RAG模式到底有8种?还是9种?还是25种?

RAG模式到底有8种?还是9种?还是25种?

jeffery_jcm
发布于 2026-06-26 11:08:54
发布于 2026-06-26 11:08:54
且听我慢慢道来
首先一句话通俗解释什么是RAG? 全称: Retrieval-Augmented Generation (检索增强生成) :RAG是一种结合信息检索与大语言模型生成的架构。
检索增强生成 (RAG) 是一种变革性的生成式人工智能架构,它将大型语言模型 (LLM) 与外部知识检索相结合,以生成更准确、更贴近实际且更具上下文相关性的响应。随着企业不断推进将生成式人工智能嵌入业务流程,RAG 提供了一种无需持续重新训练大型模型即可应对重大风险(包括信息错乱、知识陈旧和领域特定性)的方法。
RAG系统的组成部分:
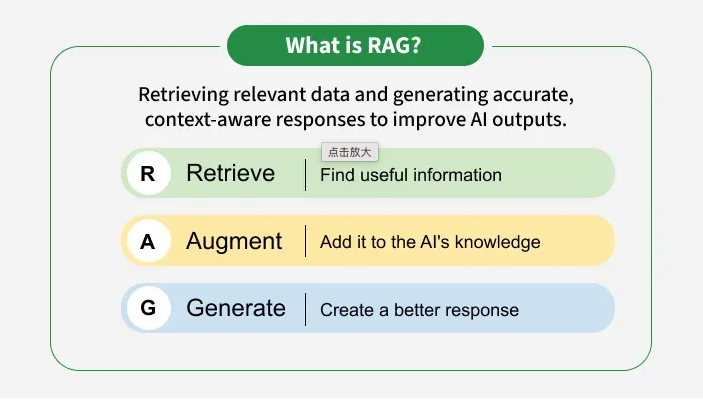
检索增强生成(RAG)
从宏观层面来看,RAG系统由三个模块组成:
查询编码器:对输入进行编码x转换为查询表示q用于检索相关文档。这可以是神经编码器,也可以是基于规则的模板。
检索器:给定查询q检索器获取文档的排名列表。d1,d2,…,dk来自语料库𝒞.寻回犬可能数量稀少(例如,BM25 (Robertson 等人,2009) ),密集(例如,DPR (Karpukhin 等人,2020) )、混合型或生成型。
生成器:生成器对输入的条件x以及检索到的文件d我产生最终输出是这通常是一个预训练的Transformer模型(例如,T5 (Raffel等人,2020),BART ( Lewis等人,2020a),GPT (Brown等人,2020)
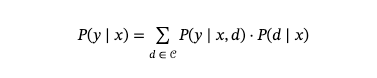
检索增强生成(RAG)中的生成过程可以表示为对条件分布进行建模
x表示输入内容 (例如:问题或提示)
d表示从语料库检索到的文档 𝒞
y表示生成的响应内容
检索增强生成(RAG)框架通过文档检索,利用外部知识访问来增强大型语言模型(LLM)。
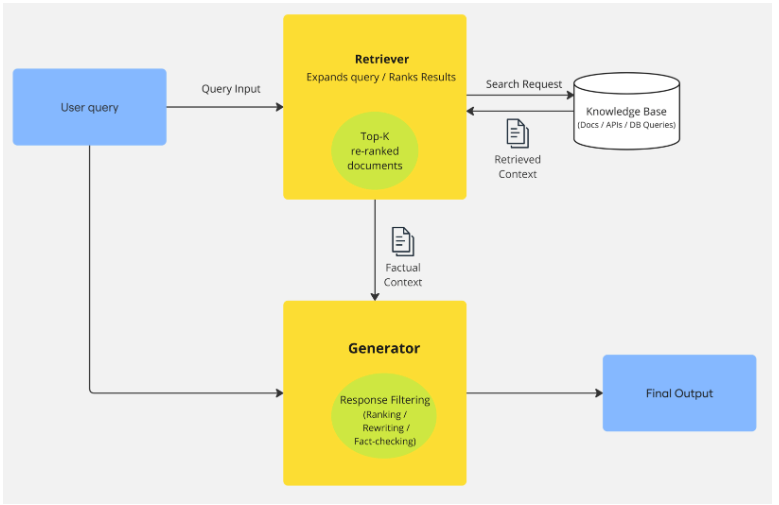
检索增强生成 (RAG) 工作流程
