腾讯云
开发者社区
文档
建议反馈
控制台
登录/注册
首页
学习
活动
专区
圈层
工具
MCP广场
文章/答案/技术大牛
搜索
搜索
关闭
发布
精选内容/技术社群/优惠产品,
尽在小程序
立即前往
首页
学习
活动
专区
圈层
工具
MCP广场
返回腾讯云官网
云开发应用征集活动 | AI 代码远征季🛰️
新增「阳光普照奖」,发文即赢社区定制周边盲盒
立即参与
🥭“荔”刻出发!用“算法”运送 长安的荔枝?
热点技术有奖征文第11期
荔码行动
🖥你会向孩子推荐计算机相关专业吗?
又到了每年志愿填报的日子📑
立即回答
Docker免费训练营开启报名,让我们一起赶考新时代!
清华OpenCamp x 腾讯云CNB联袂打造
立即报名
共建架构师技术同盟交流圈—开发者需求调研问卷
填问卷赢好礼,你的声音很重要
填写问卷
为你推荐
腾讯专区
订阅及关注
云计算
人工智能
前端
后端
编程语言
数据库
大数据
音视频
安全
物联网
硬件
运维
测试
网络与通信
架构设计
开发工具
操作系统
职业发展
算法
管理
算法
腾讯云
加密
实践
数据
无缝互操作:腾讯云KMS在SM2国密算法上与 EasyGmSSL 的兼容实践
国密算法SM2作为我国自主知识产权的非对称密钥标准,在金融、政务等领域广泛应用。实际开发中,常需本地工具与云服务协同工作,兼容性成为关键痛点。本文通过完整互操作验证,展示EasyGmSSL库与腾讯云KMS在SM2加解密、签名验签上的完美兼容性,特别突出其在极致易用性、格式灵活性和协议兼容性方面的优势。
密码学人CipherHUB
