深度解读Ring-lite:C3PO如何攻克强化学习不稳定性难题?

深度解读Ring-lite:C3PO如何攻克强化学习不稳定性难题?

唐国梁Tommy
发布于 2026-06-25 20:34:00
发布于 2026-06-25 20:34:00
让大语言模型(LLM)像人类一样思考,解决复杂的数学和编程问题,是AI领域的前沿目标。强化学习(RL)是实现这一目标的主流技术,但它有个致命弱点:训练过程极不稳定,尤其是在高效的混合专家(MoE)模型上,常常导致模型“学崩”。
现在,一篇名为《Ring-lite》的重磅论文,正面解决了这个难题。他们不仅提出了一种名为C3PO的稳定训练新算法,还基于此打造并开源了一个顶尖的推理模型 Ring-lite,并公开了所有技术细节。
今天,我们就来深入剖析这套开源“秘籍”,看看他们是如何做到的。
一、AI推理时代,我们面临的“成长的烦恼”
在AI领域,让模型具备强大的推理(Reasoning)能力,是通往通用人工智能(AGI)的必经之路。无论是解开奥数级别的数学题,还是在编程竞赛中拔得头筹,背后都依赖于模型严谨、多步的逻辑推理。
像OpenAI的O1系列和DeepSeek的R1模型,都展示了通过强化学习(RL)极大增强模型推理能力的巨大潜力。RL的逻辑很简单:模型做出推理(比如解题步骤),如果答案正确,就给予“奖励”;如果错误,就给予“惩罚”。通过不断试错和激励,模型会逐渐学会正确的思考方式。
然而,理想很丰满,现实很骨感。这个过程面临两大挑战:
1. 训练的不稳定性:RL训练过程极其敏感。想象一下,模型生成的解题步骤有长有短,这会导致每次训练的计算量和梯度(模型学习的方向和强度)剧烈波动。这种波动很容易让训练过程“脱轨”,导致模型性能突然断崖式下跌,也就是所谓的“奖励崩溃”(Reward Collapse)。
2. 混合专家(MoE)模型的挑战:MoE是一种非常高效的模型架构。它不像传统模型那样,每次计算都调动所有参数;而是像一个专家团队,每次只激活与任务最相关的少数“专家”来工作。这大大降低了计算成本。但这也带来了新的麻烦:在RL训练中,你不仅要管理整个模型的学习,还要协调内部各个专家的工作,这使得训练的稳定性问题雪上加霜。
