均匀扩散语言模型:第三条大模型路线,第一次被真正训练到了 7B

均匀扩散语言模型:第三条大模型路线,第一次被真正训练到了 7B

唐国梁Tommy
发布于 2026-06-25 21:49:28
发布于 2026-06-25 21:49:28
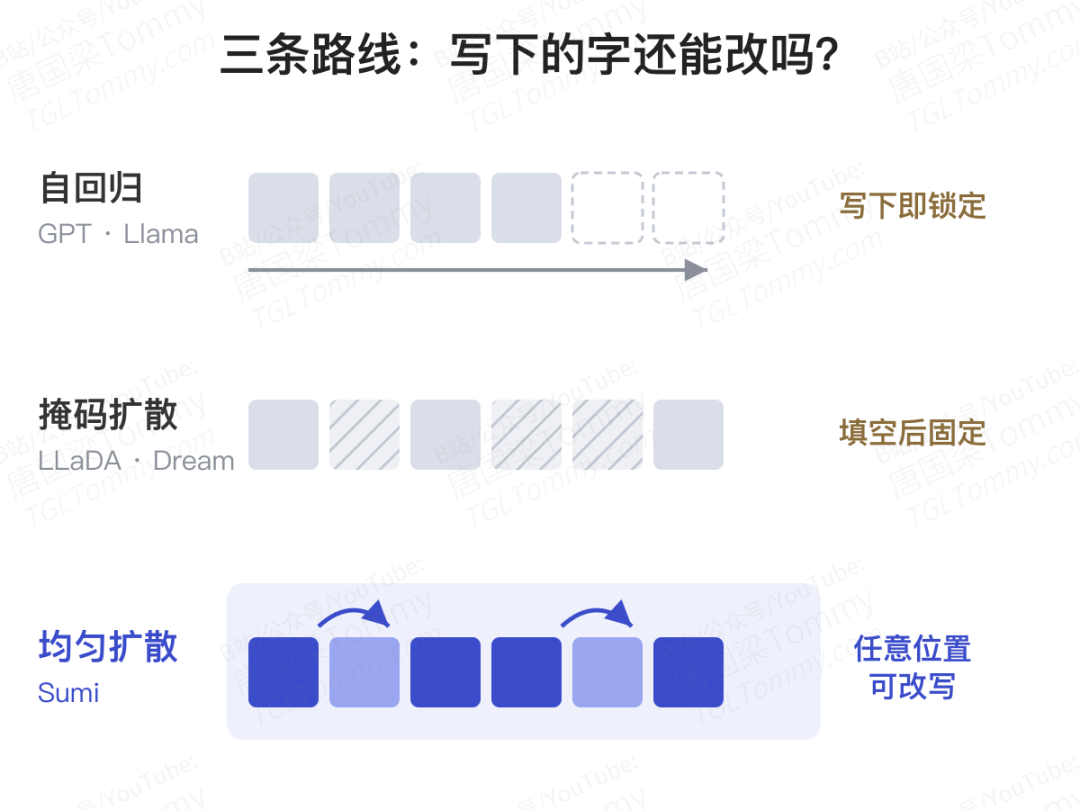
我们已经习惯了大模型一个字一个字往外蹦。从 GPT 到 Llama,主流大语言模型走的都是同一条路——自回归(autoregressive):从左到右,一次只决定下一个 token,前面写下的字再也不能改。
但这并不是唯一的可能。最近几年,扩散模型(diffusion)成了一个有力的替代方向:不再逐字生成,而是先铺满一片「噪声」,再一步步把它去噪、还原成通顺的文本。其中又分两支。一支叫掩码扩散(masked diffusion),代表是 LLaDA、Dream——它把一些位置盖上「掩码」,再逐步填空,填上去就定下来。
还有一支,几乎没人真正认真训练过。它叫均匀扩散语言模型(Uniform Diffusion Language Model,简称 UDLM)。
来自日本东北大学等机构的一篇新论文,第一次把这条路线推到了大规模:一个 7B 参数、从零用 1.5T token 训练的均匀扩散模型,全部权重、检查点和数据配方完全开源。它的名字叫 Sumi,日语里是「墨」的意思——文本从噪声中渐渐显形,就像墨在水里晕开。

缺失的那一角:均匀扩散到底特殊在哪
要理解 Sumi 的价值,先得看清三条路线的差别。
自回归是「写下就不能改」:第 5 个字定了,哪怕后面发现不对,也只能将错就错。掩码扩散松了一档:被掩码的位置可以慢慢填,但一旦填上某个真实 token,它通常也就固定了。
均匀扩散更彻底——任何位置、任何一步,都可以被重新改写。它不区分「掩码」和「真实 token」,整张画布上的每个字在去噪过程中都可能被推翻重来。理论上,这给了模型最大的自由:可以反复斟酌、随时返工,而不是被生成顺序锁死。
