OpenSearch-VL:一份能跑起来的多模态搜索 Agent 配方

OpenSearch-VL:一份能跑起来的多模态搜索 Agent 配方

唐国梁Tommy
发布于 2026-06-25 21:43:12
发布于 2026-06-25 21:43:12
当所有顶级多模态搜索 Agent 都被锁在闭源系统背后时,腾讯混元联合三所高校把数据、工具、训练算法整套配方端上了桌。
一张图看不到全貌的搜索
打开手机随手拍下一栋建筑,问"它叫什么名字、是谁建的、为什么这么造"——这种问题对人来说稀松平常,对模型却是一道综合题。
它需要 Agent 看清画面、决定先搜什么、读懂网页、再回过头追问下一步。中间任何一步出错,整条链路就断了。
这就是多模态深度搜索(Multimodal Deep Search)正在尝试解决的问题:让模型不再被动看图说话,而是像研究员那样主动去查、去验证、去推理。

听起来简单,做起来工程量极大。过去一年里,GPT-4o、Gemini、Claude 等闭源模型在这件事上断崖式领先,但训练数据、工具栈、轨迹合成流水线全都不公开,社区一直缺一份完整、可复现的开源配方。
2026 年 5 月,腾讯混元联合 UCLA、港中文、港大放出了 OpenSearch-VL,把这件事彻底端上桌:数据、工具环境、训练算法、模型权重全部开源。

它到底解决了什么问题
要训出一个能稳定跑多轮工具调用的多模态 Agent,社区面前横着三道墙。
第一堵墙是数据。头部商业系统的训练数据都是私有的,包含哪些来源、过了什么筛选、专家轨迹长什么样,外界无从得知。多模态场景下尤其难——单纯文本 QA 不够用,必须要"看图——多跳检索——验证证据——长链工具调用"这种轨迹型数据。
