从对齐偏好到提升推理:RADIO框架如何重塑检索增强生成

从对齐偏好到提升推理:RADIO框架如何重塑检索增强生成

用户9565775
发布于 2026-06-26 08:47:03
发布于 2026-06-26 08:47:03
检索增强生成(RAG)技术通过连接大语言模型与外部动态知识库,有效应对了大模型的知识时效性、幻觉等挑战。然而,其核心组件间的偏好错位——重排序器偏好的“相关”文档与生成器实际所需的“支持性”文档之间的不一致——一直是阻碍系统性能突破的瓶颈。本文将深入剖析一项名为RADIO(RAtionale DIstillatiOn)的前沿创新框架,它通过蒸馏生成器的推理依据来对齐组件偏好,为RAG系统的发展开辟了新路径。(扩展阅读:全模型微调 vs LoRA 微调 vs RAG、专业级RAG系统设计与实现:高召回可溯源的多文档知识库解决方案、海马体启发的长期记忆革命:HippoRAG架构设计与多跳推理突破、检索增强生成(RAG)与微调(Fine-tuning)的架构创新设计:技术演进、适用场景与实战指南、量子纠缠架构下的RAG与微调协同创新:确定性推理与自适应学习的统一范式、从开卷考试到智能思辨:RAG技术演进全景透析、告别“无限上下文”的幻觉:大模型知识注入的“四层矩阵”与下一场权重战争、大模型幻觉治理新范式:SCA与[PAUSE]注入技术的深度解析与创新设计、幻觉与模仿:深入剖析当前大语言模型为何未能跨越“理解”与“推理”的鸿沟、幻象克星:大模型架构创新与对抗幻觉的深度博弈_抗幻觉" 模型、大模型幻觉问题的深度解析与架构设计解决方案)
