“通才”的胜利:为何混合训练(数学+代码+谜题)才是打造最强大模型的关键?

“通才”的胜利:为何混合训练(数学+代码+谜题)才是打造最强大模型的关键?

唐国梁Tommy
发布于 2026-06-25 20:54:32
发布于 2026-06-25 20:54:32
今天,我们要深入探讨一个在AI领域越来越重要的话题:大语言模型(LLM)的多领域推理能力。如今的LLM在单一任务上,如数学解题或代码生成,已经表现得相当出色。但这和人类智慧的真正形态——能够自如地融合多种认知技能来应对复杂现实世界——还有一定距离。
一个核心问题随之而来:我们能否通过在一个领域训练模型,来提升它在另一个完全不同领域的能力? 比如,让一个精通数学的模型,同时成为逻辑推理高手?或者,学习编程会不会反而限制了模型的其他能力?
最近,一篇来自上海人工智能实验室的论文《Can One Domain Help Others? A Data-Centric Study on Multi-Domain Reasoning via Reinforcement Learning》对这一问题进行了系统性的探索。它不像以往的研究只关注单一领域的“极限冲分”,而是首次以一种“数据为中心”的视角,细致剖析了在强化学习(RL)框架下,不同推理领域之间错综复杂的“相生相克”关系。

一、 从“专才”到“通才”的鸿沟
近年来,一种被称为“基于可验证奖励的强化学习”(RLVR) 的技术范式异军突起。简单来说,它的核心思想是:让模型生成一个解题步骤(如数学推理或代码实现),然后通过一个外部验证器(如单元测试或答案对比)来判断对错,并给予奖励或惩罚。模型则在一次次的“尝试-验证-反馈” 循环中,通过强化学习不断优化自己的推理能力。
然而,这些研究大多是单点突破,它们将模型训练成了某个特定领域的专才。但现实世界的问题往往是综合性的,例如,解决一个复杂的物理问题可能同时需要数学知识、逻辑分析和编程模拟。因此,理解不同推理技能在强化学习过程中如何相互影响,就变得至关重要。
这篇论文正是为了填补这一空白。研究者们明确地将研究范围聚焦于三个关键且互有区别的推理领域:
1️⃣数学(Math):涉及代数、几何等问题的求解。
2️⃣代码(Code):涉及根据自然语言描述生成可执行代码。
3️⃣谜题(Puzzle):涉及逻辑推理,如经典的“骑士与无赖”问题。
他们的核心目标,就是系统性地回答以下几个问题:
- 单一领域训练的影响:只用数学数据训练模型,它在编程和逻辑能力上是变强了还是变弱了?
- 多领域混合训练的互动:将数学和编程数据混合在一起训练,是会产生“1+1>2”的协同效应,还是会互相干扰?
- 基础模型与指令微调模型:在进行强化学习之前,经过指令微调(SFT)的预先调教,对最终的推理能力有多大影响?
- 训练细节的关键作用:课程学习的顺序、奖励函数的设计、甚至是训练数据的语言(中文 vs 英文),会如何改变最终结果?
