𝛼 ILP: thinking visual scenes as differentiable logic programs

𝛼 ILP: thinking visual scenes as differentiable logic programs

CreateAMind
发布于 2023-09-01 08:33:16
发布于 2023-09-01 08:33:16

https://github.com/ml-research/alphailp
优点:1 𝛼ILP高精度地解决了视觉场景中的ILP问题。2 𝛼ILP可以解释,即它以逻辑程序的形式产生可读的解决方案。3 𝛼ILP 对混杂因素具有鲁棒性。4 𝛼与 CNN 不同,ILP 具有数据效率。5 𝛼ILP 执行快速推理。
抽象的
深度神经学习在学习视觉对象分类表示方面表现出了卓越的性能。然而,诸如 CNN 之类的深度神经网络并没有显式地对对象及其之间的关系进行编码。这限制了他们在需要对视觉场景进行深入逻辑理解的任务上的成功,例如康定斯基模式和邦加德问题。为了克服这些限制,我们引入𝛼ILP ILP,一种新颖的可微分归纳逻辑编程框架,它学习将场景表示为逻辑程序——直观地,逻辑原子对应于对象、属性和关系,子句编码高级场景信息。𝛼ILP 具有基于视觉输入的端到端推理架构。使用它,𝛼 ILP对复杂的视觉场景进行可微归纳逻辑编程,即通过梯度下降来学习逻辑规则。我们对Kandinsky 模式和CLEVR-Hans基准进行了大量实验,证明了以下方法的准确性和效率:𝛼ILPILP学习复杂的视觉逻辑概念。
1简介
理解视觉场景是构建智能代理的一个基本问题。卷积神经网络 (CNN) 等深度神经网络在许多视觉感知基准测试中取得了成功,但在复杂的视觉场景中表现不佳,在复杂的视觉场景中,图像中出现多个对象,代理需要推理和了解属性和关系。基于 CNN 的模型不会显式编码对象和关系,因此通常无法捕获复杂视觉场景中定义的模式。
康定斯基模式(Holzinger et al., 2019;Müller & Holzinger, 2021;Holzinger et al., 2021)已被提出来评估智能系统解释复杂视觉场景的能力。同样,CLEVR-Hans(Stammer 等人,2021)被提出来评估模型理解混杂视觉场景的能力。基于 CNN 的模型在这种情况下无法产生正确的解释,并且还可能遇到混杂因素的问题。此外,他们需要数据,并且很难学习抽象的视觉关系(Kim et al., 2018)。因此,一个自然的问题出现了:我们如何构建一个智能系统来避免这些陷阱?
为了构建一个克服基于 CNN 模型的不足的系统,出现了神经符号方法(Besold 等人,2017 年;d'Avila Garcez & Lamb,2020 年;Tsamoura 等人,2021 年),其中符号计算与神经网络。作为基于逻辑的神经符号系统,已经提出了许多框架,例如 DeepProblog (Manhaeve et al., 2018 , 2021 )、NeurASP (Yang et al., 2020 ) 和∂∂ILP(埃文斯和 Grefenstette,2018)。然而,之前的研究无法从视觉输入中完成结构学习(Manhaeve et al., 2018 , 2021;Yang et al., 2020)或无法处理复杂的规则和视觉场景(Evans & Grefenstette, 2018)。因此,复杂场景的结构学习,例如康定斯基模式(Holzinger et al., 2019;Müller & Holzinger, 2021;Holzinger et al., 2021)和 CLEVR-Hans(Stammer et al., 2021)问题是很困难的。使用这些框架是不可能的。