听上去很美,可现实是:这条路线一直是张白纸。自回归有 GPT、Llama 可以研究;掩码扩散有 LLaDA、Dream 可以站在肩膀上;而均匀扩散在大规模、大数据量的现代语境下,几乎没有任何可参照的模型。此前训过的 UDLM 要么是小算力下的「计算最优」检查点,要么最大只到 1.7B 参数。
换句话说,没人知道:当你把均匀扩散真正放大到 7B、喂进上万亿 token,它会表现成什么样?Sumi 就是为了填上这个问号而生——它不追求刷榜第一,而是想给社区一个干净的参照点。
Sumi 是怎么炼成的
Sumi 是一个 7B 参数、时间无关的双向 Transformer,骨架沿用了 LLaMA 风格的常规配置:36 层、隐藏维度 4096、SwiGLU、分组查询注意力、RoPE、OLMo 3 分词器。训练目标用的是 GIDD(广义插值离散扩散)框架的信噪比重参数化版本,纯均匀噪声。
真正的工程量在算力和数据上。团队动用了 288 张 NVIDIA H100,总共烧掉约 4.3 万 GPU 小时,分成预训练和两阶段「中训练」:
- 预训练:约 1.3T token,序列长度 1184;
- 中训练:先 130B token,再把序列扩展到 4864 做 120B token,合计约 250B。
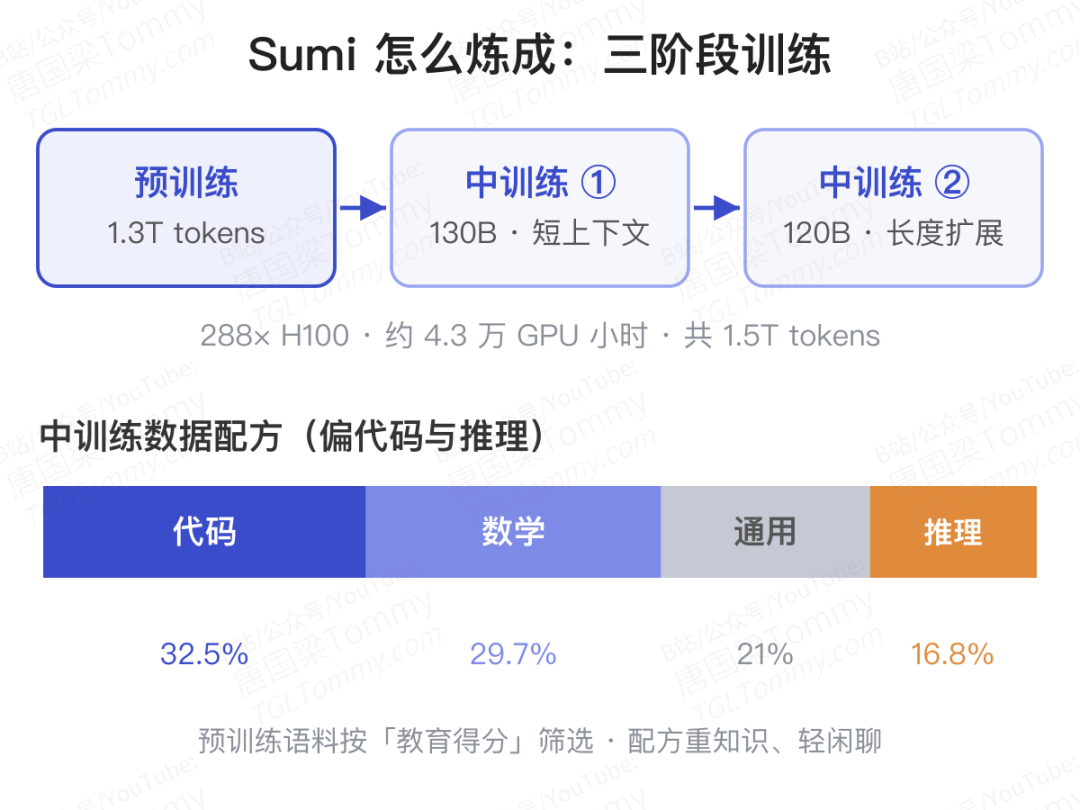
数据配方是这篇论文最舍得交底的地方,也是它和大多数「开源模型」的关键区别——Sumi 和 OLMo 是对比阵营里仅有的两个完全公开训练数据的模型。预训练语料按「教育得分」做了筛选和重排(用一个从 Qwen3-32B 蒸馏出的轻量分类器打分,保留高分文档);中训练则明显偏向代码、数学和推理:代码 32.5%、数学 29.7%、通用文本 21%、推理 16.8%。