通过对这些问题的深入探究,这篇论文为我们优化LLM的训练策略、培养更全面的多领域推理能力提供了宝贵的实践指南。
二、 核心方法:一场精心设计的控制变量实验
为了确保研究的严谨性,作者设计了一套周密的实验框架。
2.1 模型与算法
实验选用 Qwen2.5-7B 模型作为基础,并同时使用了它的两个版本:Base(基础版)和 Instruct(指令微调版)。这使得研究者可以清晰地对比SFT阶段对后续RL训练的影响。
在强化学习算法上,他们采用了群体相对策略优化(GRPO)。GRPO是PPO算法的一个变种,它巧妙地绕过了传统PPO中需要训练一个独立价值模型的步骤。取而代之的是,它在每次迭代时,让模型针对同一个问题生成多个不同的答案(一个rollout group),然后直接在这个答案群体内部进行比较,计算出每个答案的优势(Advantage)。
GRPO的优化目标可以形式化地表示为:

2.2 数据集与评估
研究者为三个领域分别精心挑选了训练数据集,并确保数据规模大致相当,以进行公平的比较(详见论文Table 1)。
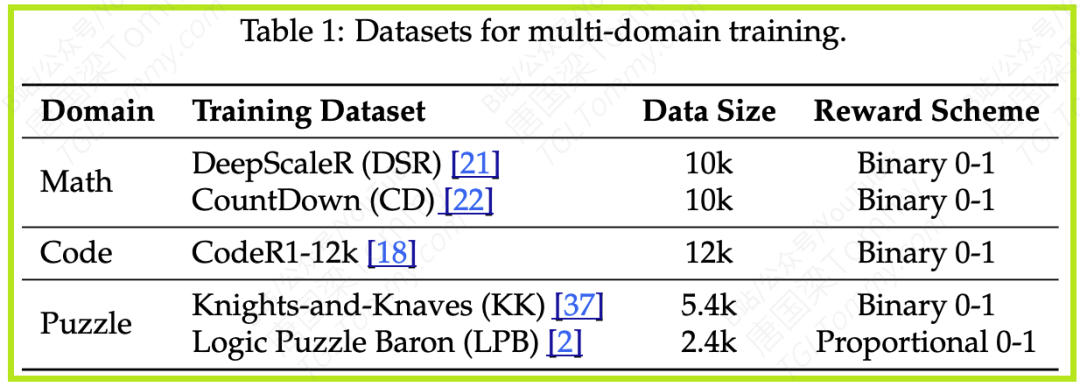
- 数学领域:使用了DeepScaleR和CountDown等数据集。
- 代码领域:使用了CodeR1-12k数据集。
- 谜题领域:使用了Knights-and-Knaves (KK) 和 Logic Puzzle Baron (LPB) 数据集。
在评估方面,他们同样采用了各个领域的权威基准测试集,如MATH500和AIME24用于评估数学,HumanEval和MBPP用于评估代码,ZebraLogicBench用于评估谜题。
三、 实验结果与深度分析
这部分是论文的精华所在。研究者通过大量的实验,为我们揭示了不同推理领域之间复杂而有趣的相互作用。
3.1 单一领域训练:有得必有失
首先,让我们看看只用一个领域的数据进行训练会发生什么(详见论文Table 4, 6, 8)。
(1)数学训练 → 强化逻辑,削弱编码
