在黑暗中进化的 Agent:没有标准答案,它怎么把自己越练越强?

在黑暗中进化的 Agent:没有标准答案,它怎么把自己越练越强?

唐国梁Tommy
发布于 2026-06-25 21:49:03
发布于 2026-06-25 21:49:03
我们已经习惯了一种朴素的进步叙事:模型越大越聪明,参数越多越能干。可一旦你真把一个 AI Agent 丢进生产环境,很快会发现一个反直觉的事实——决定它成败的,常常不是底层模型有多强,而是它身边那一圈"脚手架":它能调用哪些工具、记得哪些经验、遵循哪些工作流程。
模型可以靠训练不断变强。那这层脚手架,又该靠什么持续变强?

过去几乎所有答案都绕不开一件东西——标准答案。你得先准备一批带标注的验证题,让 Agent 在上面反复试错、打分、择优。但来自香港城市大学与微软亚洲研究院的一篇新论文,给出了一个相当大胆的回答:不需要。Agent 只要回过头复盘自己跑过的历史记录,就能把自己的工具箱升级一遍。在 SWE-Bench Pro 这个硬核的软件工程基准上,仅仅一轮复盘,通过率就从 59% 直接干到了 78%——全程没有用到任何外部评分。
这篇论文叫 Evolving Agents in the Dark,方法名为 RHO(Retrospective Harness Optimization,回顾式工具集优化)。下面我们拆开看它到底怎么做到的。
先搞懂一个词:Agent 的 "harness"
要读懂这篇论文,得先理解一个常被忽略的概念:harness(直译"挽具",这里指 Agent 的"工具集"或"装备外壳")。

一个 Agent 解决复杂任务,靠的从来不只是大模型本身的推理。它还依赖一整套外围装备:可以调用的工具(Tools)、积累下来的技能(Skills)、以及约束行为的指令(Instructions)。论文把这套装备具象成了一个工作目录——可执行脚本就是工具,markdown 文件就是技能与指令。模型是固定不变的"大脑",而 harness 是可以被随时改写的"外骨骼"。
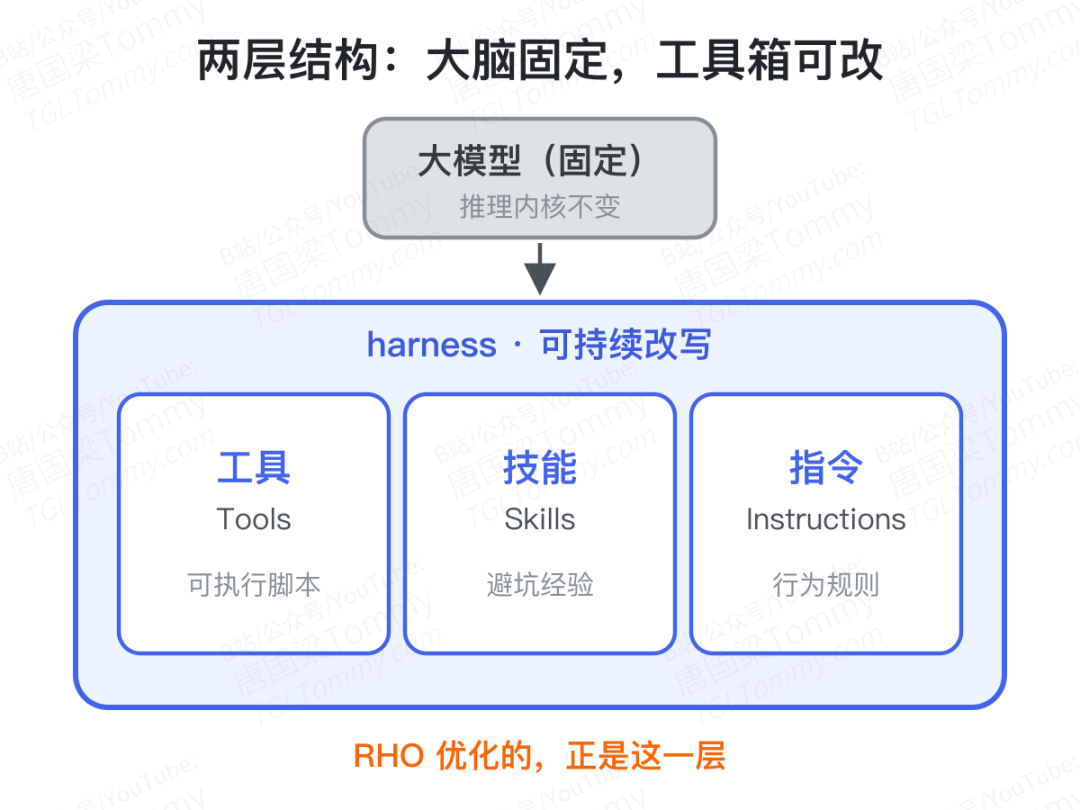
关键洞察在于:很多时候 Agent 表现不好,不是因为模型笨,而是因为它的工具箱里缺了一把趁手的螺丝刀,或者一条"这个坑别再踩"的提醒。持续打磨这层工具箱,往往比换更大的模型更划算。
老办法的死结:你得先有"标准答案"
那为什么"持续打磨工具箱"这件事一直没被解决好?