第二堵墙是工具环境。真实世界的图像往往是糊的、歪的、低分辨率的,光靠搜索引擎根本搜不出结果。Agent 必须先把图片裁剪、修复、增强,再决定下一步去哪里查。
第三堵墙是训练。多轮工具调用一旦中间一步崩了——超时、调用格式错误、查到无关结果——后面所有 token 都会被污染。直接丢掉整条 trajectory 浪费严重,全盘训练又会让噪声梯度毁掉模型。
OpenSearch-VL 给出的回应是:把这三堵墙各自拆掉,再拼成一条完整流水线。

数据:让维基百科自己生成训练题
整篇论文最有意思的设计在数据流水线。它不是雇人标注,也不是直接 prompt 大模型出题,而是把维基百科的超链接图当作天然的多跳推理图。
具体做法是这样的:从某个视觉锚点节点 v₀ 出发,沿着维基百科的链接图走 2 到 4 步随机游走,得到一条完整路径。路径首尾就是题目和答案——v₀ 提供图像(比如一张泰姬陵的照片),终点节点 vₕ 提供属性答案(比如"建造年代")。
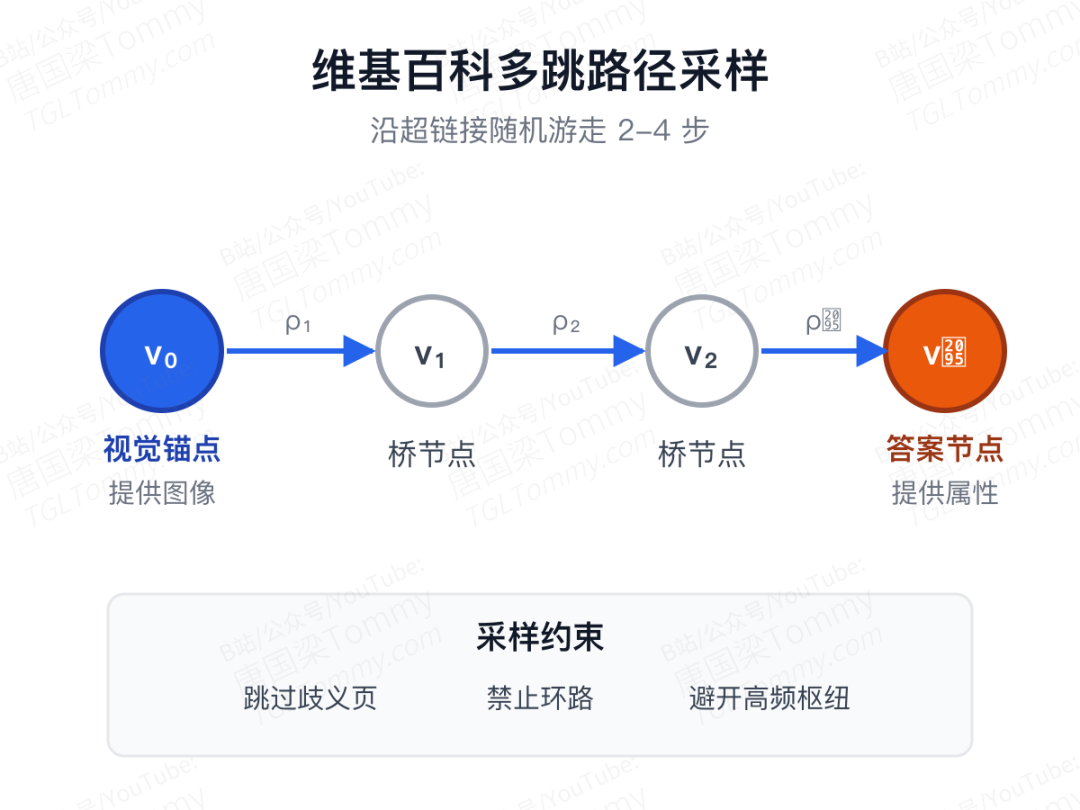
但这只解决了"出什么题",还有个更微妙的问题:直接让模型读到题目里的实体名(比如"泰姬陵建造年代"),它一步搜索就能拿到答案,根本不需要多跳推理,也不需要看图。
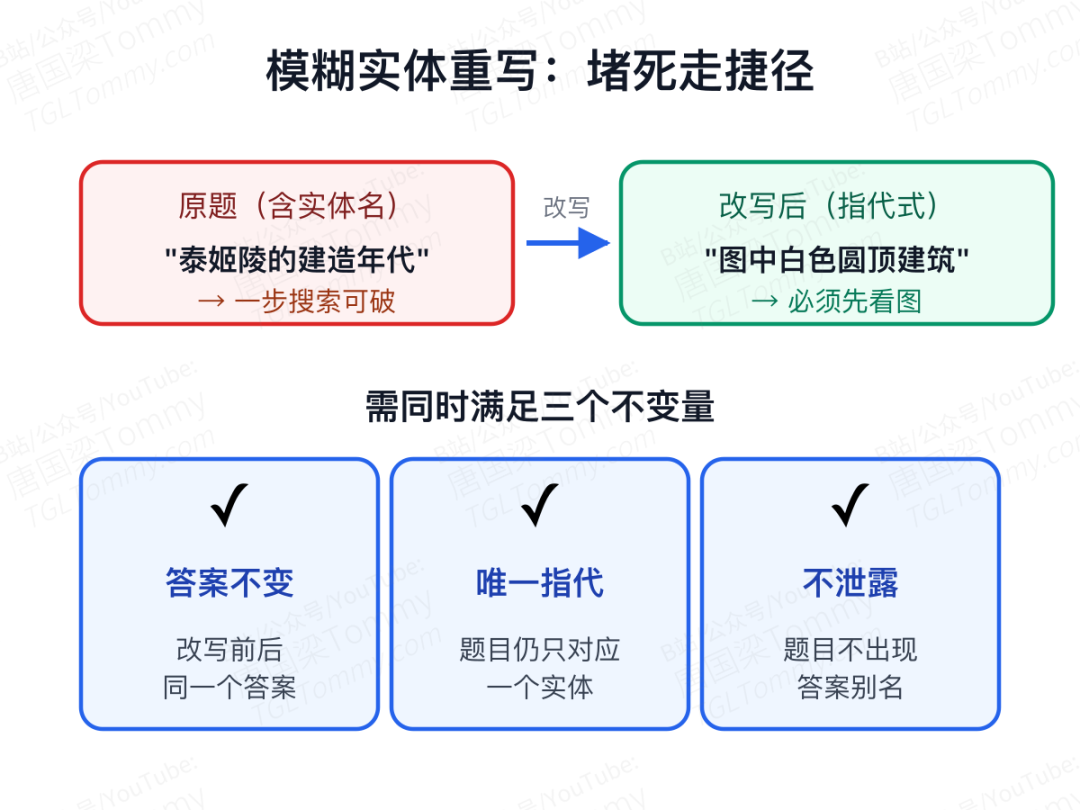
OpenSearch-VL 的对策叫模糊实体重写(Fuzzy Entity Rewriting)。它会把题目里的实体名一个个改写成关系或属性描述符,比如把"泰姬陵"换成"图中那座白色圆顶建筑"。改写要同时满足三个不变量才会被接受:
- 答案不变性:改完后答案还是同一个;
- 唯一性:题目仍然只对应一个实体;