背景与挑战:为什么需要RADIO?
RAG:大模型能力的扩展范式
大语言模型(LLM)虽然展现出了强大的生成与推理能力,但其“参数化记忆”存在固有的局限:知识是静态的、易产生幻觉,且难以获取实时或私有领域信息。RAG范式通过引入“非参数化记忆”——即外部知识库——有效弥补了这些不足。其标准流程通常包括索引构建、语义检索和增强生成三个核心阶段,其架构演变可概括如下:
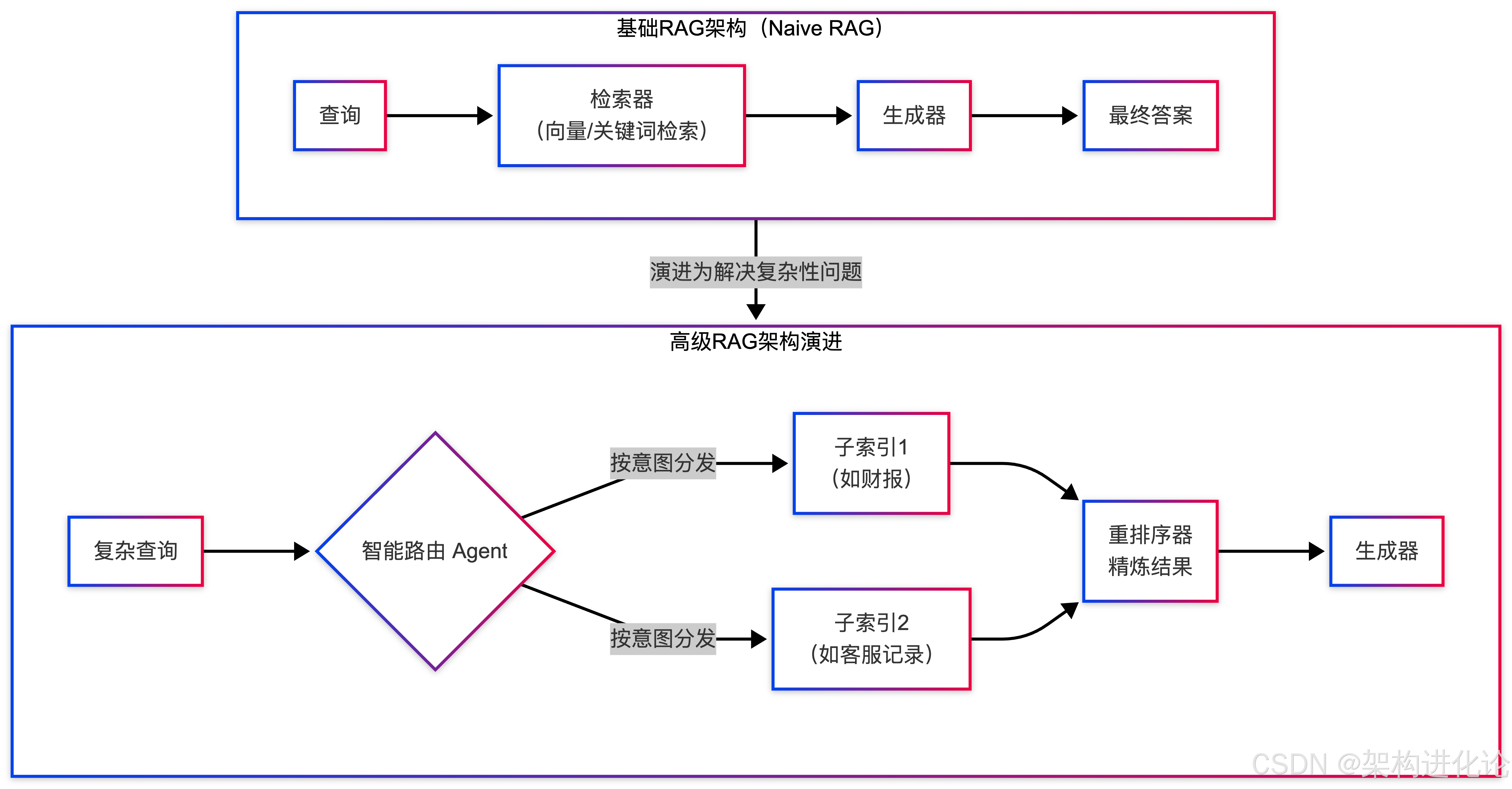
尽管高级RAG架构通过引入智能路由、混合检索、重排序(Reranker)等技术大幅提升了性能,但其检索与生成环节的目标不一致性这一根本挑战却始终存在。
核心痛点:重排序器与生成器的“偏好鸿沟”
在RAG流水线中,重排序器负责对初步检索到的海量文档进行精细排序,挑选出最相关的若干篇供给生成器。然而,重排序器通常基于查询-文档对的相关性进行训练和推理,其目标是判断“这篇文档是否与问题在主题上相关”。
而生成器的需求则不同,它需要的是能够直接支撑答案推导的证据或信息片段。一篇与问题主题高度相关、提及了所有关键词的文档,可能并未包含生成具体答案所需的关键事实、数据或逻辑链。