因为过去的主流方法——无论是提示词搜索、声明式流水线编译,还是让元智能体改写代码的 Meta-Harness——都有一个共同前提:拿一个带标注的验证集来打分。每改一版工具箱,就在验证题上测一遍通过率,留下分数最高的那版。
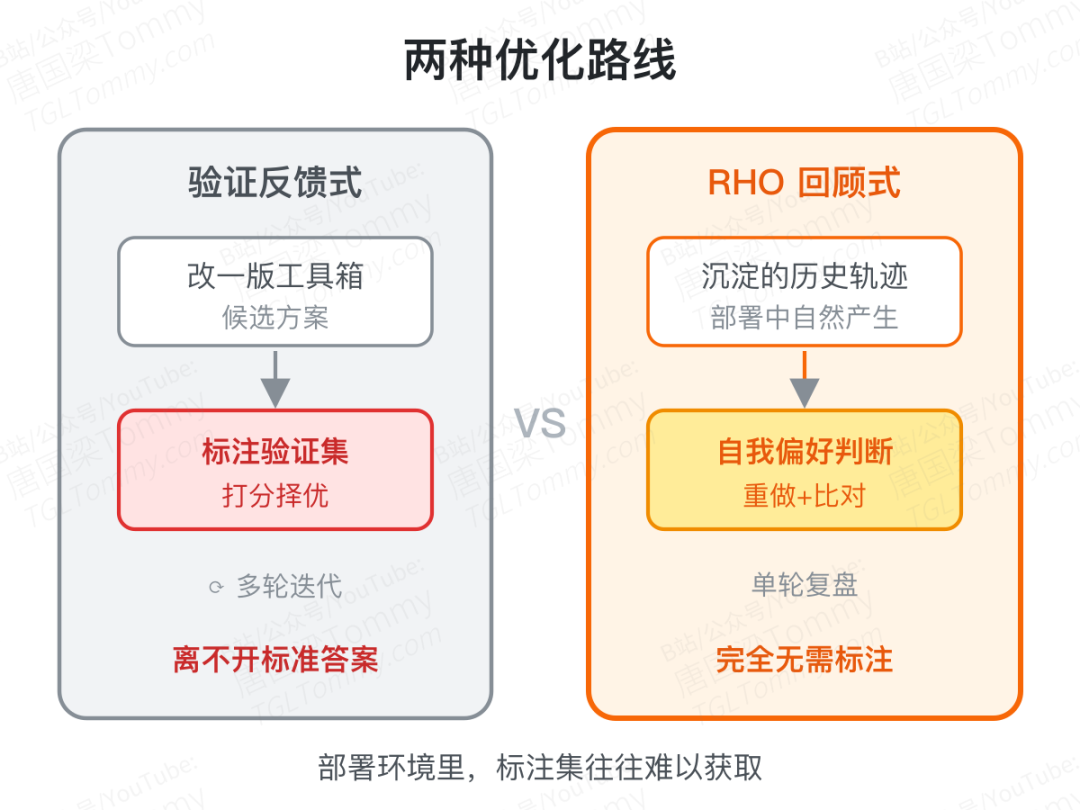
这在实验室里行得通,到了真实部署场景却常常卡壳:你很难提前攒出一批能准确代表"未来任务分布"的标注题。任务是动态变化的,标注是昂贵的,等你标好,分布可能已经漂移了。
但论文作者注意到一个被浪费掉的资源:Agent 在持续运转中,本身就会源源不断地产生大量轨迹(trajectory)——它读了什么、怎么想的、调了哪些工具、最后交出什么结果,全都被记录了下来。这些历史里,藏着大量"哪里做砸了""怎么做才对"的信号。
于是核心问题变成了:能不能只用这些没有标注的历史轨迹,就把工具箱优化好?
