OccDepth:对标 Tesla Occupancy 的开源 3D 语义场景补全方法
原创OccDepth:对标 Tesla Occupancy 的开源 3D 语义场景补全方法
原创
开源代码: https://github.com/megvii-research/OccDepth
论文链接:https://arxiv.org/abs/2302.13540
原文:OccDepth:对标 Tesla Occupancy 的开源 3D 语义场景补全方法
一、背景
在 2022 年的 Tesla AI Day 上, Tesla 将 Bev(鸟瞰图) 感知进⼀步升级,提出了基于 Occupancy Network 的感知方法。这种基于 Occupancy Grid Mapping 的表示方法,又叫体素(Voxel)占据,在 3D 重建任务中已经是一个“老熟人”了。它将世界划分成为⼀系列 3D网格单元,然后定义哪个单元被占用,哪个单元是空闲的,并且每个占据单元同时也包含分类信息,比如路面、车辆、建筑物、数目等。在自动驾驶感知中,相比普通的 3D 检测方法,这种基于体素的表示可以帮助预测更精细的异形物体。如下图 Tesla Demo 中所展示的那样,对于空间感知更精细。
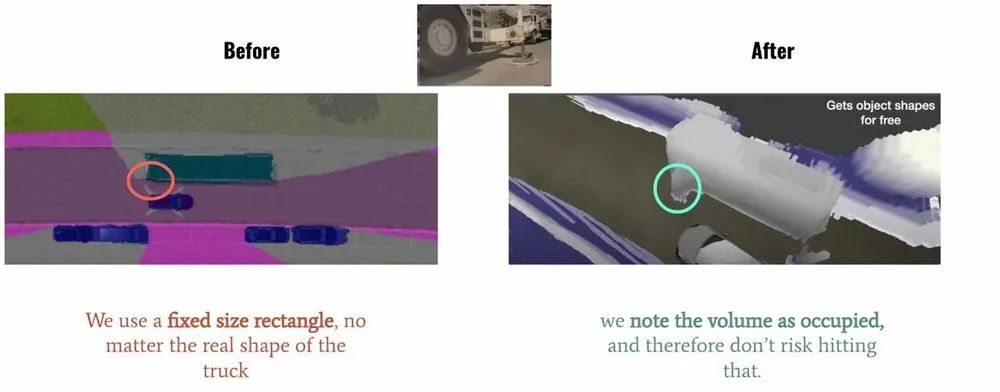
在这种在线重建的方法中,一般使用 SSC ( Semantic Scene Completion)任务评判预测的准确性,即利用图像、点云或者其他 3D 数据作为输入,预测空间中的体素占据和类别信息,并与 GT 标注相比较。在权威的自动驾驶 Semantic-Kitti SSC 任务中,可以根据输入分成纯图像和基于 3D (点云、 TSDF、体素等)的两类不同的方法。使用纯图像方案恢复 3D 结构是一个比较困难的问题,旷视研究院提出了 OccDepth 的方能股份,将纯图像输入方法的精度大幅提升,获得了视觉方法的 SOTA,其中 SC IOU 从 34.2 增高为 45.1, mIOU 从 11.1 增高为15.9。同时可视化结果表明 OccDepth 可以更好地重建出近处和远处的几何结构。下面将带大家介绍 OccDepth 具体的方法。

二、任务困难和解决动机
仅从视觉图像估计场景中完整的⼏何结构和语义信息,这是一项具有挑战性的任务,其中准确的深度信息对于恢复 3D几何结构是至关重要的。之前的很多工作,都是利用点云、 RGBD 、TSDF[1]等其他 2.5D 、3D 形式[2-8]作为输入,来预测体素占据,这也需要较昂贵的设备来采集 3D 信息。基于纯图像的方案更便宜,同时也可以提供更为丰富且稠密场景表示,MonoScene[9]提出了纯视觉的 Baseline。但相较于上述的 3D 方法,在几何结构恢复方面,表现有一定的差距。
