一关的“补丁”来打,结果选了半天的那个,临门一脚发现数据根本出不去。
二是,私有化不等于合规闭环。把数据关进自己机房,只解决了“数据不出域”这一个维度。等保定级、数据分类分级、生成式 AI 服务备案、个人信息保护影响评估(PIPIA),没有一个会因为你私有化了就自动消失。私有化是合规的必要条件,不是充分条件——这点我在下面每个行业里不再重复,但它一直在。
还有人会问:万一过了前三关,剩下的合规候选能力都不达标呢?那也不是回头放松合规,而是改流程——拿脱敏样本离线评测境外模型的能力当参照,或者等国产模型再迭代一版。合规这道闸门,不会因为能力不够就该松。
把顺序正过来,你会发现监管行业的候选集,比想象中干净得多。
五、落到垂直行业:图文密集场景,我建议这么选
这里不把某一个行业摊开讲。金融、医疗、保险科技、政务服务的问题高度同构:中文材料密集、图文混合、客户隐私重、审计要求强。这类场景套上面四道筛子,结论其实很明确。
这类垂直行业的 AI 落地,最大的量通常不在“写一段漂亮总结”,而在材料理解、字段抽取、图文核对、流程辅助:金融有开户、授信、交易凭证;医疗有病历、影像、检查报告;保险科技也有单据、照片、合同凭证。共同点不是行业名字,而是数据敏感、格式复杂、结果要能追责。
第一,大批量文档识别和字段抽取,走国产轻量档,私有化或境内 VPC 里跑。 这类活儿量大、单条便宜,国产轻量模型每百万汉字的落地成本极低。要诚实说一句:如果只比成本、不看合规,境外也有便宜档(比如 Gemini Flash),同档比下来差距没那么夸张。但只要材料里有客户身份、交易、健康或合同信息,境外模型在第一道筛子就默认出局——所以这里真正的对比,不是“国产便宜 vs 境外贵”,是“国产是你能选的档 vs 境外是你不能选的档”。成本结论,始终挂在合规筛子后面。
第二,图文混合理解这块,境内可私有化的多模态线有两条值得评:智谱 GLM 的视觉 + OCR 组合,和 Qwen-VL 系。 它们对受监管行业有一个共同优势——开源权重可私有化,客户照片、证件、合同、检查单、业务附件不出域;价格低,像 GLM-OCR 这种纯识别档,成本几乎可以忽略(注:智谱旗舰已迭代到 GLM-5 系,GLM-4.6V / OCR 是当前性价比够用的私有化档,不是说它最强)。但话说在前面:这两条线我帮你筛的是“合规 + 成本”这两关,能力名次得你自己拿脱敏样本去测——谁在你的表单版式、图片质量、术语体系上准,只有你的数据知道。
为什么不是境外视觉模型?不是它们能力不行——是这些图文材料里常常带着客户身份、交易细节、医疗信息或合同隐私,直传境外 API 这条路,在筛一就被堵死了。你可以拿脱敏样本离线评测 Gemini、Claude 的能力当参照,但生产链路里它们不在候选集。
第三,非核心、不碰客户隐私的环节——比如内部知识库问答、业务话术辅助、运营内容生成、公开资料整理——可以放宽,用豆包 / 火山这类境内云,多模态能力强、接入快。
把这类垂直行业收成一句话:敏感数据走国产私有化,图文混合理解在 GLM 视觉/OCR 与 Qwen-VL 两条线里按自己的数据评,非敏感环节再谈便利和能力。 顺序还是那四道筛子,只是落到了具体的活儿上。
医疗和银行,逻辑同构,只说结论:
医疗(病历、影像、PHI——最敏感):首选 Qwen / DeepSeek 私有化 + 国产算力,数据不出院内;非敏感科普、运营内容可用境内公有云。员工拿 C 端 App 处理患者数据,这条要明令禁止。
银行(监管最严,普遍要求境内私有化 + 等保三级):首选私有化 Qwen / DeepSeek / GLM,部署在行内或金融云;核心账户、交易数据,任何公有云直连都不建议,境外一律排除。
完整的八家价目表、汉字换算比、私有化矩阵、各家不训练 / ZDR / 数据留存的分级,我整理成了一份单独的评估表,数字太多就不堆在正文里了。这篇要你记住的不是数字,是顺序。
两个冷静的提醒
第一,政策条款会变,而且企业级和消费级是两回事。 这篇里所有“不训练 / 私有化 / 境内”的说法,都是某个时间点的口径。真要拍板,每一条都得回各家官方条款页再确认一遍,最好截图存档——尤其是企业 API 和消费级 App 的差异,这是最容易在合规审计里翻车的地方。
第二,价格在掉,但顺序不会变。 国产模型的 token 单价这两年一直在往下走,今天我引的某个数字,过几个月可能就旧了。但“先过合规、再砍候选、然后算落地价、最后比能力”这个顺序,不会因为谁降价就改变。别因为某家突然便宜,就把顺序倒过来。
今天就做的一件事
关掉这篇之前,只做一件事——
把你手上正在比的那张模型价目表盖住,先回答一个问题:我的业务数据,能不能离开境内受控环境?
如果答案是“不能”,那张价目表里至少一半的行,你现在就可以划掉。剩下的,才是你真正该认真比的候选。
选型从来不是从最便宜或最强的那一行开始的——是从这个你可能一直没正面回答的问题开始的。
关注「模型之外的事」
进入一个带你解读 AI 落地、模型治理与产业真实约束的频道。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号