这篇论文的价值正在于此:它直面了“MoE + RL” 这块硬骨头,不仅提出了一套行之有效的解决方案,还慷慨地将所有成果开源,为整个AI社区铺平了道路。
二、核心贡献:不仅仅是一个模型,更是一套完整的“秘籍”
Ring-lite团队的贡献是全方位的,可以概括为四大亮点:
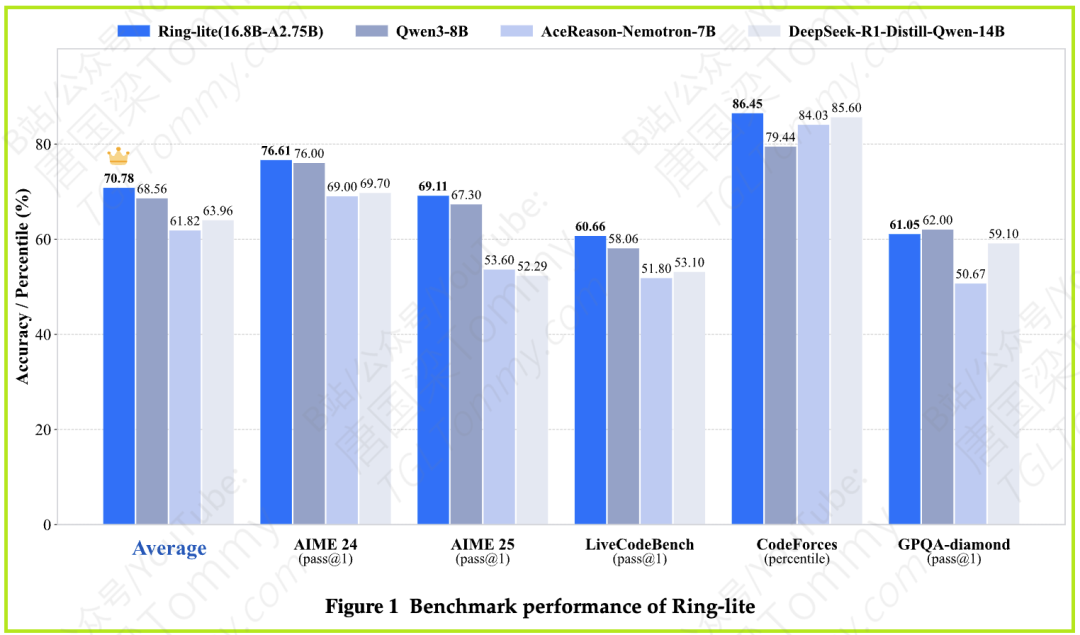
1. 顶尖的开源推理模型(Ring-lite):他们推出了Ring-lite,一个拥有168亿总参数,但每次推理仅激活27.5亿参数的MoE模型。它在数学、编程和科学等多个高难度推理基准上,性能媲美甚至超越了许多参数量接近100亿的密集模型。简单来说,就是用更少的计算资源,办了更漂亮的事。
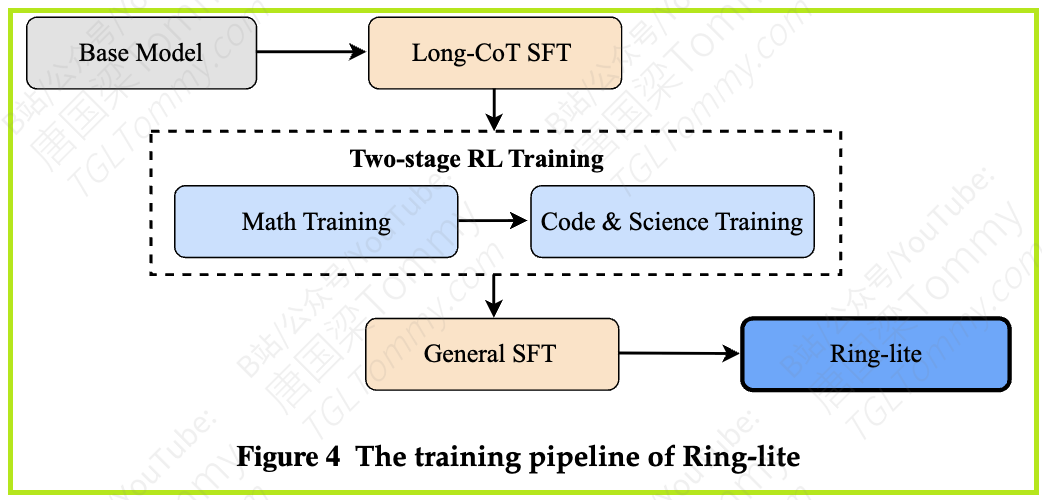
2. 创新的稳定训练算法(C3PO):这是本次研究的“王牌”。他们提出了一种名为C3PO(Constrained Contextual Computation Policy Optimization)的新型RL优化框架。它的核心思想是固定每次训练的“计算量”,从根本上解决了因响应长度变化导致的训练不稳定性问题。
3. 解决领域冲突的训练策略(两阶段训练法):当你想让一个模型同时擅长数学和编程时,简单地把两种数据混在一起训练,结果往往是“样样通,样样松”。Ring-lite团队发现了一种更优的“课程表”式训练法:先专心学好数学,打下逻辑基础,然后再去学编程和科学,效果拔群。
4. 一个反直觉的训练洞察(熵检查点选择):在选择哪个版本的预训练模型进行RL强化时,我们的直觉是选在测试集上表现最好的那个。但研究发现,恰恰相反!选择一个“不太确定”、保留了更多可能性的模型(即熵更高),作为RL训练的起点,反而能取得更好的最终效果。
下面,我们就来逐一拆解这些技术细节,看看他们到底是怎么做到的。
三、方法解析:C3PO如何“稳定输出”?