- 结果:当模型只在数学数据集上训练后,其数学能力和谜题解决能力都得到了显著提升。例如,Base模型在数学上的平均分从22.48%提升至47.48%,在谜题上的平均分也从9.07%跃升至22.42%。然而,它的代码能力却出现了退化(从67.46%下降到64.23%)。
- 分析:这揭示了一个深刻的联系:数学和逻辑谜题共享了底层的逻辑推理能力。强化其中一个,另一个也会受益。但这种抽象的、符号化的逻辑推理,似乎与代码生成所需的更结构化、更严谨的语法规则存在一定的冲突。
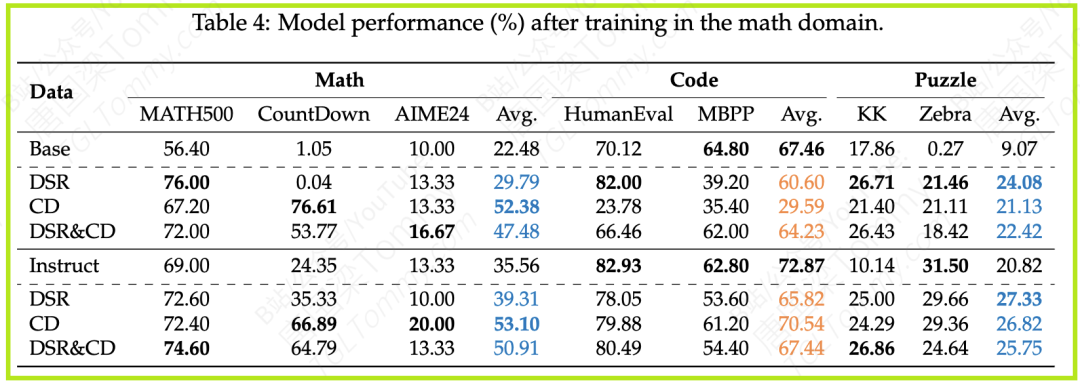
(2)代码训练 → 编码能力飙升,但泛化依赖SFT
- 结果:用代码数据训练后,模型的编码能力大幅提升。有趣的是,Instruct模型在其他领域(数学、谜题)上的泛化表现远好于Base模型。Base模型在接受代码训练后,在其他任务上甚至出现了性能下降。
- 分析:这说明,代码训练形成的思维定式(如严格遵循代码格式)可能会限制模型在其他非结构化任务上的灵活性。而SFT阶段的训练,似乎赋予了模型更强的泛化和适应能力,使其能够更好地将从编码中学到的结构化思维迁移到其他领域。

(3)谜题训练 → 极大地促进数学能力
- 结果:谜题训练同样展现了强大的跨领域迁移效果,尤其是在数学上。Base模型在谜题数据上训练后,其MATH500分数甚至接近了未经RL训练的Instruct模型,显示出极强的跨域泛化能力。然而,它对编码能力的影响同样是不稳定的,通常是负面的。
- 分析:这再次印证了逻辑推理是数学能力的核心基石之一。通过解决逻辑谜题,模型学会了演绎、归纳和多步推理,这些技能可以直接迁移到数学问题的解决中。
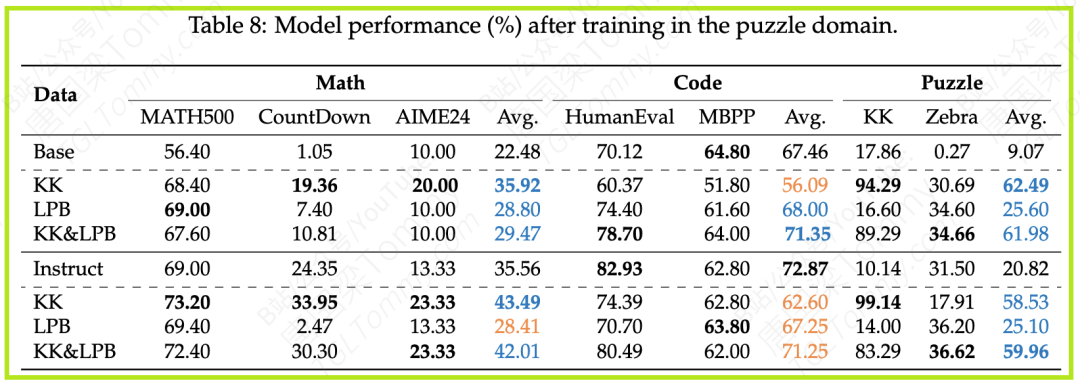
3.2 组合领域训练:协同与制衡的艺术
单一领域的训练揭示了跨界的利弊,那么将不同领域的数据混合起来训练,又会产生怎样的化学反应呢?(详见论文Table 9)
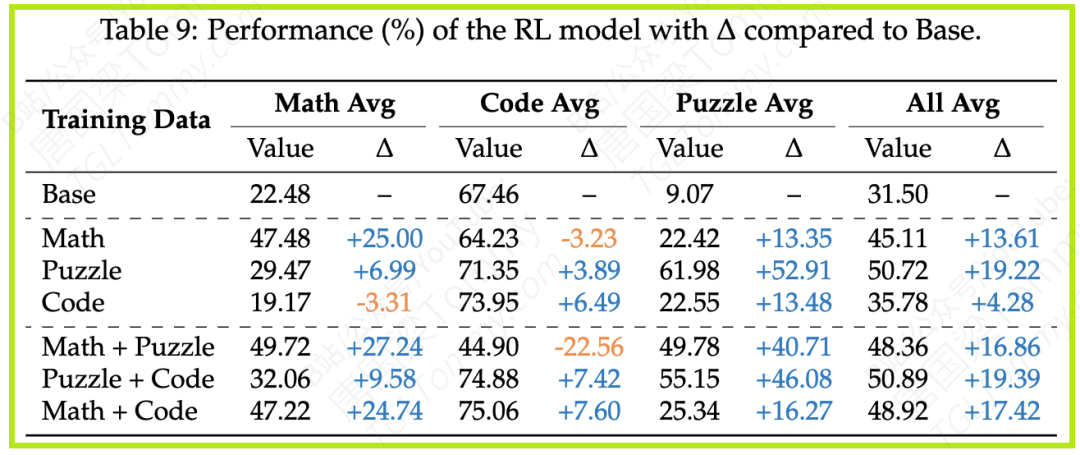
(1)双领域组合:强强联合也可能内耗
结果:
- 数学 + 谜题:这个组合在数学任务上取得了比单领域训练更好的成绩。但代价是,代码能力出现了“灾难性遗忘”,性能下降了超过22%。
- 谜题 + 代码:这是一个令人惊喜的“黄金组合”。它不仅在各自领域表现出色,而且整体平均性能(50.89%)在所有双领域组合中最高。
- 数学 + 代码:这个组合同样提升了代码性能,但对谜题能力的助益有限。
分析:这表明,并非所有领域的组合都能带来正面效果。数据组合的设计需要非常小心,以平衡协同作用和负面迁移。谜题+代码组合的成功,可能在于它们分别强化了模型的逻辑推理和结构化思维,形成了一种互补,而数学+谜题的组合则过度强化了抽象逻辑,牺牲了对代码这种形式化语言的适应性。
(2)三领域组合:通才的胜利
结果:当把数学、代码、谜题三个领域的数据全部混合进行训练时,模型的整体平均性能达到了最高的56.57%(详见论文Figure 3 & 4)。虽然它在某些单项上(如谜题)并非最强,但它在所有任务上都保持了非常稳健和均衡的表现,没有出现严重的短板。
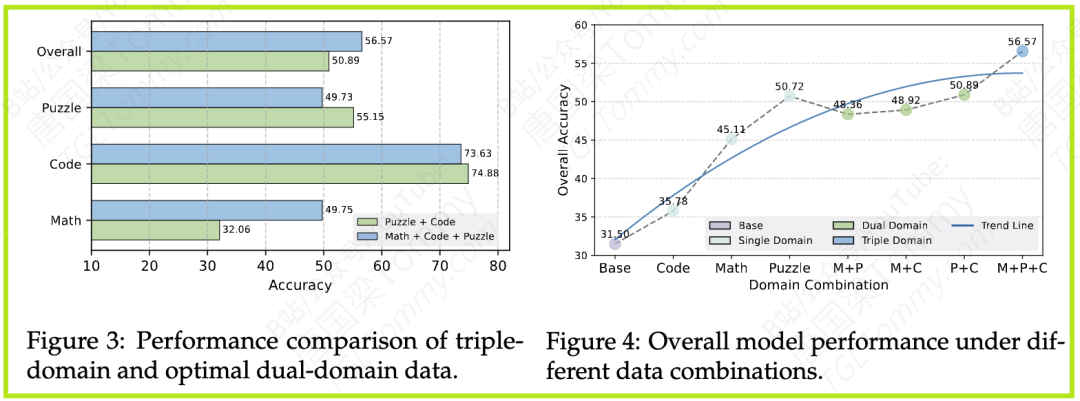
分析:这是本次研究最重要的发现之一。通过引入更多样化的数据,可以有效提升模型的整体鲁棒性和泛化能力,防止在特定任务上出现性能崩溃。这就像一个学生,如果只学文科,理科成绩可能会很差;但如果文理兼修,即使单科不是状元,综合实力也会更强。
3.3 训练细节中的魔鬼:模板、课程、奖励与语言
除了领域组合,论文还深入探讨了几个常被忽视但至关重要的训练细节。
(1)模板一致性是生命线
- 发现:在训练和测试时使用不匹配的指令模板,会导致模型性能急剧下降(详见论文Table 11)。例如,使用R1模板训练的模型,在测试时如果换成Qwen模板或无模板,性能会一落千丈。
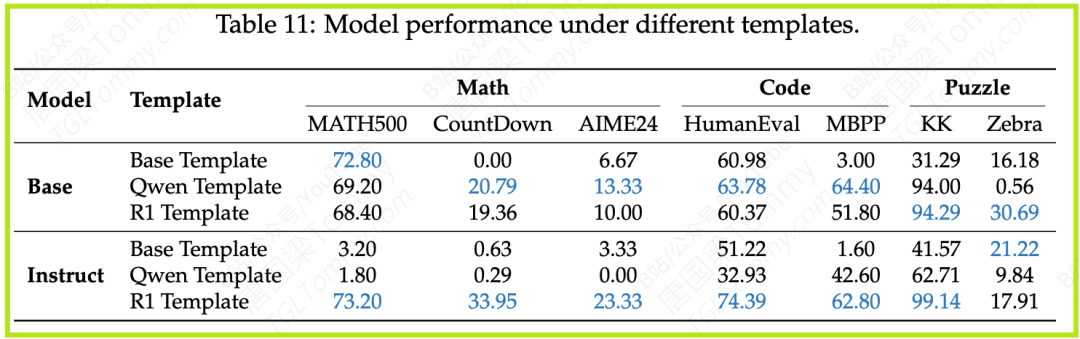
- 启示:这提醒我们,RLVR模型的性能在很大程度上是“脆弱”的,它高度依赖于固定的交互格式。在实际应用中,必须确保推理时使用的模板与训练时完全一致,否则模型的表现将无法保证。