RHO 的解法:让 Agent 当自己的"复盘教练"
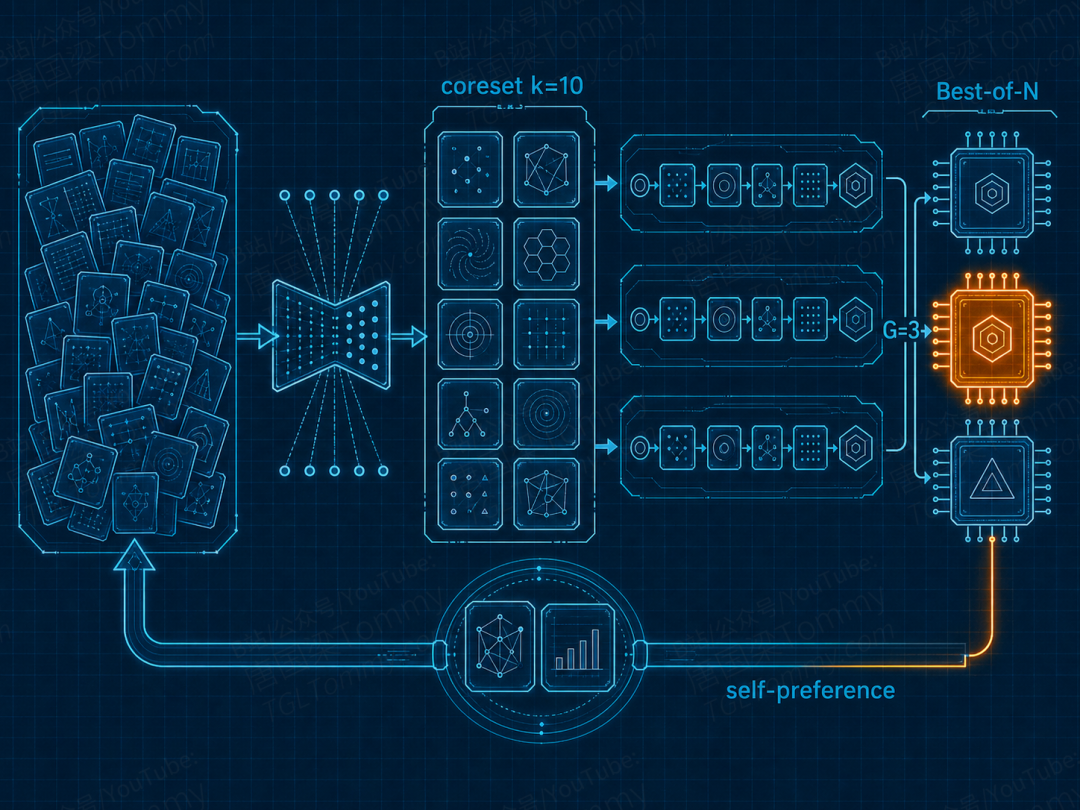
RHO 的核心赌注是:用 Agent 自己对轨迹的偏好判断(self-preference),去替代那个缺失的标准答案。整个流程分三步走。

第一步,挑出最该复盘的题(Coreset Selection)。 历史轨迹动辄成千上万,全拿来优化既烧钱又会被大量琐碎信号淹没。RHO 用一个叫 DPP(行列式点过程) 的数学工具,从海量轨迹里挑出一小撮"既难又多样"的代表题。这里有个微妙的平衡:只挑最难的,会扎堆在某一类题上;只追求覆盖广,又抓不住痛点。论文用一个权重参数 θ=0.7,让难度和多样性兼顾——实验证明,单独偏向任何一边,效果甚至还不如随机抽样。
第二步,重做一遍,从分歧里找毛病(Group Rollout)。 对挑出来的每道题,RHO 让 Agent 并行重做好几遍,然后从这组结果里提炼两类诊断信号:
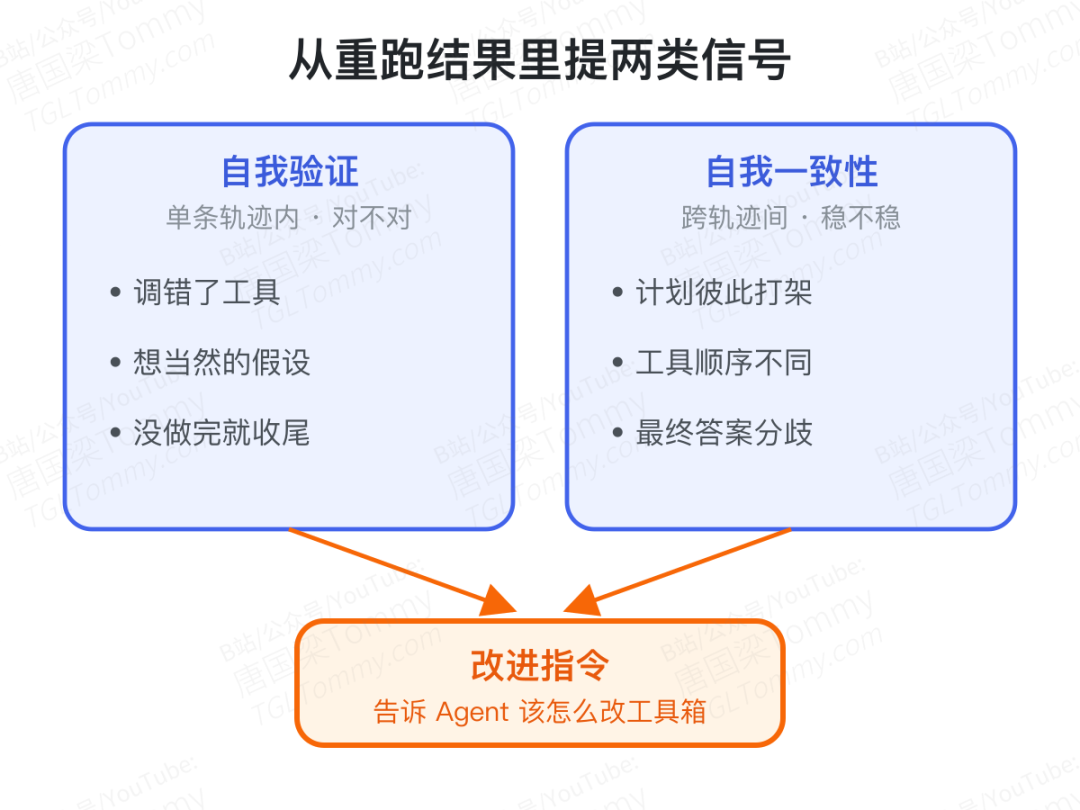
