
从网上抓取谷歌航班价格
提问于 2019-03-28 13:39:54
我正在努力学习如何使用python库BeautifulSoup,例如,我想在Google航班上节省一次航班的价格。因此,我连接到谷歌航班,例如在此链接,我想得到最便宜的航班价格。
因此,我将在div中得到这个类的值“gws-比对-结果_巡回-价格”(如图中所示)。
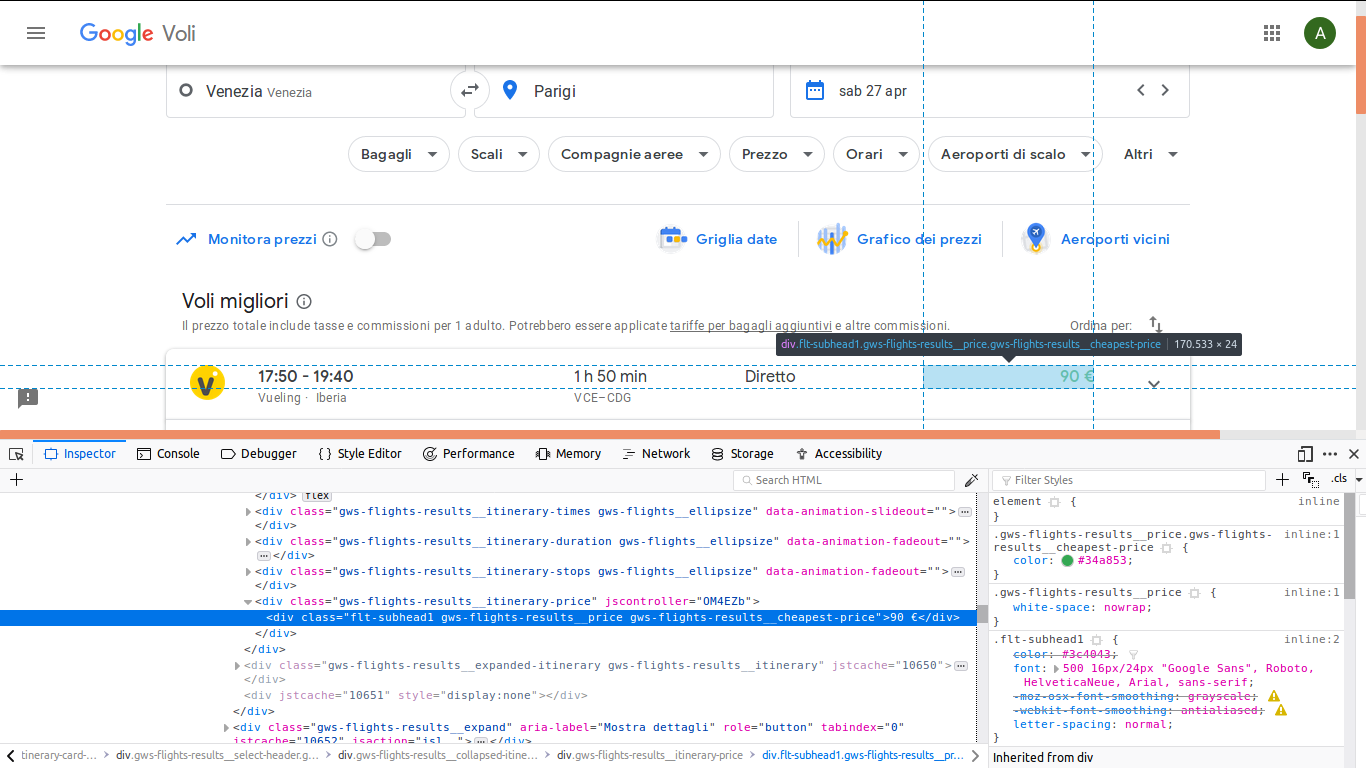
下面是我编写的简单代码:
from bs4 import BeautifulSoup
import urllib.request
url = 'https://www.google.com/flights?hl=it#flt=/m/07_pf./m/05qtj.2019-04-27;c:EUR;e:1;sd:1;t:f;tt:o'
page = urllib.request.urlopen(url)
soup = BeautifulSoup(page, 'html.parser')
div = soup.find('div', attrs={'class': 'gws-flights-results__itinerary-price'})但是得到的div有类NoneType。
我也试着用
find_all('div') 但在我以这种方式发现的所有div中,没有我感兴趣的div。有人能帮我吗?

回答 3
Stack Overflow用户
回答已采纳
发布于 2019-03-28 13:49:43
看起来javascript需要运行,所以使用像selenium这样的方法
from selenium import webdriver
url = 'https://www.google.com/flights?hl=it#flt=/m/07_pf./m/05qtj.2019-04-27;c:EUR;e:1;sd:1;t:f;tt:o'
driver = webdriver.Chrome()
driver.get(url)
print(driver.find_element_by_css_selector('.gws-flights-results__cheapest-price').text)
driver.quit()Stack Overflow用户
发布于 2019-03-28 14:06:58
很高兴你正在学习网络抓取!因此,您获得NoneType的原因是因为您正在抓取的网站动态加载内容。当请求库获取url时,它只包含javascript。这个类的div“gws飞行-结果_巡回-价格”还没有呈现出来!因此,这是不可能的刮方法,你是用来刮这个网站。
但是,您可以使用其他方法,例如使用selenium或splash等工具获取页面,以呈现javascript,然后解析内容。
Stack Overflow用户
发布于 2019-03-28 14:00:19
BeautifulSoup是提取部分HTML或XML的一个很好的工具,但在这里,您只需要将url获取到另一个JSON对象的get请求。
(我现在不在电脑旁边,明天可以用一个例子来更新。)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/55407247
复制相关文章




点击加载更多


腾讯云开发者
