每对项目组间的熊猫相关矩阵
我有这样一个csv文件:
date,sym,close
2014.01.01,A,10
2014.01.02,A,11
2014.01.03,A,12
2014.01.04,A,13
2014.01.01,B,20
2014.01.02,B,22
2014.01.03,B,23
2014.01.01,C,33
2014.01.02,C,32
2014.01.03,C,31然后,通过df函数得到一个名为read_csv的数据文件。
import numpy as np
import pandas as pd
df=pd.read_csv('daily.csv',index_col=[0])
groups=df.groupby('sym')[['close']].apply(lambda x:func(x['close'].values))groups看起来如下所示:
sym
A [nan,1.00,2.00,...]
B [nan,1.00,2.00,...]
C [nan,1.00,2.00,...]如何计算每对系统之间的相关性?
AA,AB,AC,BB,BA,BC,CA,CB,CC顺便说一下,每个系统的项目号可能是,而不是。
回答 2
Stack Overflow用户
发布于 2015-04-14 13:07:59
使用上面的df,创建一个枢轴表:
dfp = df.pivot('date','sym')
print(dfp)close sym A B C date 2014-01-01 10 20 33 2014-01-02 11 22 32 2014-01-03 12 23 31 2014-01-04 13 NaN 30
熊猫将计算成对的系数:
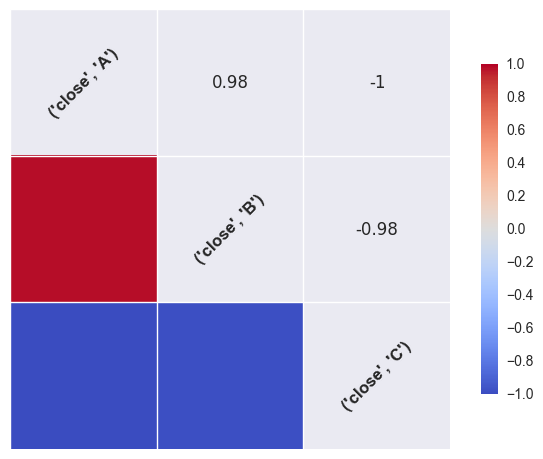
print(dfp.corr())close sym A B C sym close A 1.000000 0.981981 -1.000000 B 0.981981 1.000000 -0.981981 C -1.000000 -0.981981 1.000000
但是如果你想美化它,请查看seaborn:
import seaborn as sns
sns.corrplot(dfp, annot=True)结果:
Stack Overflow用户
发布于 2015-04-14 22:35:10
获得groups后
sym
A [nan,1.00,2.00,...]
B [nan,1.00,2.00,...]
C [nan,1.00,2.00,...]我创建了一个DataFrame df2
df2=DataFrame()
df2['A']=groups['A']
df2['B']=groups['B']
df2['C']=groups['C']
df2.corr()该方法可以通过组间的数据得到相关关系。然而,并不完美。如何将组转换为这样的DataFrame?组的循环键?我需要继续努力。
https://stackoverflow.com/questions/29631240
复制



相似问题
sinon存根数组对象
从sinon存根返回sinon存根
函数不能用Mocha/Sinon模拟/存根
Sinon存根返回false
在Sinon中,无法成功存根/模拟方法返回。
领取专属 10元无门槛券
AI混元助手 在线答疑

洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