要理解C3PO的巧妙之处,我们得先看看老方法GRPO(Group Relative Policy Optimization)有什么问题。
老方法GRPO的“先天缺陷”
GRPO是目前LLM强化学习中广泛使用的一种算法。它的工作流程大致是:对于一批问题,让模型生成多个答案,然后根据答案的好坏(奖励)来调整模型。但它有两个主要问题:
1. 步内长度偏差(Within-step length bias):模型生成的答案有长有短。GRPO在计算梯度时,为了公平,会将每个答案的总奖励除以其长度,得到一个“平均每字符奖励”。这看似公平,却导致了一个意想不到的后果:它系统性地放大了短答案的梯度,同时削弱了长答案的梯度。一个虽然步骤详尽但答案很长的正确解法,其学习信号可能反而不如一个步骤简略的短答案。
2. 跨步梯度方差(Across-step gradient variance):更致命的是,每一批次(step)训练中,所有答案的总token数是剧烈变化的。这一批可能是50万token,下一批可能就变成了80万token。这对于优化器(比如AdamW)来说,就像开车时油门忽大忽小,车子必然会前后摇晃,难以平稳前进。反映在训练中,就是梯度范数剧烈波动,最终导致训练崩溃。
C3PO的“定海神针”:固定Token预算
C3PO的设计思想极其简洁,直击要害:既然问题出在每次训练的token总量不稳定,那我就把它固定下来。
类比一下:假设一位老师批改作业。
- GRPO的方式是:每小时固定批改30名学生的作业。但有的学生写了500字,有的写了1500字。结果老师这小时工作量巨大,下一个小时又很清闲,状态很不稳定。