本项工作借鉴了“人类使用双眼能比单眼更好地感知3D世界中的深度信息”的思想,提出了名为 OccDepth 的语义场景补全方法。它分别显式和隐式地利用图像中含有的深度信息,以帮助恢复良好的 3D几何结构。在 SemanticKITTI 和 NYUv2 等数据集上的⼤量实验表明,与当前基于纯视觉的 SSC方法相比,我们提出的 OccDepth方法均达到了 SOTA,在 SemanticKITTI 上整体实现了+4.82% mIoU 的提升,其中+2.49% mIoU 的提升来在自隐式的深度优化,+2.33% mIoU 提升来自于显式的深度蒸馏。 在NYUv2 数据集上,与当前基于纯视觉的 SSC方法相比OccDepth 实现了+4.40% mIoU 的提升。 甚至相比于所有 2.5D 、3D 的方法, OccDepth 仍然实现了 +1.70% mIoU 的提升。
三、具体方法
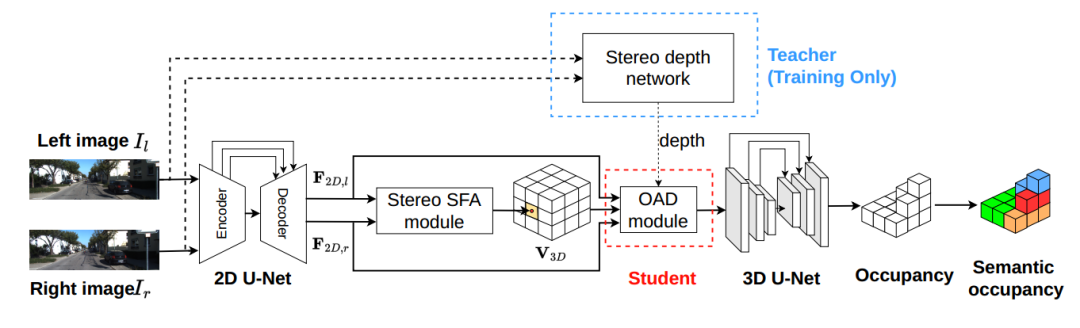
上图是 OccDepth 的主要流程。3D 场景语义补全可以根据输入的双目图像所推理出来,其中连接了一个双目特征软融合(Stereo-SFA )模块用于隐式地将特征提升到 3D 空间,一个占用深度感知(OAD) 模块⽤于显式地增强深度预测,后续接上 3D U-Net 用于提取几何和语义信息。其中双目深度网络仅在训练的时候使用,用蒸馏的方法帮助 OAD 模块提升深度预测能力。
3.1 双目特征软融合模块
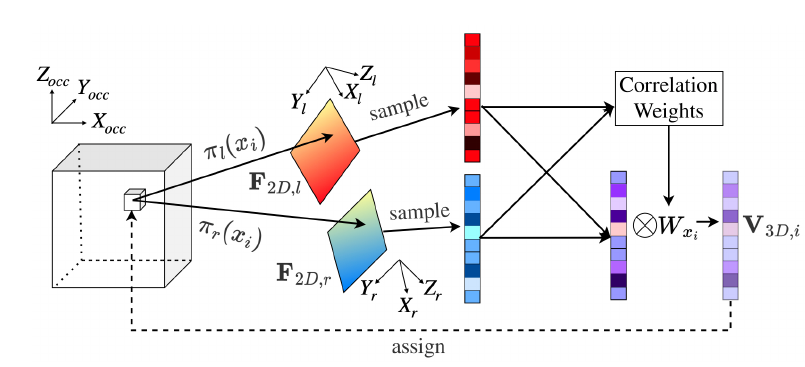
上图显示了 Stereo-SFA 模块的处理过程。为了计算有界 3D 场景中每个体素的特征表示,需要建立起 2D 图像特征和 3D 体素特征之间的特征映射。与将 2D 特征反投影到 3D 空间的 LSS[14] 不同,我们选择将每个体素投影到相应图像像素的映射方法,后者能够为有界空间内的所有体素建立起完整的特征映射。此外,我们通过计算同一空间体素对应左右图像上 2D 特征之间的相关性可以隐式地将深度信息编码为 3D 体素特征的权重。这里假设双目相机已经经过了校准并且输入图像经过了去畸变处理,那么双目相机的内外参数都是已知的,3D 到 2D 的投影关系也是已知的。对于给定X\times Y\times Z个体素,他们的中心坐标表示为 X\in R^{X\times Y \times Z \times 3},那么 3D 到 2D 的投影可以表示为 \pi(x)。然后,3D 体素特征 V_{3D}\in R^{ X\times Y \times Z\times C}可以从相应的 2D 特征图 F_{2D}中采样获得,表示为:V_{3D}=\phi_{\pi(x)}(F_{2D}) 。之后用 V_{3D,l}和 V_{3D,r}分别表示为从左 2D 特征图和右 2D 特征图获取的 3D 特征,那么加权的 3D 特征 V_{3D,w}可以写为
