原创 | 顶会论文也漏引?不仅有,还很多!


作者:林嘉亮
本文约3000字,建议阅读10分钟本文重点阐述使用CRPSE对计算机科学顶会中的论文进行漏引检测的结果和分析。学术研究是一个持续发展的过程。它在现有知识的基础上创造新知识,同时为未来研究打下基础。论文中的引用,体现的是过去与现在研究的联系。没有这种联系,就不会有知识的创造和积累。此外,引用赋予了学术研究的专业性。一方面,引用能够为读者提供相关领域的信息。这些信息加强了读者对当前工作的理解,使作者和读者达成了某种共识。另一方面,引用可以验证当前工作的可信度。恰当的引用表明作者对论文所涉及的领域有充分的了解,也可以成为支持作者论点的论据。因此,引用极其重要,但全面而准确地引用并非易事。
据我们所知,目前还没有针对论文科学实体的漏引检测方法及其应用到顶会论文上的漏引情况分析。为解决这个问题,我们提出了论文科学实体引文推荐(Citation Recommendation for Published Scientific Entity,CRPSE)方法,将论文科学实体映射到它们的源论文。采用该方法,对计算机科学顶会上发表的论文中存在漏引的论文科学实体进行了全面的统计分析。
这里针对本文定义了两个概念,一个是论文,一个是论文科学实体。
论文(Paper):
论文定义为一般的学术出版物,不限于期刊或会议论文,还可以指书籍、报告、专利和标准。
论文科学实体(Published Scientific Entity):
论文科学实体定义为有衍生论文的科学对象(scientific object)且论文的作者即为该科学对象的提出者。论文科学实体按命名方式可以分为两大类。第一类由原作者命名,如neighbor-joining method、ATRP、ImageNet和AlphaGo。第二类由后来的研究人员根据原作者的名字命名,如Schrödinger equation,Bradford's law,Turing test和Witten-Bell smoothing。
所提出的方法CRPSE主要分为以下步骤:构建论文科学实体-论文映射数据集、过滤噪声数据、排序与推荐。具体的方法可以参见本文相关的学术论文“Detecting and Analyzing Missing Citations to Published Scientific Entities”,见图1。

图1 本文相关学术论文信息
本文重点阐述使用CRPSE对计算机科学顶会中的论文进行漏引检测的结果和分析。我们从十四个计算机科学顶会(AAAI、ACL、COLING、COLT、CVPR、ECCV、EMNLP、ICLR、ICML、IJCAI、INTERSPEECH、NeurIPS、RSS和USS)收集了12,278篇常规论文(regular paper),在这些论文中,发现了475个在计算机科学及数学领域的论文科学实体在使用时没有适当的引用。这个数字显示,即使在计算机科学顶会上发表的论文,漏引的情况也并不少见。