这种由预训练数据与优化目标差异导致的组件间偏好错位,使得重排序器精心挑选的“最佳”文档,在生成器眼中可能并非最优选择,最终导致系统给出的答案准确性下降。
RADIO框架:架构与工作原理
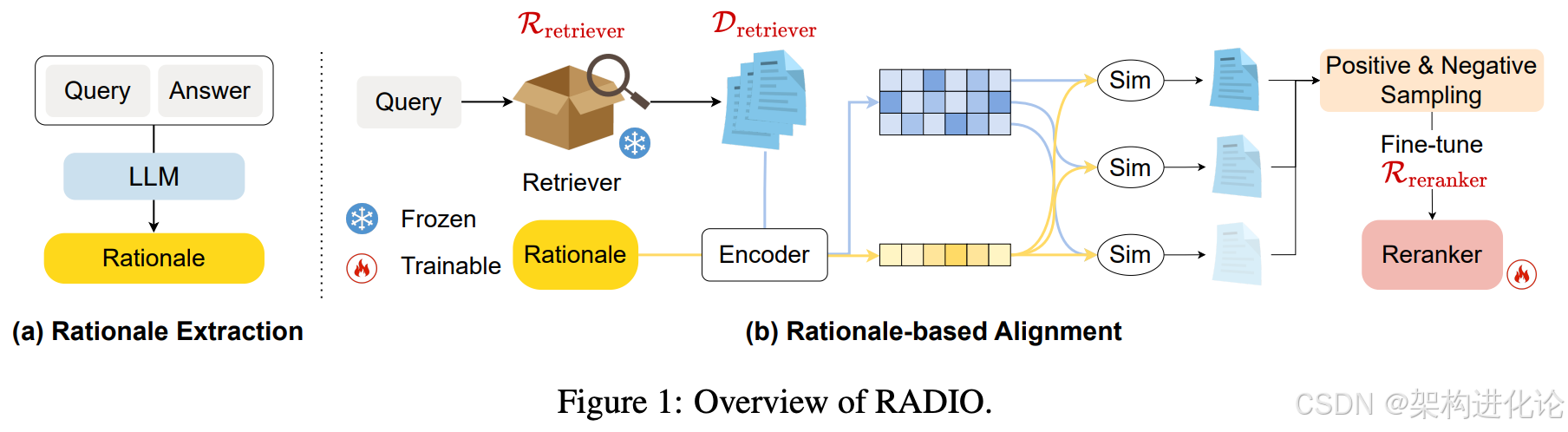
RADIO框架的核心思想是知识蒸馏:将生成器(通常是一个强大的LLM)在生成答案时所依赖的、隐式的“推理依据”显式地提取出来,并以此为标准,去指导和重新训练重排序器,从而使两者的目标对齐。(扩展阅读:RLHF:大模型价值观对齐的关键技术演进与实践、化解对齐税:RLHF对齐过程中的模型平均化创新方法、ORPO:颠覆传统,偏好对齐的简约革命、大模型偏好对齐强化学习技术:从PPO、GRPO到DPO的演进与创新)
整体架构概览
RADIO框架的运作可分为两个核心阶段,其完整的工作流程如下图所示:
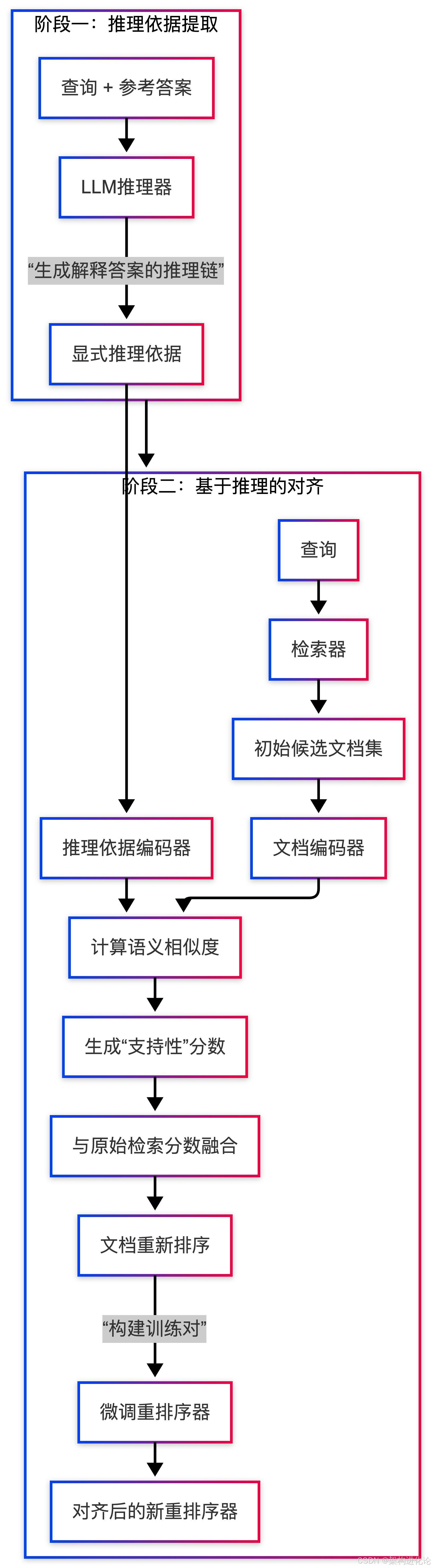
阶段一:推理依据提取
这一阶段的目的是为每个“查询-答案”对,获取一个清晰的、文本形式的推理依据(Rationale)。
- 方法:利用一个能力强大的LLM(如GPT-5),将查询(Question)和其真实答案(Ground Truth Answer)一同作为输入,通过设计特定的提示词(Prompt),要求模型输出推导出该答案所需的推理步骤或关键证据。
- 示例:
- 查询:“珠穆朗玛峰最先是由哪支登山队成功登顶的?”