为了缓解这个问题,我们建议𝛼 ILP ,脚注1一种新颖的可微分归纳逻辑编程(ILP)框架,它将以对象为中心的感知与 ILP 相结合(Muggleton, 1991,1995;Nienhuys-Cheng 等人,1997; Cropper等人, 2022),建立了第一个框架第四种神经符号系统,即神经:符号→→Neuro,由 Kautz 提出(2022)。𝛼ILP 将神经网络 (Neuro) 的输出映射到符号表示 (Symbolic),然后在其之上执行基于梯度的学习 (Neuro)。𝛼�ILP执行结构学习,即从复杂的视觉场景中学习离散逻辑程序。为此,我们的系统是神经符号系统的扩展,例如 DeepProblog (Manhaeve et al., 2018 , 2021 ) 和∂∂ILP(埃文斯和 Grefenstette,2018)。
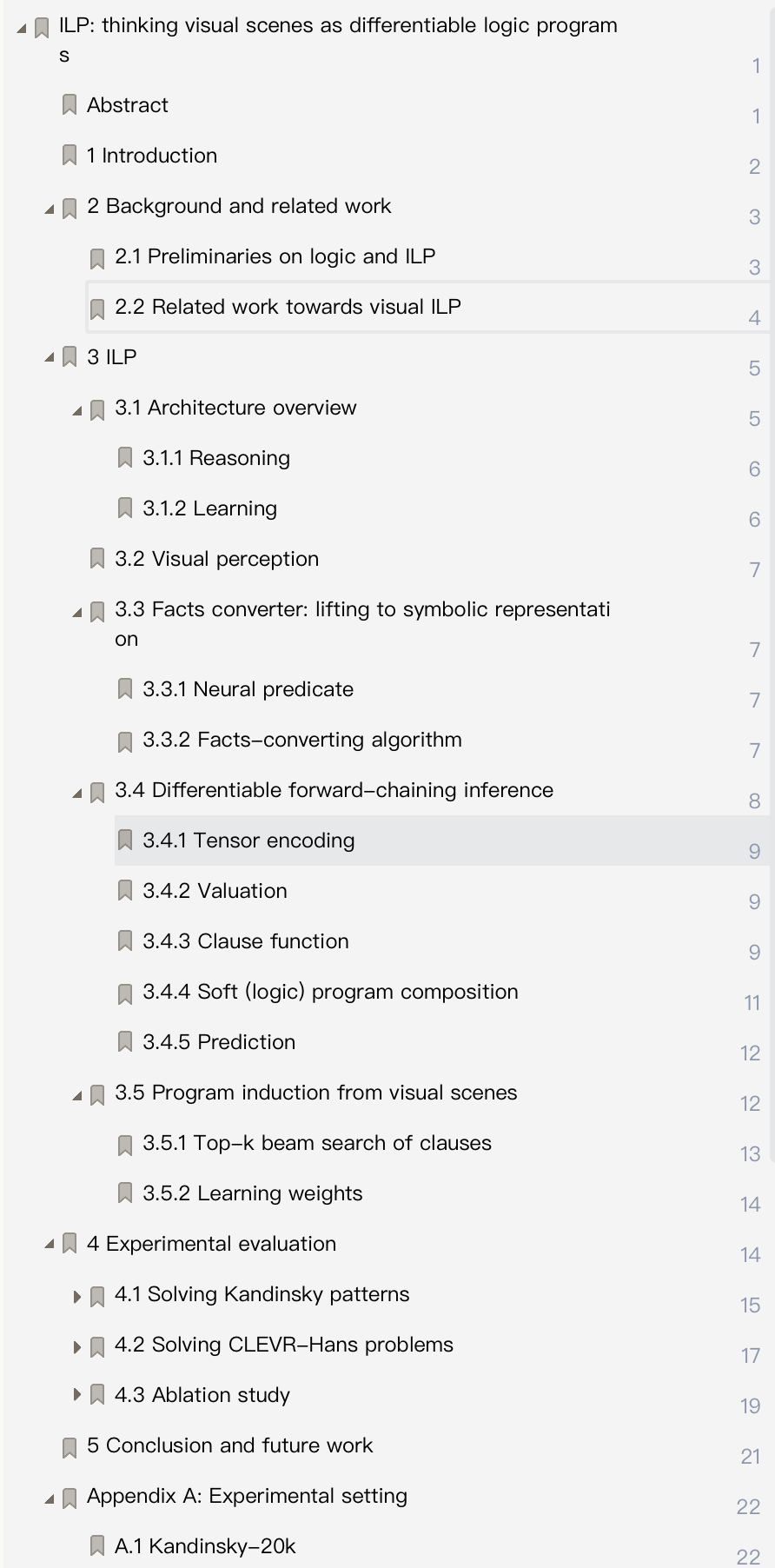
𝛼ILP 具有基于视觉输入的端到端推理架构,由三个主要组件组成:(i) 视觉感知模块、(ii) 事实转换器和 (iii) 可微推理模块。事实转换器将视觉感知模块的输出转换为概率事实的形式,然后将其输入推理模块。然后,推理模块根据给定的事实集执行可微的前向链接推理。它计算可以从给定的事实集和加权逻辑规则推导出来的事实集(Evans & Grefenstette,2018;Shindo 等人,2021)。根据前向链接推理的结果可以做出最终的预测。𝛼�ILP 学习通过可微分 ILP 技术对高级场景信息进行编码的逻辑程序(Shindo 等人,2021)。它通过 top- k波束搜索生成子句候选,并通过反向传播学习子句的权重。
关键贡献:(1)我们建议𝛼�ILP,一种新颖的框架,可从视觉场景中执行可区分的 ILP。(2) 建立𝛼�ILP,我们提出了一种基于视觉输入的端到端推理架构。它通过使用感知模型和事实转换算法对视觉场景执行可微的前向链接推理。(3)我们还提出了一个学习方案𝛼�ILP 对复杂的视觉场景执行可微分的 ILP。它将可微 ILP 技术与视觉领域相结合,即有效地生成子句并从复杂的视觉场景中执行基于梯度的优化。(4) 我们通过实证证明了以下优点:𝛼�ILP:(一)𝛼�ILP 解决了视觉场景中的 ILP 问题,即 Kandinsky 模式 (Holzinger et al., 2019 ; Müller & Holzinger, 2021 ; Holzinger et al., 2021 ) 和 CLEVR-Hans (Stammer et al., 2021 ),高精度优于神经基线模型。(二)𝛼�ILP可以生成解释,即以逻辑程序的形式产生可读的解决方案。(三)𝛼�ILP 对混杂因素具有鲁棒性,即避免过度拟合混杂因素。(四)𝛼�ILP 具有数据效率,即即使使用 10% 的训练数据,性能也不会下降。(五)𝛼�ILP可以进行快速推理。它支持 GPU 上高效的并行批量计算,因此可以快速对大型数据集中的大量实例进行分类。