2025-06-26
258
0
AI代码远征季#小游戏
AI 代码远征季 | 「CloudBase AI ToolKit」开发《草原之王》简直太酷啦!
不想折腾配置环境?项目需要部署发布到公网环境让更多人看到?如何从零开始快速构建项目?
熊猫钓鱼
2025-06-25
187
0
热点技术征文第11期长安的荔枝
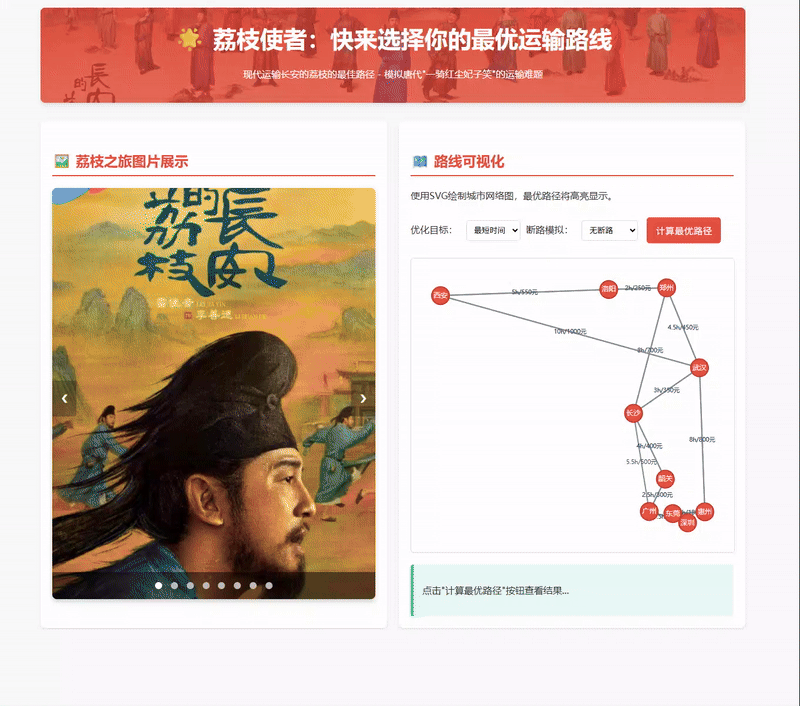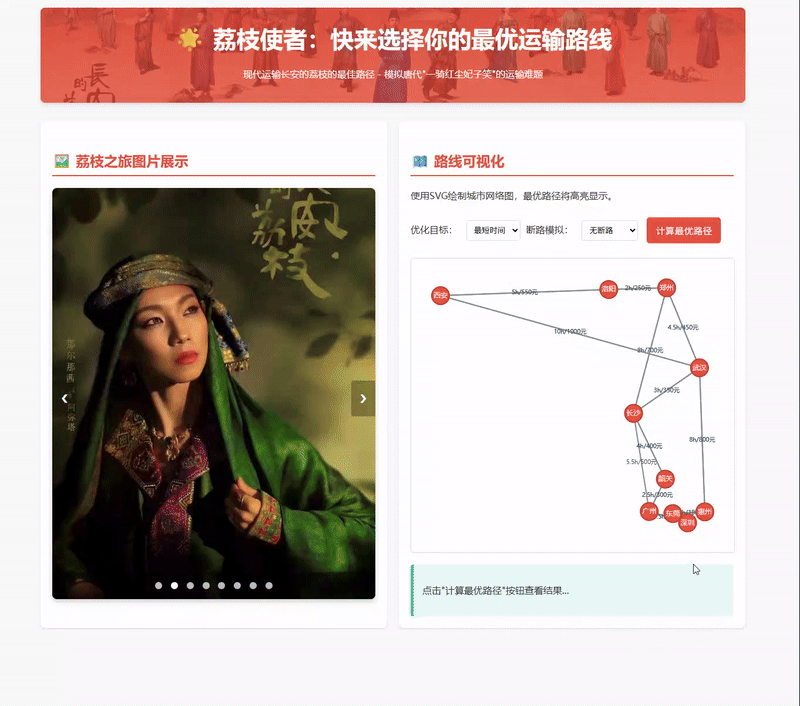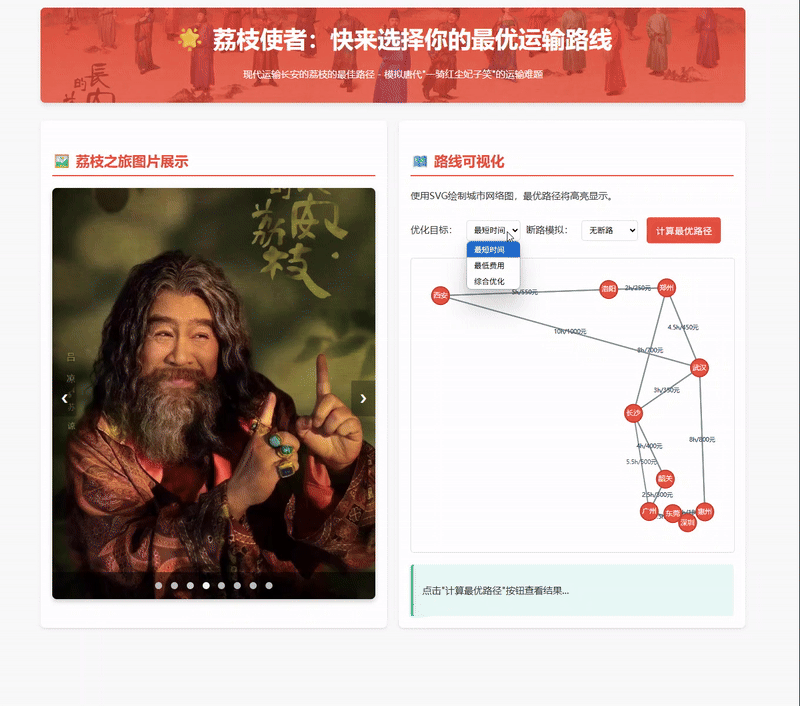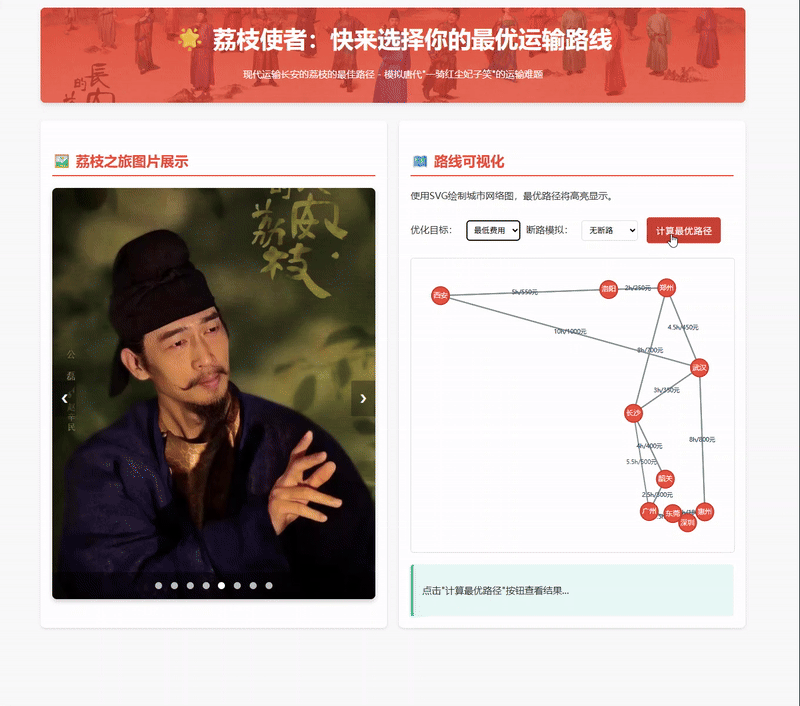
《长安的荔枝》背后惊天秘密!Dijkstra算法如何逆天改命,20小时送达西安?
鉴于近期热播剧集《长安的荔枝》所描绘的紧急使命,假设你作为圣上钦点的“荔枝使”,肩负着一项至关重要的任务:务必将岭南(以“深圳”为起点)的鲜美荔枝,以最快、最优的方式运抵大唐都城长安(以“西安”为终点)。
Lion 莱恩呀
2025-06-25
278
0
腾讯云低代码解决方案
技术派低代码的破局之路:OneCode 如何用硬核技术重构开发范式
在低代码赛道狂奔的十年里,行业始终面临着一道「效率与控制」的二元悖论:纯可视化拖拽的工具让业务人员快速搭建应用,却在复杂逻辑面前举步维艰;强调代码生成的平台试图兼顾开发效率,却因「生成即失控」的代码黑箱让技术团队望而却步。当多数低代码平台沉迷于「可视化噱头」时,OneCode 选择了一条截然不同的破局之路 —— 以 AI 原生编译为核,构建「全代码可编程」的技术体系,用硬核技术重新定义低代码的企业级价值。