- 答案:“1953年由埃德蒙·希拉里和丹增·诺尔盖所在的英国登山队。”
- 可能提取的推理依据:“人类首次成功登顶珠穆朗玛峰发生在1953年。这次登顶是由一支英国探险队完成的,队员埃德蒙·希拉里(新西兰人)和夏尔巴人向导丹增·诺尔盖(尼泊尔人)是首批站在顶峰的人。因此,答案是英国登山队。”
这个推理依据不再是简单的答案复述,而是包含了时间、关键人物、国籍归属等支持最终答案形成的逻辑链条。
阶段二:基于推理依据的对齐
这是RADIO框架的创新核心,目的是利用上一步提取的推理依据,重新定义文档的“好坏”标准,并以此微调重排序器。
a. 文档重新评分与排序
- 编码:使用文本编码器(如BERT)分别将候选文档和提取的推理依据转换为稠密向量(Embeddings)。
- 计算支持性分数:计算每个文档向量与推理依据向量之间的语义相似度(如余弦相似度)。这个分数直接反映了该文档对生成正确答案的支持程度,分数越高,说明文档内容与推理依据越吻合。
- 分数融合与重排:将新得到的“支持性分数”与检索器原始的“相关性分数”进行加权融合,得到每个文档的最终得分。依据最终得分对所有文档进行重新排序。在新的排序中,那些不仅相关、更能提供答案证据的文档会被提升到前列。
b. 重排序器微调
- 构建训练样本:从重新排序后的列表中,将排名最高的文档作为正例(Positive Example)。从排名靠后的位置采样若干个文档作为负例(Negative Example)。这样就构建了
(查询, 正例文档,负例文档)的训练三元组。 - 模型优化:使用对比学习(Contrastive Learning)的目标函数(如InfoNCE损失)来微调重排序器。该目标函数的核心是拉近查询与正例文档在表示空间的距离,同时推远查询与负例文档的距离。通过这种方式,重排序器被训练去识别和偏好那些更符合生成器推理需求的文档。
技术实现与代码解析
以下是一个简化的RADIO核心对齐过程的代码示例,使用PyTorch框架,旨在展示其关键步骤的逻辑。
import torch
import torch.nn as nn
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
class RADIOAlignment:
"""
RADIO框架中对齐过程的核心实现类。
包含基于推理依据的文档重排序和重排序器微调的逻辑。
"""
def __init__(self, reranker_model, encoder_name='all-MiniLM-L6-v2'):
"""
初始化对齐模块。
参数:
reranker_model: 待微调的重排序器模型(一个torch.nn.Module)。
encoder_name: 用于编码文档和推理依据的文本编码器名称。
"""
self.reranker = reranker_model
# 加载一个固定的句子编码器,用于计算推理相似度
self.encoder = SentenceTransformer(encoder_name)
# 相似度计算使用余弦相似度
self.cos_sim = nn.CosineSimilarity(dim=-1)
def compute_rationale_similarity(self, documents, rationale):
"""
计算每个文档与推理依据的语义相似度。
参数:
documents: list of str, 候选文档列表。
rationale: str, 提取的推理依据文本。
返回:
torch.Tensor: 每个文档的相似度分数。
"""