2.2视觉ILP的相关工作
50 多年前,俄罗斯计算机科学家 MM Bongard 发明了一百个人类设计的视觉识别任务的集合(Bongard & Hawkins,1970),现在称为 Bongard Problems(BP),以证明人类高级认知与计算机化模式识别之间的差距。受 BP 的启发,Bongard-LOGO(Nie 等人,2020)问题被提出作为机器学习社区的基准。Kandinsky(Holzinger et al., 2019;Müller & Holzinger, 2021;Holzinger et al., 2021)已被提出来评估智能系统解释复杂视觉场景的能力。同样,CLEVR-Hans(Stammer 等人,2021)已被提出来评估模型理解混杂视觉场景的能力。这些基准对基于 CNN 的识别模型提出了挑战。
命题逻辑和一阶逻辑是在机器上执行推理的既定框架(Lloyd,1984;Kowalski,1988)。逻辑归纳推理的开创性研究是在 70 年代初完成的(Plotkin,1971)。模型推理系统 (MIS)(Shapiro,1983)已被实现为逻辑程序的有效搜索算法。Inductive Logic Programming(Muggleton,1991,1995 ; Nienhuys-Cheng 等,1997;Cropper 等,2022)出现在机器学习和逻辑编程的交叉点。许多 ILP 框架已经被开发出来,例如 FOIL (Quinlan, 1990)、Progol(Muggleton,1995)、ILASP(Law 等人,2014)、Metagol(Cropper 和 Muggleton,2016;Cropper 等人,2019)和 Popper(Cropper 和 Morel,2021)。符号 ILP 系统专用于符号输入。𝛼 ILP deals with visual inputs by having an end-to-end neuro-symbolic reasoning architecture. 𝛼 ILP employs similar structure-learning techniques which have been developed for probabilistic logic programs (Bellodi & Riguzzi, 2015; Nguembang Fadja & Riguzzi, 2019) and performs learning on complex visual scenes. Different settings of probabilistic ILP approaches have been introduced in De Raedt et al. (2008). 𝛼 ILP is based on the learning from entailment setting, where the logical entailment is computed from probabilistic inputs. 𝛼 ILP computes the logical entailment with probabilistic values for facts and clauses in a differentiable manner.
