大模型终于能读千页文档了!DeepSeek-OCR 用 1 招压缩 10 倍,准确率还能 97%

大模型终于能读千页文档了!DeepSeek-OCR 用 1 招压缩 10 倍,准确率还能 97%

HELLO程序员
发布于 2026-06-26 20:50:56
发布于 2026-06-26 20:50:56
“给大模型喂一份 1000 页的财报,它要么‘内存爆炸’,要么切片段后逻辑全乱 —— 这难题终于被破解了!” 近期 DeepSeek 发布的 DeepSeek-OCR,名字里带 “OCR” 却不止是文字识别工具,它靠 “文本转图像再压缩” 的反常规思路,把大模型处理长文档的 tokens 消耗砍到原来的 1/10,还能保持 97% 的准确率。Twitter 网友直呼:“这不仅解决了文字识别,连 AI 训练瓶颈、智能体记忆难题都顺带破了!”
01
反常识操作:把文字当图片存,10 倍压缩还不丢精度
谁能想到,解决大模型 “记不住长文档” 的关键,是把文本 “变个形态”?DeepSeek-OCR 的核心逻辑,就像给文档装了一套 “智能压缩包”,靠两个部件默契配合实现突破:
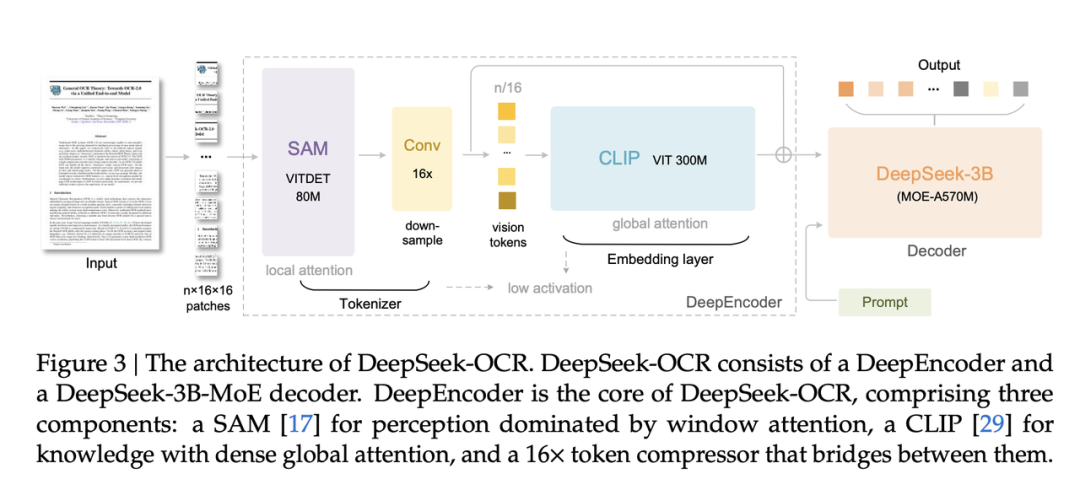
1. DeepEncoder:把千页文档压成 “摘要卡片”
这个视觉压缩模块堪称 “文档瘦身大师”,分三步完成高效压缩:先靠 SAM-base 模型 “扫描” 文档细节,连表格里的小数点、公式里的符号都不放过;再用 16 倍卷积压缩器 “瘦身”,把每页几千个文本 tokens 压成 256 个视觉 tokens—— 相当于把一本厚书缩成几张摘要卡片;最后用 CLIP-large 锁定文档结构,确保公式、图表的位置不混乱。
图片
举个直观例子:处理 20 页带公式的学术论文,传统方法得切成 4 段,公式和正文的关联全断;DeepSeek-OCR 却能像专业图书管理员,先摸清整体布局,再把 20 页内容压成 5120 个视觉 tokens,比原本文本 tokens 少了近 10 倍。等你问 “实验数据在哪”,它能立刻定位并还原完整内容,连公式推导的逻辑链都不会乱。
2. MoE 解码器:需要时 “无损解压”
压缩后怎么用?全靠 MoE 专家解码器 “精准还原”。它基于 DeepSeek-3B-MoE 架构,只激活 570M 参数(相当于总参数的 1/5),就能把视觉 tokens 变回清晰文本。比如解压财报里的复杂表格,不仅能还原数字,连表头层级、数据关联都和原文一模一样,比人工整理还精准。
图片