- C3PO的方式是:每小时固定批改10000字的内容。不管这10000字来自多少名学生,老师每小时的工作量都是恒定的。
C3PO的实现正是如此。在每个训练步骤中,它不再处理固定数量的样本,而是设定一个固定的token预算 Φ(比如论文中的409600个token)。然后,它会从模型生成的大量候选答案中,像“自助餐”一样,不断挑选答案,直到装满这个 Φ 的“盘子”。
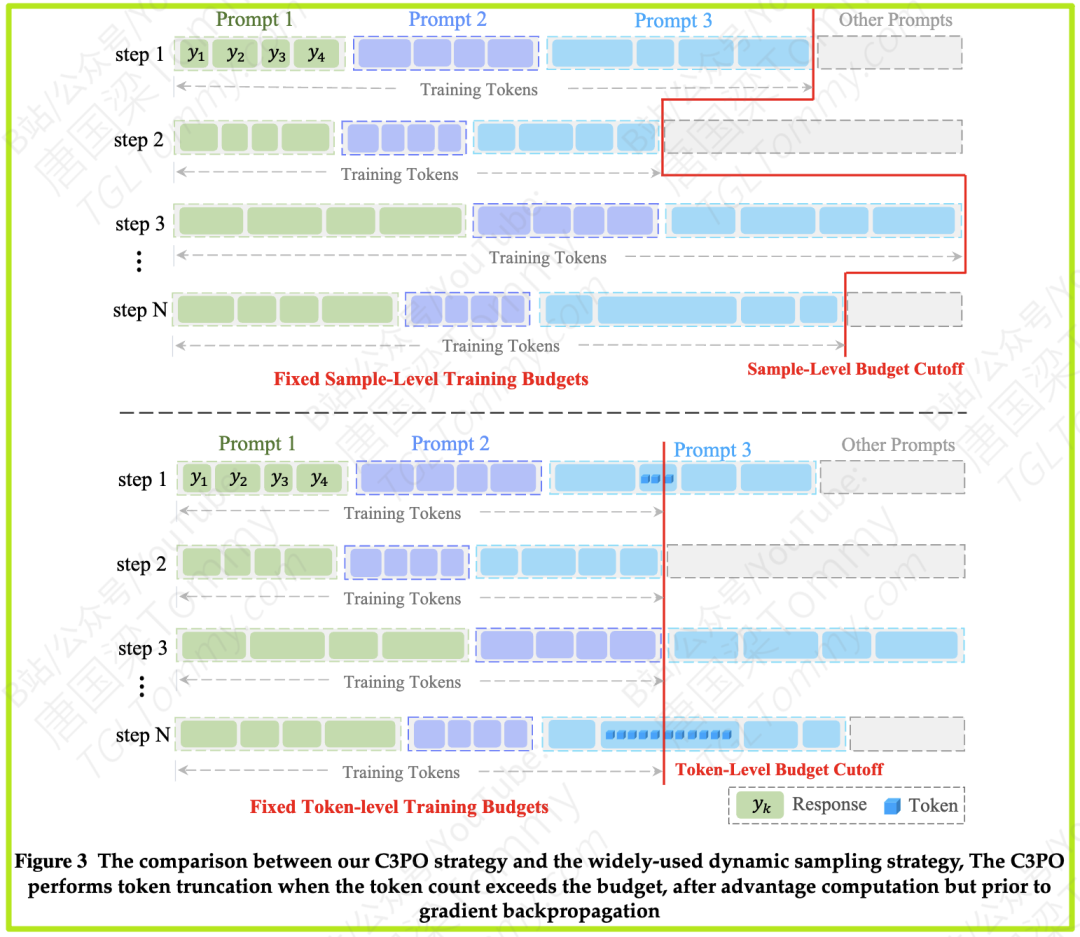
这个小小的改动,带来了两大好处:
1. 同质化的梯度缩放(Homogeneous Gradient Scaling):由于总token数 Φ 是一个常数,损失函数中的归一化因子也变成了常数。这意味着每个token对模型更新的贡献变得更加公平,消除了长度歧视。
2. 确定性的训练动态(Deterministic Training Dynamics):每个训练步骤的计算负载变得完全可预测。这对于需要协同工作的大规模分布式训练系统来说是个巨大的福音,可以有效避免资源浪费和计算瓶颈,提升整体训练效率。
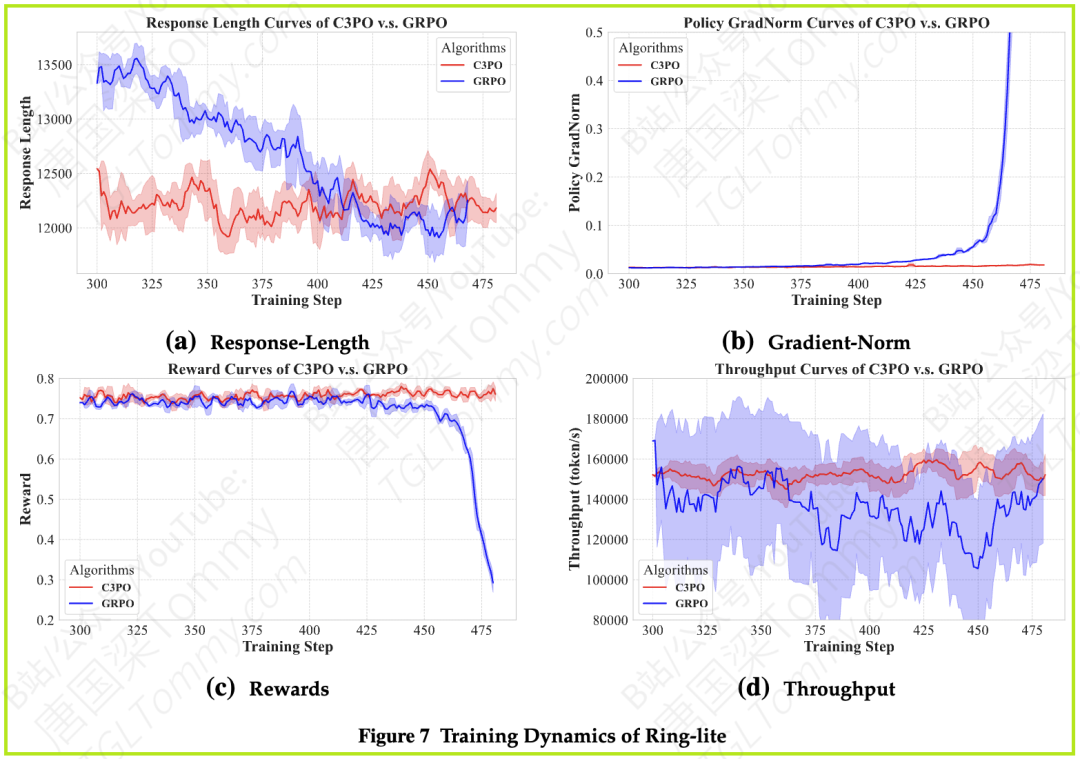
论文中的图7 清晰地展示了C3PO的威力。无论是MoE模型还是密集模型,C3PO的训练曲线(蓝色)在响应长度、梯度范数、奖励和吞吐量四个方面,都如一条平稳的直线,而GRPO(红色)则像过山车一样颠簸,最终“翻车”。
两阶段训练法:如何让模型“德智体美劳”全面发展?