符号程序和神经网络的集成,称为神经符号计算(Besold et al., 2017;d'Avila Garcez & Lamb, 2020;Tsamoura et al., 2021),之前已经被解决过,例如 DeepProblog ( Manhaeve et al., 2018 , 2021 ), NeurASP (Yang et al., 2020 ), ILP (Evans & Grefenstette, 2018 ; Jiang & Luo, 2019 ), NS-CL (Mao et al., 2019 ), 积分溯因学习(Dai et al., 2019)和可微定理证明器(Rocktäschel & Riedel, 2017)∂∂; 米勒维尼等人,2020)。Kandinsky 模式和 CLEVR-Hans 无法通过这些框架轻松解决,因为它们需要从复杂的视觉场景中学习完整的结构。DeepProblog 支持结构学习,但仅限于草图设置(Solar-Lezama,2008;Bošnjak 等人,2017)。支持以对象为中心的感知模型、可微分前向推理以及用于解决复杂视觉场景中任务的高效子句搜索。一些神经符号模型已经开发用于视觉问答(VQA)(Antol et al., 2015 ; Johnson et al., 2017 ; Santoro et al., 2018 ; Mao et al., 2019𝛼�; 阿米扎德等人,2020)。在基于 VQA 的模型中,符号程序由代表问题的自然语言句子确定,但 ILP 没有该假设。此外, ILP 属于概率逻辑编程的范畴(De Raedt et al., 2016;Raedt et al., 2020)。因此,可以采用社区开发的概率逻辑编程方法。