onecode
2025-06-25
112
0
grpc
c++
c#
从零构建 gRPC 跨语言通信:C++ 服务端与 C# 客户端完整指南
在现代分布式系统中,gRPC 作为高性能、跨语言的 RPC 框架越来越受欢迎。它基于 HTTP/2 协议,使用 Protocol Buffers(Protobuf)作为接口定义语言,支持多种编程语言,能够高效地实现不同语言之间的远程过程调用。本文将手把手教你如何从零开始构建一个完整的 gRPC 通信系统,使用 C++ 实现服务端,C# 实现客户端。
码事漫谈
2025-06-25
203
0
TDP云声计划
腾讯云 TDP 第五届线上发展交流大会邀您 | 共赴开发者之约
时光的指针划过TDP的星河航程, 每一次代码的跃动、每一次反馈的碰撞,都在为云计算的疆域拓印下属于开发者的足迹。2025 年已悄然走过半年,回望这过去的半年,我们依然秉持着为开发者拓展更广阔产品体验与反馈途径的信念不懈奋进。我们满怀感恩之心,感谢每一位一路同行的开发者,你们的陪伴是我们的力量源泉。在这个充满活力与机遇的时刻,第五届开发者交流大会即将拉开帷幕,腾讯云 TDP 团队怀着诚挚的心意邀请您拨冗莅临,与我们一同交流、分享、探讨,我们渴望倾听更多来自开发者们的声音,共同书写 TDP 发展的崭新篇章。
TDP 官方运营
2025-06-25
413
0
热点技术征文第11期长安的荔枝
看《长安的荔枝》现代荔枝使来算最优路线进献荔枝吧!