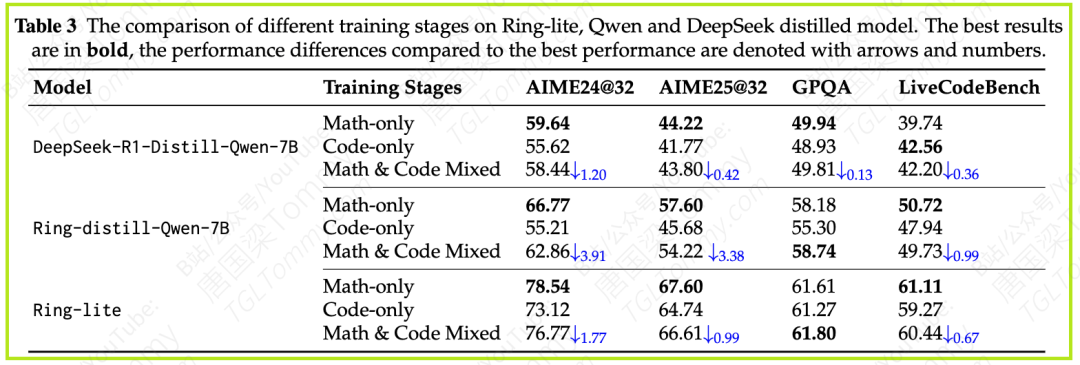
当你试图让一个模型同时学习数学和编程时,会发生什么?论文的表3给出了答案:领域冲突。混合训练的结果是,模型在数学上的表现不如只学数学的模型,在编程上的表现也不如只学编程的模型。
这背后的原因可能是,数学推理和代码生成虽然都依赖逻辑,但它们的“思维模式”和“表达范式”有很大差异。同时学习会让模型“精神分裂”。
Ring-lite的解决方案是设计一个科学的“课程表”,即两阶段RL训练:
第一阶段:专攻数学。先让模型通过RL训练,深入学习数学的抽象逻辑和严谨推理。这是打下“理科思维”的基础。
第二阶段:拓展到代码和科学。在模型具备了强大的数学能力后,再引入代码和科学数据进行RL训练。此时,模型可以将在数学中学到的逻辑推理能力“迁移”过来,事半功倍。
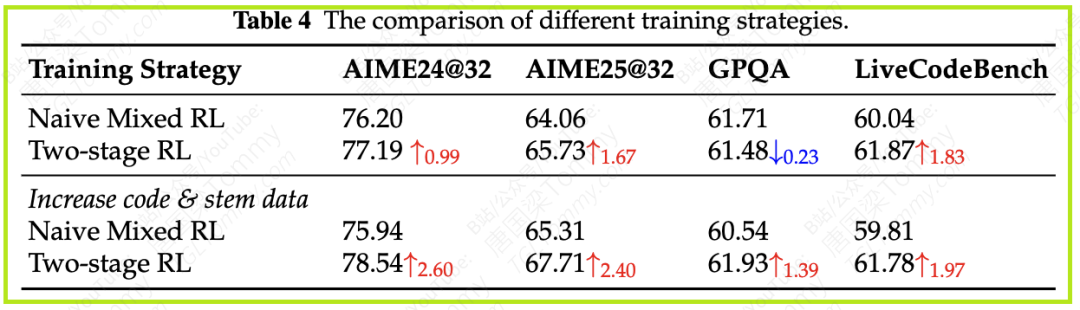
表4的数据证实了这种方法的有效性。与简单的混合训练相比,两阶段训练法在AIME25(数学)和LiveCodeBench(编程)等基准上都取得了显著的性能提升。
反直觉的智慧:为何“不完美”的起点更好?
在进行RL训练前,通常会先对模型进行监督微调(SFT),让它对任务有个初步的了解。SFT会训练很多轮(epoch),每一轮都会保存一个模型检查点。我们应该用哪一轮的模型来开始RL呢?