RAG架构分类:根据现有系统的架构侧重点对其进行分类——检索中心型、生成器中心型、混合型和鲁棒性导向型设计
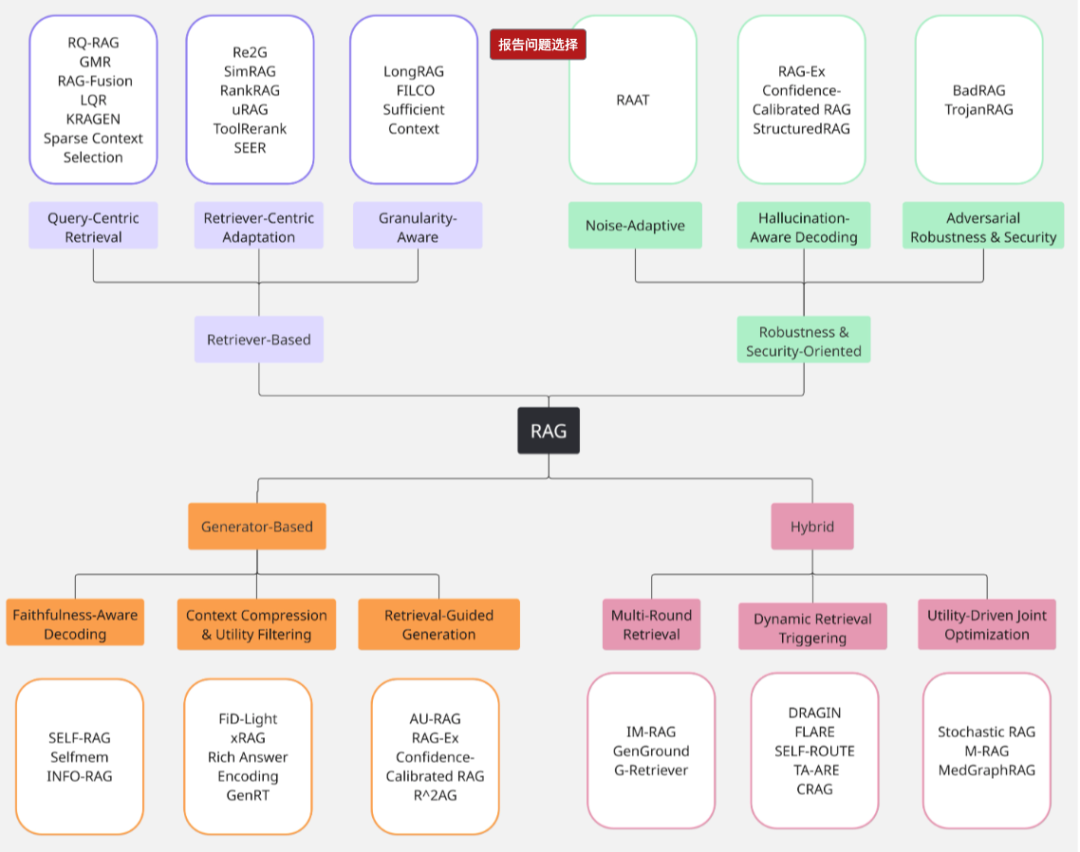
当你在豆某包或者千某问上搜索,到2026年为止,RAG按照复杂与演进大致分为4类 :
1.Naive RAG(基础 / 朴素 RAG)
2.Advanced RAG(高级 RAG)
3.Graph RAG(图谱 RAG)
4.Agentic RAG(智能体 RAG)
也有说RAG可分类为:
1.Naive RAG (基础/朴素RAG)
2.Advanced RAG (高级RAG)
3.Modular RAG (模块化RAG)
btw:但是这种说法不一定准确哈
按照技术实现方式分为8种:
1.Naive RAG(基础)
2.HyDE(假设文档嵌入)
3.Corrective RAG(纠正式)
4.Self-RAG(自反思)
5.Graph RAG(图谱)
6.Hybrid RAG(混合:向量 + 关键词 + 图谱
7.Adaptive RAG(自适应:按查询复杂度动态选策略)
8.Agentic RAG(智能体)
更有甚者说是25种RAG架构:
1.Corrective RAG 纠错型RAG
2.Speculative RAG
3.Agenetic RAG
4.Self-RAG
5.Adaptive RAG
6.Refeed Retrieval Feedback RAG
7.Realm (Retrieval-Augmented Language Model) RAG
8.Raptor (Tree-Organized Retrieval) RAG
9.Replug (Retrieval Plugin) RAG
10.Memo RAG
11.Attention-Based RAG
12.RETRO (Retrieval-Enhanced Transformer) RAG
13.Auto RAG
14.Cost-Constrained RAG
15.ECO RAG
16.Rule-Based RAG
17.Conversational RAG
18.Iterative RAG
19.HybridAI RAG
20.Generative AI RAG
21.XAI (Explainable AI) RAG
