Loop Engineering:Agent 时代,别再手动写 Prompt

Loop Engineering:Agent 时代,别再手动写 Prompt

山行AI
发布于 2026-06-26 19:14:08
发布于 2026-06-26 19:14:08
前言
当 AI coding agent 已经能写代码、跑测试、读 issue、开 PR,真正的瓶颈就不再是“怎么写一个更聪明的 prompt”。更大的问题变成:谁来持续触发它?谁来给它上下文?谁来限制风险?谁来验证结果?谁来决定什么时候交给人?
这就是 Loop Engineering 要回答的问题:开发者的杠杆点正在从 prompt 本身,转向设计一个能持续提示、调度、验证和交接的循环系统。
loop-engineering[1] 是 Cobus Greyling 开源的参考仓库。它不是单纯的文章合集,而是把 loop engineering 拆成可复用模式、starter、skill、CLI 工具、检查清单和安全文档,面向 Grok、Claude Code、Codex、Cursor 等 AI coding agents。
仓库一句话很有代表性:Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead.
换成中文就是:不要每次亲自提示 Agent,而是设计一个系统,让系统持续提示、检查和推进 Agent。
Loop Engineering 社交横幅
这个项目解决什么问题
很多团队刚开始使用 coding agent 时,模式是人工发 prompt:
•“帮我看一下 issue。”
•“修一下这个测试。”
•“检查一下 PR。”
•“整理 changelog。”
这当然有用,但问题也明显:每次都要人来启动、提供上下文、判断风险、监督结果。随着任务变多,开发者会重新变成“Agent 调度员”。
Loop Engineering 的核心观点是:真正的自动化不在于让 Agent 偶尔帮忙,而在于把 Agent 放进可重复、可审计、有边界的循环里。
一个 loop 是一个递归目标:定义目的、状态、节奏、工具、验证方式和交接条件,然后让 AI 持续迭代,直到目标完成,或者 loop 判断需要移交给人。
README 原始附图:五个构件 + Memory
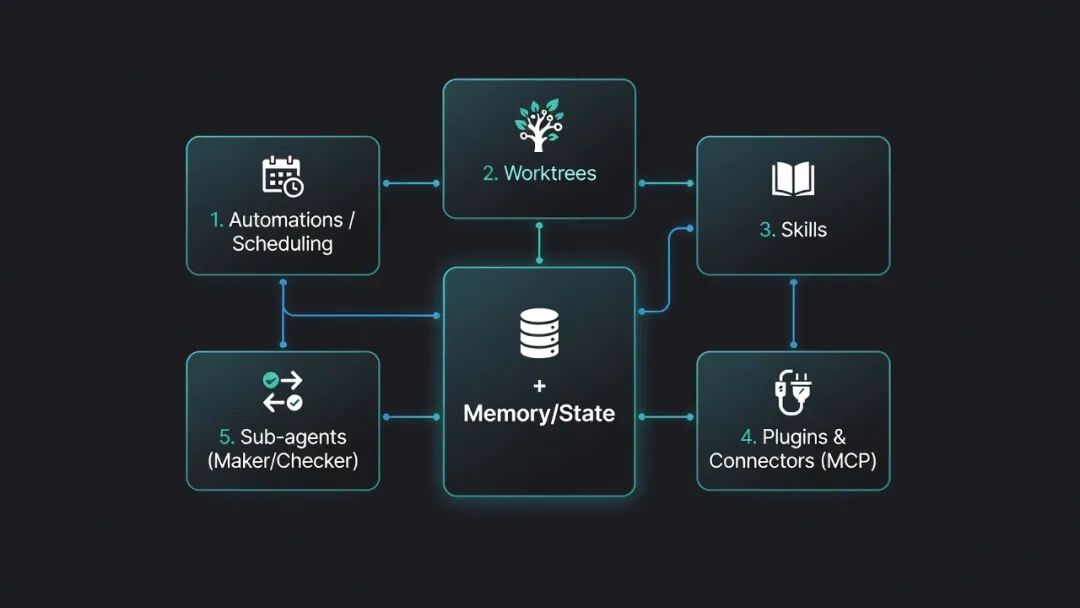
Five Building Blocks + Memory
README 把 Loop Engineering 拆成 五个构件 + Memory。
1Automations / Scheduling:负责按节奏触发发现、分诊、巡检等任务。
2Worktrees:为并行执行提供隔离环境,避免多个 Agent 或循环互相踩工作区。
3Skills:沉淀项目知识、流程规范和可复用操作经验。