这种 “压缩 - 解压” 模式,彻底解决了传统长文档处理的痛点:不用切片段导致逻辑断档,不用反复传数据导致延时,tokens 消耗少了,显存占用也跟着降 —— 单张 A100 GPU 就能轻松跑起千页文档处理。
02
实测数据炸裂:3 大场景吊打对手,效率差 400 倍
光说不练假把式,DeepSeek 在论文里用三类测试证明实力,结果让 Azure、Tesseract 等对手望尘莫及,尤其是真实场景的表现,完全戳中了行业痛点。
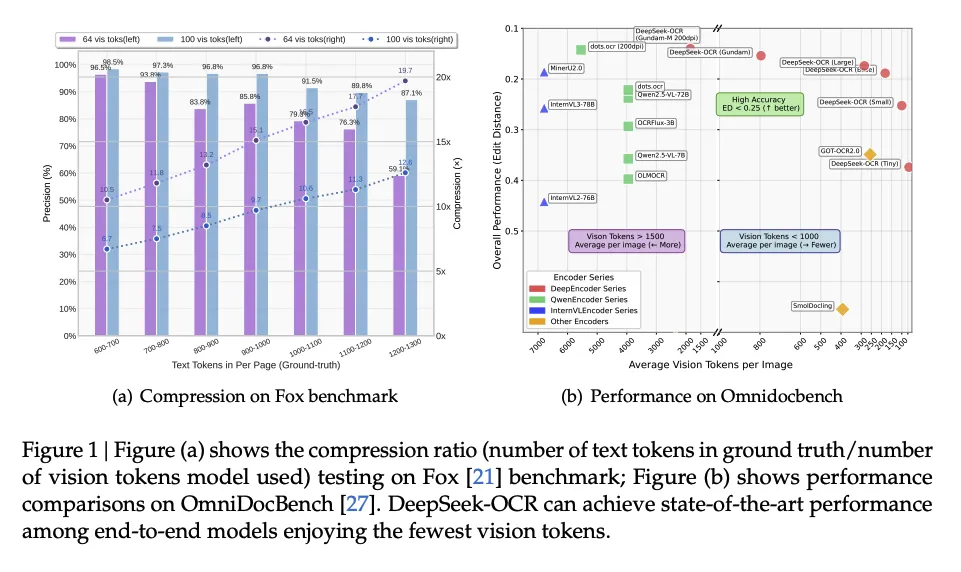
1. 标准测试:10 倍压缩下准确率 97.3%
在 ICDAR 2023 数据集(10 万页多语言文档)测试中,DeepSeek-OCR 每页只用 256 个 tokens,处理速度达 8.2 页 / 秒,显存仅占 4.5GB;而 MinerU2.0 每页要 6000 多个 tokens,速度才 1.5 页 / 秒,显存占 12.8GB。更关键的是准确率 ——10 倍压缩下仍有 97.3%,比 Azure OCR 高出 11 个百分点。
在难度更高的 OmniDocBench 测试中,它更是 “以少胜多”:用 100 个视觉 tokens 就超过了 GOT-OCR2.0(256 tokens),用不到 800 个 tokens 就碾压了需要 6000 多 tokens 的 MinerU2.0,把 “高效 + 高精度” 做到了极致。
2. 真实场景:金融、科研、法律全 hold 住
选三个最难啃的领域实测,结果更让人惊喜:
处理 286 页上市公司年报,表格还原准确率 95.7%,关键数据误差<0.3%,单轮 4 分 12 秒搞定;MinerU2.0 得切 6 段处理,耗时 29 分钟,表格断档率 18.2%。
解析 62 页带 45 个复杂公式的 Nature 论文,公式识别准确率 92.1%,生成的 LaTeX 格式能直接复制用;Azure OCR 准确率仅 76.3%,格式乱得没法用。
识别 158 页带批注的并购合同,批注关联准确率 89.5%,条款逻辑全保留;Tesseract 5.0 只有 62.3%,27% 的批注和正文关联全断。
3. 训练效率:1 天抵人工 400 天
传统人工标注一天只能处理 500 页文档,而 DeepSeek 的 “动态数据生成框架” 一天能产出 20 万页标注数据,效率差了 400 倍!更厉害的是模型迭代速度 —— 用 100 万页数据训练 7 天,复杂场景准确率就能提升 12.6 个百分点,大大降低了落地成本。