这套「重教育、重代码」的配方,几乎注定了 Sumi 的性格——它会在知识和代码上很强,在「家长里短」的常识上吃亏。后面的结果正是如此。
实测:知识和代码亮眼,常识掉队
论文在 13 个基准上,把 Sumi 和同量级、同 token 预算的开源自回归模型(Falcon-7B、Llama 2-7B、OLMo-7B)放在同一套评测协议下硬碰硬,另外列出 LLaDA-8B、Llama 3-8B 的参考分数。
在协议内对比里,Sumi 的成绩相当能打:
- 通用知识最强——MMLU 拿到 51.1,而 Llama 2 是 46.0、OLMo 只有 28.0;
- 代码最强——HumanEval 22.6(Falcon 直接 0 分、Llama 2 仅 12.8);
- 数学推理有亮点——GSM8K 32.8,明显领先同组,整体与 Llama 2 互有胜负。
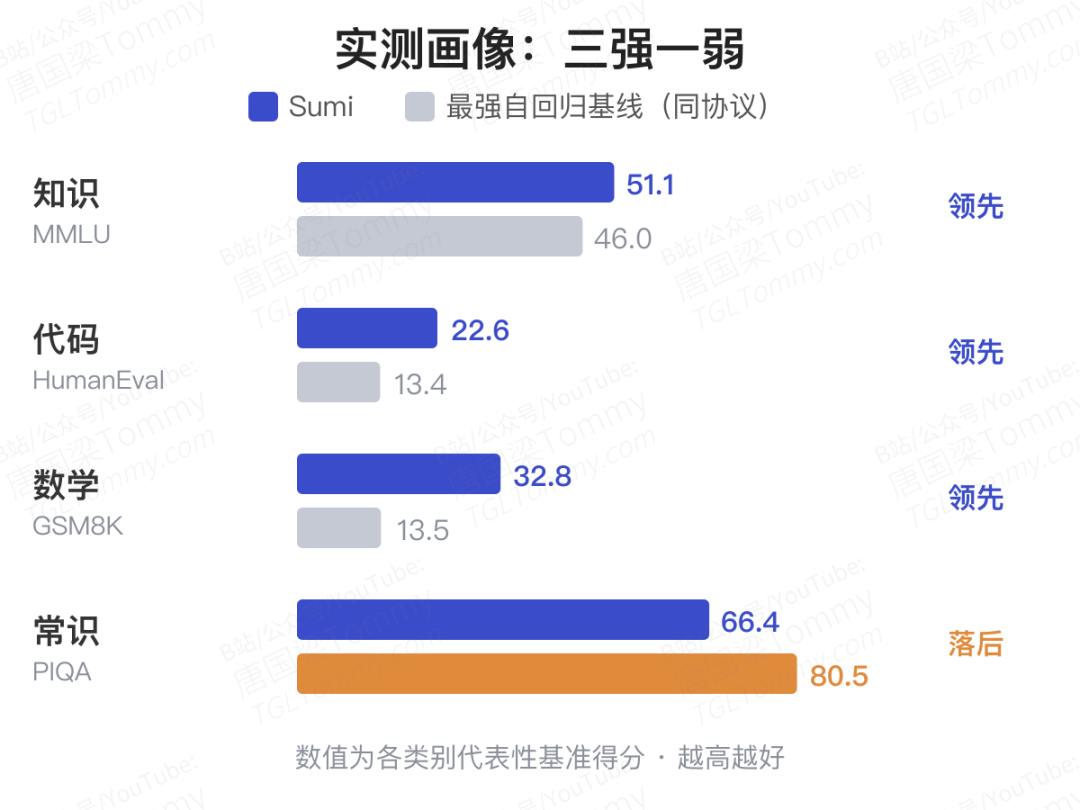
代价也很明确:常识类基准是 Sumi 的软肋。PIQA、HellaSwag、WinoGrande 上它都排在末尾,比如 PIQA 只有 66.4,而 Falcon 有 80.5。论文坦承,教育导向的数据配方是「嫌疑人」之一——过度的质量筛选确实会拉高知识/推理、压低常识——但也诚实地补了一句:这个差距太大,光靠数据配方解释不了,留待后续研究。
需要说明:作为参照的 LLaDA-8B(掩码扩散)和用了 15T token 的 Llama 3-8B 整体更强,但前者不开数据、后者训练量是 Sumi 的十倍。Sumi 的意义不在于赢过它们,而在于证明这条路线在大规模下确实跑得通。
当模型「随时能改字」,会发生什么
光有一个能用的模型还不够。论文真正有趣的部分,是四个小规模的「探针实验」(每个任务只取 30 道题,作者反复强调这是方向性观察、不是定论)。它们试图回答一个核心问题:当一个模型理论上随时能改写任何字,它的生成行为会变成什么样?