# 编码所有文档和推理依据
doc_embeddings = self.encoder.encode(documents, convert_to_tensor=True)
rationale_embedding = self.encoder.encode(rationale, convert_to_tensor=True)
# 计算余弦相似度
# rationale_embedding需要扩展维度以进行批量计算
similarity_scores = self.cos_sim(doc_embeddings, rationale_embedding.unsqueeze(0))
return similarity_scores
def rerank_documents(self, query, documents, rationale, retrieval_scores, alpha=0.7):
"""
根据推理依据和原始检索分数,对文档进行重新排序。
参数:
query: str, 用户查询。
documents: list of str, 候选文档列表。
rationale: str, 推理依据。
retrieval_scores: torch.Tensor, 检索器给出的原始分数。
alpha: float, 融合权重(0-1),alpha * 推理分数 + (1-alpha) * 检索分数。
返回:
tuple: (重新排序后的文档列表, 重新排序后的索引, 最终融合分数)
"""
# 1. 计算推理支持分数
rationale_scores = self.compute_rationale_similarity(documents, rationale)
# 2. 对两种分数进行最小-最大归一化,使其尺度一致
def min_max_normalize(tensor):
return (tensor - tensor.min()) / (tensor.max() - tensor.min() + 1e-8)
rationale_scores_norm = min_max_normalize(rationale_scores)
retrieval_scores_norm = min_max_normalize(retrieval_scores)
# 3. 分数融合
fused_scores = alpha * rationale_scores_norm + (1 - alpha) * retrieval_scores_norm
# 4. 根据融合分数降序排序
sorted_indices = torch.argsort(fused_scores, descending=True)
sorted_docs = [documents[i] for i in sorted_indices]
sorted_scores = fused_scores[sorted_indices]
return sorted_docs, sorted_indices, sorted_scores
def train_step(self, query, pos_doc, neg_docs, temperature=0.05):
"""
执行一次对比学习训练步骤,微调重排序器。
参数:
query: str, 查询文本。
pos_doc: str, 正例文档。
neg_docs: list of str, 负例文档列表。
temperature: float, InfoNCE损失的温度参数。
返回:
torch.Tensor: 损失值。
"""
# 使用重排序器获取查询和文档的表示
# 假设self.reranker能够返回查询和文档的嵌入向量
q_embedding = self.reranker.encode_query(query)