4Plugins & Connectors:通过 MCP 等方式连接真实工具,例如 Git、工单、CI、文档系统。
5Sub-agents:拆分 maker/checker,避免同一个 Agent 自写自验。
6Memory / State:把循环的长期状态放在会话之外,例如 STATE.md、run log、budget 文件。
这个拆分的价值在于,它把“Agent 使用经验”变成了工程构件,而不是停留在提示词技巧层面。
功能架构图
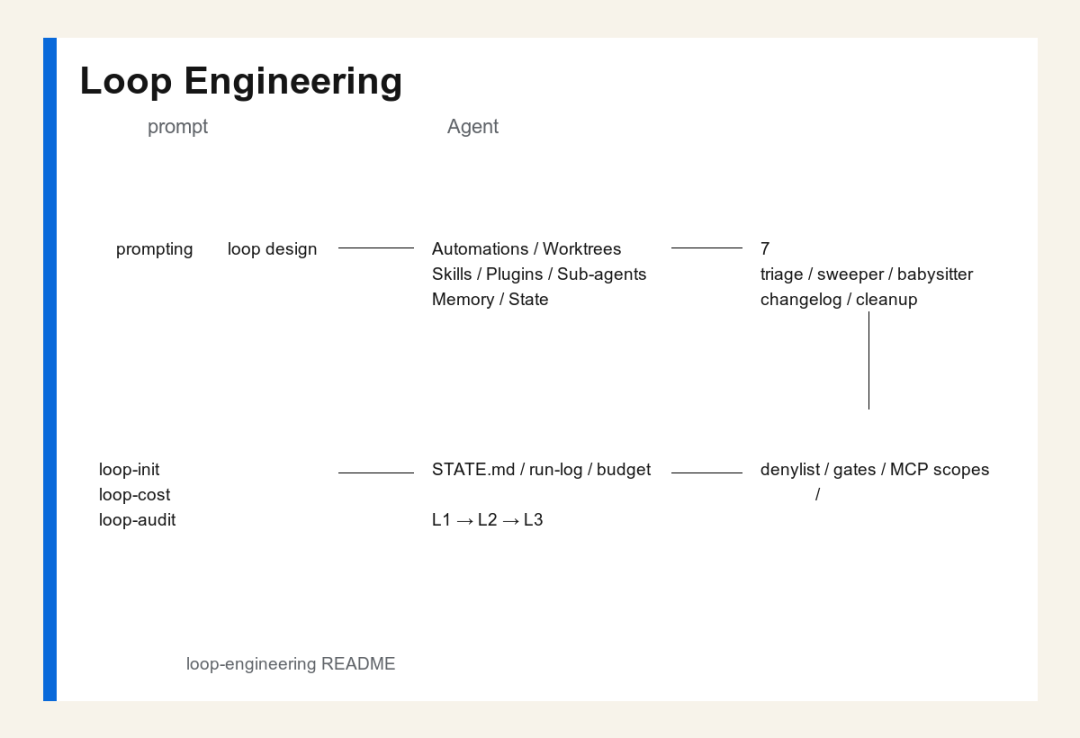
Loop Engineering 功能架构图
从仓库结构看,loop-engineering 包含六层内容。
第一层:理念层
它定义了 loop engineering 的核心观念:从一次性 prompt 转向系统化 loop design。开发者要设计目标、节奏、状态、验证和人工交接,而不是反复手动喊 Agent 干活。
第二层:构件层
README 的五个 building blocks 加 memory,是整个方法论的基础。它告诉用户,一个稳定循环至少需要调度、隔离、知识、连接器、子代理和持久状态。
第三层:模式层
仓库内置 7 个生产模式,覆盖日常分诊、PR 看护、CI 清扫、依赖清扫、changelog 草稿、合并后清理、issue 分诊。
第四层:工具层
项目提供 3 个主要 npm CLI:
•loop-init:脚手架工具,用于按 pattern 和目标工具生成 starter。
•loop-cost:token 成本估算器,用于判断循环频率和模式会不会烧穿预算。
•loop-audit:Loop Readiness Score CLI,用于审计项目是否具备上线 loop 的条件。
第五层:运行层
通过 STATE.md、loop-run-log.md、loop-budget.md 等文件,把循环的状态、日志和预算显式化。
第六层:安全层
通过 denylist、人工 gate、MCP scope、report-only 阶段、分级上线策略,降低无人值守 loop 带来的误操作风险。
Loop 执行流程图
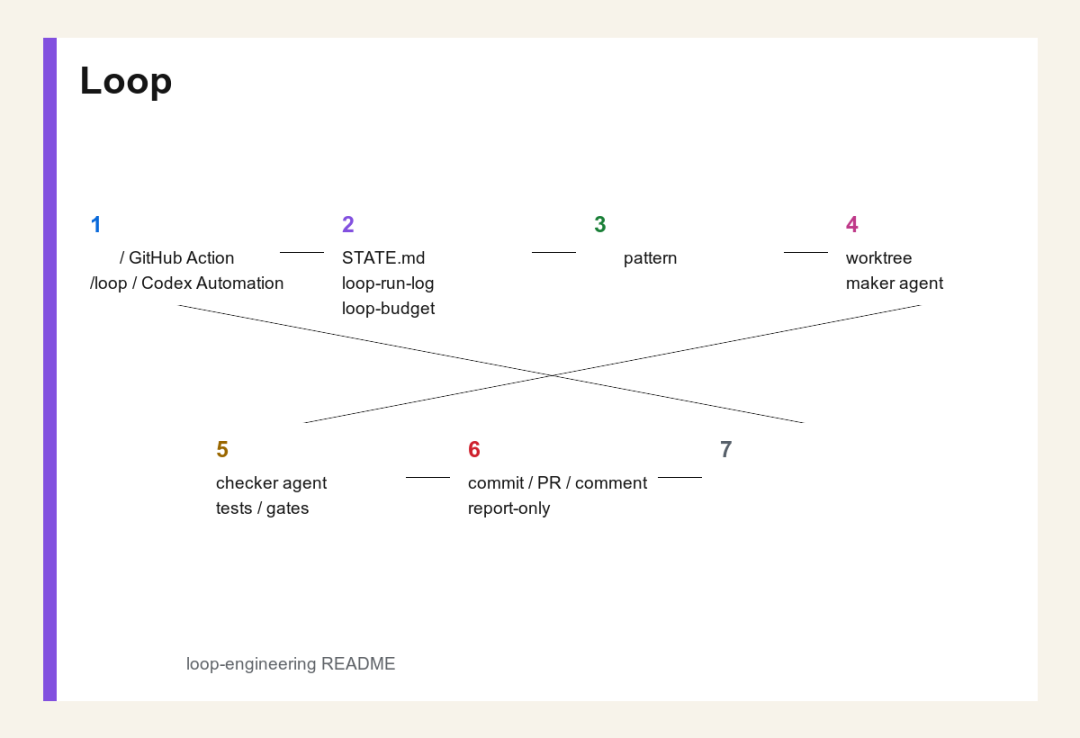
Loop Engineering 流程图
一个典型 loop 可以这样运行:
1调度器触发任务,例如每天一次、每 15 分钟一次,或通过 GitHub Actions / Codex Automation / Grok /loop 触发。
2读取 STATE.md、run log、budget 等外部状态。
3根据 pattern 做分诊,判断任务类型、风险等级和应该进入的执行模式。
4在隔离 worktree 中执行,通常由 maker agent 完成改动。
5由 verifier/checker agent 或 CI gate 做验证。