近期热播剧《长安的荔枝》生动再现了唐代"一骑红尘妃子笑"的荔枝运输盛况。剧中,荔枝使李善德面临从岭南到长安(今西安)紧急运送新鲜荔枝的艰巨任务。这一历史场景激发了思考:如果唐代有现代算法技术,荔枝运输会怎样优化?
肥晨
2025-06-21
200
0
热点技术征文第11期长安的荔枝
长安荔枝滞销?不,是你没装「荔枝使」专属外挂!
最近追《长安的荔枝》追得上头,看着李善德抱着账本算路线算到秃头,恨不得隔空扔给他一台笔记本电脑 —— 您瞧,当年要是有咱这「荔枝运输智能规划系统」,哪儿还需要在岭南烈日下暴走?直接坐在长安城胡商的酒肆里,喝着葡萄酿就把路线优化了!
Jimaks
2025-06-23
313
2
TDP云声计划
最方便的应用构建——利用云原生快速搭建本地deepseek知识仓库
云原生构建(Cloud Native Build,简称CNB),是基于Docker生态,对环境、缓存、插件进行抽象的一种构建工具。它采用声明式的语法,让开发者能够以更简洁、高效的方式构建软件。CNB的核心价值在于提供了一种标准化的构建流程,使得构建结果在不同环境中具有一致性和可移植性。
熊猫钓鱼
2025-06-24
219
0
MCP头号玩家
MCP
有了这个AI数字美食顾问,再也不愁今天吃什么
智能体(Agent)是一种以云计算为基础设施、人工智能为核心驱动的自主决策系统。相较于AI大模型工具(如元宝、通义等)的通用性定位,智能体更强调场景化适配与垂直领域深耕。
穿过生命散发芬芳
2025-06-25
205
1
为你推荐
腾讯专区
订阅及关注
云计算
人工智能
前端
后端
编程语言
数据库
大数据
音视频
安全
物联网
硬件
运维
测试
网络与通信
架构设计
开发工具
操作系统
职业发展
算法
算法
腾讯云
加密
实践
数据
无缝互操作:腾讯云KMS在SM2国密算法上与 EasyGmSSL 的兼容实践
国密算法SM2作为我国自主知识产权的非对称密钥标准,在金融、政务等领域广泛应用。实际开发中,常需本地工具与云服务协同工作,兼容性成为关键痛点。本文通过完整互操作验证,展示EasyGmSSL库与腾讯云KMS在SM2加解密、签名验签上的完美兼容性,特别突出其在极致易用性、格式灵活性和协议兼容性方面的优势。
密码学人CipherHUB
2025-06-26
AI代码远征季#小游戏
AI 代码远征季 | 「CloudBase AI ToolKit」开发《草原之王》简直太酷啦!
不想折腾配置环境?项目需要部署发布到公网环境让更多人看到?如何从零开始快速构建项目?
熊猫钓鱼
2025-06-25
热点技术征文第11期长安的荔枝
《长安的荔枝》背后惊天秘密!Dijkstra算法如何逆天改命,20小时送达西安?