pos_embedding = self.reranker.encode_document(pos_doc)
neg_embeddings = torch.stack([self.reranker.encode_document(neg) for neg in neg_docs])
# 计算正例和负例的分数(点积或余弦相似度)
pos_score = F.cosine_similarity(q_embedding, pos_embedding, dim=-1) / temperature
neg_scores = F.cosine_similarity(q_embedding.unsqueeze(0), neg_embeddings, dim=-1) / temperature
# 构建InfoNCE损失(一种对比损失)
# 分子是正例分数的指数,分母是所有样本(正例+负例)分数指数之和
numerator = torch.exp(pos_score)
denominator = numerator + torch.sum(torch.exp(neg_scores))
loss = -torch.log(numerator / denominator)
return loss
# 使用示例(概念性代码)
if __name__ == "__main__":
# 初始化一个简单的重排序器模型(此处为示意)
class SimpleReranker(nn.Module):
# ... 模型定义 ...
pass
base_reranker = SimpleReranker()
radio = RADIOAlignment(base_reranker)
# 模拟输入
example_query = "珠穆朗玛峰的首登队伍是哪国的?"
example_docs = ["文档A内容...", "文档B内容...", "文档C内容..."] # 假设已检索到的文档
example_rationale = "首次登顶是1953年英国探险队完成的,关键成员是希拉里和丹增。"
example_retrieval_scores = torch.tensor([0.9, 0.7, 0.5]) # 检索器原始打分
# 1. 基于推理依据重排序文档
reranked_docs, indices, scores = radio.rerank_documents(
query=example_query,
documents=example_docs,
rationale=example_rationale,
retrieval_scores=example_retrieval_scores,
alpha=0.6
)
print("重排序后的文档顺序:", reranked_docs)
# 2. 构建训练样本并微调(示意)
positive_doc = reranked_docs[0] # 排名第一的作为正例
negative_docs = reranked_docs[-2:] # 排名最后的两个作为负例
loss = radio.train_step(example_query, positive_doc, negative_docs)
print("对比损失:", loss.item())
# loss.backward() 并执行优化器步骤,以更新base_reranker的参数RADIO与相关技术的比较及演进脉络
在RADIO出现之前,已有多种技术尝试解决RAG中的组件对齐或优化问题,但RADIO通过引入显式的推理信号,实现了范式的创新。