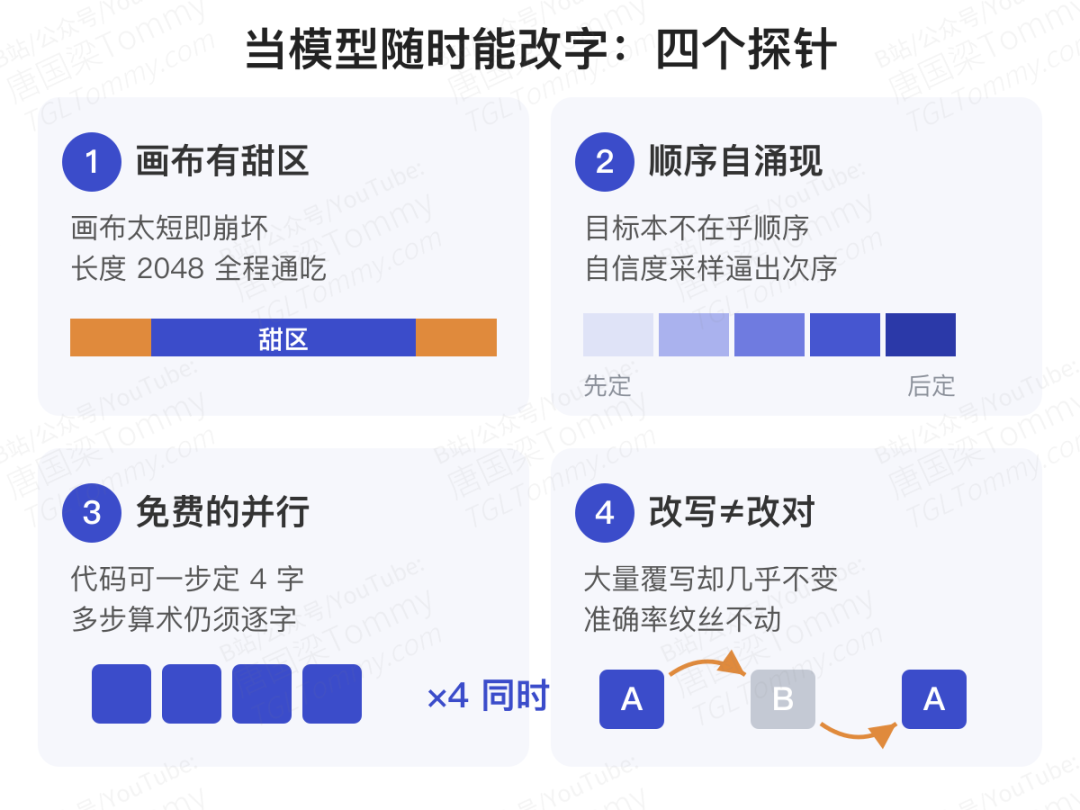
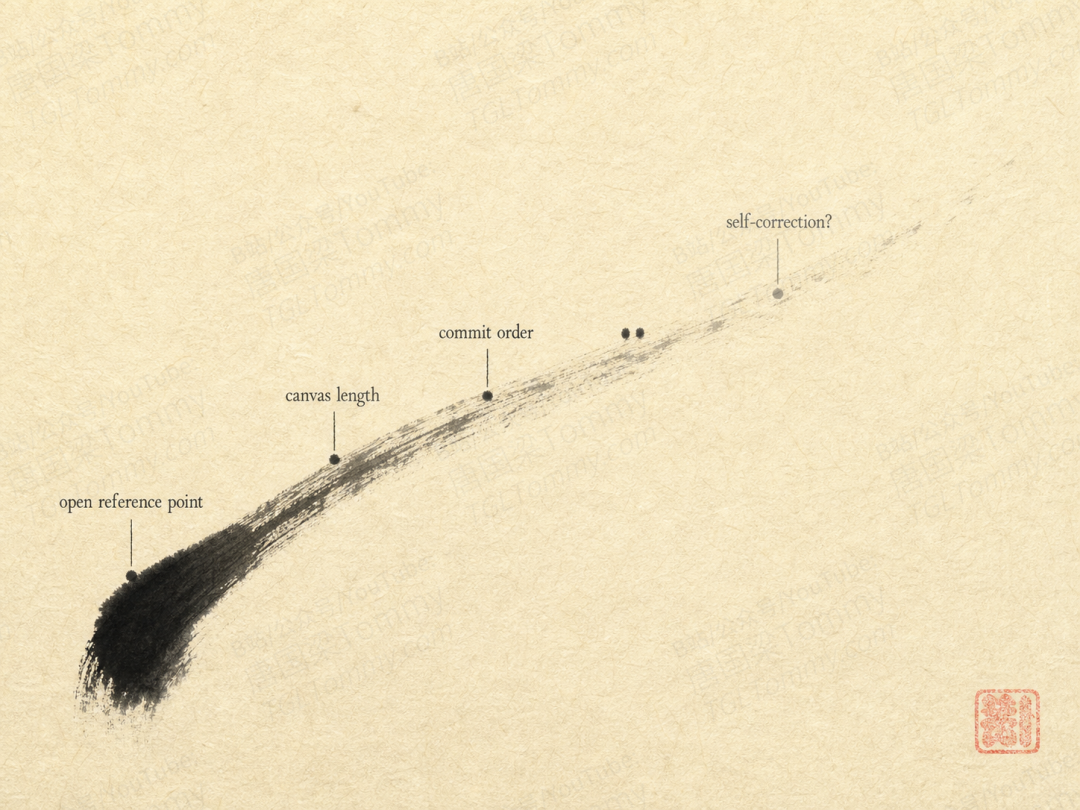
第一,画布大小很挑任务。 均匀扩散生成时要先铺一张固定大小的「画布」(canvas,即一开始分配多少个 token 位置)。Sumi 只在一个与任务相关的「舒适区间」里写得流畅,画布太短会崩(GSM8K 尤其敏感,一出训练范围就输出近似乱码),有些任务画布太长也会退化。好在 2048 这个长度对所有任务都落在舒适区,所以全程用它。
第二,「自信度采样」会自发涌现出书写顺序。 Sumi 的训练目标是完全不在乎顺序的,可一旦用基于「自信度」的采样器——优先确定那些它已经很有把握的位置、把拿不准的往后拖——模型就自发组织出了一种清晰的提交顺序。换成随机的祖先采样,这种结构就消失了。也就是说,顺序不是模型自带的,是采样策略「逼」出来的。
第三,这种结构换来了一点「免费的并行」。 掩码扩散通常需要一步只定一个 token 才最准。Sumi 在代码任务上则可以一步同时敲定 4 个 token,精度几乎不掉——相当于白赚了并行加速。但多步算术(GSM8K)不行,一步定 2 个就立刻变差,说明它对顺序高度敏感。
第四,「能改字」并不等于「会改对」。 既然均匀扩散能覆写已定下的 token,那多给它几轮去噪,它会自我纠错吗?实验给了个反直觉的答案:58% 到 100% 的修订步骤确实在覆写 token,但净效果几乎为零——最终改动不到 1% 的字,答案几乎从不翻转,准确率纹丝不动。细看轨迹,这些覆写大多是「A 改成 B 又改回 A」的来回打转,而不是有方向的修正。额外算力没有自动变成自我纠错。
