
Pandas按列值过滤
提问于 2020-07-19 20:08:59
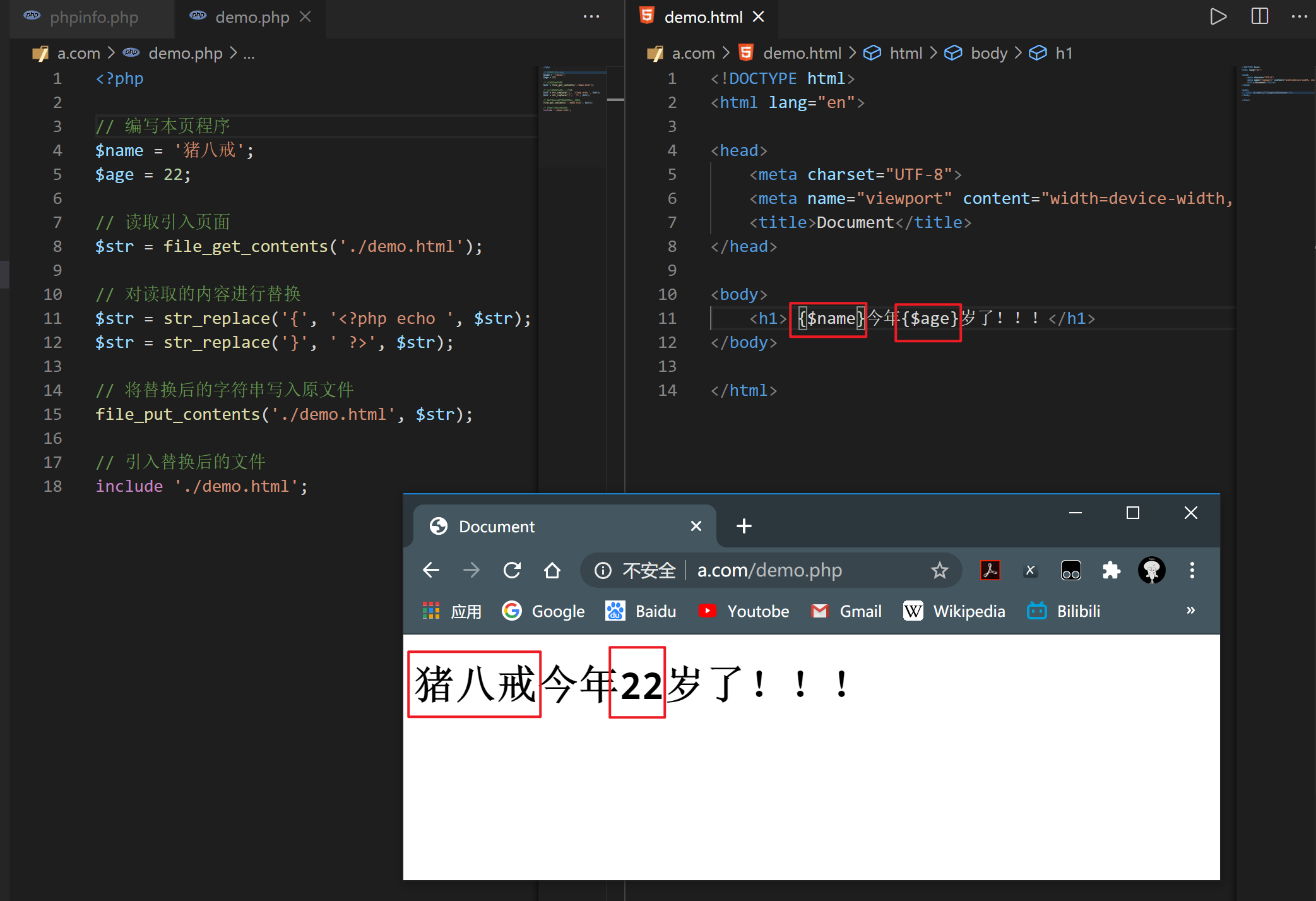
如何在只保留n列的情况下按列排序值?这就是我正在努力解决的问题:
import pandas as pd
import numpy as np
file = ('example.csv')
df = pd.read_csv(file)
df = df[['ID', 'Hero', 'Customer']].drop_duplicates('ID', keep="first")
df.head()
Output:
ID | Hero | Customer
45 Rambo Nils
90 Superman Sophia
33 Superman Sophia
55 Rambo Sophia
12 Hulk Sophia为了得到我想要的格式(在本例中是heatmap),我这样做了:
heatmap = df.groupby(['Hero', 'Customer']).size().unstack(fill_value=0)
heatmap
Output:
Ida Jonas Morgan Sophia Nils
Rambo 0 0 3 11 1
Superman 2 0 0 66 0
Hulk 0 0 0 7 0我想要做的是按降序对其进行排序,以便将值最高的列推到左侧,如下所示:
想要的输出:
Sophia Morgan Ida Nils Jonas
Rambo 11 3 0 1 0
Superman 66 0 2 0 0
Hulk 7 0 0 0 0如果我想保留n-数量的客户,我该如何做到?我遇到的另一个问题是ID在数据操作中丢失了,我不确定在count()-function之后如何处理它。我觉得我已经做了不必要的复杂(?)。

回答 1
Stack Overflow用户
发布于 2020-07-19 20:15:33
拥有df
Ida Jonas Morgan Sophia Nils
Rambo 0 0 3 11 1
Superman 2 0 0 66 0
Hulk 0 0 0 7 0尝试:
df.reindex(df.sum().sort_values(ascending = False).index, axis=1)测试结果:
Sophia Morgan Ida Nils Jonas
Rambo 11 3 0 1 0
Superman 66 0 2 0 0
Hulk 7 0 0 0 0页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62985137
复制






腾讯云开发者