ILP的一些关键组成部分的类似概念已经在之前的研究中进行过研究,例如神经谓词(Diligenti 等人,2017 年;Donadello 等人,2017 年)𝛼�𝛼�𝛼�𝛼�; Badreddine 等人,2022)、加权前向链推理(Sourek 等人,2018;Si 等人,2019)以及可微结构学习(Evans 和 Grefenstette,2018;Sourek 等人,2017)。𝛼 ILP 第一个将这些概念集成到以视觉对象为中心的领域作为一致框架的项目。逻辑张量网络(LTN)(Badreddine 等人,2022)为一阶逻辑提供了统一的可微分语言。LTN 将一阶逻辑中的每个术语映射为数字表示以代替解释𝛼�。然后谓词基于函数,该函数采用术语的数字表示并返回 [0, 1] 中的真值。 𝛼 ILP 采用类似的方法来连接子符号和符号表示。
3 alphaILP
3.1 Architecture overview
3.1.1推理
𝛼�ILP 具有端到端推理架构,其工作原理如下:(i)使用视觉感知模型根据对象对原始输入图像进行分解。(ii) 以对象为中心的表示被转换为一组概率事实。(iii) 使用加权子句进行可微分前向推理。图1的底行 说明了推理架构𝛼�ILP。
3.1.2学习
𝛼�ILP 通过执行可微 ILP 从视觉输入中学习逻辑程序,即我们提供正例、负例和背景知识。每个示例都作为视觉场景给出。图1的顶行 说明了学习流程𝛼�ILP。学习与𝛼�ILP如下:(Step1)通过top- k波束搜索生成一组候选子句。使用端到端推理架构从视觉场景的示例中进行搜索。(Step2)训练生成的子句的权重以最小化损失函数。通过使用端到端推理架构,𝛼�ILP 找到了一个逻辑程序,可以通过梯度下降来解释复杂的视觉场景。我们现在详细描述我们的架构。
3.2 Visual perception
yolo,renset 等等
