MS 2013:基于表单中的复选框更改报表中的标签标题
MS 2013:基于表单中的复选框更改报表中的标签标题
提问于 2017-02-23 05:06:58
我在表格上有checkbox (Name:chkHead; Caption:Out of Office),在报告中有label(Name:lblHead; Caption: Name of office head)。
详细图像:
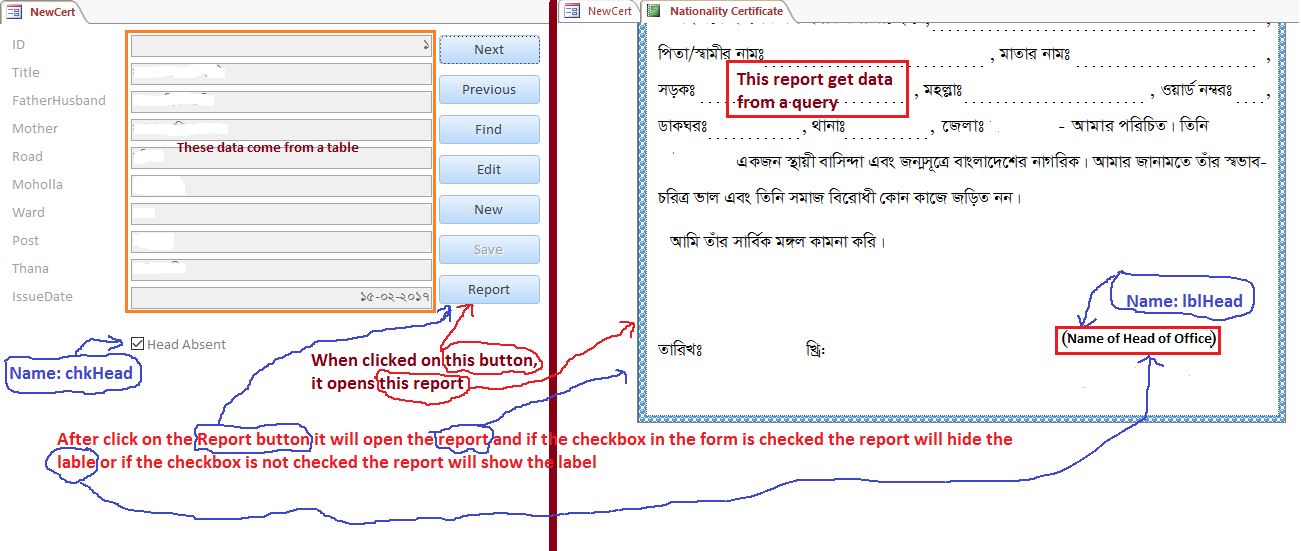
当我单击表单中的报表按钮时,它将根据特定的查询生成报表。如果选中表单中的复选框,则标签标题必须是“负责人”,否则它将显示办公室负责人的姓名。
我正在使用MS Access 2013。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-02-23 05:34:42
- 创建两个标签-> 1.办公室主管名称2.负责人
- 单击窗体设计视图中的复选框,然后在“设计”选项卡下选择“属性工作表”
- 在右侧的“属性表”中,在“事件”下选择“on”,并在其中选择“代码生成器”。
如果Me!MyCheckBox = True,则为
1. Write the code similar to the below inside sub()Me.Label2.Visible =真
Me.Label2.Visible = False
否则,如果Me!MyCheckBox = False,则
Me.Label2.Visible = False
Me.Label2.Visible =真
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/42416623
复制相关文章





点击加载更多
相似问题
如何在聚合函数中选择spark sql查询中的所有列
聚合后获取Spark DataFrame的所有列
spark中多列的聚合
Spark Scala透视后多个聚合列按名称选择列
如何在spark中迭代选择列
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