鉴于近期热播剧集《长安的荔枝》所描绘的紧急使命,假设你作为圣上钦点的“荔枝使”,肩负着一项至关重要的任务:务必将岭南(以“深圳”为起点)的鲜美荔枝,以最快、最优的方式运抵大唐都城长安(以“西安”为终点)。
Lion 莱恩呀
2025-06-25
腾讯云低代码解决方案
技术派低代码的破局之路:OneCode 如何用硬核技术重构开发范式
在低代码赛道狂奔的十年里,行业始终面临着一道「效率与控制」的二元悖论:纯可视化拖拽的工具让业务人员快速搭建应用,却在复杂逻辑面前举步维艰;强调代码生成的平台试图兼顾开发效率,却因「生成即失控」的代码黑箱让技术团队望而却步。当多数低代码平台沉迷于「可视化噱头」时,OneCode 选择了一条截然不同的破局之路 —— 以 AI 原生编译为核,构建「全代码可编程」的技术体系,用硬核技术重新定义低代码的企业级价值。
onecode
2025-06-25
grpc
c++
c#
从零构建 gRPC 跨语言通信:C++ 服务端与 C# 客户端完整指南
在现代分布式系统中,gRPC 作为高性能、跨语言的 RPC 框架越来越受欢迎。它基于 HTTP/2 协议,使用 Protocol Buffers(Protobuf)作为接口定义语言,支持多种编程语言,能够高效地实现不同语言之间的远程过程调用。本文将手把手教你如何从零开始构建一个完整的 gRPC 通信系统,使用 C++ 实现服务端,C# 实现客户端。
码事漫谈
2025-06-25
TDP云声计划
腾讯云 TDP 第五届线上发展交流大会邀您 | 共赴开发者之约
时光的指针划过TDP的星河航程, 每一次代码的跃动、每一次反馈的碰撞,都在为云计算的疆域拓印下属于开发者的足迹。2025 年已悄然走过半年,回望这过去的半年,我们依然秉持着为开发者拓展更广阔产品体验与反馈途径的信念不懈奋进。我们满怀感恩之心,感谢每一位一路同行的开发者,你们的陪伴是我们的力量源泉。在这个充满活力与机遇的时刻,第五届开发者交流大会即将拉开帷幕,腾讯云 TDP 团队怀着诚挚的心意邀请您拨冗莅临,与我们一同交流、分享、探讨,我们渴望倾听更多来自开发者们的声音,共同书写 TDP 发展的崭新篇章。
TDP 官方运营
2025-06-25
热点技术征文第11期长安的荔枝
看《长安的荔枝》现代荔枝使来算最优路线进献荔枝吧!
近期热播剧《长安的荔枝》生动再现了唐代"一骑红尘妃子笑"的荔枝运输盛况。剧中,荔枝使李善德面临从岭南到长安(今西安)紧急运送新鲜荔枝的艰巨任务。这一历史场景激发了思考:如果唐代有现代算法技术,荔枝运输会怎样优化?
肥晨
2025-06-21
热点技术征文第11期长安的荔枝
长安荔枝滞销?不,是你没装「荔枝使」专属外挂!
最近追《长安的荔枝》追得上头,看着李善德抱着账本算路线算到秃头,恨不得隔空扔给他一台笔记本电脑 —— 您瞧,当年要是有咱这「荔枝运输智能规划系统」,哪儿还需要在岭南烈日下暴走?直接坐在长安城胡商的酒肆里,喝着葡萄酿就把路线优化了!
Jimaks
2025-06-23
TDP云声计划
最方便的应用构建——利用云原生快速搭建本地deepseek知识仓库
云原生构建(Cloud Native Build,简称CNB),是基于Docker生态,对环境、缓存、插件进行抽象的一种构建工具。它采用声明式的语法,让开发者能够以更简洁、高效的方式构建软件。CNB的核心价值在于提供了一种标准化的构建流程,使得构建结果在不同环境中具有一致性和可移植性。
熊猫钓鱼
2025-06-24
MCP头号玩家
MCP
有了这个AI数字美食顾问,再也不愁今天吃什么
智能体(Agent)是一种以云计算为基础设施、人工智能为核心驱动的自主决策系统。相较于AI大模型工具(如元宝、通义等)的通用性定位,智能体更强调场景化适配与垂直领域深耕。
穿过生命散发芬芳
2025-06-25
晚上好!
欢迎来到腾讯云开发者社区
登录
沙龙日历
全部 >
加入讨论
的问答专区 >
原创作者热度排行榜
更多 >
问题归档
专栏文章
快讯文章归档
关键词归档
开发者手册归档
开发者手册 Section 归档
领券