3.3 Facts converter: lifting to symbolic representation
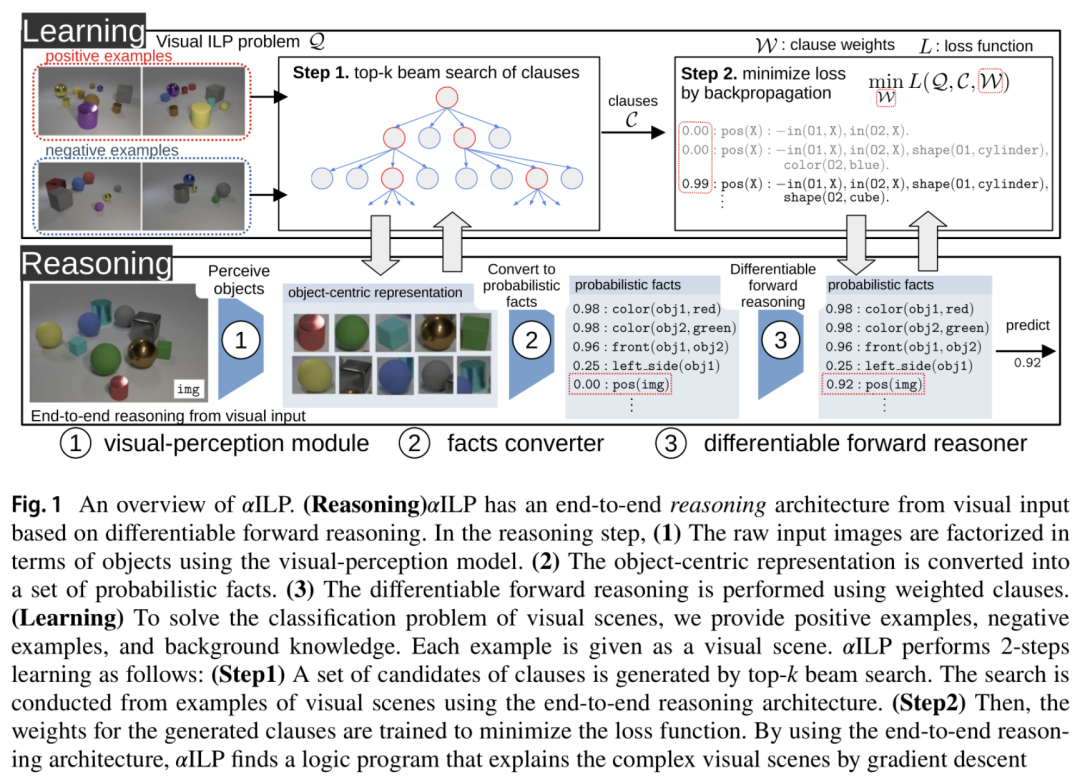
在以对象为中心的感知之后,𝛼�ILP 生成逻辑表示,即一组概率事实。我们提出了一种新型谓词,可以引用可微函数来计算概率。我们还提出了一种将感知结果转换为概率事实的算法。
3.3.1 Neural predicate
为了在子符号表示和符号表示之间架起一座桥梁,我们提供了一种新型谓词,我们将其称为神经谓词。神经谓词与可微函数相关联,我们将其称为评估函数,它产生基于事实的概率。

直观地,我们给出神经谓词和项的一阶逻辑解释如下:(i)每个神经谓词被分配给向量空间中的一个函数,(ii)神经谓词参数中的每个项被分配给一个向量。该向量可以是神经网络的输出,或者是术语的编码,例如属性的one-hot编码。
3.3.2 Facts‐converting algorithm
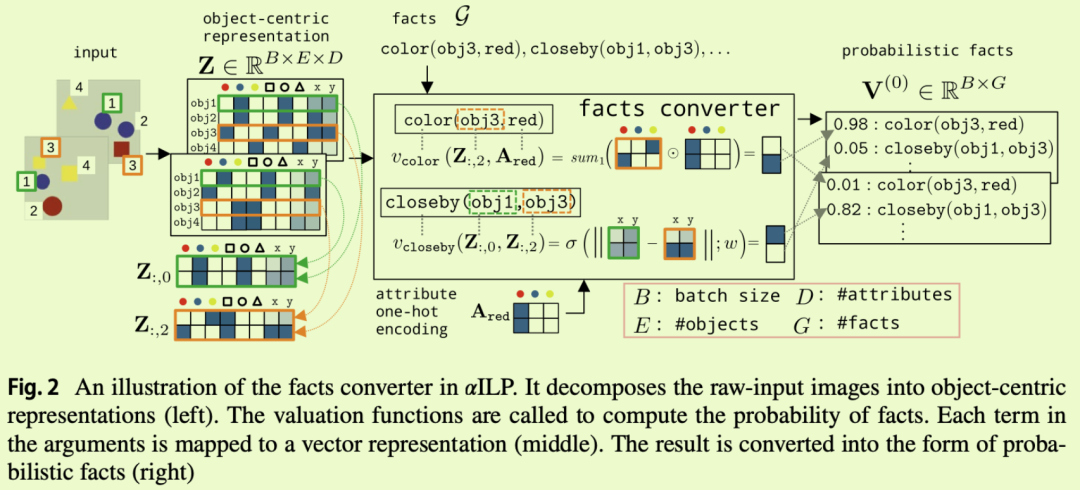

3.4 Differentiable forward‐chaining inference

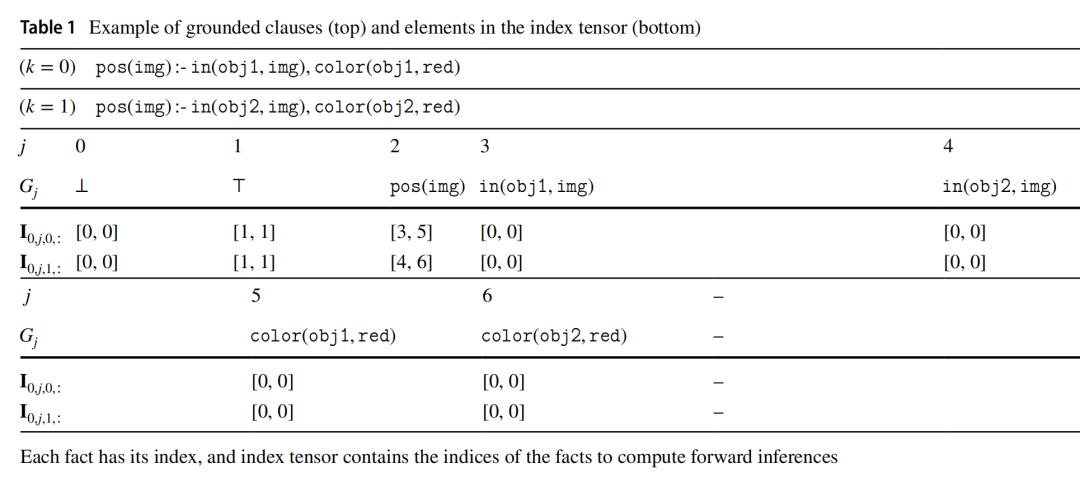
3.4.1 Tensor encoding



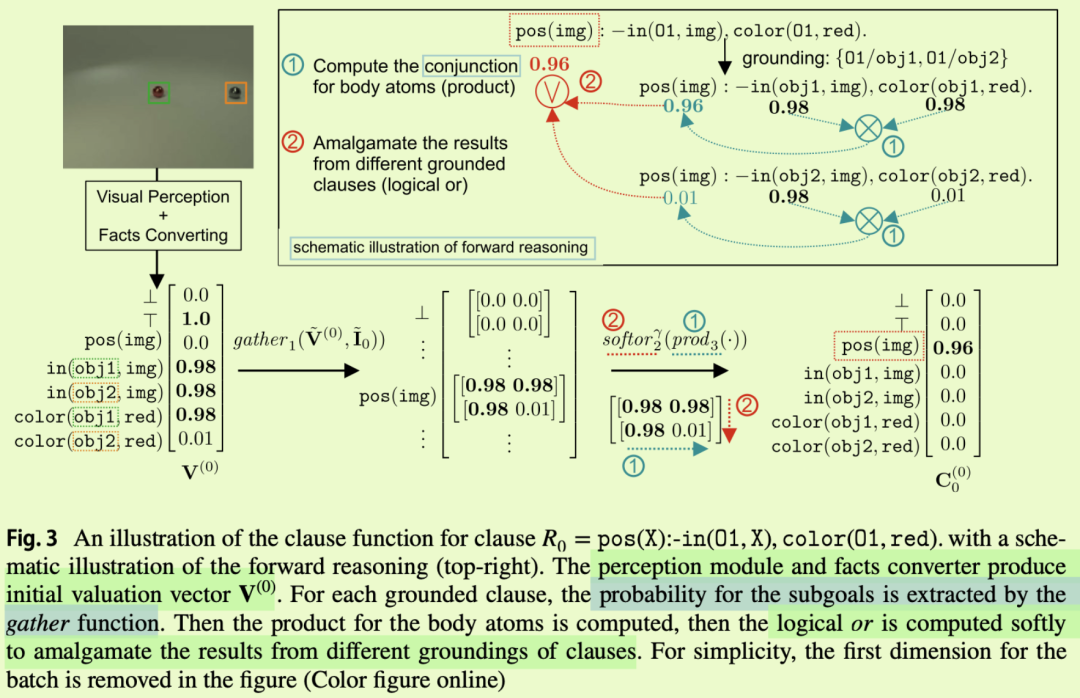

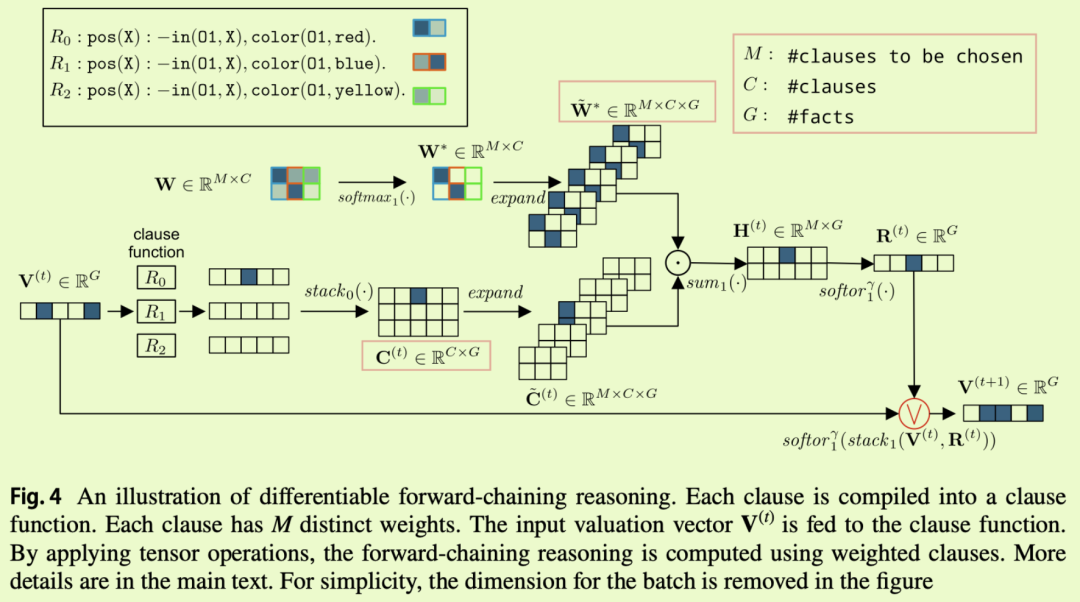



4 优点:
1 𝛼ILP高精度地解决了视觉场景中的ILP问题。2 𝛼ILP可以解释,即它以逻辑程序的形式产生可读的解决方案。3 𝛼ILP 对混杂因素具有鲁棒性。4 𝛼与 CNN 不同,ILP 具有数据效率。5 𝛼ILP 执行快速推理。



完整内容请参考原论文
相关推荐:
AGI结构模块很细分:脑网络结构高清大图
AGI部分模块的优秀复现:
最新代码:一个epoch打天下:深度Hebbian BP (华为实验室) 生物视觉 +
AGI之 概率溯因推理超越人类水平 VSA符号溯因abductive推理 +
Spaun2 Extending the World's Largest Functional Brain Model 架构 +
自由能AI模型的理论高度和潜力(信息量大)自由能loss +
DeepMind Dreamer 系列为什么效果这么好及自由能理论高度和潜力 世界模型+
世界模型仅用 1 小时训练一个四足机器人从头开始翻滚、站立和行走,无需重置。10 分钟内适应扰动或快速翻身站立 躯体控制 +
代码:Learning to Learn and Forget (华为)长短期记忆网络 +
inductive Logic Programs 视觉推理 +
框架及硬件
生物神经网络的开源芯片 +
矢量符号架构作为纳米级硬件的计算框架 +
Self-Expanding ⾃扩展神经⽹络
benchmark:
NeuroGym- An open for developing and sharing neuroscience tasks
60作者的NeuroBench:通过协作、公平和有代表性的基准测试推进神经形态计算
Towards Data-and Knowledge-Driven AI: A Survey Neuro-Symbolic 图表
系统观:
大脑中复杂适应动力学的神经调节控制
突触神经耦合的混沌动力特性
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-07-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号