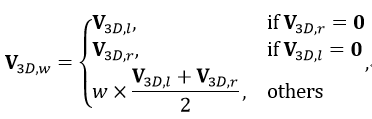
其中 w表示根据 V_{3D,l}和 V_{3D,r}之间相关性计算得到的权重。在本工作中实际实现的时候采用余弦相似度来衡量特征的相关性。
3.2 占用感知的深度蒸馏模块
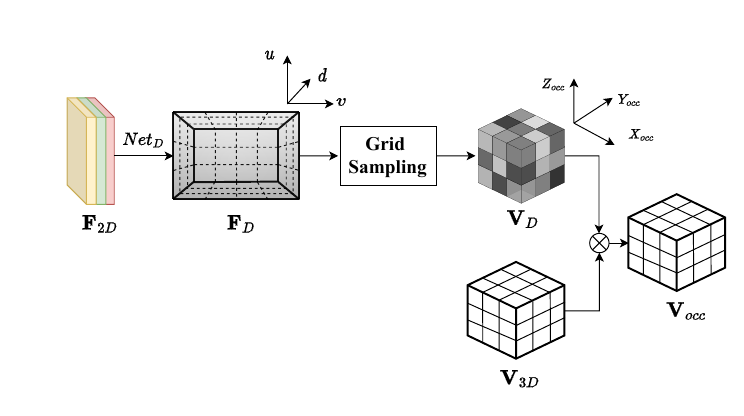
为了在将 2D 图像特征转换为 3D 体素特征时引入空间占用的先验信息,本项工作提出了占用深度感知(OAD)模块,通过预测的深度信息显式地引入到空间占用先验信息。上图为占用感知深度模块的示意图,为了简单起见,图中仅展示了单图像 V_D的处理流程。
受到优秀的 3D 物体检测工作[15-16]的启发,OAD 模块使用预测的深度信息来估计体素特征空间中物体存在的先验概率。然后使用此概率信息来改善体素特征的空间信息。根据上述的 Stereo-SFA 模块可以得到体素空间 V_{3D}\in R^{ X\times Y \times Z\times C}中对应的特征图。将具有下采样尺度 S=8的单尺度图像特征 F_{2D}\in R ^{ H\times W \times C}送到 OAD 模块,首先,使用一个深度分布网络 Net_D来预测多视图输入图像的深度特征 F_{D}\in R ^{ H\times W \times C};其次,使用 softmax 算子将 F_D变换为截锥体的深度分布 G_{D}\in R ^{ H\times W \times C}其中 D是离散深度块的个数。之后,截锥体深度分布 G_D通过使用相机标定矩阵 P\in R^{3\times 4}和可微网格采样过程被转换为体素空间深度分布表示 V_D \in R^{X\times Y \times Z}最后可以获得占用感知体素特征 V_{occ} :
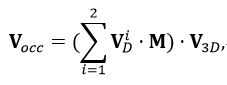
其中M是对双目图像输入之间可视重叠区域的体素像素进行平均的掩码,重叠区域的值为 0.5,其他为 1.0。 V_D可以被理解成体素空间中的先验占用概率。
3.3 残差设计
OccDepth 通过优化几何损失函数、语义损失函数、深度损失函数和 MonoScene 中提出的 L_{mono}损失函数进行训练:
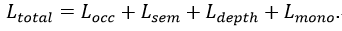
其中 L_{mono}=L_{rel}+L^{scal}_{sem}+L^{geo}_{scal}+L_{fp},L_{rel}可以帮助更好地提取语义信息, L_{sem}^{scal},L_{scal}^{geo}可以帮助提高语义和几何结构精度的提升,而 L_{fp}则是用于提升模型的补全能力。