(2)课程学习与策略刷新
- 发现:通过设计一个从易到难的“课程”(例如,在KK谜题中,从3个子问题的任务开始,逐步增加到8个子问题),可以显著提升模型的最终性能上限。在此基础上,研究者提出了一种“策略刷新”策略:每完成一个难度等级的训练,就用当前最优的模型作为下一阶段的“参考模型”,并重置优化器状态。这种方法能有效加速收敛,并取得了近乎完美的准确率(详见论文Figure 6)。
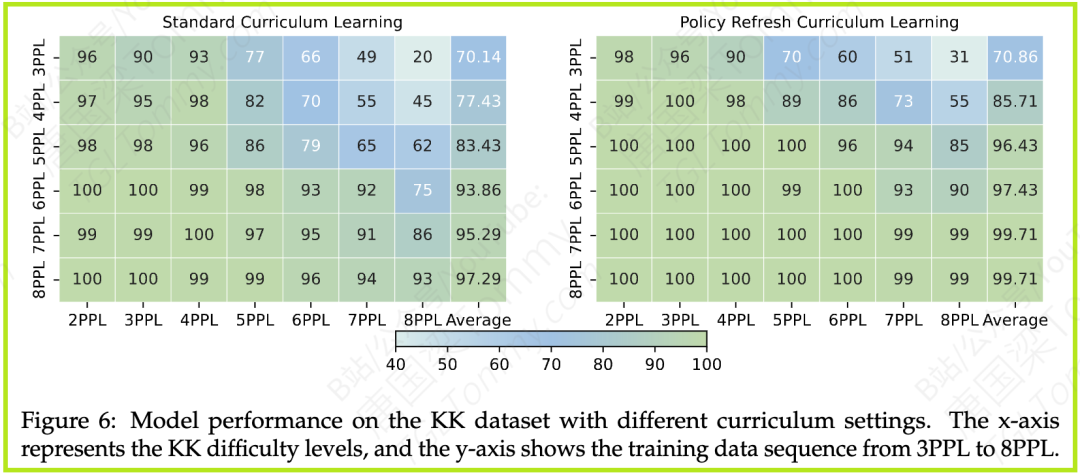
- 启示:这说明,让模型“循序渐进”地学习,比“一口吃个胖子”效果更好。定期的“清零重启”可以帮助模型摆脱局部最优,更好地适应更复杂的任务。
(3)奖励设计的权衡
- 发现:奖励函数的设计需要与任务难度相匹配。对于像KK这样相对简单的任务,直接的二元奖励(完全正确得1分,否则0分)效果最好。而对于LPB这样更复杂的任务,二元奖励会导致模型因几乎拿不到奖励而“摆烂”(训练崩溃)。此时,部分奖励(根据答对的比例给分)成为一种更有效的替代方案(详见论文Figures 7 & 8)。
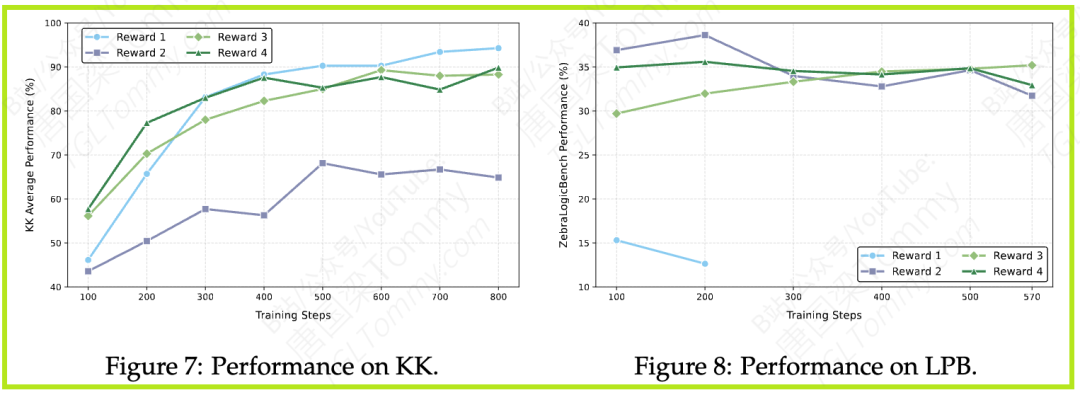
- 启示:没有一通百用的奖励机制。设计奖励时必须考虑“奖励稀疏性”问题。在困难任务中,提供更密集的、细粒度的奖励信号,对于引导模型学习至关重要。
(4)语言的敏感性
- 发现:在完全相同的设置下,使用中文数据训练的模型,在推理能力上的表现持续地、显著地低于使用英文数据的模型(详见论文Figure 11)。
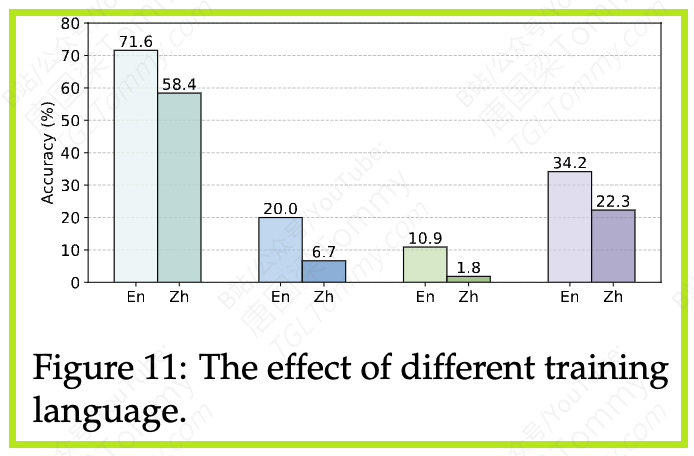
- 启示:这揭示了当前LLM在处理不同语言时可能存在的内在偏见或能力差异。即便是在进行下游的RL训练,模型底层的语言表征能力依然是性能的基石。对于非英语的推理任务,可能需要更先进的跨语言泛化算法。
四、 总结与启示
这篇论文通过一场大规模、系统化的实验,为我们描绘了一幅大模型多领域推理能力的全景图。它带来的启示是深刻而实用的:
1. 走向“通才”是必由之路:单一领域的极限优化虽然重要,但构建能够应对真实世界复杂性的AI,必须拥抱多领域、多样化的数据训练。三领域混合训练的成功,证明了模型的通用推理能力受益于更广泛的知识和技能覆盖。
2. 协同与制衡是关键:领域间的相互作用是复杂的。数学与逻辑可以相互促进,但它们可能与代码能力相冲突。在设计训练策略时,我们需要像配制药方一样,仔细权衡不同“成分”(数据领域)的比例,以达到最佳的整体效果。
3. SFT是RL成功的基石:指令微调(SFT)不仅仅是让模型学会“听话”,它更深远地影响了模型在后续强化学习中的泛化和迁移能力。一个经过良好SFT的“三好学生”,在学习新知识时,显然比一个“野路子”的基础模型更具潜力。
4. 细节决定成败:这篇研究有力地证明,模板、课程、奖励、语言这些看似微小的细节,都可能对最终结果产生决定性的影响。这提醒所有AI从业者,在追求模型和算法创新的同时,绝不能忽视这些基础而关键的工程实践。
总而言之,这篇论文不仅为我们揭示了LLM推理能力背后的诸多秘密,更为我们未来如何构建更强大、更通用的AI系统,指明了一条清晰且数据驱动的道路。从“专才”到“通才”,这或许正是下一代AI进化的方向。
参考文献
论文名称: Can One Domain Help Others? A Data-Centric Study on Multi-Domain Reasoning via Reinforcement Learning
第一作者: 上海 AI Lab
论文链接: https://arxiv.org/pdf/2507.17512
发表日期: 2025年7月23日
GitHub:https://github.com/Leey21/A-Data-Centric-Study.git
你好,我是唐国梁Tommy,专注于分享AI前沿技术。
#大模型推理 #AI大模型 #强化学习 #AI技术 #人工智能 #唐国梁Tommy #大模型算法原理 #多模态大模型
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号