- 不泄露:题目里不出现答案实体的别名。
最终配上锚点视觉 grounding——把 v₀ 替换成"图中的那个 X"这种指代表达式,强迫模型必须先看图、识别出锚点,才能开始走推理链。这一步直接堵死了"绕过图像、纯靠文本走捷径"的可能。
整条流水线再叠上质量控制和分阶段过滤,最后产出两个数据集:SearchVL-SFT-36k(用于监督微调)和 SearchVL-RL-8k(用于强化学习)。专家轨迹由 Claude Opus 4.6 在真实工具环境里合成,平均每条 6.3 轮工具调用,最终保留 36592 条高质量轨迹。
工具:搜索之外的一整套视觉修复
OpenSearch-VL 把工具集分成三类,覆盖了真实搜索场景中会用到的全部基础动作。
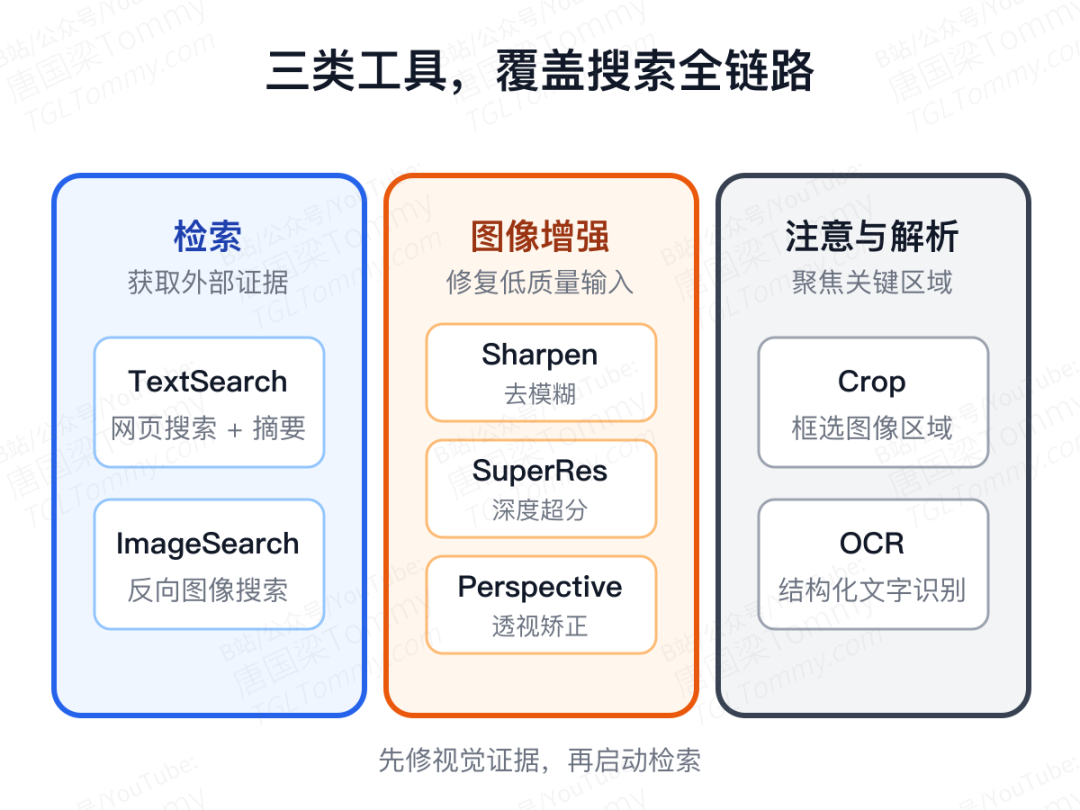
检索类包括 TextSearch(带页面阅读和 LLM 摘要的网页搜索)和 ImageSearch(反向图像搜索)。这是常规操作。
真正特别的是图像增强类——Sharpen 用反锐化掩模去模糊、SuperResolution 用 EDSR 做深度超分、PerspectiveCorrect 自动矫正歪斜文档。这三件工具是为了应对真实世界里那些"糊照片、低清缩略图、歪斜文档、拥挤截图"的输入。
最后是注意与解析类:Crop 让 Agent 自己框选图像区域,OCR 做带版面标签的结构化文字识别。
这套设计背后的判断很关键:纯检索不够,Agent 必须先把视觉证据修干净再去查。论文里把这种行为命名为 think-with-image——遇到不可靠的图像,模型会先调用增强工具修复,再启动检索。
训练:让失败轨迹也能被利用
最后一块拼图是训练算法。这部分论文用一节专门讲了一件事:失败的轨迹要怎么处理。