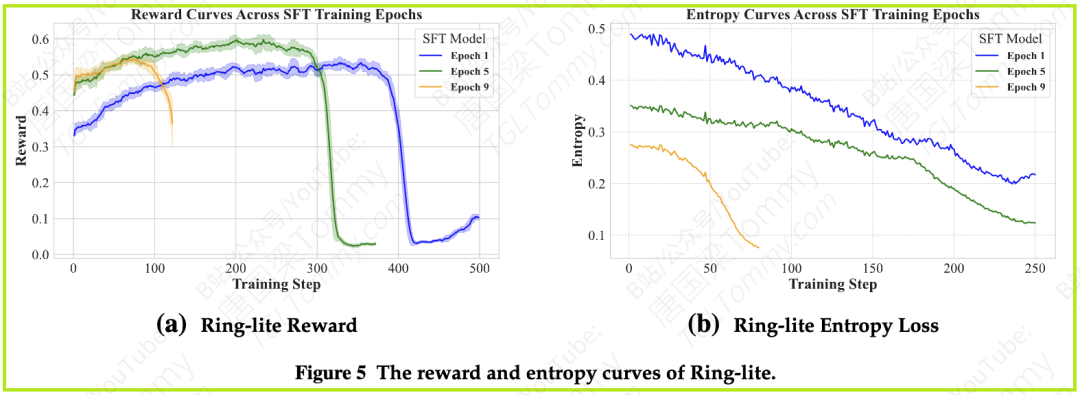
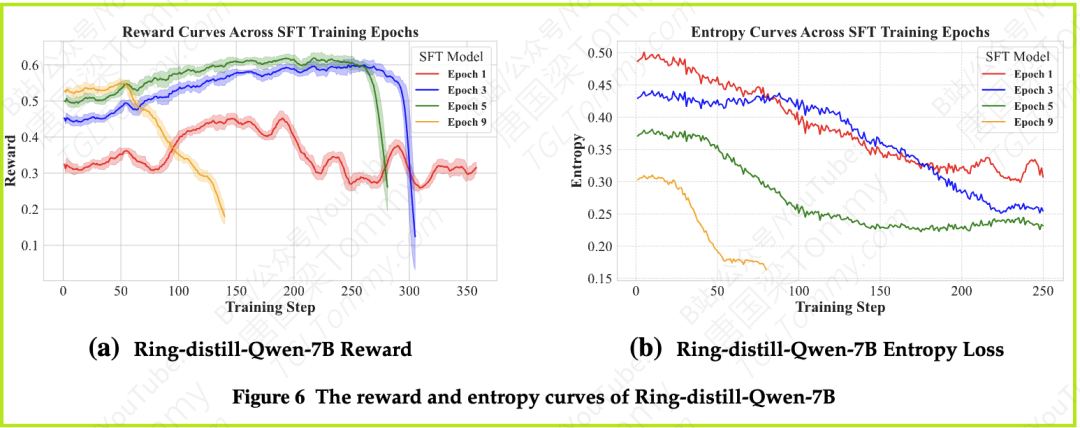
直觉告诉我们,应该选在验证集上得分最高的那个。但论文的图5和图6揭示了一个惊人的事实:SFT训练轮次越多的模型,其熵(entropy)越低。熵可以理解为模型对自身输出的“不确定性”。熵越低,代表模型越“自信”,认准了一条路走到黑。
RL训练需要模型进行广泛的探索(Exploration)。一个过于自信(低熵)的模型,就像一个只会背标准答案的“好学生”,思维僵化,不愿意尝试新的解法,因此在RL中很快就会碰壁,导致奖励崩溃。
相反,一个来自较早SFT轮次的、熵较高的模型,虽然在测试集上分数没那么高,但它保留了更多的“可能性”和“灵活性”,更像一个充满好奇心、愿意探索各种解法的学生。这样的模型在RL训练中反而能走得更远,取得更好的最终成就。
四、实验结果:用数据说话,Ring-lite有多强?