6如果安全且在允许范围内,可以提交 PR、评论、生成报告或执行动作。
7如果高风险、歧义大、证据不足,就带着完整上下文交接给人。
8结果回写状态,等待下一轮调度。
这套流程的重点不是“Agent 一直自动跑”,而是什么时候可以自动,什么时候必须停下来交给人。
七个生产模式
仓库 patterns/README.md 列出了 7 个可复用 loop pattern。
•Daily Triage:每天或每 2 小时运行,适合低风险的日常分诊,第一周建议 L1 report-only。
•PR Babysitter:每 5 到 15 分钟运行,持续看护 PR 状态,成本高、风险中等。
•CI Sweeper:每 5 到 15 分钟运行,处理 CI 失败,token 成本非常高,适合谨慎进入 L2。
•Dependency Sweeper:每 6 小时到每天运行,做依赖升级或修补,风险中等。
•Changelog Drafter:每天或 tag 触发,自动生成 changelog 草稿,风险低。
•Post-Merge Cleanup:每天或每 6 小时运行,做合并后清理,适合非高峰时段 report-only。
•Issue Triage:每 2 小时到每天运行,对 issue 做分诊、标注、建议处理路径,风险低。
这些 pattern 的共同点是:每个都说明它解决什么问题、推荐调度节奏、需要什么 skill/state、如何验证、何时移交给人,以及在 Grok、Claude Code、Codex、GitHub Actions 下怎么落地。
5 分钟上手路径
README 给出的快速开始很直接。
class="language-bash">"color:#6a9955"># 1. 生成 starter
npx "color:#6a9955">#c586c0">@cobusgreyling/loop-init . --pattern daily-triage --tool grok
"color:#6a9955"># 2. 估算 token 成本
npx "color:#6a9955">#c586c0">@cobusgreyling/loop-cost --pattern daily-triage --level L1
"color:#6a9955"># 3. 审计 loop 准备度
npx "color:#6a9955">#c586c0">@cobusgreyling/loop-audit . --suggest
"color:#6a9955"># 4. 查看从空状态到 L1 / L2 的分数变化
bash scripts/before-after-demo.sh
"color:#6a9955"># 5. 以 report-only 方式启动
/loop 1d Run loop-triage. Update STATE.md. No auto-fix in week one.