四、实验
4.1 指标对比
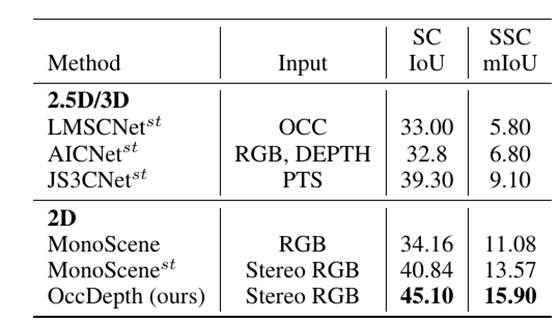
上表是在 SemanticKITTI 数据集的测试集上的表现结果表,所有 2.5D/3D 的方法都修改为基于双目图像推理的版本,并标有上标“st”。双目图像用于为 2.5D/3D 方法生成 occupancy、TSDF、点云和深度图。对于基于单目的 MonoScene,我们从双目输入获取的特征中平均融合成 3D 体素特征,并将其命名为 MonoScene^{st}。在表中,最佳的结果以粗体显示。场景补全的IoU 和语义场景补全的 mIoU 作为指标被用于评价方法的性能。在相同双目输入情况下,本工作提出的 OccDepth 具有最好的结果。
OccDepth 在 SemanticKITTI 数据集的测试集上的测试结果报告在上表中。上表的实验结果表明,在相同双目图像作为输入的情况下,我们的 OccDepth 优于其他方法。与作为 2D 基础方法的 MonoScene 相比,OccDepth 在 SemanticKITTI 上提高了 +4.82 mIoU/+10.94 IoU(表 \ref{mainResults0}。同时,在 SemanticKITTI 上, 与 MonoScene^{st}相比,我们的 OccDepth 也取得了相当大的改进([+2.33 mIoU,+4.26 IoU])。这意味着 OccDepth 可以提供比 MonoScene^{st}更精细的几何结构。
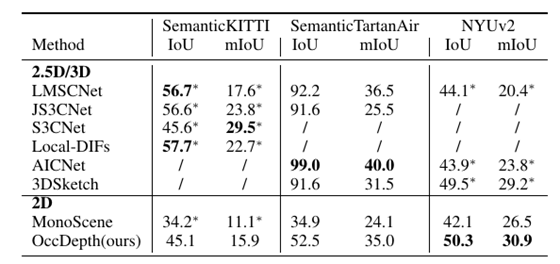
在不同数据集上和 2.5D/3D 数据作为输入的方法的对比表。OccDepth 的结果在一些室内场景上和 2.5D/3D 的方法接近甚至有所超越,在室外场景上和某些 2.5D/3D 方法相媲美。"*" 表示结果引用自 MonoScene。“/”表示缺失结果。
我们还将 OccDepth 与原始 2.5D/3D 作为输入的基础方法进行了比较,结果列在上表中。在 SemanticKITTI 数据集的隐藏测试集中,虽然 OccDepth 只使用水平视野比激光雷达( 82°vs. 180°)小得多的双目图像,但 OccDepth 取得了和使用 2.5D/3D 基础方法可比的结果 。这个结果表明 OccDepth 具有相对较好的补全能力。在 NYUv2 的测试集中,因为没有双目图像,我们的 OccDepth 将 RGB 图像和深度图生成虚拟双目图像作为输入。结果显示, OccDepth 取得了比所有 2.5D/3D 方法更好的 mIoU 和 IoU([+0.8 IoU,+1.7 mIoU])。