多轮 Agent 的训练有个长期头疼的问题——一条 16 轮的工具调用,前 14 轮推理都很合理,第 15 轮调用工具时格式崩了,导致最后一轮的回答完全错位。这时候直接判定整条失败丢掉,等于把前面 14 轮的有用学习信号一起扔了;可如果照单全收,post-failure 的 token 又是纯噪声。
OpenSearch-VL 的解法叫多轮 fatal-aware GRPO,在标准 GRPO 上加了两个机制。
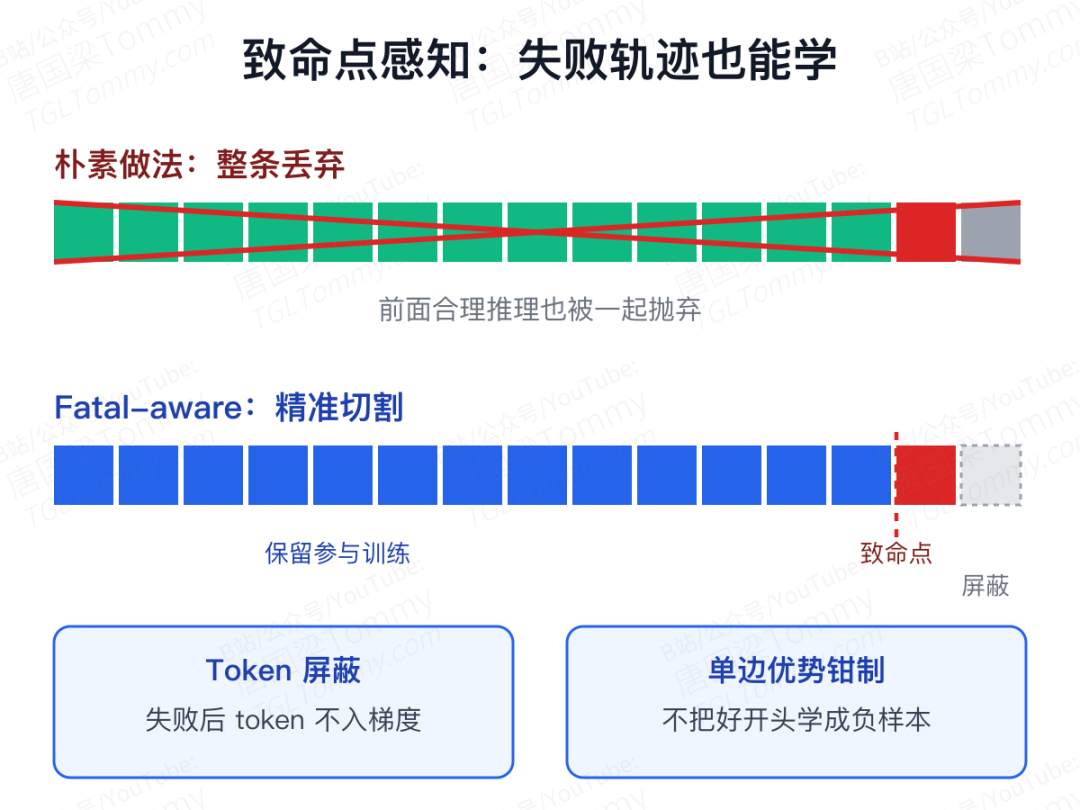
Token 屏蔽(fatal-aware token masking):在算策略梯度时,把失败点之后的所有 token 从优化目标里抹掉,只保留 pre-failure 部分参与训练。这样噪声梯度被切断了。
单边优势钳制(one-sided advantage clamping):对失败轨迹的负向 advantage 做单边夹紧,避免模型把"失败前那段合理推理"也学成需要避免的负样本。换句话说,模型仍然能从失败的开头学到正确的推理姿态,只是不再被失败的结尾带歪。
这个设计的直觉很朴素:别把婴儿和洗澡水一起倒掉。多轮 Agent 训练里大量轨迹是部分成功的,能不能从这些"半截好"的样本里榨出梯度,直接决定 RL 阶段能不能稳定收敛。
数字怎么样
实验跑在 Qwen3-VL-30B-A3B(MoE 架构)的基础上。和原始 baseline 相比,OpenSearch-VL 在 7 个多模态深度搜索基准上平均提升 13.8 个点——平均分从 47.8 抬到 61.6。
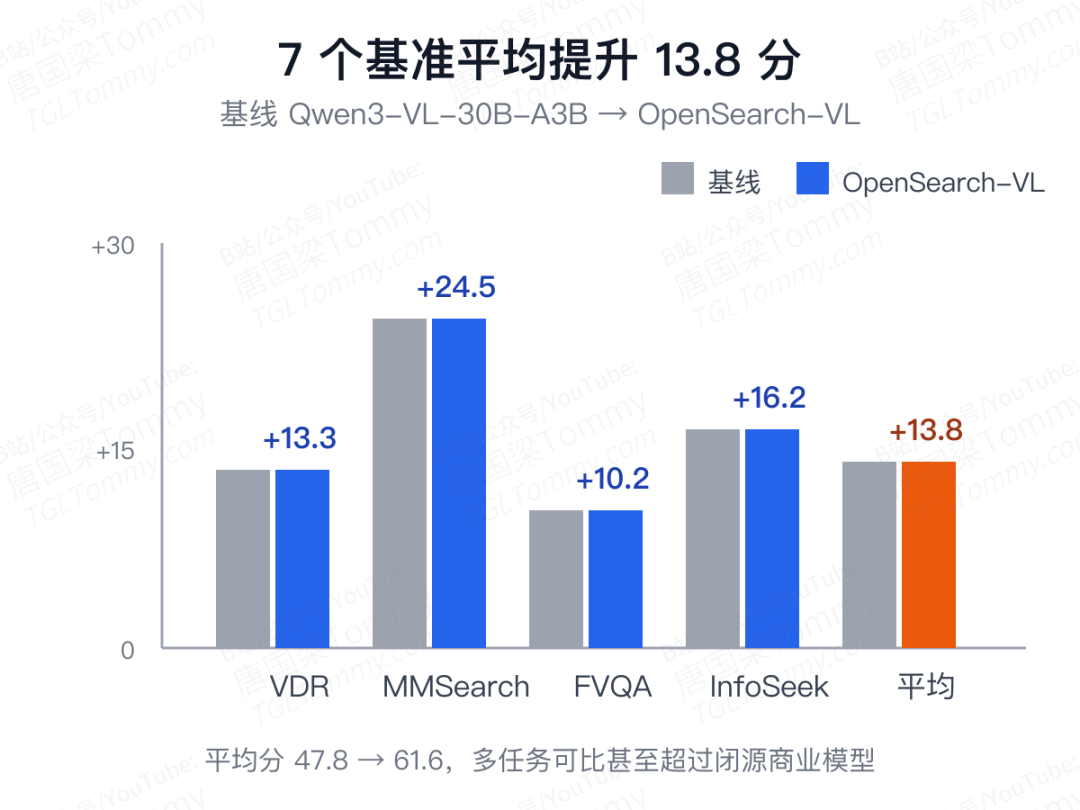