这条路径很务实:先 scaffold,再估成本,再审计准备度,最后从 report-only 开始,而不是一上来无人值守自动修改代码。
三个 CLI 工具分别做什么
loop-init:生成循环脚手架
它根据 pattern 和目标工具生成 starter,自动带上需要的 state、budget、run-log、skill 等文件。适合快速把 daily-triage、issue-triage、ci-sweeper 这类模式落到真实项目里。
loop-cost:估算运行成本
loop 的成本不是一次对话成本,而是“频率 × 子代理 × 上下文长度 × 验证轮数”的复合成本。loop-cost 用来提前估算不同 pattern、level、cadence 下的 token 花费。
loop-audit:检查项目是否适合跑 loop
它会给出 Loop Readiness Score,并可通过 --suggest 提示缺哪些东西,例如预算文件、run log、状态文件、验证策略或安全边界。
分级上线策略:L1 到 L3
README 推荐的 rollout 是:L1 report → L2 assisted fixes → L3 unattended。
•L1 report-only:只观察、分诊、生成报告,不自动修改。适合第一周。
•L2 assisted fixes:允许小范围辅助修复,但仍需要人审核或 gate。
•L3 unattended:允许无人值守执行,但前提是边界清晰、验证可靠、成本可控、回滚可行。
这套分级非常重要。Loop Engineering 的本质不是“更大胆地自动化”,而是“更可控地自动化”。
适合哪些团队
这个项目特别适合以下场景:
•已经在使用 Claude Code、Codex、Grok、Cursor 等 coding agent,但还停留在人工 prompt 阶段。
•有大量重复性工程维护任务,例如 issue 分诊、PR 看护、CI 修复、依赖更新、changelog 草稿。
•希望把 Agent 工作流接入 GitHub Actions、MCP、项目状态文件和安全检查。
•想建立团队级 Agent 运行规范,而不是每个人各自摸索提示词。
•希望用 report-only 方式先观察,再逐步放权。
风险与边界
README 对风险讲得很直接:Loop engineering 会放大判断力,无论是好判断还是坏判断。
主要风险包括:
•Token 成本爆炸:高频 loop、长上下文、子代理和验证轮次都会叠加成本。
•无人值守错误:如果验证不可靠,loop 会自动放大错误。
•Comprehension debt:如果人不读 loop 产出的变更,理解债会累积得更快。
•多人冲突:两个人跑同一个 loop,可能得到相反结果;loop 不知道,工程师必须知道。
因此,真正落地时需要至少准备:denylist、人工 gate、日志、预算、验证命令、回滚策略、MCP scope 和明确的 handoff 条件。
工程原则观察
•KISS:用 STATE.md、run-log、budget 等普通文件承载状态,简单透明,容易审计。
•YAGNI:建议从 L1 report-only 开始,不提前追求全自动无人值守。
•SOLID:pattern、starter、skill、tool、docs 分层明确,职责边界清晰。
•DRY:7 个 pattern 和 starter 把重复 loop 设计抽象成模板,避免每个项目从零写。
•潜在违背点:如果团队一开始就把多个 loop、多个工具、多个 sub-agent 同时上线,会引入过度复杂度。更稳妥的路径是先选一个低风险 pattern,比如 Daily Triage 或 Changelog Drafter,跑一周 report-only 后再升级。
一句话总结
Loop Engineering 的重点不是让 Agent 更像人,而是让 Agent 工作流更像工程系统:有状态、有节奏、有边界、有验证、有交接。
提示词是一次性的,loop 是可运营的。真正的分水岭不是“会不会用 Agent”,而是“能不能把 Agent 变成一套可靠的工程循环”。
声明:本文由山行整理自:loop-engineering GitHub 仓库[2],如果对您有帮助,请帮忙点赞、关注、收藏,谢谢~
参考链接
[1] loop-engineering: https://github.com/cobusgreyling/loop-engineering
[2] loop-engineering GitHub 仓库: https://github.com/cobusgreyling/loop-engineering
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号