22.Context Cache in LLM RAG
23.Grokking RAG: The Intuitive Learner
24.Replug Retrieval Feedback
25.Attention Unet RAG
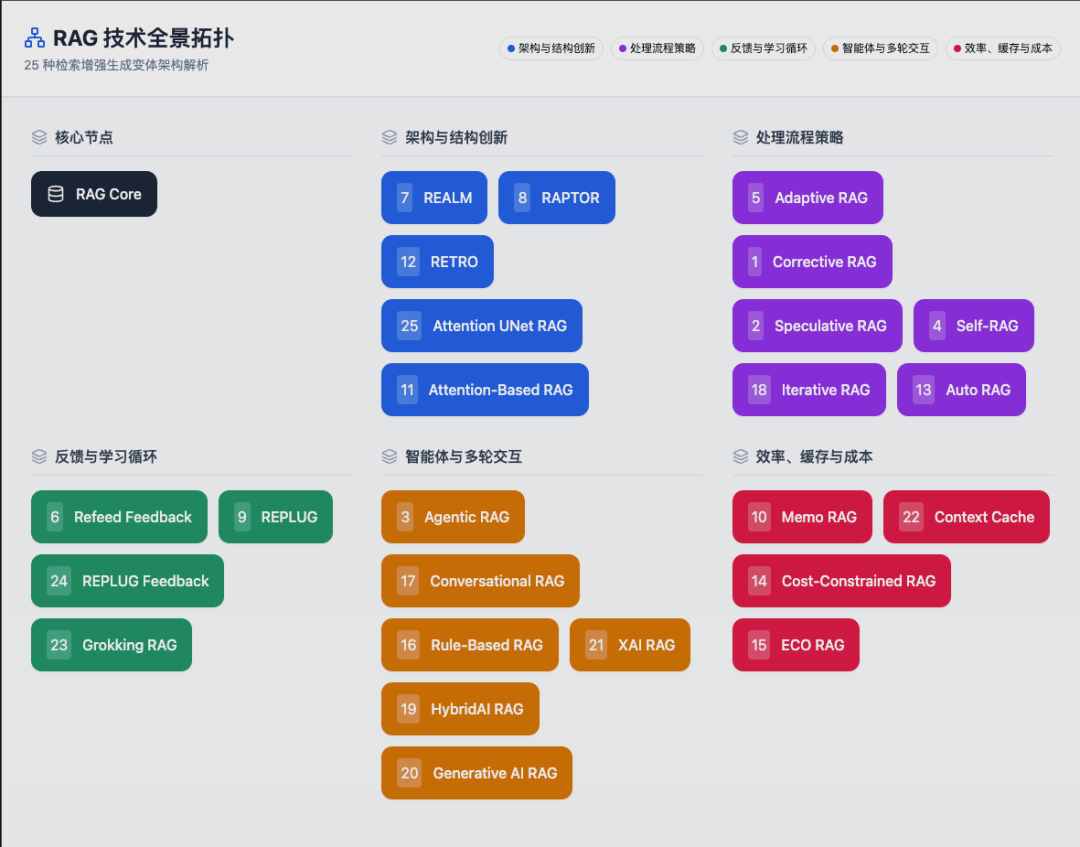
RAG 技术分层架构全景
后续会针对这25种RAG架构模式做详细介绍
本篇基于什么是RAG?RAG设计模式展开介绍
下面详细介绍基于《Retrieval-Augmented Generation for Large Language Models: A Survey》这篇论文提到的三种RAG模式的实现方式:
A:Naive RAG 朴素RAG
步骤:加载->分块->嵌入->检索->生成
重点:简单相似度搜索 ,不进行优化
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
# 1. 加载并分割数据
text_splitter = CharacterTextSplitter(chunk_size= 500 , chunk_overlap= 100 )
texts = text_splitter.split_text( "文档内容在此处 " )
# 2. 创建嵌入并存储到向量数据库中
embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
# 3. 检索文档
retriever = db.as_retriever()
# 4. 使用 LLM 生成响应
llm = ChatOpenAI(model= "gpt-4o" )
query = "什么是 LangChain?"
docs = retriever.get_relevant_documents(query)
context = "\n\n" .join([doc.page_content for doc in docs])
response = llm.invoke( f"Context: {context} \nQuestion: {query} " )
print (response)示例输出:
输入查询: 什么是langchain?