在提出的仿真数据集 SemanticTartanAir 的测试集中,我们在这里使用深度真值作为这些 2.5D/3D 方法的输入,所以 2.5D/3D 方法的准确率非常高。另一方面,与 2.5D/3D 输入方法相比, OccDepth 具有较为接近的 mIoU 结果,并且 OccDepth 没有使用深度真值。与 纯视觉推理的方法相比,OccDepth 具有更高的 IoU 和 mIoU ([+17.6 IoU, +10.9 mIoU])。
4.2 定性对比
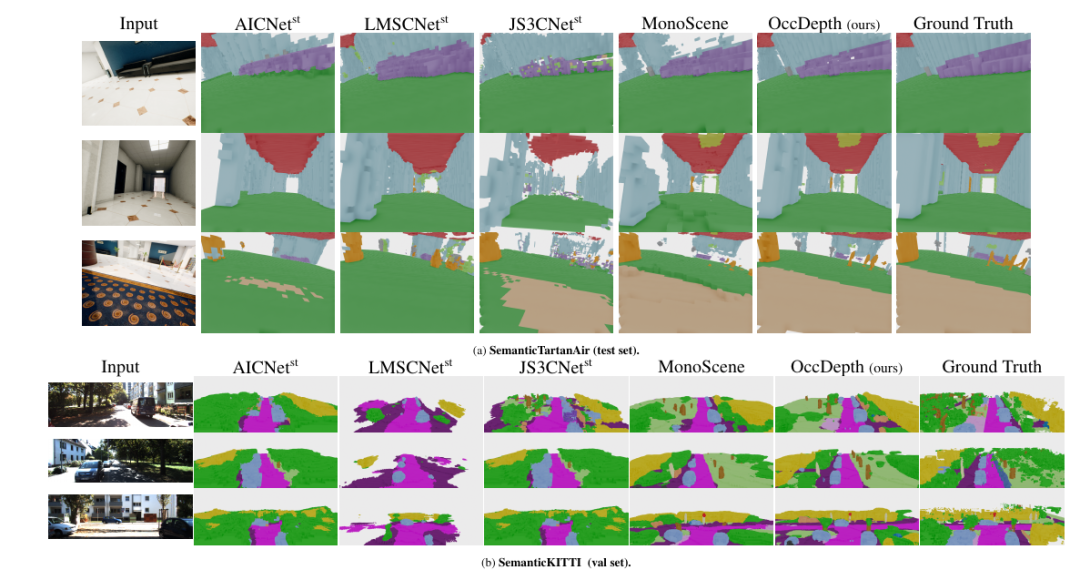
在 SemanticTartanAir 和SemanticKITTI 上的可视化结果。最左侧是输入的图像,最右侧是语义体素真值,中间为各种方法的可视化结果。这里显示了 OccDepth 在两个数据集中有较好结果场景。
在室内场景 SemanticTartanAir 数据集上,虽然所有方法都正确获得了正确的场景表示,但 OccDepth 对物体边缘具有更好的还原效果,例如沙发(图(a)的第 1 行)和天花板灯(图(a)的第 2 行) 和地毯(图(a)的第 3 行)。而在室外场景的 SemanticKITTI 数据集上,与基础方法相比,OccDepth 的空间和语义预测结果明显更好。例如,通过 OccDepth 可以实现路标(图(b)的第 1 行)、树干(图(b)的第 2 行)、车辆(图(b)的第 2 行)和道路(图(b)的第 3 行)的准确识别。
4.3 消融实验

对提出的模块进行消融实验。(a) Stereo-SFA 模块的消融实验。(b) OAD 模块中深度蒸馏数据源的消融实验。(c)OAD 模块中深度蒸馏数据源的消融实验。“w/o Depth”表示不使用深度蒸馏,Lidar depth 是指激光雷达点云生成的深度图,Stereo Depth 是指 LEAStereo 模型生成的深度图。以上实验都在 SemanticKITTI 的 08 号轨迹上进行测试。(a),(b),(c)的消融实验结果证明了提出的每个模块的有效性。
五、总结
在这项工作中,我们提出了一种有效利用深度信息的 3D 语义场景补全方法,我们将其命名为 OccDepth 。我们在 SemanticKITTI(室外场景)和 NYUv2(室内场景)数据集等公共数据集上训练了 OccDepth, 实验结果表明,本工作提出的 OccDepth 在室内场景和室外场景上都可与某些以 2.5D/3D 数据作为输入的方法相媲美。特别地是,OccDepth 在所有场景体素类别分类上都优于当前基于纯视觉推理的方法。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