- 自我验证(Self-validation):审视单条轨迹内部对不对——有没有调错工具、有没有想当然的错误假设、是不是没做完就草草收尾。
- 自我一致性(Self-consistency):比对多条轨迹之间一不一致——如果几遍跑出来的计划、工具顺序、最终答案彼此打架,说明这道题 Agent 心里没底、不确定性高,正是需要加固的地方。
这两路信号合在一起,就成了"该怎么改工具箱"的具体指令。
第三步,多生成几版,选自己最满意的(Best-of-N)。 工具箱优化本身是有随机性的,给对了信号也未必一次就改好。所以 RHO 一口气生成 N 个候选工具箱,让每个都重新跑一遍那些代表题,再用 Agent 的两两偏好打分,留下最被偏爱的那一版——并且只在它确实优于原版(分数大于零)时才接受。
整个过程没有任何一处用到外部的标准答案,全靠 Agent 自己跟自己较劲。
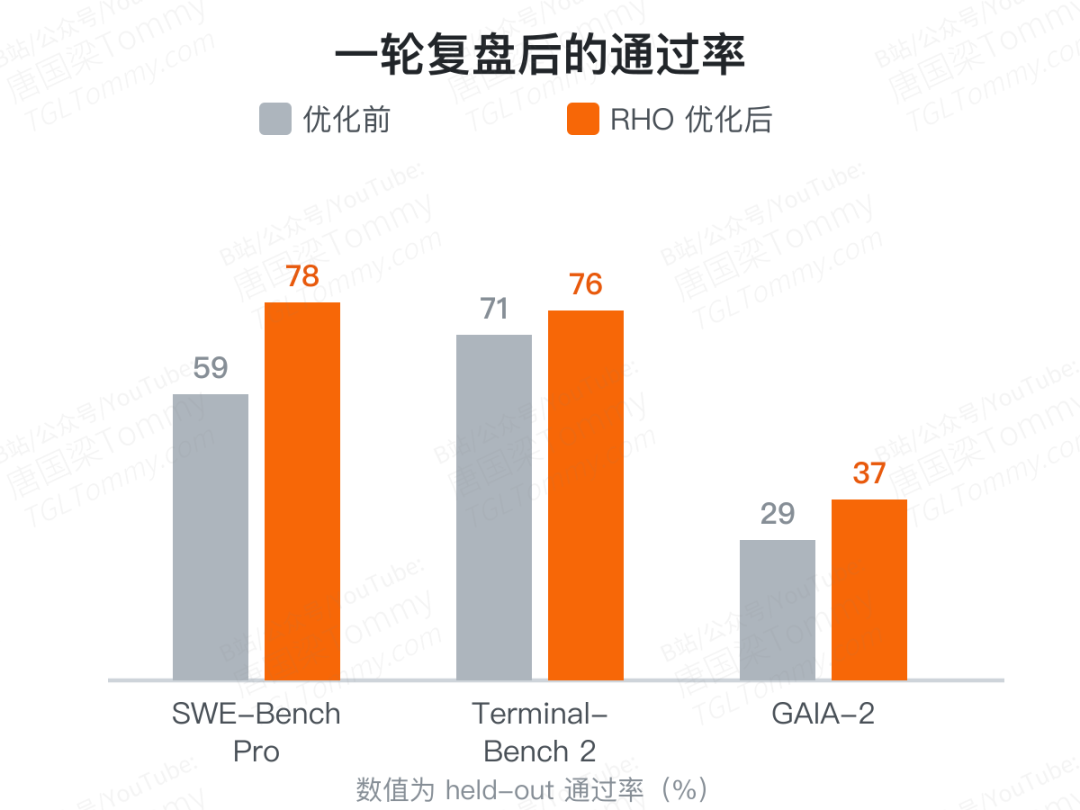
结果:一轮复盘,59% 冲到 78%
数字很有说服力。在三个跨度极大的领域基准上,仅一轮 RHO 优化的成绩是:
- SWE-Bench Pro(软件工程):59% → 78%,绝对提升 19 个百分点;
- Terminal-Bench 2(命令行技术活):71% → 76%;
- GAIA-2(知识工作):29% → 37%。
作为对比,几个同样"不需要标注"的主流方法(Dynamic Cheatsheet、ReasoningBank、Sleep-time Compute)在同样预算下,提升大多只有 1 到 5 个百分点,远不及 RHO。论文把这归因于 RHO 改的东西更彻底——它能新建工具、技能和指令,而不是像那些方法一样只在"记忆"层面打转。
更耐人寻味的是和需要标注的 Meta-Harness 的对比:RHO 不用任何标注、花 1 倍算力,拿到 0.78;Meta-Harness 在同等单轮预算下只有 0.62;硬要追平 RHO,它得跑满 10 轮、烧掉约 3 倍算力,才勉强到 0.80——而且全程离不开标注。
它到底改了什么?答案是"自我验证"
那 RHO 究竟往工具箱里塞了什么,让 Agent 脱胎换骨?