在对数据的分析中,发现一些论文科学实体的引用不准确(注:不准确的引用表示没有引用真正匹配的源论文,属于广义范围中的漏引)。例如,对于论文科学实体DeepLabv3+,在一篇论文中,“Rethinking Atrous Convolution for Semantic Image Segmentation”被当作参考文献,而其真正的源论文是“Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation”。这篇被误引的论文实际上是DeepLabv3(DeepLabv3+的前一个版本)的源论文。另一个类似的例子是论文科学实体VQAv2。在一篇论文中,它的参考文献是“VQA: Visual Question Answering”,但事实上,这个实体是在“Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering”中提出的。除了引用与实际所需论文不相符的错误之外,也存在引用相符,但参考文献标题写错的情况。例如,论文科学实体EPIC-KITCHENS的源论文“Scaling Egocentric Vision: The EPIC-KITCHENS Dataset”被错误地写成“Scaling egocentric vision: the dataset”。针对这种不准确的引用,我们强烈呼吁加强认识,严格防范,以保持学术和科学的严谨性。
除了不准确的引用外,我们发现,有不少论文科学实体存在漏引的情况。相当一部分这些存在漏引的论文科学实体是计算机科学领域,或者至少是在一个小的细分领域广为人知的著名实体。为了进一步了解漏引的情况,我们进行了统计分析,以弄清这些论文科学实体属于什么类型,以及它们距离源论文发表的时间有多长。
首先,我们将这些漏引的论文科学实体手动分类到不同领域,结果显示在图2中。
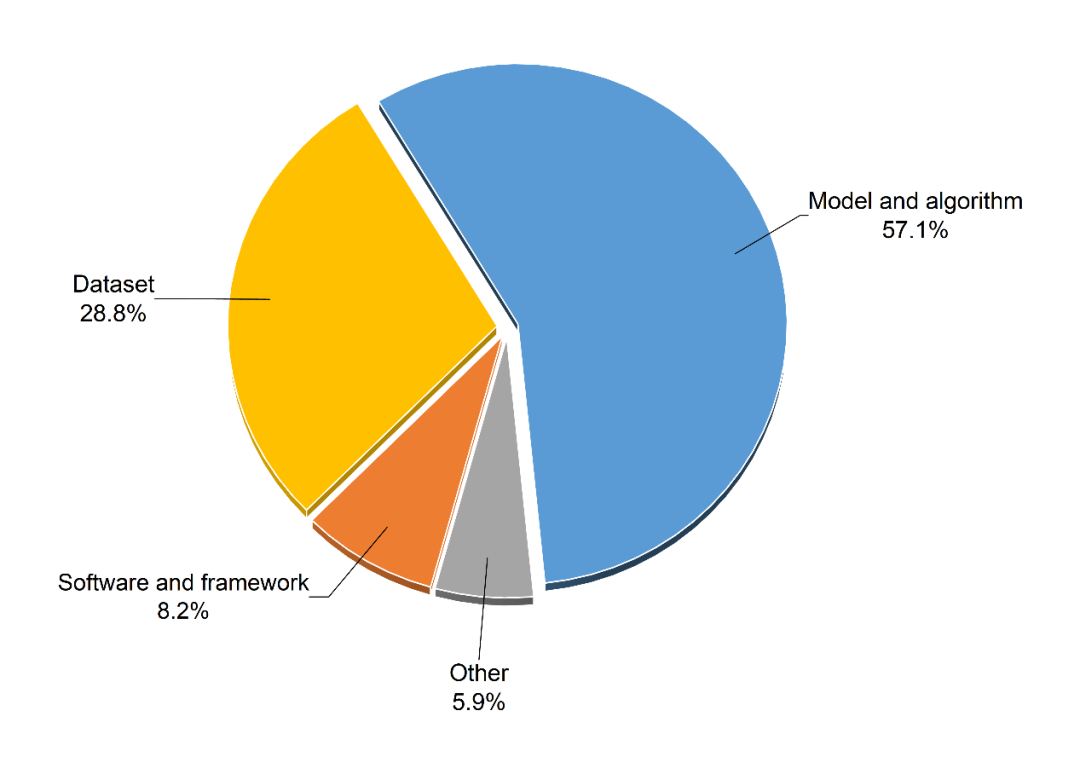
图2漏引的论文科学实体类型分布
如图2所示,大部分缺失引用的实体是模型和算法,占总数的一半以上。模型和算法是计算机科学的核心。模型和算法缺失引用的比例很高,这正说明了它们在这个领域的广泛性,也就是说,计算机科学的大多数研究都提出了模型或算法作为贡献。k-means是一个典型的例子。这个著名的算法由J. MacQueen在1967年提出,后来成为了机器学习领域的每个研究人员都应该掌握的基础知识。研究人员使用该算法进行数据处理或基于它开发新的算法。由于它实在太出名,一些研究人员在使用它时便没有引用。同样的情况出现在数据集实体中,缺失引用实体属于数据集的占比超过四分之一。数据集可以说是模型和算法的孪生物,通常一个新的模型和算法提出后,基本都要在公开的数据集与前人的模型和算法进行比较。一些著名数据集不断在某些特定的任务中使用,从而成为了这些任务的标准数据集,导致人们对这些数据集越来越熟悉,以致使用时不加引用。这样的例子有the Penn Treebank、COCO和LibriSpeech。