它的价值与它的诚实
把这些放在一起看,Sumi 的贡献其实是双层的。
表层是一个能用、且完全可复现的 7B 均匀扩散模型:权重、中间检查点、完整训练配方、数据配比,全都摆上了台面。对一个此前几乎空白的方向来说,这等于一次性给社区交付了「第一块可以踩的砖」。
更深一层,是那四个探针抛出的开放问题:均匀扩散的「随时可改写」到底是真优势,还是只是没被用对?自信度采样涌现出的顺序结构、代码任务上的免费并行、迟迟不出现的自我纠错——这些现象哪些是均匀扩散这条路线本身的特性,哪些只是 Sumi 这个具体模型的偶然?论文很克制地承认:它提出了这些问题,但没有回答。
局限也写得很坦白:探针只跑了 30 道题,用 Falcon 困惑度做流畅度的粗略代理,没有做严格的对照实验;常识的大幅落后超出了数据配方能解释的范围;模型本身只是个未经指令微调和安全对齐的基座,会一本正经地胡说、也可能产出有害内容,作者明确说它是给研究用的,不是拿来直接部署的。
一篇不急着宣布「我赢了」、而是认真把一条冷门路线推到能被研究的论文,本身就稀缺。Sumi 团队已经预告,指令微调版本会在后续放出。墨已经落进水里,接下来要看的,是社区能从这片晕开的痕迹里,读出多少关于第三条路线的答案。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号