论文给的例子很具体。在 SWE-Bench Pro 上,Agent 通过复盘发现:Go 的工具链装在一个非标准路径下、默认找不到;Python 的缓存目录如果不在生成最终 diff 前清理掉,补丁就经常打不干净。于是它给自己新建了一个 check_build_and_lint 工具,专门定位这些非标准工具链、并标出那些必须排除在补丁之外的产物——精准堵上了原来反复踩的坑。
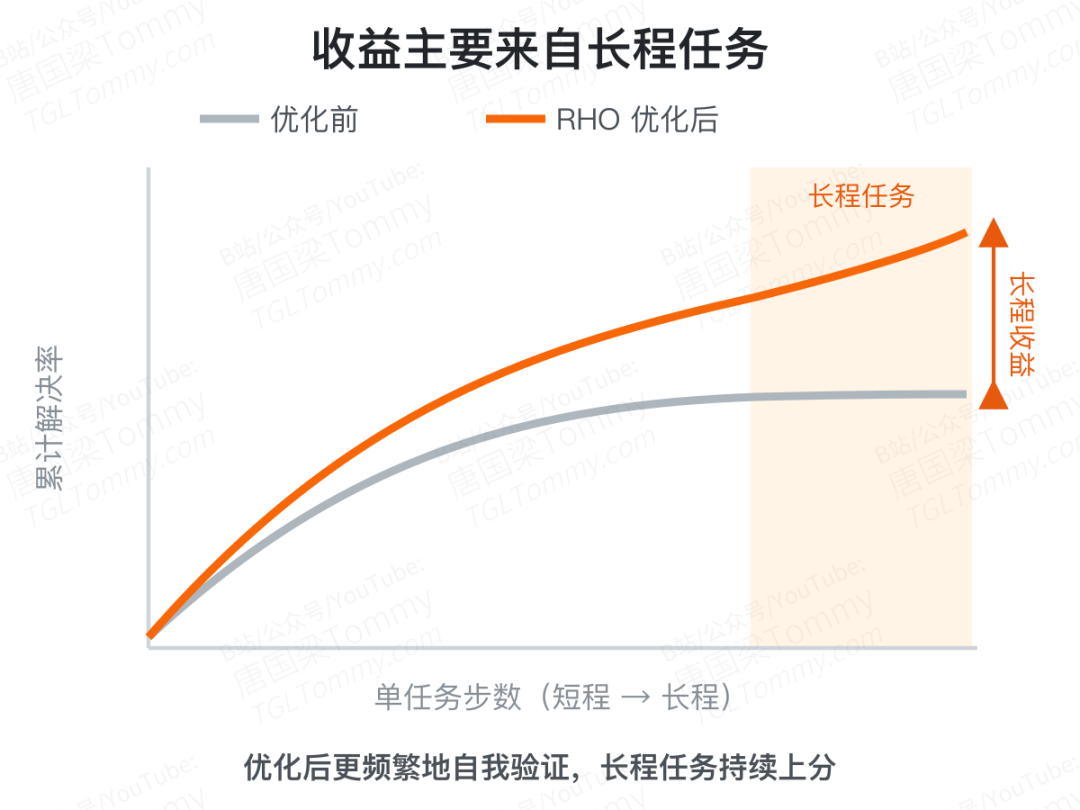
更深一层的观察是:性能提升几乎全部来自那些需要很长步骤才能完成的"长程任务"。而优化后 Agent 的工作方式也变了——在 SWE-Bench Pro 上,它开始更频繁地验证自己的工作,这种"做完不急着交、先自查一遍"的习惯,正是长程任务上涨分的主力;在另外两个基准上,则表现为更主动地调用新造的工具。
消融实验进一步证明这两路信号缺一不可:去掉"自我一致性",SWE-Bench Pro 直接从 0.78 跌到 0.56;去掉"自我验证"也明显下滑。把原始轨迹一股脑丢给优化器、跳过显式诊断,效果同样更差。换句话说,先把毛病诊断清楚,再动手改,比"凭感觉改"靠谱得多。
别急着乐观:三个现实边界
RHO 很漂亮,但作者自己也划清了边界,这点值得尊重。

其一,它需要能反复重来的环境。 "重做一遍"是整套方法的地基,这意味着环境得能干净地重置、容忍多次尝试——那些一次性、不可逆的任务,RHO 暂时管不了。
其二,它假设能力主要由可编辑的工具箱承载。 论文验证的是软件工程、技术活、知识工作这三类;换到工具箱形态、任务特征都不一样的领域,能不能照搬还是未知数。
其三,它完全信任历史轨迹。 这是最微妙的一条:如果某条轨迹在执行中途被注入了对抗性内容,从这种被污染的历史里"复盘"出来的工具箱,反而可能把坏行为固化下来。作者因此专门建议——部署时要保留完整的审计日志、敏感的工具箱改动需要人工审批。
写在最后
RHO 真正有意思的地方,其实不在那个 19% 的数字,而在它换了一个看问题的角度:一个 Agent 跑过的历史,本身就是一座还没被开采的金矿。 重做几遍、互相比对,哪里不行、该怎么改,信号其实都埋在里面,根本不必外求一份标准答案。
在标注数据稀缺、任务分布又不断漂移的真实部署环境里,这种"自己复盘自己、在黑暗中摸索着进化"的能力,也许比再大一号的模型更稀缺、也更值钱。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号