口说无凭,我们来看看Ring-lite的“成绩单”。
实验设置
- 选手:Ring-lite (16.8B MoE, 2.75B激活)
- 对手:包括Qwen3-8B、AceReason-Nemotron-7B等当前顶尖的开源模型。
- 考场:AIME(美国数学邀请赛)、LiveCodeBench(实时编程竞赛)、GPQA-diamond(研究生水平科学问答)、Codeforces(编程竞赛平台)等一系列高难度推理基准。
最终成绩(表1)
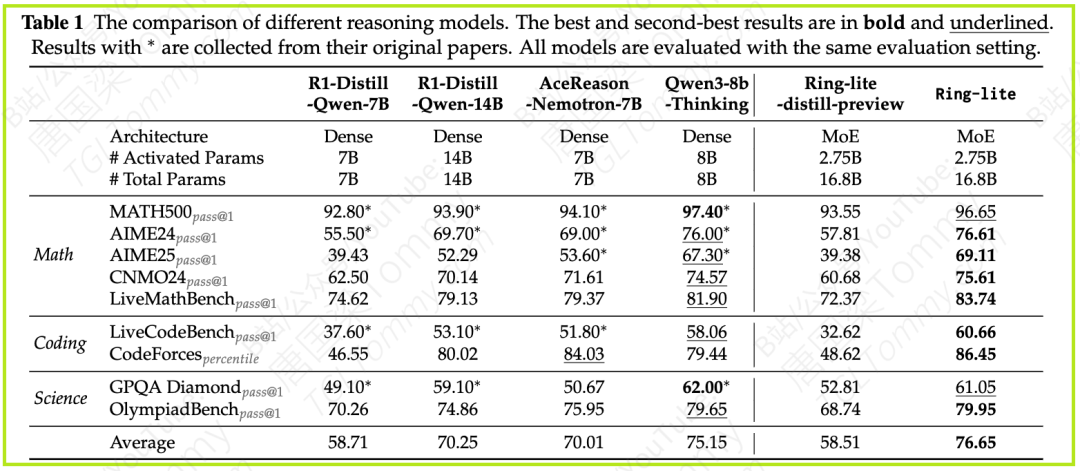
Ring-lite的表现堪称惊艳:
- 在平均分上,Ring-lite(76.65)超越了所有参数量在10B以下的密集模型,包括强大的Qwen3-8B-Thinking(75.15)。
- 在具体的“科目”上:
- AIME24 (pass@1): 76.61%
- LiveCodeBench (pass@1): 60.66%
- Codeforces (percentile): 86.45%
这些数据雄辩地证明:通过C3PO和精巧的训练策略,MoE模型不仅可以被稳定地训练,还能在推理任务上达到业界顶尖水平,同时保持着极高的计算效率。
五、启示与未来:通往更强推理的下一步
Ring-lite的工作无疑是AI推理领域的一个里程碑,但探索永无止境。基于这篇论文,我们可以看到几个清晰的未来方向:
- 通用奖励模型的探索:目前,奖励依赖于有明确答案的验证器(如代码沙箱)。未来的研究需要开发能够像人类一样,评估开放性、创造性推理过程质量的通用奖励模型,这将是模型能力从“解题”走向“思想”的关键。
- 系统化的数据合成:高质量的推理数据是稀缺资源。如何利用现有模型自动、高效地生成海量、多样化且高质量的训练数据,是推动该领域继续发展的核心瓶颈之一。
- 深入理解MoE的内在机制:Ring-lite证明了MoE的有效性,但其内部的2.75B激活参数是如何分工协作的?是否存在“数学专家”、“几何专家”、“算法专家”?深入分析MoE的专家激活模式,可能会带来更精细、更高效的模型设计思路。
总而言之,Ring-lite及其背后的C3PO算法,不仅为我们带来了一个强大的开源推理工具,更重要的是,它提供了一套完整、透明且可复现的科学方法论。它告诉我们,即使是驯服AI中最狂野的“巨兽”,只要有正确的工具和策略,我们也能让它稳定地为我们服务,并推动人工智能的边界不断向前延伸。
参考文献
论文名称: Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
第一作者: Ling Team, Inclusion AI
论文链接: https://arxiv.org/abs/2506.14731
发表日期: 2025年6月17日
GitHub:https://github.com/inclusionAI/Ring.git
你好,我是唐国梁Tommy,专注于分享AI前沿技术。
#强化学习 #LLM #大模型推理 #Reasoning #MoE #唐国梁Tommy #大模型训练 #AI技术 #AI前沿论文解读 #AI大模型
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号