接着,我们研究时间对论文科学实体的漏引有什么影响。对有漏引实体的源论文,根据其发表年份进行排序,结果显示在表1和图3中。

表1 漏引的论文科学实体对应源论文发表年数统计特征
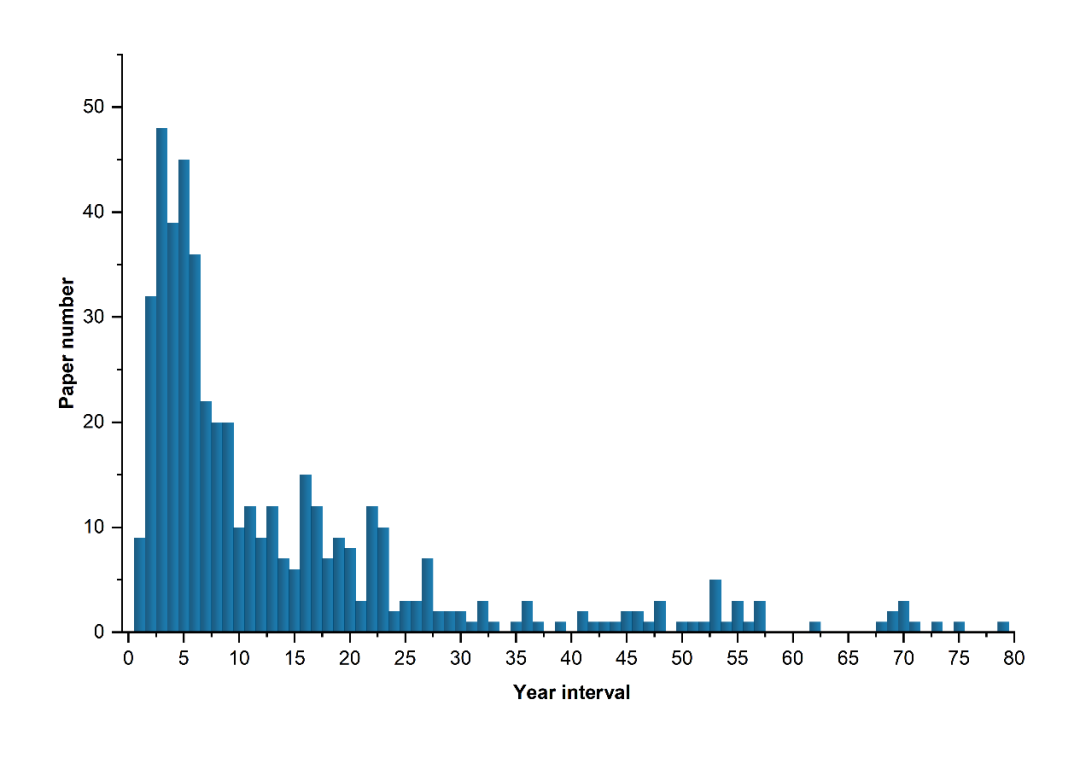
图3漏引的论文科学实体类型分布
在这些论文中,最早发表的是“On Colouring the Nodes of a Network”,其提出了论文科学实体Brooks' theorem。与先前的估计相反,一些新提出的实体,如SpecAugment,也存在缺失引用的问题,而且这种情况还不少。SpecAugment的源论文“SpecAugment: A Simple Data Augment Method for Automatic Speech Recognition”发表于2019年,比研究的基准年2020年仅早一年。从图3中可以明显看到一个偏斜的分布,分布的峰值偏离中心位于左边。这意味着更多最近提出的论文科学实体受到缺失引用的影响。我们认为,这是由于这些最近提出的论文科学实体被研究人员使用得更多,出现的频次更高造成的。相比之下,提出时间较长的论文科学实体则与最新研究的联系较弱,所以出现的基数较小。为了消除异常值的影响,根据分布和统计测试的结果,我们把中位数8年作为衡量标准。该值比平均值更能代表数据的总体情况。这个时间可以看作是计算机科学相关的研究成果从新发布到发展成为公众知识所需要的时间。在这8年里,这些实体首先被提出并接受检验,然后得到了广泛推广,同时不断地启发着后来的研究人员。它们被反复使用,甚至成为了教科书上的内容,使得研究人员对这些实体过于熟悉,以至于会不加引用地使用它们。
鉴于研究中发现大量实体存在漏引的情况,我们呼吁按照学术规范的要求,对所有论文科学实体都应该进行准确的引用。本文的相关论文已经发表在Scientometrics Vol. 127, Issue 5, pp. 2395-2412 (2022)。
编辑:黄继彦
校对:林亦霖
作者简介
林嘉亮,厦门大学计算机科学与技术专业博士候选人,曾任职高级工程师并获评创新创业骨干人才和紧缺人才。主要研究兴趣为科学计量、科学评价与自然语言处理。提出了学术论文自动审稿(Automated Scholarly Paper Review,ASPR)的概念和体系,并在此基础上发表了若干篇论文。
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”加入组织~
腾讯云开发者