具体到几个有代表性的榜单:
- VDR(视觉文档检索):+13.3
- MMSearch(多模态搜索):+24.5
- FVQA(事实型 VQA):+10.2
- InfoSeek(信息搜寻):+16.2
更值得注意的是和闭源系统的对比。论文报告,OpenSearch-VL 在多个任务上达到了与商业模型相当甚至更好的水平。这意味着开源社区第一次有了一份不需要黑箱、不需要付费 API 就能复现的多模态搜索 Agent 基线。

它的边界在哪里
OpenSearch-VL 不是终点,论文本身也没有把它包装成"全面超越"。几个仍然存在的张力值得注意。
轨迹合成依赖闭源模型。专家轨迹是用 Claude Opus 4.6 跑出来的,这意味着开源管线的"教师信号"上限仍然受制于现有最强闭源模型。要做到完全闭环自给自足,还差一步。
评测覆盖的真实世界仍然有限。七个基准更偏知识密集型搜索,对于一些更长尾的领域——比如本地服务、动态电商、实时新闻——能力如何还有待观察。
工具集是面向搜索场景的。目前的工具集围绕"看图找信息"展开,要扩展到更复杂的具身场景(比如真实浏览器操作、长链表单填写),需要工具环境再做一轮扩张。
但这些限制不影响它的价值。一份真正可跑可复现的开源配方,本身就是社区最稀缺的东西。
一句话收尾
如果说过去一年多模态 Agent 的进展像一场看得见结果、看不见过程的魔术,OpenSearch-VL 把魔术师的台本完整摆在了桌上——从数据怎么造、工具怎么搭、失败怎么训,到最后的模型权重,全部公开。
接下来一段时间,最有意思的事情可能不是它本身,而是社区会基于这套配方做出什么。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号