03
不止是 OCR:大模型长上下文的 “破局钥匙”
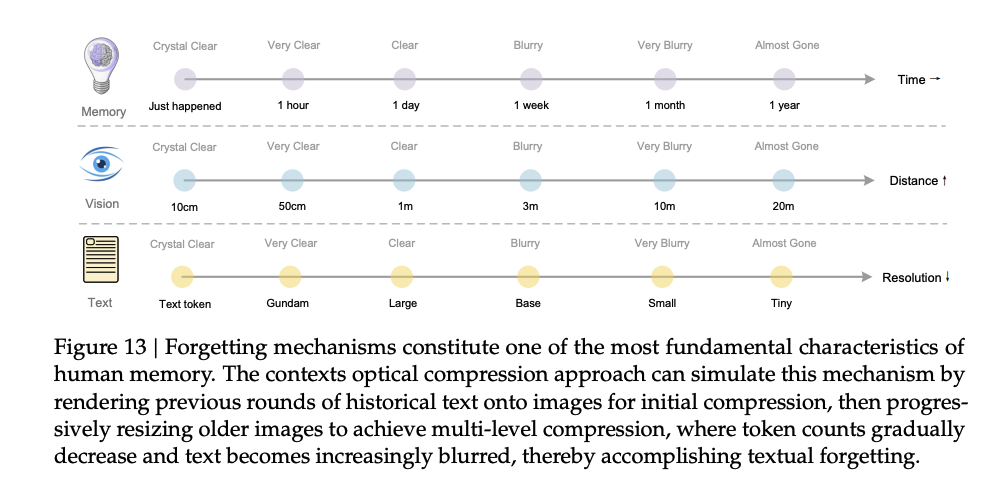
DeepSeek-OCR 最厉害的不是 “认字准”,而是帮大模型突破了 “上下文天花板”。论文里提出的 “分层上下文管理策略”,彻底解决了大模型 “记不住、装不下” 的问题:
(10 轮对话、20 页文档):存原始文本,零误差;
(100 轮对话、200 页文档):10 倍压缩存图像,精度效率兼顾;
(1000 轮对话、1000 页文档):20 倍压缩存,海量信息装得下。
这套方案在 DeepSeek-R1 模型上测试,长文档问答准确率提升 34.5%,显存省了 68%—— 原本 16GB 显存设备只能装 32k tokens,现在能装 320k tokens(相当于 600 页 PDF),直接扩容 10 倍!
图片
目前已有 3 家头部金融机构、2 家教育公司试点:金融分析师用它提财报数据,省 70% 整理时间;老师用它批改作业,手写答案、画图题都能判;工业场景读巡检报告,辅助生成维修方案,反馈效率提升 60%-85%。
04
不完美但可期:这些坑还需填
当然,DeepSeek-OCR 也不是万能的。论文坦诚提到两个短板:一是压缩比超 30 倍时,关键信息保留率会跌破 45%,医疗、法律等高精度场景暂不适用;二是复杂图形识别较弱,三维图表、手写艺术字的准确率比印刷体低 12-18 个百分点。
但瑕不掩瑜,它真正的价值在于 “技术范式转变”—— 把 OCR 从单纯的文字识别工具,变成了大模型长上下文的解决方案。以后大模型处理长文档,或许都会用 “文本转图像” 的压缩思路,这对降低 AI 应用成本、推动行业智能化转型,意义重大。
更良心的是,DeepSeek 延续了开源传统,已在 GitHub 和 Hugging Face 开放模型,开发者不用再为长文档处理难题发愁。
05
谁先解决 “记忆痛点”,谁就握有下一代 AI 钥匙
大模型的竞争,本质是 “处理复杂信息能力” 的竞争。以前大家比 “谁算得快”,现在比 “谁记得多、记得准”。DeepSeek-OCR 用 “视觉压缩” 这招,给行业指了条新路子 —— 不用堆算力、不用扩内存,换个思路就能突破瓶颈。
最后想问:如果你的工作要经常处理长文档,DeepSeek-OCR 能帮你解决哪些痛点?是财报整理、论文研读,还是合同审核?评论区聊聊你的需求~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号