回复:“LangChain 是一个框架,用于构建将语言模型与向量数据库等工具相结合的应用程序,以实现检索增强生成 (RAG)。它简化了将数据集成到语言学习模型 (LLM) 工作流程中的过程。
朴素RAG的局限性:
阶段 | 挑战 |
|---|---|
检索阶段 | - 可能召回不相关的文本片段。- 受限于相似度计算,可能遗漏关键细节。 |
生成阶段 | - 存在幻觉风险(编造事实)。- 可能生成不一致或冗余的回答。 |
增强阶段 | - 难以将信息进行连贯整合。- 输出内容可能缺乏风格一致性。 |
B. Advanced RAG 高级RAG
步骤:预处理->多查询->检索->后处理->生成
重点:增加查询优化、重新排名和上下文压缩
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Qdrant
from langchain.embeddings import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.rerankers import Reranker
# 1. 预检索优化 🛠️
text_splitter = CharacterTextSplitter(chunk_size= 500 , chunk_overlap= 100 )
texts = text_splitter.split_text( "高级文档内容." )
embeddings = OpenAIEmbeddings()
db = Qdrant.from_texts(texts, embeddings) # 使用 Qdrant 实现灵活检索
# 2. 查询优化 🔍
query_variations = [
"解释 LangChain 概念." ,
"LangChain 的用例是什么?" ] “
LangChain 如何简化工作流程?”
#
3. 检索和重排序 ✂️
retriever = db.as_retriever()
all_docs = []
for query in query_variations: # 多查询方法
docs = retriever.get_relevant_documents(query)
all_docs.extend(docs)
# 重排序结果
reranker = Reranker()
ranking_docs = reranker.rank(all_docs, query)
# 4. 上下文压缩 🔧
context = "\n\n" .join([doc.page_content for doc in ranking_docs[: 3 ]]) # 选择前 3 个文档
# 5. 使用优化后的输入生成响应
llm = ChatOpenAI(model= "gpt-4o" )
prompt = PromptTemplate.from_template( "基于上下文的答案:\n{context}\n问题:{query}" )
response = llm.invoke(prompt.format ( context=context, query= "什么是 LangChain?" ))
print (response)优化索引:
技术手段 | 核心用途 |
|---|---|
分块策略 🧩 | 将数据拆分为可管理的片段,以实现高效处理。 |
数据清洗 🧹 | 去除噪声干扰,确保用于索引的文本片段具备高质量。 |
多表示索引 🗂️ | 存储多种视角的数据(文本、语义向量),以更好地捕捉上下文信息。 |
自查询检索 🤖 | 在检索前内部生成优化查询,以提升结果的相关性。 |
父文档检索 📖 | 检索完整文档而非孤立片段,以实现更优的上下文整合。 |
检索前优化与检索后优化的权衡取舍:
流程 | 优势 | 劣势 |
|---|---|---|
检索前 (Pre-Retrieval) | ✅ 搜索速度更快。✅ 结果更聚焦,减少噪声干扰。✅ 实现更简单。 | ❌ 预处理成本高。❌ 灵活性受限。❌ 存在过滤掉有用数据的风险。 |
检索后 (Post-Retrieval) | ✅ 可灵活优化结果。✅ 支持纠错处理。✅ 能适配查询意图。 | ❌ 需要更多计算资源。❌ 依赖初始检索的质量。❌ 配置更复杂。 |
C. Modular RAG 模块化RAG
步骤:模块化设置->路由->动态查询->上下文融合->生成
重点:支持特定任务模块、路由和内存集成
优点:1.即插即用的咯灵活性2.动态查询处理3.任务特定精确度4.可扩展且面向未来
from langchain_community.document_loaders import WebBaseLoader
from langchain.vectorstores import Pinecone
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.retrievers.multi_query import MultiQueryRetriever
# 1. 模块化数据加载 🔄
loader = WebBaseLoader( "https://example.com/article" )
data = loader.load()
# 2. 灵活索引 📦
text_splitter = CharacterTextSplitter(chunk_size= 500 , chunk_overlap= 100 )
texts = text_splitter.split_documents(data)
embeddings = OpenAIEmbeddings()
vector_store = Pinecone.from_documents(texts, embeddings)
# 3. 高级查询路由 🌐
multi_retriever = MultiQueryRetriever.from_llm(
retriever=vector_store.as_retriever(), llm=ChatOpenAI(model= "gpt-4o" )
)
