如何阻止Gephi在导入时擦除MySQL节点表中的“in”列,并替换它的自动增量列
如何阻止Gephi在导入时擦除MySQL节点表中的“in”列,并替换它的自动增量列
提问于 2022-08-18 06:49:15
预期的行为是简单地从MySQL导入节点数据,而不做任何更改:
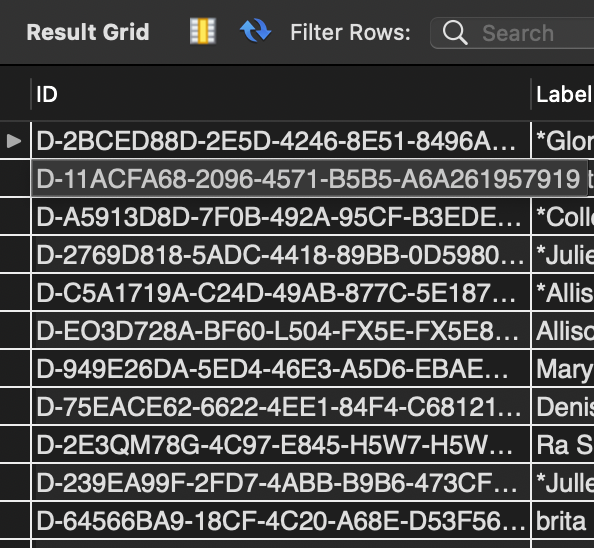
然而,Gephi正在擦除ID列中的所有数据,并将其替换为自动递增的ID列:
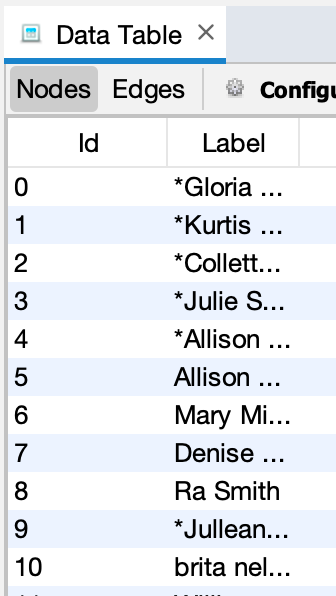
当然会导致导入边缘的错误:
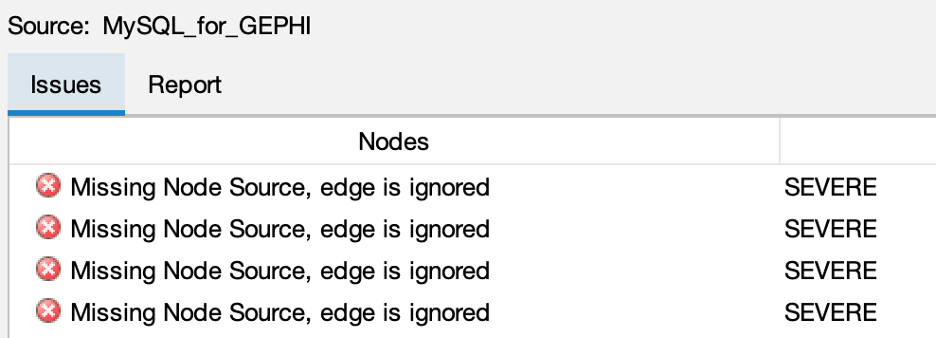
在导入查询中没有什么特别之处:
节点查询:选择*来自GEPHI_nodes边缘查询:选择*来自GEPHI_edges
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-08-20 01:48:02
显然,当从CSV导入时,在查找“id”列标题之前,Gephi将转换为小写:
gephi.io.importer.plugin.file.spreadsheet.process.ImportNodesProcess
lowerCaseHeaders.add(headerName.toLowerCase());鉴于从数据库导入:
gephi.io.importer.plugin.database.EdgeListDatabaseImpl并没有提供这样的细节。
Stack Overflow用户
发布于 2022-08-20 11:29:09
还请注意:当Gephi导入CSV时,它尝试为每一列(用户可以过度使用)计算数据类型。因此,如果数字以文本的形式出现在CSV列中,则Gephi正确地将它们识别为数字。
从数据库导入数据时的行为是完全不同的,相反,Gephi从表本身读取数据类型。因此,如果SQL表将数字存储为文本,则Gephi将不会尝试更正它,而且实际上没有提供任何明显的方法来超越这种行为。
因此,只有那些由Gephi识别的特定SQL数据类型才会被正确导入,而所有其他数据类型都将默认为作为字符串导入。正确识别的类型如下所示。
特别要注意的是,没有在此列表中的十进制列将默认为字符串,因此不会注册为用于范围分析的数字,等等。
承认的数据库进口:
BIGINT,TINYINT,SMALLINT,布尔,浮动,双,位,实
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73405138
复制相关文章




相似问题
在调试器中获得404的例子是for /wp/Array?
如何获得不同的相关职位
在wordpress中,如何在单击不同的电子邮件ids时依次发送不同的电子邮件
如何获得带有关联类别和标记名称的post,而不是使用rest的ids?
如何遍历所有帖子并使用Get媒体附件计数附件
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