技术方法 | 核心思想 | 优点 | 局限 | 与RADIO的对比 |
|---|---|---|---|---|
传统重排序 | 训练一个模型(如Cross-Encoder)直接判断查询-文档对的相关性。 | 计算精度高,能捕捉细粒度语义。 | 目标仍是“主题相关性”,而非“答案支持性”。 | RADIO改变了优化目标,使其与生成器对齐。 |
响应质量蒸馏 | 用生成器的最终输出答案质量作为信号,来间接优化检索或重排序组件。 | 端到端优化,信号与最终目标一致。 | 信号过于粗糙和滞后,难以精确传递生成器具体需要哪些文档信息。 | RADIO使用中间的推理依据作为更精细、更直接的监督信号。 |
Hypothetical Document Embeddings (HyDE) | 让LLM根据查询生成一个“假设性”答案文档,然后用这个假设文档去检索。 | 缓解了查询与真实文档在表述上的语义鸿沟。 | 假设文档可能是错误或虚构的,以其为标准可能引入噪声。 | RADIO使用基于真实答案推导出的推理依据,准确性更高,逻辑性更强。 |
Self-RAG | 让生成模型在生成过程中,自己决定何时检索、如何利用检索结果并进行自我评判。 | 检索与生成深度融合,高度自适应。 | 需要复杂的训练,且模型内部决策过程不透明,难以单独优化检索组件。 | RADIO保持模块化,通过蒸馏实现组件间透明、可解释的对齐,便于单独优化和部署。 |
从技术演进角度看,RADIO代表了RAG系统从“基于相关性的检索”向“基于推理的检索”的深刻转变。它不再仅仅追问“文档是否与问题有关”,而是追问“文档是否能支撑起推导出正确答案的逻辑”。这与业界关于“检索器需要具备推理能力”的前沿观点不谋而合。
应用展望与总结
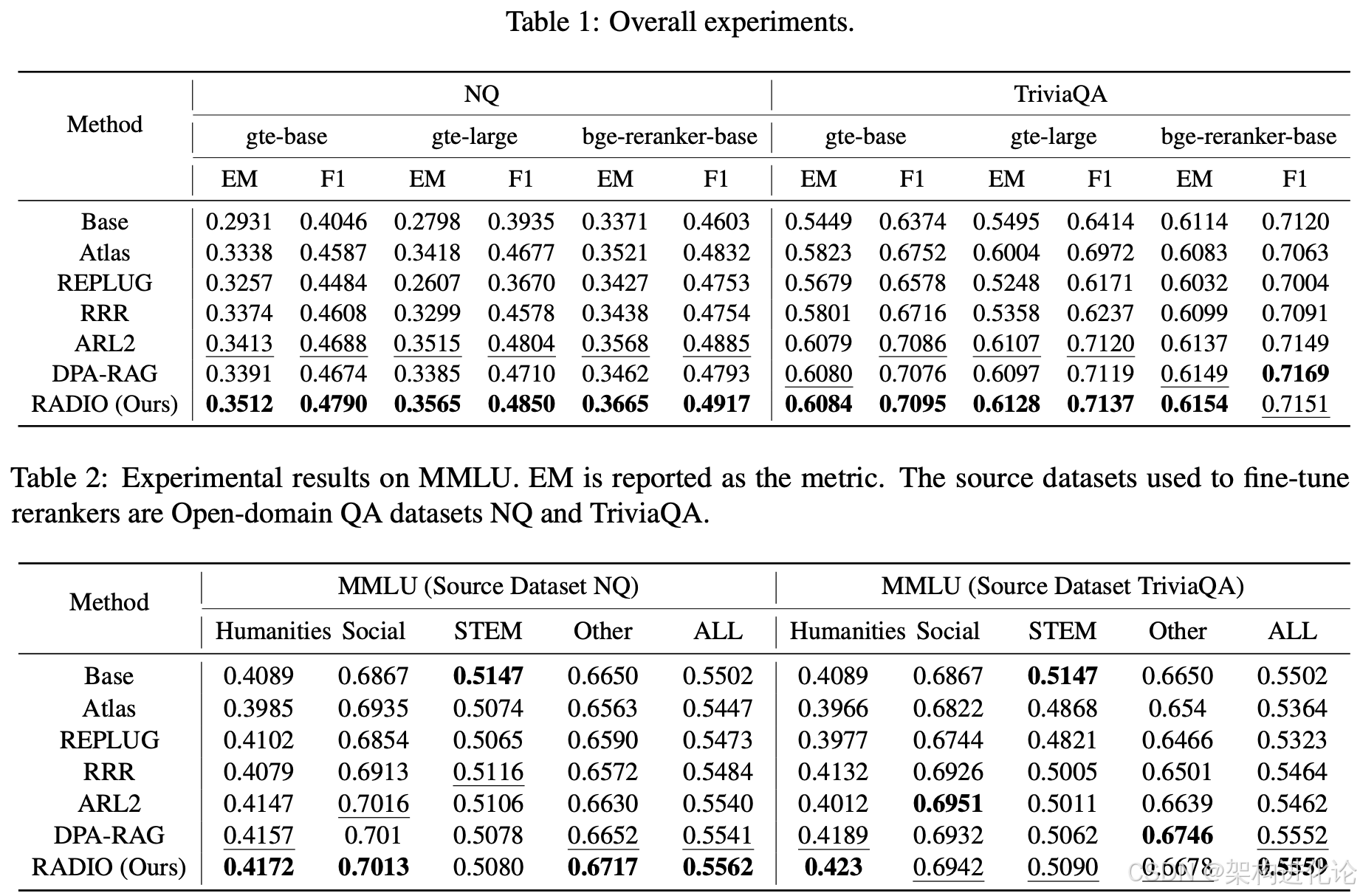
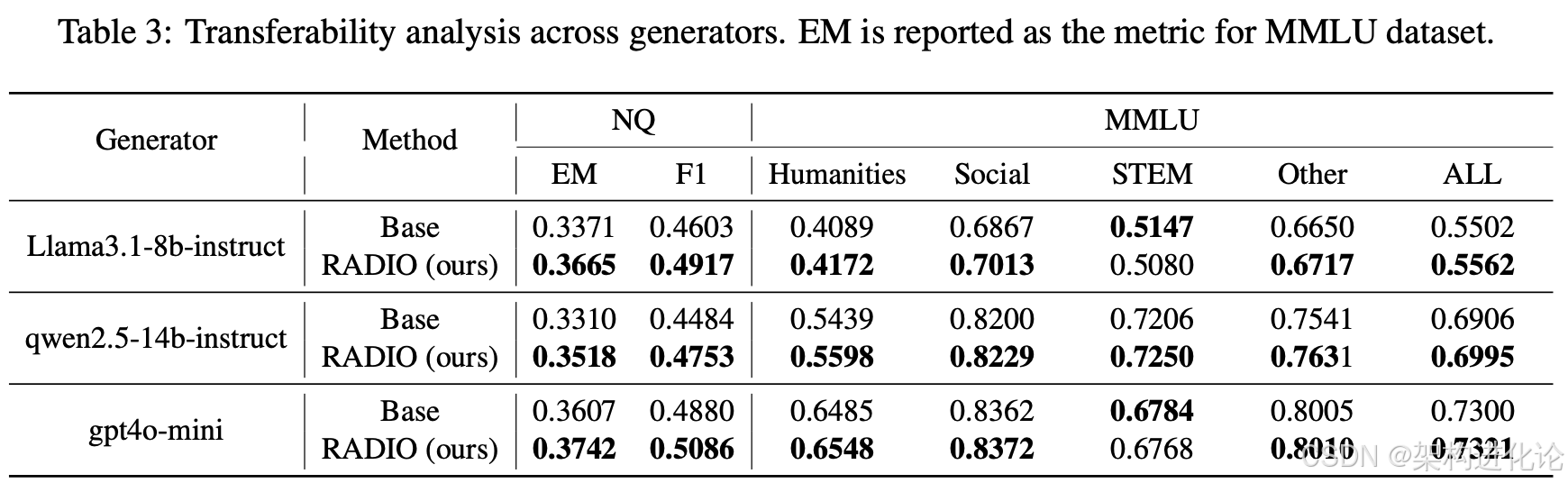
实验表明,RADIO在开放域问答(如NQ、TriviaQA)、多选题(MMLU)以及多跳推理(Musique)等任务上,相比基线方法取得了显著的性能提升。更重要的是,经过RADIO微调后的重排序器,在迁移到不同生成器时仍能保持性能增益,展现了良好的可迁移性和鲁棒性。

未来展望:
- 多模态扩展:当前RADIO主要处理文本。未来可探索将其扩展到多模态RAG中,例如,从图像描述或视频摘要中提取“视觉推理依据”,来对齐多模态检索器。
- 动态与迭代检索:可以将推理依据的生成与检索过程结合,形成动态、多轮的检索-推理循环,让系统在复杂问题上能像人类一样“刨根问底”。
- 与Agentic RAG融合:RADIO可以作为高级Agentic RAG系统(如LlamaIndex提出的智能体检索架构)中的一个核心组件,为负责路由和决策的智能体提供更精准的、基于推理的文档评估能力。(扩展阅读:大模型开发框架深度对比:Spring AI、LangChain、LangGraph与LlamaIndex的技术选型指南)
总结: RADIO框架通过理性蒸馏这一巧妙的思路,将生成器的隐含推理能力显式化,并以此作为桥梁,弥合了RAG管道中检索与生成组件之间的目标鸿沟。它不仅是解决偏好对齐问题的一个有效方案,更是指引RAG技术向更精准、可解释、以推理为中心方向发展的一个重要里程碑。在长上下文窗口技术不断发展、智能体范式兴起的今天,RADIO所代表的“精准增强”理念,确保了RAG技术不会过时,而是向着更精深、更智能的方向持续演进。(扩展阅读:可解释AI(XAI):构建透明可信人工智能的架构设计与实践)
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号