# 4. 特定任务提示 🎯
custom_prompt = PromptTemplate(template= """回答以下问题:
{context}
问题:{question}""" )
# 5. 内存模块 🧠
memory = ConversationBufferMemory(return_messages= True )
# 6. 动态问答链 ⚡
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model= "gpt-4o" ),
retriever=multi_retriever,
memory=memory,
chain_type_kwargs={ "prompt" : custom_prompt}
)
# 7. 执行灵活管道
响应 = qa_chain.run( "LangChain 的主要特性是什么?" )
print (response)模块化RAG的优势:
特性 | 优势 |
|---|---|
可适应性 🔄 | 可针对不同任务替换或重新配置模块,确保可扩展性与复用性。 |
精准检索 🎯 | 采用多查询扩展与自查询机制,提升检索准确率。 |
任务专属优化 🛠️ | 使流水线适配问答、摘要或知识图谱等专业化工作流。 |
动态查询路由 🚦 | 自动将查询路由至最相关的数据源与检索方法。 |
记忆集成 🧠 | 追踪多轮查询间的上下文历史,支持迭代优化与多步骤工作流。 |
以下是 Modular RAG 在幕后所做的工作:
- 路由模块🚦 → 决定此查询是否需要网络搜索、内部文档或API 数据。
- 多查询扩展 🔗 → 生成3-5 个问题变体,以涵盖不同的角度。
- 并行检索 🔍 →同时在多个数据源(向量存储、API 等)中运行搜索。
- 重新排名📊 → 选择排名靠前的数据块,并删除重复或无意义的结果。
- 内存 🧠 → 检查过去的查询以获取上下文 — 此查询是否建立在先前的问题之上?
- LLM 答案 🎯 → 整合最佳信息并撰写最终回复——清晰、简洁、切中要点。
步骤一:导入所需库
from langchain.vectorstores import Qdrant # 用于嵌入的向量存储
from langchain.embeddings import OpenAIEmbeddings # 嵌入模型
from langchain.text_splitter import RecursiveCharacterTextSplitter # 将文档分割成块
from langchain.chains import RetrievalQA # 检索增强生成 (RAG)
from langchain.prompts import ChatPromptTemplate # 提示模板
from langchain.chat_models import ChatOpenAI # 基于 GPT 的 LLM步骤二:设置模块化组件
# 加载并准备数据
text = "您的文档内容..." # 替换为您的输入数据
splitter = RecursiveCharacterTextSplitter(chunk_size= 500 , chunk_overlap= 100 )
chunks = splitter.create_documents([text])
# 嵌入和向量存储
embeddings = OpenAIEmbeddings()
vector_db = Qdrant.from_documents(chunks, embeddings, collection_name= "modular_rag_demo" )
# 检索器配置步骤三:多查询模块
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# 多查询提示
query_template = """
生成给定查询的三个变体:
查询:{question}
变体:
1. ...
2. ...
3. ...
"""
prompt = PromptTemplate(input_variables=[ "question" ], template=query_template)
# 生成多查询扩展
llm = ChatOpenAI(model= "gpt-4o" )
query_chain = LLMChain(prompt=prompt, llm=llm)
query_variations = query_chain.run({ "question" : "总结2023年的气候政策" })步骤四:检索和排序数据
# 检索每个变体的文档
retrieved_docs = [ ]
for query in query_variations.split ( "\n" ) :
retrieved_docs.extend ( retriever.get_relevant_documents ( query ) )
# 重新排序并压缩上下文
context = "\n\n" .join ( doc.page_content [ : 200 ] for doc in retrieved_docs ) # 压缩到 200 个字符步骤五:使用 LLM 生成输出
# 创建提示模板
template = """
上下文:
{context}
问题:
{question}
答案:
"""
chat_prompt = ChatPromptTemplate.from_template(template)
# 生成回复
response = llm.invoke(chat_prompt.format ( context =context, question= "总结2023年的气候政策" ))
print (response)输出示例📝
输入查询: “总结2026年的气候政策。”
输出答案: “2026年的气候政策重点在于推广可再生能源、制定更严格的碳排放法规以及达成国际气候协议,以将全球变暖幅度控制在1.5摄氏度以内。感谢您的提问!
refer: https://arxiv.org/html/2506.00054v1#S2
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号